Zarządzanie incydentami dla dynamicznych zespołów
Wybór KPI oraz innych wskaźników w przypadku zarządzania incydentami
Śledzenie i stopniowe doskonalenie zarządzania incydentami
W dzisiejszym świecie ciągłej dostępności incydenty techniczne mają poważne następstwa.
Biorąc pod uwagę utratę przychodów, spadek wydajności pracowników i opłaty związane z pracami serwisowymi, przestój systemu kosztuje firmy średnio 300 000 USD za godzinę. W przypadku poważnych awarii te koszty znacznie wzrastają (wystarczy wspomnieć awarię systemów IT w 2017 roku, która kosztowała firmę Delta Airlines około 150 mln USD). A klienci, którzy nie mogą opłacić rachunków, skorzystać z wideokonferencji, aby odbyć ważne spotkanie, czy kupić biletu lotniczego, szybko przeniosą się do konkurencji.
Przy tak dużej stawce obecnie szczególnie ważne jest dla zespołów śledzenie wskaźników KPI związanych z zarządzaniem incydentami i wykorzystywanie wypływających z nich wniosków do wykrywania, diagnozowania i usuwania incydentów, a ostatecznie także do zapobiegania ich występowaniu.
Dobra wiadomość jest taka, że w przypadku incydentów związanych ze środowiskami sieciowymi i oprogramowaniem (w przeciwieństwie do systemów mechanicznych i pracujących w trybie offline) zespoły mogą zazwyczaj zarejestrować znacznie więcej danych, które pomogą im lepiej zrozumieć incydent i udoskonalić działania.
Jest też zła wiadomość. Czasami nadmiar danych może maskować problemy, zamiast je uwydatniać.
Wartość KPI oraz innych wskaźników i analiz dotyczących incydentów
Kluczowe wskaźniki wydajności (KPI) pomagają firmom ustalić, czy udaje im się osiągać określone cele. W przypadku zarządzania incydentami takimi wskaźnikami mogą być: liczba incydentów, średni czas rozwiązywania lub średni czas między incydentami.
Śledzenie wskaźników KPI związanych z zarządzaniem incydentami może pomóc w identyfikacji i diagnozowaniu problemów z procesami i systemami, wyznaczaniu poziomów odniesienia i realistycznych celów dla zespołu, a także dostarczać punktu wyjścia przy poszukiwaniu odpowiedzi na bardziej złożone pytania.
Załóżmy na przykład, że celem Twojej firmy jest rozwiązywanie wszystkich incydentów w ciągu 30 minut, ale obecna średnia zespołu wynosi 45 minut. Bez konkretnych wskaźników trudno powiedzieć, na czym polega problem. Czy na poziomie systemu obsługi alertów pojawia się zwłoka? Czy proces jest wadliwy? Czy Twoje narzędzia diagnostyczne wymagają aktualizacji? Czy problem tkwi w zespole, czy w technologii?
Teraz dodaj kilka wskaźników. Jeśli wiesz dokładnie, jak długo trwa przetwarzanie w systemie obsługi alertów, możesz zidentyfikować to jako problem lub wykluczyć. Jeśli widzisz, że ponad 50% czasu zajmuje diagnostyka, możesz skoncentrować się na usprawnieniu tego obszaru. Jeśli stwierdzasz, że zespół B pracuje o 25% wolniej od zespołów A, C i D, możesz zacząć szukać przyczyny.
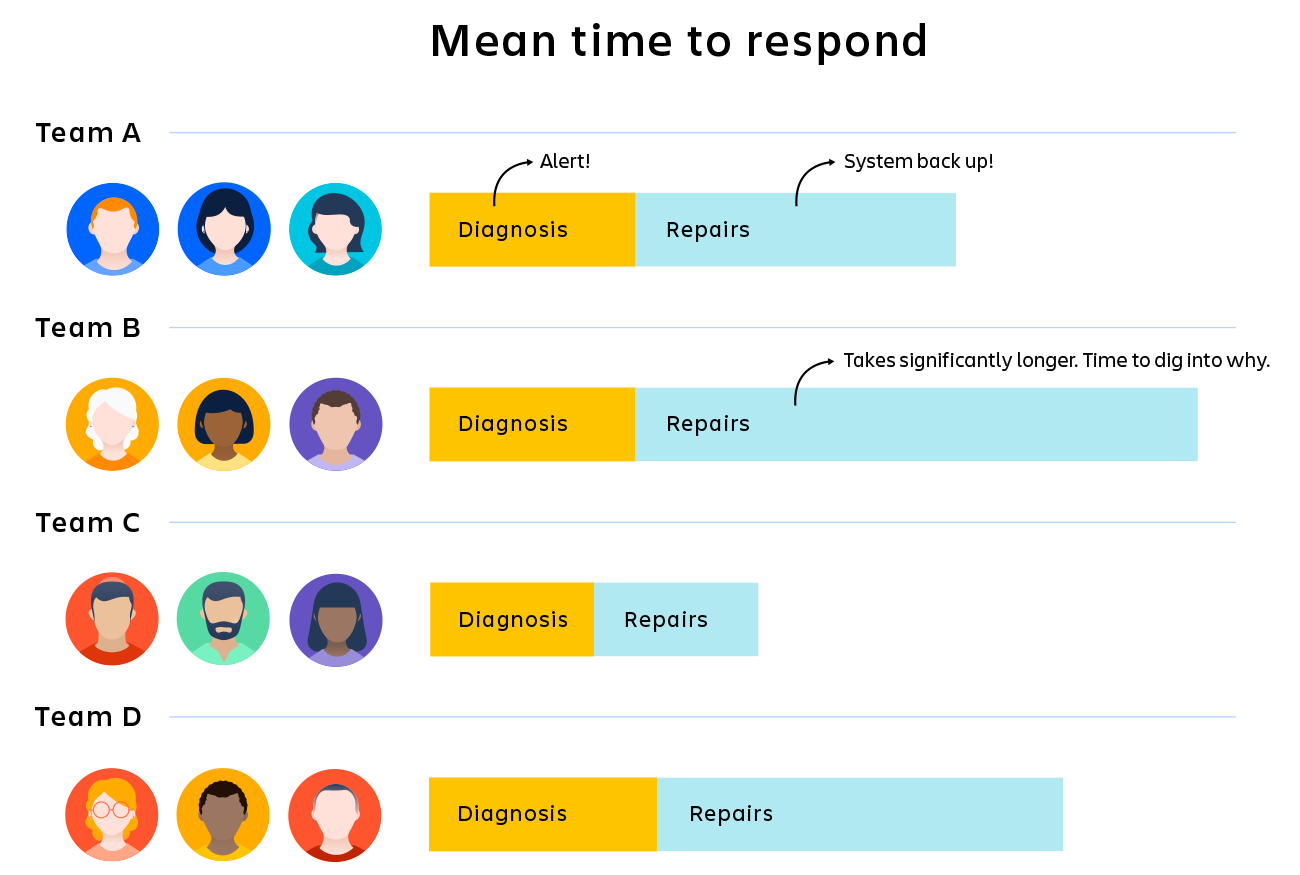
Wskaźniki KPI nie naprawią automatycznie Twoich problemów, ale pomogą zrozumieć ich przyczyny i skupić energię na zagłębianiu się we właściwych obszarach.
Popularne KPI oraz inne wskaźniki dotyczące incydentów
Liczba utworzonych alertów
Jeśli korzystasz z narzędzia do obsługi alertów, dobrze jest wiedzieć, ile alertów generuje system w danym okresie. Rozwiązanie, takie jak Jira Service Management, pozwala zarówno wysyłać alerty, jak i opracowywać raporty oraz pulpity umożliwiające ich śledzenie.
Zwróć uwagę na okresy, w których występują istotne i nietypowe wzrosty lub spadki albo nagłe zmiany trendów, a w razie ich zaobserwowania przeanalizuj przyczyny takich zmian i zastanów się, w jaki sposób zespół może się z nimi uporać.
Liczba incydentów na przestrzeni czasu
Śledzenie liczby incydentów na przestrzeni czasu oznacza przyjrzenie się średniej liczbie incydentów w konkretnym okresie. Może to być tydzień, miesiąc, kwartał, rok, a nawet dzień.
Czy z czasem częstotliwość incydentów wzrasta, czy maleje? Czy liczba incydentów utrzymuje się na dopuszczalnym poziomie, czy mogłaby być niższa? Po zidentyfikowaniu problemu z liczbą incydentów możesz przystąpić do zadawania pytań na temat przyczyn wzrostu tej liczby lub utrzymywania się jej na wysokim poziomie, a także zastanowić się, co zespół może zrobić, aby rozwiązać ten problem.
MTBF
MTBF (średni czas między awariami) to średni czas między awariami produktu technologicznego, które można naprawić. Ten wskaźnik może być przydatny przy śledzeniu dostępności i niezawodności produktów.
Podobnie jak w przypadku innych wskaźników, jest to dobry punkt wyjścia do zastanowienia się nad bardziej złożonymi kwestiami. Jeśli wskaźnik MTBF jest niższy niż pożądany, trzeba się zastanowić, dlaczego systemy tak często ulegają awarii i w jaki sposób można obniżyć ich liczbę lub zapobiec ich występowaniu w przyszłości.
MTTA
MTTA (średni czas uzyskania potwierdzenia) to średni czas, który upływa między wygenerowaniem alertu systemowego, a potwierdzeniem incydentu przez członka zespołu i przystąpieniem do prac nad jego rozwiązaniem. Na tej podstawie możesz dowiedzieć się, na ile sprawnie zespół reaguje na zgłoszenia.
W razie stwierdzenia problemów z szybkością reakcji możesz ponownie zacząć głębiej przyglądać się problemowi. Dlaczego Twój wskaźnik MTTA jest wysoki? Czy zespoły są nadmiernie obciążone pracą? A może coś je rozprasza? Czy nie wiadomo dokładnie, kto odpowiada za alert? Wskaźnik MTTA umożliwia rozpoznanie problemu, a udzielenie odpowiedzi na tego rodzaju pytania ułatwiają dotarcie do jego sedna.
MTTD
MTTD (średni czas wykrycia) to średni czas potrzebny zespołowi na odkrycie problemu. Ten termin często stosuje się w cyberbezpieczeństwie, gdy zespoły są skoncentrowane na wykrywaniu ataków i naruszeń.
Jeśli ten wskaźnik drastycznie się zmienia lub nie jest do końca zgodny z oczekiwaniami, raz jeszcze należy sobie zadać pytanie, dlaczego.
MTTR
MTTR może oznaczać średni czas naprawy, rozwiązywania, reakcji lub odzyskiwania. Prawdopodobnie najbardziej przydatnym spośród tych wskaźników jest średni czas rozwiązywania, który pozwala śledzić nie tylko czas poświęcony na diagnostykę i naprawę problemu, ale także czas spędzany na upewnieniu się, że problem się nie powtórzy. Jak wskazuje program badań DevOps Research and Assessment (DORA), odzyskiwanie jest podstawowym wskaźnikiem DevOps pozwalającym mierzyć stabilność zespołu DevOps.
Ten wskaźnik również najlepiej sprawdza się w celach diagnostycznych. Czy problemy są rozwiązywane tak szybko i skutecznie, jak tego oczekujesz? Jeśli nie, trzeba sobie zadać bardziej złożone pytania o to, dlaczego właściwie wskaźnik nie spełnia oczekiwań i jakie są przyczyny takiego stanu rzeczy.
Jak wskazuje programie badań DevOps Research and Assessment (DORA), odzyskiwanie jest kluczowym wskaźnikiem DevOps pozwalającym mierzyć stabilność zespołu DevOps. Jest to całkowity czas potrzebny na wykrycie problemu, ograniczenie jego skutków i jego rozwiązanie.
Czas dyżurów domowych
Jeśli stosujesz rotację dyżurów domowych, przydatne może być śledzenie ilości czasu, który pracownicy oraz podwykonawcy spędzają na dyżurach domowych.Dzięki temu zyskasz pewność, że żaden pracownik ani żaden zespół nie jest nadmiernie obciążony pracą.
Korzystając z narzędzia, takiego jak Jira Service Management, możesz wygenerować kompleksowe raporty, które pozwolą błyskawicznie sprawdzić te wskaźniki.
SLA
Umowa o gwarantowanym poziomie świadczenia usług (SLA) to umowa między dostawcą a klientem określająca wymierne wskaźniki, takie jak czas dostępności, szybkość reakcji i obowiązki.
Zobowiązywania zawarte w umowach SLA (dotyczące dostępności, średniego czasu odzyskiwania itp.) stanowią jedną z przyczyn, dla których zespoły zarządzające incydentami muszą śledzić te wskaźniki. Jeśli lub gdy wskaźniki, takie jak średni czas reakcji lub średni czas między awariami, ulegną zmianie, należy zaktualizować umowy i/lub wprowadzić poprawki — i to szybko.
SLO
Docelowy poziom świadczenia usług (SLO) to wchodzące w skład umów SLA uzgodnienie dotyczące konkretnych wskaźników, takich jak czas dostępności. Podobnie jak sama umowa SLA, poziomy SLO również są ważnymi wskaźnikami, których śledzenie pozwala zyskać pewność, że firma dotrzymuje warunków umowy, jeśli chodzi o obsługę klienta.
Znaczniki czasu (lub oś czasu)
Znacznik czasu jest zakodowaną informacją na temat tego, co zdarzyło się w określonym czasie przed incydentem, w trakcie jego trwania lub po jego zakończeniu. Informacji tych nie traktuje się zazwyczaj jako wskaźnika, jednak są to ważne dane uwzględniane przy ocenie stanu zarządzania incydentami i opracowywaniu strategii poprawy.
Znaczniki czasu pomagają zespołom w tworzeniu osi czasu incydentów z uwzględnieniem działań poprzedzających incydent oraz prac podejmowanych w reakcji na jego wystąpienie. Przejrzysta, udostępniona oś czasu jest jednym z najbardziej przydatnych artefaktów podczas analizy post-mortem incydentu.
Czas działania
Dostępność jest to ilość czasu (wyrażona w formie wartości procentowej), przez który systemy są dostępne i działają prawidłowo.
Rosnący poziom łączności usług internetowych oraz postępująca złożoność samych systemów oznaczają, że praktycznie nie istnieje coś takiego, jak gwarancja dostępności na poziomie 100%. W przypadku większości produktów celem jest zapewnienie wysokiej dostępności, czyli udostępnienie systemu lub produktu, który działa prawidłowo bez zakłóceń przez długi czas. W branży przyjmuje się, że bardzo dobrym wynikiem jest dostępność na poziomie 99,9%, a wynik na poziomie 99,99% jest doskonały.
Wykorzystywanie tego wskaźnika do oceny skuteczności własnych działań sprowadza się właściwie do składania deklaracji klientom oraz ich dotrzymywania. Jednak podobnie jak w przypadku innych wskaźników, ten również stanowi jedynie punkt wyjścia. Jeśli nie osiągasz dostępności na poziomie 99,99%, ustalenie przyczyny będzie wymagało przeprowadzenia większej liczby badań, rozmów z zespołem oraz analiz procesu, struktury, dostępu lub technologii.
Przestroga dotycząca analizy incydentów
Wadą wskaźników KPI jest skłonność do nadmiernego polegania na pobieżnych danych. Uzmysłowienie sobie, że Twój zespół nie rozwiązuje incydentów dostatecznie szybko, samo w sobie nie naprawi problemu. Wciąż musisz się dowiedzieć, jak oraz dlaczego zespół rozwiązuje problemy lub tego nie robi. Musisz też dowiedzieć się, czy problemy, które porównujesz, faktycznie da się ze sobą porównać.
Na podstawie wskaźników KPI nie dowiesz się, w jaki sposób Twoje zespoły radzą sobie z trudnymi problemami. Wskaźniki nie wyjaśniają również, dlaczego czas między incydentami się skraca, zamiast wydłużać. Nie dadzą również odpowiedzi na pytanie, dlaczego incydent A trwał trzy razy dłużej od incydentu B.
Do tego potrzebujesz analiz. Choć dane mogą stanowić dobry punkt wyjścia do przeprowadzania tych analiz, mogą być również przeszkodą. Mogą dawać nam złudne poczucie, że robimy wystarczająco dużo, nawet jeśli nasze wskaźniki nie ulegają poprawie. Mogą sprzyjać wrzucaniu do jednego worka incydentów, które w rzeczywistości drastycznie się od siebie różnią i należy podejść do nich w odmienny sposób. W efekcie grozi to ignorowaniem doświadczenia swoich zespołów oraz samych złożonych sytuacji będących przyczyną incydentów.
„Incydenty są znacznie bardziej unikatowe, niż zazwyczaj się przyjmuje. Dwóm incydentom trwającym tyle samo mogą towarzyszyć drastycznie odmienne poziomy zaskoczenia i niepewności w procesie ustalania przebiegu zdarzenia. Może charakteryzować je również skrajnie różny poziom ryzyka związanego z podejmowaniem czynności w celu złagodzenia ich skutków lub poprawy sytuacji. Incydenty nie są produkowanymi gadżetami, w których kluczowymi wskaźnikami jakości są ograniczone wariacje wymiarów fizycznych”.
— John Allspaw, Moving Past Shallow Incident Data (Wychodzenie poza pobieżne dane o incydentach)
Nie chodzi o to, że wskaźniki KPI są złe. Zdecydowanie nie należy wylewać dziecka z kąpielą. Chodzi o to, że same wskaźniki KPI to za mało. Stanowią one punkt wyjścia. Są narzędziem diagnostycznym. Są pierwszym krokiem na bardziej złożonej drodze do autentycznej poprawy.
Jira Service Management oferuje funkcje raportowania, dając Twojemu zespołowi możliwość śledzenia wskaźników KPI oraz monitorowania i optymalizacji praktyki zarządzania incydentami.
Konfigurowanie harmonogramu dyżurów domowych za pomocą Opsgenie
W tym samouczku nauczysz się konfigurować harmonogram dyżurów domowych, stosować reguły zastępujące, ustawiać powiadomienia o dyżurach domowych oraz wykonywać inne czynności w Opsgenie.
Przeczytaj ten samouczekSzablony i przykłady informowania o incydentach
Podczas reagowania na incydent szablony komunikatów są nieocenione. Pobierz szablony, z których korzysta nasz zespół, a także inne przykłady dotyczące częstych incydentów.
Przeczytaj ten artykuł