

Here’s a way to build a bridge that never fails: Drain the river and fill it in with concrete.
Expensive, ugly, and stupid. But it’s certainly fail-proof.
This is a really simplified version of the problem web developers face when aiming to build high availability services. We’ve talked about the increasingly-interconnected nature of cloud tools and the domino-goes-crashing-down effect that can happen when just one critical service has downtime. Web uptime is more important than ever, and it’s critical that these services we all rely on are up and running as often as possible.
What is high availability?
High availability refers to a system or component that is operational without interruption for long periods of time.
High availability is measured as a percentage, with a 100% percent system indicating a service that experiences zero downtime. This would be a system that never fails. It’s pretty rare with complex systems. Most services fall somewhere between 99% and 100% uptime. Most cloud vendors offer some type of Service Level Agreement around availability. Amazon, Google, and Microsoft’s set their cloud SLAs at 99.9%. The industry generally recognizes this as very reliable uptime. A step above, 99.99%, or “four nines,” as is considered excellent uptime.
But four nines uptime is still 52 minutes of downtime per year. Consider how many people rely on web tools to run their lives and businesses. A lot can go wrong in 52 minutes.
So what is it that makes four nines so hard? What are the best practices for high availability engineering? And why is 100% uptime so difficult?
These are just a few of the questions we’ll aim to answer here in our guide to high availability.
With great complexity comes great responsibility
Imagine a set of concrete steps in your neighborhood. With some simple maintenance and upkeep, and barring some dramatic change to their environment, those stairs will basically last forever. The historic “uptime” of that set of stairs is excellent. We still use stairs today that were constructed thousands of years ago and have rarely, if at all, been “unavailable.”
Now imagine an escalator. You’ve got a product solving the same problem as the stairs (getting people up and down) with some great added features and benefits (the product burns energy, not the user). And you’ve got all the variables the stairs face (regular use, environmental conditions) along with a whole stack of new variables; moving parts, power sources, belts, gears, lubricants.
It’s easy to see what product will have stronger uptime. The escalator will need to come offline for regular repair and maintenance. Sometimes it will just plain break down. Eventually, the whole system will need to be replaced. The best escalator engineers in the world can’t build an escalator with the same uptime as stairs. It’s not even worth trying. The best way to keep an escalator running as often as possible is to intentionally take it offline for routine maintenance.
You can think of web services the same way. Adding complexity can lead to some great features and benefits, but it decreases the chance for extreme uptime. An average engineer can build a static web page with a few pieces of text that enjoys much higher uptime than Facebook. Even though Facebook has a bunch of engineers and other resources, they’re dealing with way more complexity.
Building for high availability comes down to a series of tradeoffs and sacrifices. Complexity vs. simplicity is one of the first decisions someone needs to make when considering building for high availability.
Eliminate single points of failure
One of the foundations of high availability is eliminating single points of failure. A single point of failure is any component of the system which would cause the rest of the system to fail if that individual component failed.
The first example of this is load balancing between multiple servers. Users send traffic and it gets served by either server 1 or server 2. The load balancer detects when server 1 is offline and sends all traffic to server 2. Something like this:
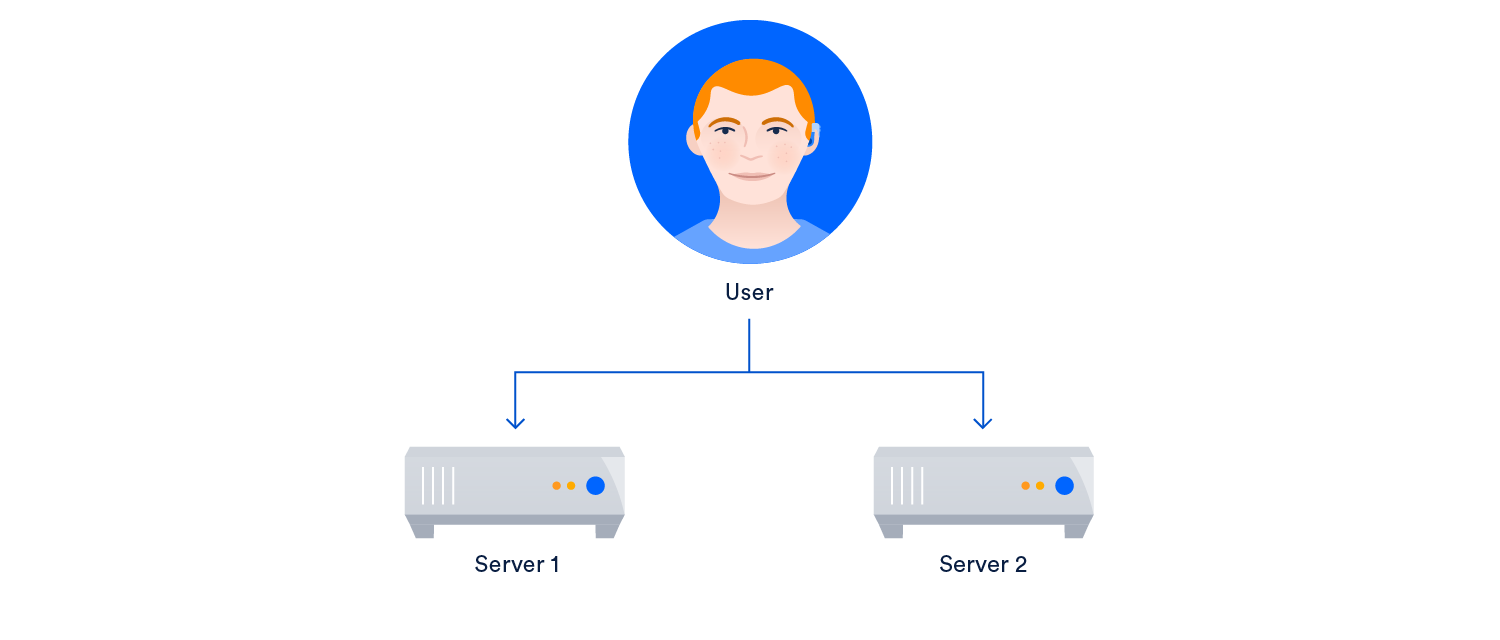
This eliminates a single point of failure, but it’s far from perfect. If server 1 fails, we need a way to monitor for failures and direct traffic to the backup if there’s a problem. That’s where a load balancer comes in and sits between the users and the servers.
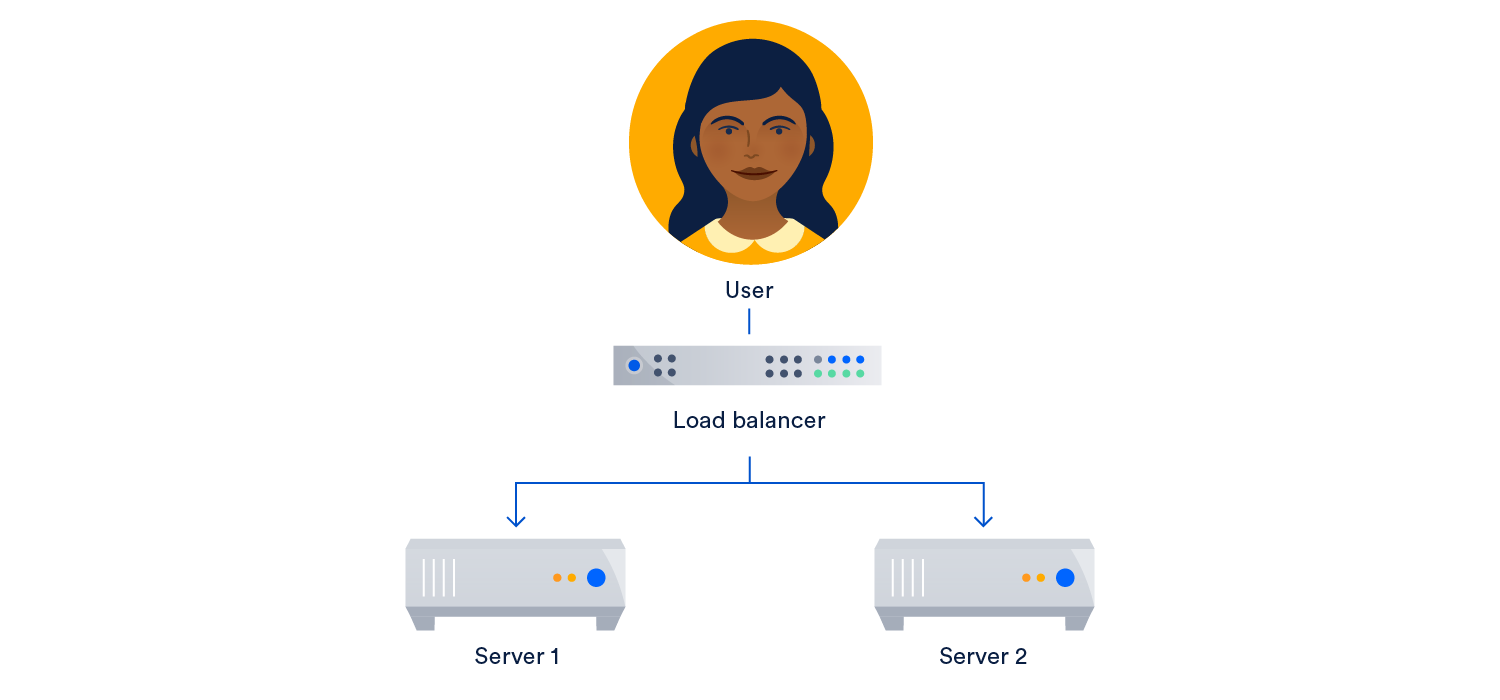
The most common strategy for failure monitoring and detection on redundant systems is this top-to-bottom technique. Here the top layer (in this case, the load balancer) does the work of monitoring the layer below. If a problem is detected, the load balancer redirects traffic to server 2.
But now we have a new version of the same problem we started with: a single point of failure. What happens if our load balancer fails? We could get around it by adding another load balancer in the top layer, which would look something like this:

Of course now there’s a new problem. Failover to a redundant load balancer involves a DNS change. This can take a while. The solution would be to add a tool that allows for rapid IP remapping, such as Elastic IP.
This will automatically create a static IP address that floats between the load balancers. If one is unavailable, traffic will be handled by the other load balancer.

This setup is the foundation of how most teams are building for high availability. Below the servers may be databases and more servers. You may have more redundancies and more backup tools throughout the stack. But the basics of high availability infrastructure are going to look something like this.
Consistency vs. reliability
With distributed, redundant systems like this, the trick becomes balancing availability and consistency. For more on this, explore the CAP Theorem.
The problem is that the more database servers you’re utilizing, the more likely it is that one of those backups isn’t a mirror image of the other at a given point in time. You might have great availability by backing up to another server or database, but if that backup delivers old data to your end users, you might have a bigger problem on your hands than downtime.
This is why we all like to tolerate a little downtime. If the alternative is logging in and seeing the wrong version of your data, downtime doesn’t seem so bad.
Other high availability tools and tips
Multiple geographic zones
To optimize for high availability, it’s worth considering hosting in multiple geographic zones. When an outage on a server occurs and impacts your system, there’s a better chance of availability on servers distributed geographically.
The February 2017 AWS outage showed the huge impact one region can have when it goes down.
Microservices
So far we’ve talked about infrastructure as one self-contained system, where everything across your application fits neatly into one structure. This is the simplest way to manage things, but mean all your eggs are in this one basket.
The push toward micro-services helps alleviate some of that. This means breaking the different functions of an application down into individual systems that be integrated with each other. If any one piece has downtime, the entire application will only be partly impacted.
But, again, this comes with tradeoffs. Adding micro-services means adding operational complexity. You have different services to deploy and monitor, more back-end tooling to spin up, more engineering resources to keep everything humming.
For more on microservices, check out this presentation from Netflix.
Overengineering and bad processes
It’s tempting to solve every availability desire by over-engineering the problem. You could set up an endless fortress of servers, backups, and redundancies. You could bleed your organization dry by throwing every dollar at chasing 100% uptime.
But the further down the uptime rabbit hole you go, the more complexity and time you add, and the harder it becomes to realize a tangible benefit. Pretty soon, you’re filling the river with concrete. Going from two nines to four nines is a lot simpler than going from four nines to six nines, which is easier still than six nines to seven nines. At some point, you see diminishing benefit from chasing availability.
Another thing to note is that most downtime is an issue of human error, people pushing bad code, rather than faulty architecture. The simplest way to avoid downtime may be to implement better processes for testing and managing changes, for tracking errors and addressing bugs. Measure twice, cut once.
Striking the right balance
In a perfect world, all complex applications would be available every minute of every day. However, in reality, no company is perfect and instead needs to make important decisions when it comes to the complexity/availability trade-off. To help guide these decisions, it can be helpful to ask a few questions when you’re deciding on the trade-offs. Here are a few examples:
- How will my customers react if my application is down for 5 minutes? 10 minutes? 1 hour? 3 hours? 24 hours? Multiple days?
- What percentage of my customer base or revenue will I lose at those same intervals?
- What will my customers accept as maintenance intervals? Once a month? Once a year?
- What specifically is the added value of taking on more infrastructure complexity? Capacity for more users? Faster response times? More revenue?
- How does that value compare to the risks we are taking on with additional complexity? On a scale of 1-10, how comfortable are we with those risks?
- Do we have the right folks working here to operationalize and scale the project(s)?
- If our systems do go down, do we have a solid incident management process to handle incidents and communicate with users during downtime?
The answers to these questions will always be specific to the company, customers, and the moment in time. Take Twitter and StatusPage as examples. We all remember the so-called fail whale in Twitter’s early years when it seemed that the site couldn’t go more than a day without experiencing downtime. There’s a good chance Twitter prioritized features for early users over high availability.
On the other hand, If StatusPage went down on a daily basis in our first year, we wouldn’t be around today to write this blog post. For us, having a highly available system was a first principle in order for us to have any chance of success in the future.
This post was originally published on the Statuspage blog in 2016.

