Incident management for high-velocity teams
Optimizing incident management for IT operations
Outages impact the bottom line.
Downtime often means not only lost revenue, but also reputational damage, compliance and regulatory penalties, lost customers, and an uptick in operational costs and delays as IT professionals are pulled off other projects to resolve incidents.
In fact, one report by IHS estimated downtime costs North American organizations over $700 billion per year—and 78% of that cost is attributed to lost employee productivity.
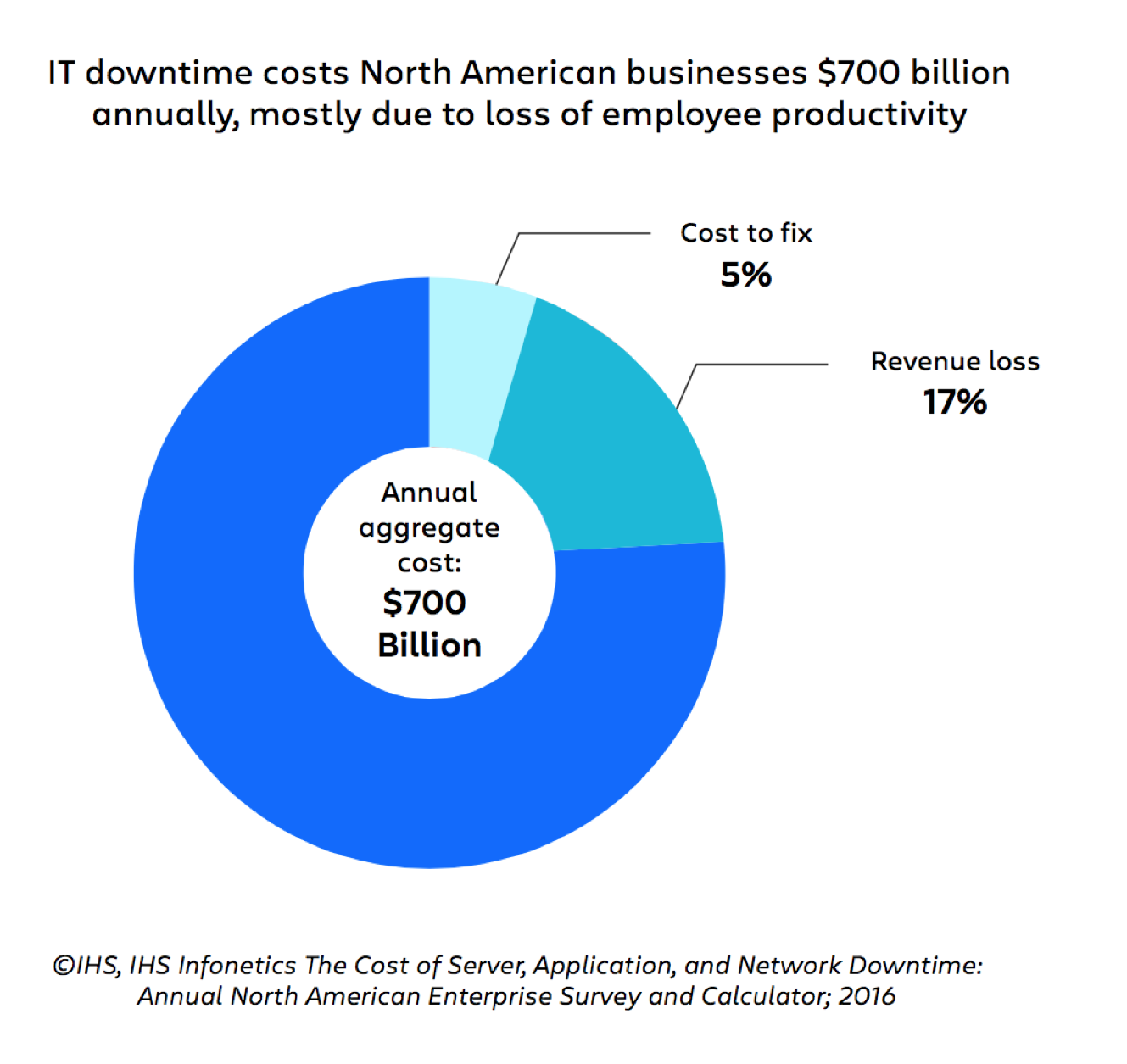
Figures like these make it clear that lost revenue isn’t the only – or even the most important – priority for incident management. An optimized incident management process also needs to address the very real, very expensive challenges of the people, process, and technology behind incident management.
The challenges facing modern IT incident management
Disconnected processes and technologies
A side effect of 40 years of computing innovation is that many companies now operate an eclectic mix of applications and systems. Some applications live in their own data centers where they can be intimately controlled, while others are delivered on the Cloud and managed by third-party providers.
This collection of applications, services, and systems often results in a tenuously connected patchwork of solutions and processes for logging, monitoring, and alerting. It’s not uncommon for enterprises to use dozens of monitoring tools to track thousands of application events or alerts each day.
This patchwork approach can lead to an overwhelming volume of alerts, a breakdown in communication, a lack of clear priority for on-call employees, and a situation where a failure in one stage of this patchwork process can take down the whole thing.
An overwhelming volume of alerts/incidents
Many IT operations departments funnel alerts into email boxes to counteract their volume problem. But this just makes matters worse, creating a situation where email requires 24-7 monitoring by senior-level staff responsible for prioritizing incidents and escalating critical messages.
This never-ending stream of alerts can be overwhelming and lead to alert fatigue, burnout, work dissatisfaction, anxiety, and longer response times. It impacts both employee well-being in the workplace and productivity, which directly impacts the business bottom line.
Rising operations costs
While infrastructure costs have declined, operations costs have risen – driven, in part, by the complexity of debugging issues when you don’t control the entire system.
Measuring the wrong success metrics
Service desk operations success has often been measured with metrics like call throughput and mean call time – neither of which contribute to or directly measure the effectiveness of incident management.
Even useful metrics like MTTR and MTBF aren’t alone enough to improve incident management performance. They are there to help us identify an issue, but they can’t answer the stickier, more qualitative questions of why and how incidents occur and are resolved and how to improve those metrics.
Outdated incident response team structures
Until the last decade, responding to IT incidents was the primary job of operations teams. Organizations typically implemented a tiered team structure (Level 1, Level 2, Level 3) to respond to issues reported by customers or monitoring tools.
The goals of incident management back then were the same: minimize operational cost while maintaining service levels. Because of that, Level 1 responders were typically low-cost, entry-level employees. If they couldn’t resolve an incident, they escalated to Level 2 (typically more experienced, mid-level professionals). This escalation process would continue until the issue was resolved.
While this process does prioritize cost savings, it does so at the expense of agility. The slower response time of a team that starts incidents with entry-level employees and requires multiple levels of escalation can have an immediate impact on incident resolution timelines, which directly impact company reputation as customer frustration spreads across social media channels.
Plus, with companies losing 78% of their incident management dollars on employee productivity, it’s pretty clear that an escalation model doesn’t actually save a company money. If the person who built the software can fix the bug in 15 minutes and your entry-level person spends two hours and has to escalate it anyway, that’s not an efficient system.
In a world of always-on services, agility has become more important than ever. Metrics like mean time to respond and mean time to resolve have gained traction precisely because companies need to maximize agility if they want to minimize cost.
How to optimize your IT incident management process
It’s clear it’s time to refocus our incident management efforts with processes, team structures, and practices that reflect the new business realities of today. But what does that refocusing process look like?
Prioritize and consolidate alerts
The primary culprit in alert fatigue and a key contributor to lost productivity is a surplus of meaningless, non-actionable alerts. The simplest fix? Identify critical systems, de-duplicate redundant notifications, and create a clear prioritization hierarchy for alerts.
Create an on-call schedule that works for your teams
Avoiding alert fatigue, burnout, and inefficiencies also means creating an on-call schedule that works for your teams. This means not overburdening any one person or team, providing backup support where needed, and reevaluating the effectiveness of your schedule on a regular basis.
Automate where you can
It’s easy to lose focus when you’re manually sifting through dozens of reports to identify and escalate the ones that matter. The good news is that this is no longer something that has to be done manually by a team member and you can avoid lost productivity and alert fatigue by removing it from the task list through automation.
Alert routing, notification, deduplication, message workflows, conference bridge creation, status page updates, on-call scheduling, escalation processes, and KPI tracking can also be wholly or partially automated to save the team time and reduce human error in set, repetitive tasks. Not to mention that automation saves the company money over time.
Communicate effectively across channels and stakeholders
Incidents impact a variety of stakeholders – often both internal and external – and those stakeholders need to be informed. Studies show that 87% of business stakeholders want updates on incidents (and 56% are more frustrated by lack of communication than they are by the incident itself). And customers definitely feel the same.
In a time where always-on is the expectation, having a solid incident communication plan in place is a vital piece of the optimization puzzle.
Make it easy to track the right metrics
The easier it is to track success metrics and review them, the more likely your team is to keep up with them. Automate reporting where possible and get clear up front on which metrics matter for your team and why.
Conduct blameless postmortems
An incident isn’t over just because the app or database is back online. To prevent incidents, reduce time spent on future incidents, and better understand how your processes, teams, and policies are impacting your incident management, you need to conduct postmortems.
At Atlassian, our postmortems are blameless, which means they focus on improving performance and moving forward – not finding someone to blame.
Choose technology that supports your processes and needs
Automation. Alert prioritization. On-call scheduling. KPI tracking. To be effective, each of these essential processes needs technology that supports them. Before you choose your technology, make sure you understand your goals, processes, and team needs. If you want to automatically organize, de-duplicate, and prioritize alerts, you need a solution that has those features—a solution such as Jira Service Management.
Learn incident communication with Statuspage
In this tutorial, we’ll show you how to use incident templates to communicate effectively during outages. Adaptable to many types of service interruption.
Read this tutorialIncident communication templates and examples
When responding to an incident, communication templates are invaluable. Get the templates our teams use, plus more examples for common incidents.
Read this article