Gerenciamento de incidentes para equipes de alta velocidade
Otimização do gerenciamento de incidentes para operações de TI
As interrupções afetam os resultados.
O tempo de inatividade muitas vezes significa não apenas perda de receita, mas também danos à reputação, penalidades de conformidade e regulatórias, perda de clientes, aumento nos custos operacionais e atrasos, à medida que os profissionais de TI são retirados de outros projetos para resolver incidentes.
Na verdade, um relatório da IHS estimou que o tempo de inatividade custa às empresas norte-americanas mais de US$ 700 bilhões por ano — e 78% desse custo é atribuído à perda de produtividade dos funcionários.
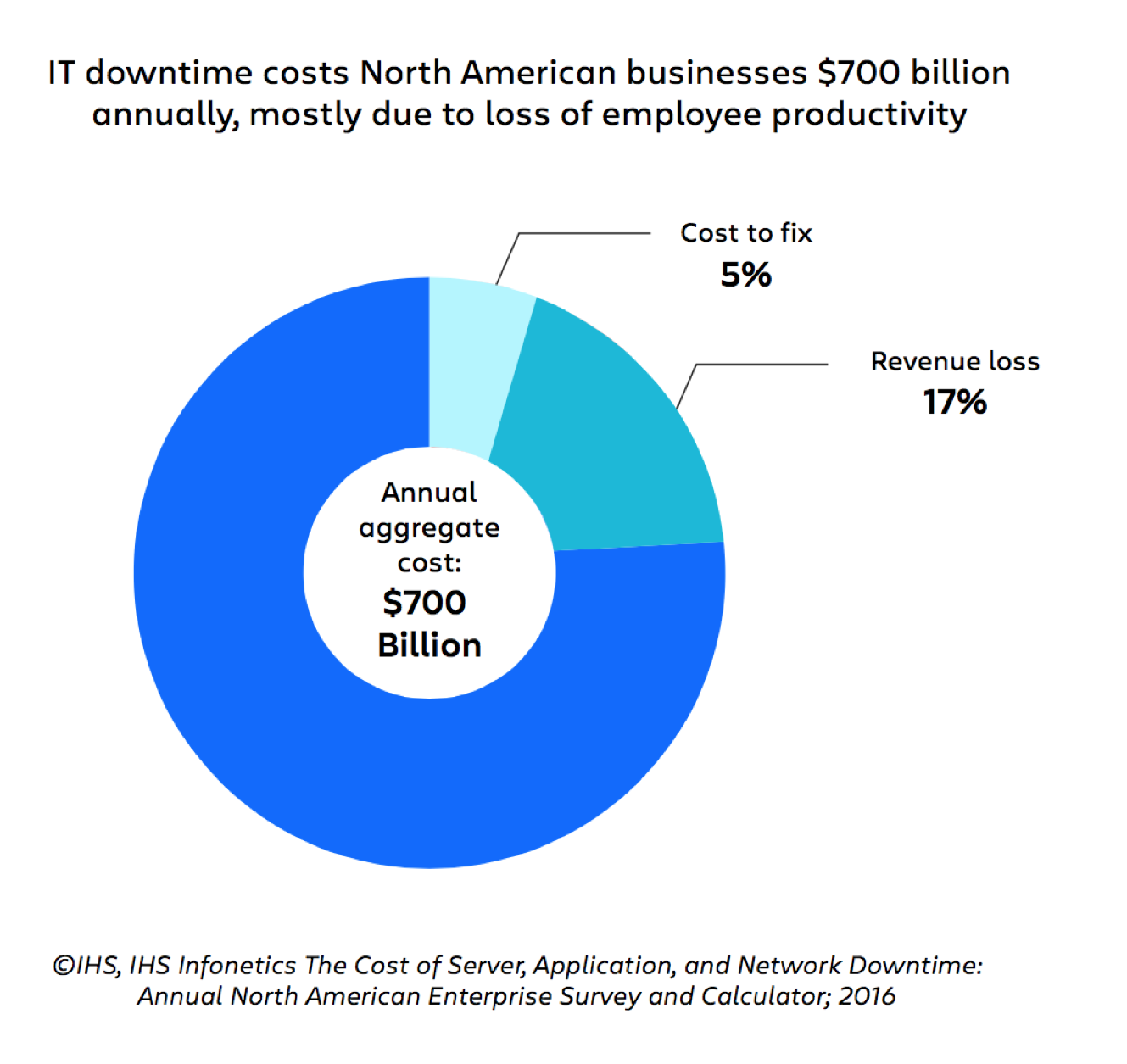
Números como estes deixam claro que a perda de receita não é a única—ou mesmo a mais importante—prioridade para o gerenciamento de incidentes. Um processo otimizado de gerenciamento de incidentes também precisa enfrentar os desafios muito reais e muito caros das pessoas, processos e tecnologia por trás do gerenciamento de incidentes.
Os desafios enfrentados pelo moderno gerenciamento de incidentes de TI
Processos e tecnologias desconectados
Um efeito colateral de 40 anos de inovação em computação é que muitas empresas agora operam uma mistura eclética de aplicações e sistemas. Algumas aplicações vivem nos próprios data centers, onde podem ser bem controladas, enquanto outras são entregues no Cloud e gerenciadas por provedores terceirizados.
Essa coleção de aplicações, serviços e sistemas resulta com frequência em um patchwork de soluções e processos para registro, monitoramento e alertas. Não é incomum que empresas utilizem dezenas de ferramentas de monitoramento para acompanhar milhares de eventos de aplicações ou alertas todos os dias.
Esta abordagem de patchwork pode levar a um volume esmagador de alertas, uma falha na comunicação, uma falta de prioridade clara para os funcionários de plantão e uma situação em que uma falha em uma etapa deste processo de patchwork pode derrubar tudo.
Um volume esmagador de alertas/incidentes
Muitos departamentos de operações de TI direcionam alertas em caixas de e-mail para neutralizar seu problema de volume. Mas essa prática só piora as coisas, criando uma situação em que o e-mail requer monitoramento 24 horas por dia pela equipe de nível superior responsável por priorizar incidentes e escalar mensagens críticas.
Este fluxo interminável de alertas pode ser esmagador e levar a fadiga de alertas, esgotamento, insatisfação no trabalho, ansiedade e tempos de resposta mais longos. Ele afeta tanto o bem-estar dos funcionários no local de trabalho quanto a produtividade, o que afeta os resultados dos negócios.
Aumento dos custos de operações
Embora os custos com infraestrutura tenham diminuído, os custos de operações aumentaram—impulsionados, em parte, pela complexidade dos itens de depuração quando você não controla todo o sistema.
Medição das métricas de sucesso erradas
O sucesso das operações da central de atendimento tem sido medido com métricas como transferência de chamadas e duração média de chamada – nenhum dos quais contribui ou mede diretamente a eficácia do gerenciamento de incidentes.
Mesmo métricas úteis como MTTR e MTBF não são o bastante para aprimorar o desempenho do gerenciamento de incidentes. Elas estão lá para nos ajudar a identificar um item, mas não podem responder às perguntas mais rígidas e qualitativas de por que e como os incidentes ocorrem e são resolvidos e como melhorar essas métricas.
Estruturas da equipe de resposta a incidentes desatualizadas
Até a última década, responder a incidentes de TI era o principal trabalho das equipes de operações. As empresas costumavam a implementar uma estrutura de equipe em níveis (nível 1, nível 2, nível 3) para responder a itens relatados por clientes ou ferramentas de monitoração.
Lá atrás, os objetivos do gerenciamento de incidentes eram os mesmos: minimizar custo operacional, mantendo o nível do serviço. Por causa disso, os respondentes de nível 1 eram funcionários de nível básico de baixo custo. Se eles não pudessem resolver um incidente, eles escalonavam para o nível 2 (geralmente profissionais mais experientes, de nível médio). Este processo de escalonamento continuaria até que o item fosse resolvido.
Enquanto este processo prioriza economia de custos, ele o faz às custas da agilidade. O tempo de resposta mais lento de uma equipe que inicia incidentes com funcionários de nível básico e requer vários níveis de escalonamento pode ter um impacto imediato nos cronogramas de resolução de incidentes, que afetam diretamente a reputação da empresa à medida que a frustração do cliente se espalha pelos canais de mídia social.
Além disso, com empresas perdendo 78% de seus dólares de gerenciamento de incidentes com produtividade de funcionários, é bem claro que um modelo de escalonamento não economiza dinheiro da empresa. Se a pessoa que criou o software pode corrigir o bug em 15 minutos e o funcionário de nível de entrada gasta duas horas e precisa escalonar o problema ao próximo nível, esse sistema não é eficiente.
Em um mundo de serviços sempre disponíveis, agilidade se tornou mais importante que nunca. Métricas como tempo médio de resposta e tempo médio para resolução ganharam tração porque as empresas precisam maximizar a agilidade se quiserem reduzir custo.
Como otimizar seu processo de gerenciamento de incidentes de TI
Está claro que é hora de reorientar os esforços de gerenciamento de incidentes com processos, estruturas de equipe e práticas que reflitam as novas realidades de negócios de hoje. Mas como é esse processo de reorientação?
Priorizar e consolidar alertas
O principal culpado pela fadiga de alerta e um contribuinte essencial para a perda de produtividade é um excedente de alertas sem sentido e não acionáveis. A correção mais simples? Identificar sistemas críticos, remover a duplicação de notificações redundantes e criar uma hierarquia de priorização clara para alertas.
Criar um cronograma de plantão que funcione para suas equipes
Evitar fadiga de alerta, esgotamento e ineficiências também é criar um cronograma de plantão que funcione para as equipes. É não sobrecarregar nenhuma pessoa ou equipe, oferecer suporte de backup onde necessário e reavaliar a eficácia do cronograma com frequência.
Automatizar onde é possível
É fácil perder o foco quando você está fazendo a revisão manual de dezenas de relatórios para identificar e escalar os que importam. A boa notícia é que esse processo não precisa mais ser manual por um membro da equipe e você pode evitar a perda de produtividade e fadiga de alertas removendo essa etapa da lista de tarefas por meio da automação.
Encaminhamento de alertas, notificação, desduplicação, fluxos de trabalho de mensagens, criação de ponte de conferência, atualizações da página de status, cronogramas de plantão, processos de escalonamento e rastreamento de KPI também podem ser totais ou parcialmente automatizados para economizar tempo da equipe e reduzir erros humanos em tarefas repetitivas definidas. Sem falar que a automação economiza dinheiro da empresa ao longo do tempo.
Estabelecer comunicação eficaz com canais e partes interessadas
Os incidentes afetam diversas partes interessadas – muitas vezes internas e externas – e essas partes interessadas precisam ser informadas. Estudos mostram que 87% das partes interessadas da empresa querem atualizações sobre incidentes (e 56% estão mais frustradas pela falta de comunicação do que pelo próprio incidente). E os clientes com certeza sentem o mesmo.
Em uma época em que a expectativa é disponibilidade ininterrupta, ter um plano de comunicação de incidentes sólido é uma peça vital do quebra-cabeça de otimização.
Facilitar o acompanhamento das métricas certas
Quanto mais fácil for rastrear e analisar as métricas de sucesso, maior será a probabilidade de que a equipe possa ficar em dia com elas. Automatize os relatórios sempre que possível e deixe claro quais métricas importam para sua equipe e por quê.
Realizar análises retrospectivas sem atribuição de culpa
Um incidente não acabou apenas porque o aplicativo ou o banco de dados voltou a ficar on-line. Para evitar incidentes, reduzir o tempo gasto em incidentes futuros e entender melhor como os processos, equipes e políticas estão afetando o gerenciamento de incidentes, você precisa realizar análises retrospectivas.
Na Atlassian, as análises retrospectivas não buscam culpados, o que significa que elas se concentram em melhorar o desempenho e seguir adiante — não encontrar alguém para culpar.
Escolha a tecnologia que ofereça suporte aos seus processos e necessidades
Automação. Priorização de alertas. Cronogramas de plantão. Acompanhamento de KPI. Para ser eficaz, cada um desses processos essenciais precisa de tecnologia que os apoie. Antes de escolher a tecnologia, entenda as metas, os processos e as necessidades da equipe. Se você quer organizar, desduplicar e priorizar automaticamente os alertas, você precisa de uma solução que tenha essas funções — uma solução como o Jira Service Management.
Aprenda a comunicação de incidentes com o Statuspage
Neste tutorial, você vai ver como usar templates de incidentes para se comunicar com eficácia durante interrupções. Adaptável a muitos tipos de interrupção de serviço.
Leia este tutorialExemplos e templates de comunicação de incidentes
Ao responder a um incidente, os templates de comunicação são inestimáveis. Veja os templates que as equipes usam e mais exemplos de incidentes comuns.
Leia este artigo