

If there ever was a day it felt like the entire internet ground to a halt, it was Feb. 28.
Amazon’s S3 storage service went down in its US-EAST-1 Region for the better part of 4 hours, causing a lot of prominent web sites and services to not function. For a service that powers a huge amount of the web and promises its customers 99.9% uptime, it was a very unusual outage. The last blip in S3’s normally stellar uptime was an outage in August 2015.
The venting, and jokes, started pouring in on Twitter.
As easy as it can be to poke fun at incidents like this, it’s important to remember wide-scale downtime can have negative effects for a lot of people. From the hard-working AWS engineers, to the developers who build on AWS, to everyone trying to use web tools for getting through their day, we all felt the pain yesterday.
For Statuspage, days like this are why we exist: to help keep teams and users in the loop during downtime. But it wasn’t a perfect day for us, either. While our core services — the ability to serve status pages, create incidents, update status, and send notifications – we’re running, we host the majority our CSS and images on S3. This meant, in short, a lot of status pages we host didn’t look quite right and in many cases, were slow to load. We’ll be using the incident as a learning opportunity and will be working on implementing asset hosting redundancies to serve our customers better in the future.
What the day showed for us, though, was how much people rely on communication in times of crises. When Twitter becomes the water cooler for incidents like this, Statuspage becomes the war room.
The explosion of communication
Whenever a notable web service provider has an outage, we see spikes in traffic to customer pages and users logging in to create incidents. When it’s something as foundational to the internet as AWS, we see a thundering herd.
Thousands of our customers use Amazon to host their tech. On Tuesday we got a unique vantage into just how critical Amazon S3 is to the web. Here are some numbers on the scope of the outage Tuesday from our perspective:
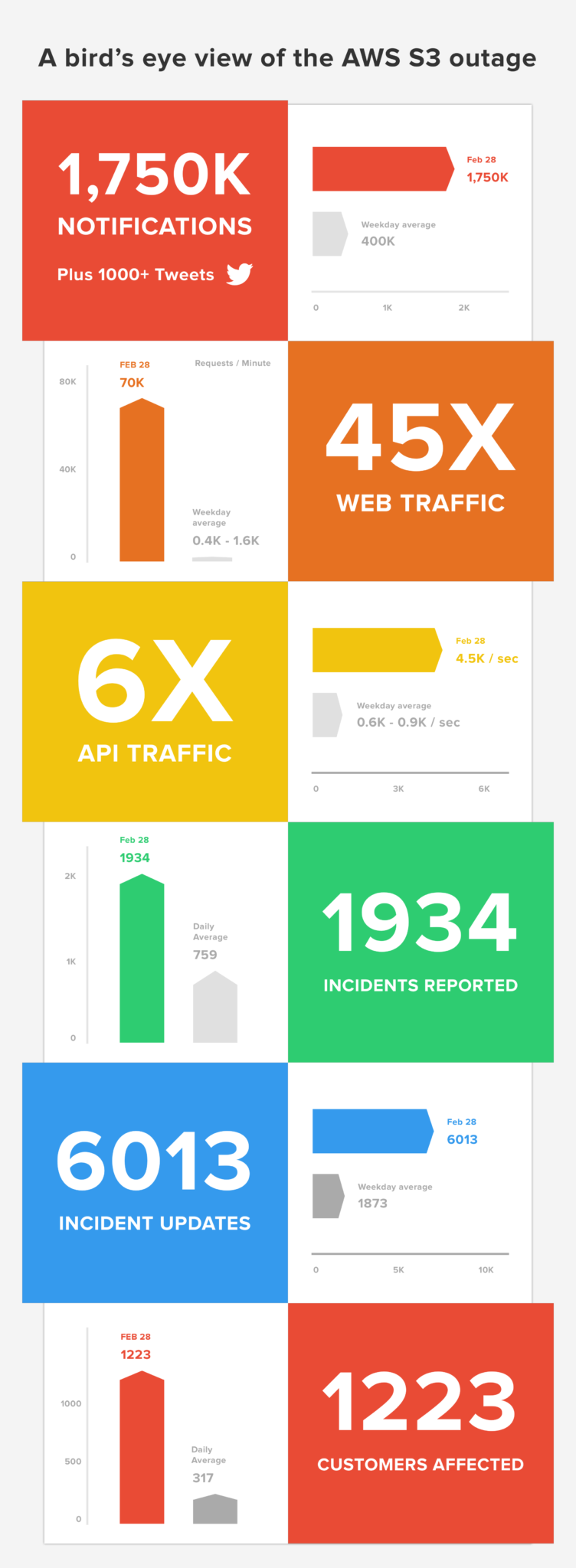
All of the moving parts in an incident are pretty complex, but the reason behind the surge of activity on our service is simple: people, and specifically customers of SaaS products, need to know what’s going on during incidents. Our customers used Statuspage to help their teams and users know what was going on, why they were experiencing issues, and when a fix was expected.
What was great about this particular case is that no one of our customers was the official source of info on this outage. Only AWS knew the exact root cause and when things would be up and running again. But all these Statuspage users didn’t just sit back and adopt a “someone else’s problem” attitude while their users suffered. Instead, these teams took action and kept their stakeholders in the loop as best they could, even if that meant not knowing the whole picture themselves sometimes. We’re proud of these teams for doing the right thing and keeping their communities informed.
Creating an incident communication plan
All that said, we still see a lot of people scramble to keep up when an incident like this happens. When you haven’t thought through your incident response plan, it’s easy to get buried in inbound support tickets when the big incident hits. There doesn’t need to be a major cloud outage for proper incident response to come in handy. While Tuesday outage was very high profile, we know there are smaller scale outages every day and that no software provider is immune from downtime. As we saw, even services as robust as Amazon are vulnerable to incidents.
Nobody likes getting caught off-guard and scrambling to get communication out the door. Now’s the time to get your tooling and process in place when things are calm, so you’re prepared when things aren’t.
Take a listen to our webinar to get started and when you’re ready, you can launch a page for your customers.
This post was originally published on the Statuspage blog in 2017.


