Как работает управление инцидентами в Jira Service Management
Обзор
Управление инцидентами — это практика реагирования на незапланированное событие или сбой в обслуживании с последующим восстановлением работы затронутой службы.
- Инцидент. Незапланированный сбой в обслуживании или снижение его качества.
- Серьезный инцидент. Инцидент со значительными последствиями для предприятия, требующий немедленного и скоординированного решения.
Проблема — это пока не известная основная причина, вызвавшая один или несколько инцидентов.
Платформа Atlassian для управления инцидентами предоставляет полный контекст и данные, необходимые для быстрого и эффективного устранения инцидента.
- С помощью Jira Service Management агенты могут легко управлять задачами и инцидентами, о которых сообщают пользователи.
- Агенты могут быстро эскалировать серьезные инциденты, отправляя оповещения дежурной команде. Решение Jira Service Management позволяет командам ИТ и DevOps контролировать ситуацию во время инцидентов. С его помощью можно сосредоточить оповещения в одной системе, а также уведомить нужных сотрудников и дать им возможность совместно работать и быстро принимать необходимые меры.
- Встроенные средства управления ресурсами и конфигурацией в Jira Service Management (доступны с планами Premium и Enterprise) помогают агентам отследить зависимости в ИТ-инфраструктуре и найти потенциальные причины инцидента.
- И наконец, благодаря общим рабочим пространствам вы сможете собрать в одном месте практики, процессы и процедуры управления инцидентами, от перечней процедур и баз знаний до анализа результатов реагирования на инциденты.
Это эффективное комплексное решение по управлению инцидентами помогает командам выполнять эскалацию инцидентов, привлекать нужных реагирующих лиц, штурмовать инциденты и в конечном итоге минимизировать время простоя.
Процесс управления инцидентами
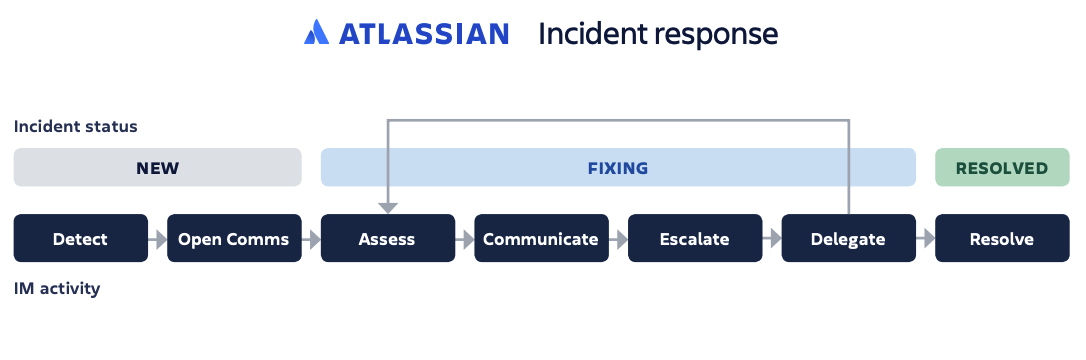
Ключом к управлению инцидентами является качественный алгоритм действий и его соблюдение. Реакция на инциденты — довольно широкий термин, поэтому мы разберем конкретные и наиболее вероятные этапы устранения инцидента после его обнаружения, а также назначения ему категории и приоритета.
- Первоначальная диагностика. Команды, следующие принципам DevOps, обычно занимаются инцидентом с момента его диагностики до устранения, тогда как в многоуровневых службах поддержки имеется передовая команда, которая работает по тому же принципу и при необходимости может эскалировать инцидент командам поддержки 2-го или 3-го уровня.
- Эскалация. При необходимости следующая команда продолжит диагностику инцидента, используя полученные данные, и в случае неудачи эскалирует инцидент следующей команде.
- Коммуникация. Команда должна регулярно сообщать об обновлениях статуса внешним и внутренним заинтересованным лицам, на которых влияет инцидент.
- Изучение и диагностика. Изучение и диагностика инцидента должны продолжаться, пока он не будет разрешен. Иногда команды могут привлечь внешние ресурсы или специалистов из других отделов, чтобы проконсультироваться и получить помощь в решении проблемы.
- Разрешение и восстановление после инцидента. На этом шаге команда завершает диагностику и выполняет все необходимое, чтобы разрешить инцидент. Определяющим критерием при восстановлении после инцидента являются усилия, которые будут затрачены на полное восстановление работы службы, так как уже после этого может потребоваться развернуть и протестировать некоторые исправления (например, исправления багов и т. д.).
- Закрытие. В конечном итоге эскалированный инцидент снова передается в службу поддержки для закрытия. Закрывать инциденты могут только сотрудники службы поддержки. Это позволяет поддерживать высокое качество обслуживания и последовательность в решении проблем. Владелец инцидента должен связаться с пользователем, сообщившим об инциденте, и убедиться, что найденное решение является удовлетворительным и инцидент действительно можно закрыть.

Подробнее см. на странице управления инцидентами.
Начало работы с управлением инцидентами в Jira Service Management
Начало работы с управлением инцидентами
В Jira Service Management имеется рабочий процесс управления инцидентами, совместимый с библиотекой инфраструктуры информационных технологий (ITIL). Он называется Incident Management workflow for Jira Service Management (Рабочий процесс управления инцидентами для Jira Service Management). Рекомендуется начать с этого рабочего процесса и постепенно адаптировать его к потребностям конкретного предприятия. Подробнее о редактировании рабочих процессов.
По умолчанию в представление инцидента для агентов включены следующие поля. При необходимости можно добавить пользовательские поля.
Создание соглашений об уровне обслуживания (SLA) для записей об инцидентах
В Jira Service Management встроены полезные SLA. С их помощью команды могут отслеживать, насколько их уровень обслуживания соответствует ожиданиям клиентов. Администраторы проекта могут создать цели по SLA, указав типы запросов, которые необходимо отслеживать, а также время, за которое эти запросы нужно решить. Затем вы сможете определить условия и календари, с учетом которых будет задано начало, приостановка и прекращение измерения показателей SLA.
Чтобы создать новое соглашение SLA, выполните следующие действия:
- В проекте службы поддержки выберите Project Settings > SLAs (Настройки проекта > SLA). Будут показаны все существующие SLA.
- Выберите Add SLA (Добавить SLA).
- В поле рядом со значком часов укажите новое название SLA или выберите существующее.
- (SLA не получится переименовать после создания, поэтому выберите название, из которого можно легко определить измеряемые показатели SLA.)
- Задайте цели и условия SLA. Подробнее о настройке целей SLA и настройке временных показателей SLA.
- Нажмите Save (Сохранить).
Присвоение отметки серьезным инцидентам в Jira Service Management
При сбое критически важных служб решение Jira Service Management Cloud предоставляет необходимые инструменты, которые помогают агентам быстро устранять инциденты. Присвоив отметку серьезному инциденту, вы сделаете его заметнее на фоне остальных инцидентов. Такие инциденты также группируются с помощью JQL в специальной одноименной очереди.
Чтобы присвоить отметку серьезному инциденту:
- Перейдите к инциденту, который необходимо отметить как серьезный.
- Включите переключатель Major incident (Серьезный инцидент) в разделе сведений о задаче.
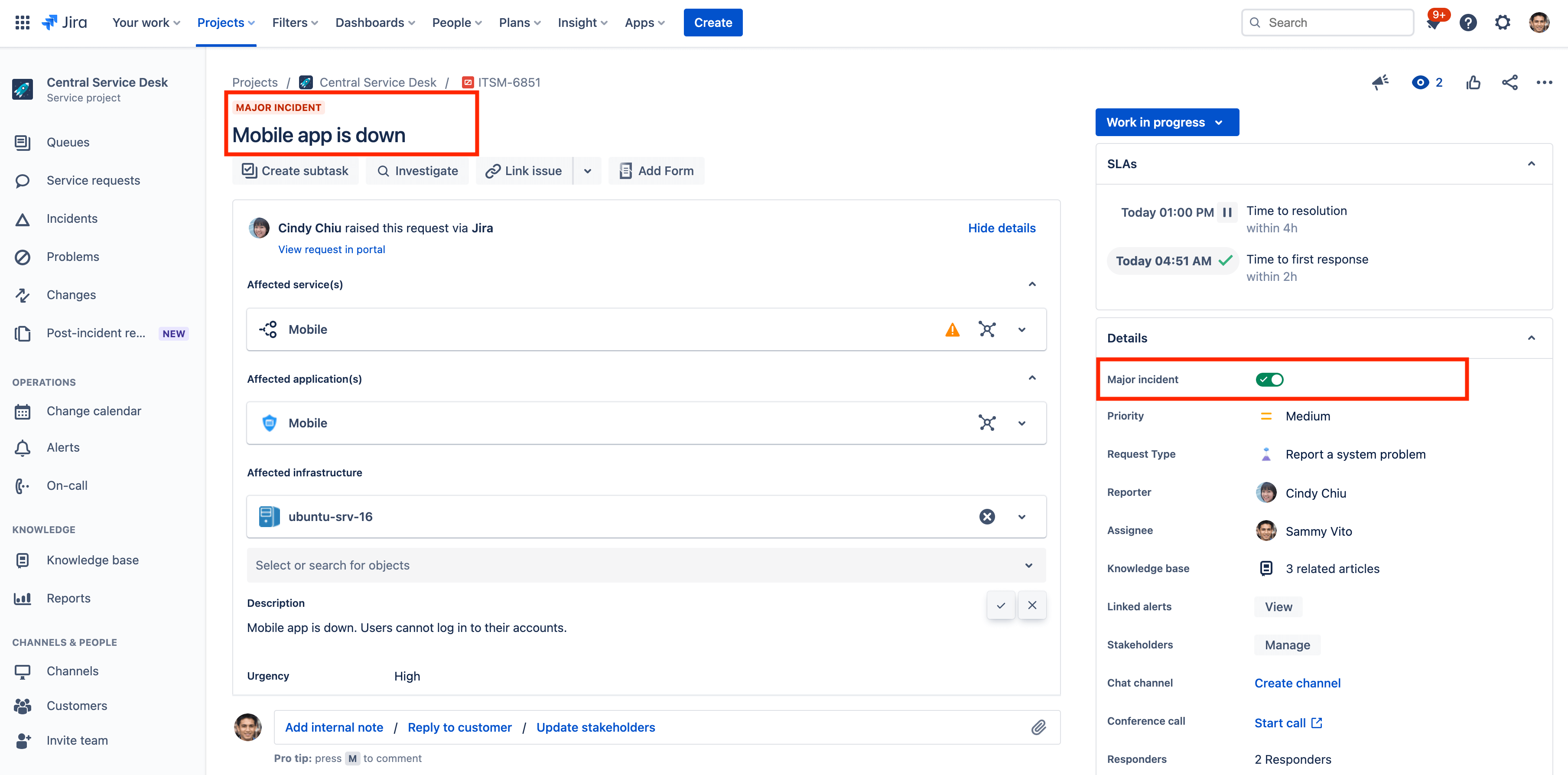
Примечание. Если для ваших инцидентов не отображается поле Major incident (Серьезный инцидент), убедитесь, что это поле добавлено в представление задачи. Для добавления полей к типу задачи необходимо быть администратором Jira.
Создание и отправка обновлений в канал Slack напрямую из инцидента
В Jira Service Management можно подключить рабочее пространство и создать выделенный канал Slack для каждого инцидента. Подключите рабочие пространства Slack к проекту службы поддержки, чтобы создавать каналы Slack для инцидентов, добавлять в эти каналы лиц, реагирующих на инциденты, обновлять соответствующие приоритеты, а также принимать меры в случае возникновения инцидентов и помогать команде быстрее приступить к их устранению.
Чтобы создать для инцидентов канал в Slack:
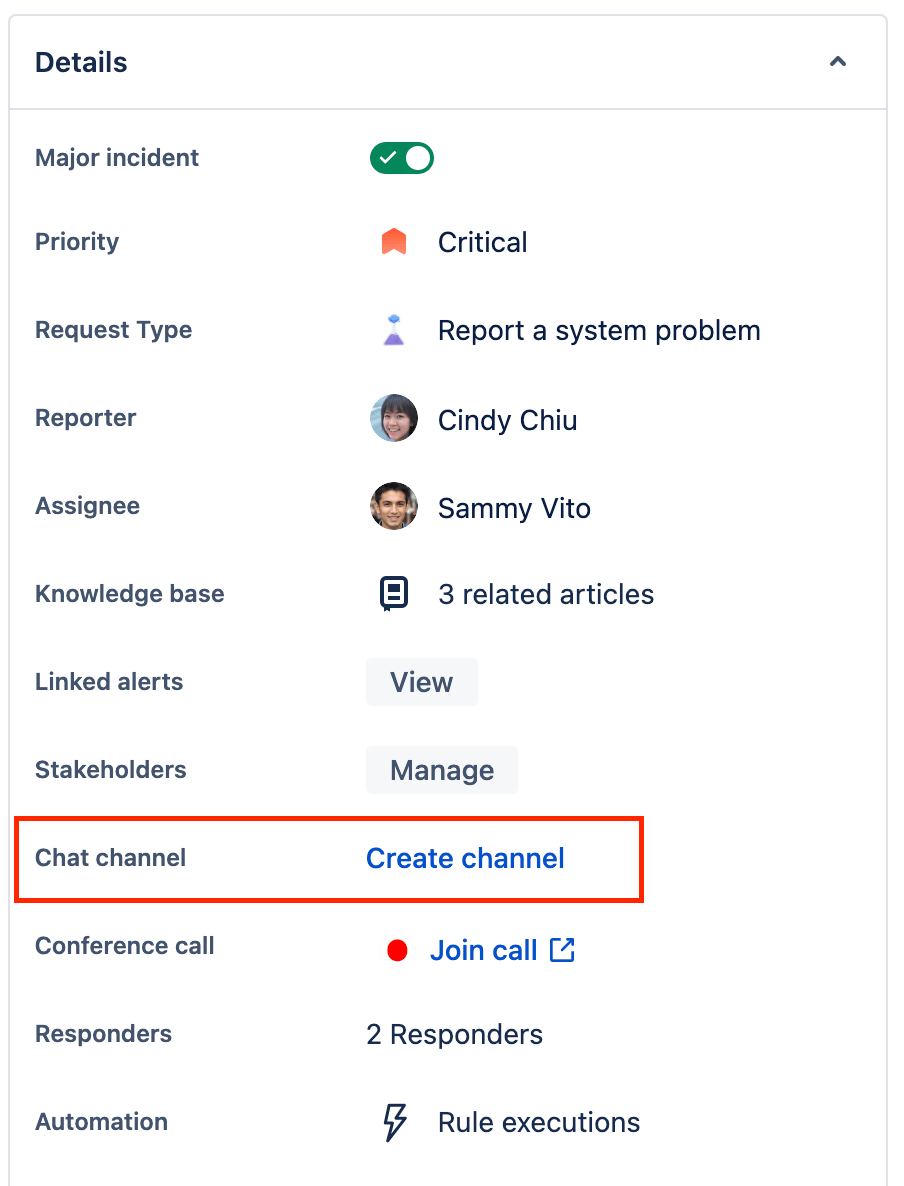
- Перейдите к инциденту, для которого необходимо создать канал в Slack.
- В разделе сведений о задаче выберите Create channel (Создать канал).
Отправка обновлений об инцидентах внутренним заинтересованным лицам
Внутренние заинтересованные лица не занимаются реагированием на инцидент, но при этом они должны оставаться в курсе прогресса по инциденту, а также выполнять соответствующие действия и принимать меры предосторожности. В Jira Service Management можно добавить пользователей в качестве заинтересованных лиц и уведомлять их об обновлениях по электронной почте.
Чтобы добавить или удалить внутреннее заинтересованное лицо:
- Перейдите к инциденту, для которого необходимо добавить внутреннее заинтересованное лицо.
- В разделе сведений напротив поля заинтересованного лица выберите Manage (Управление).
- Найдите пользователей, которых необходимо добавить в качестве заинтересованных лиц.
Чтобы сообщить внутренним заинтересованным лицам об обновлении:
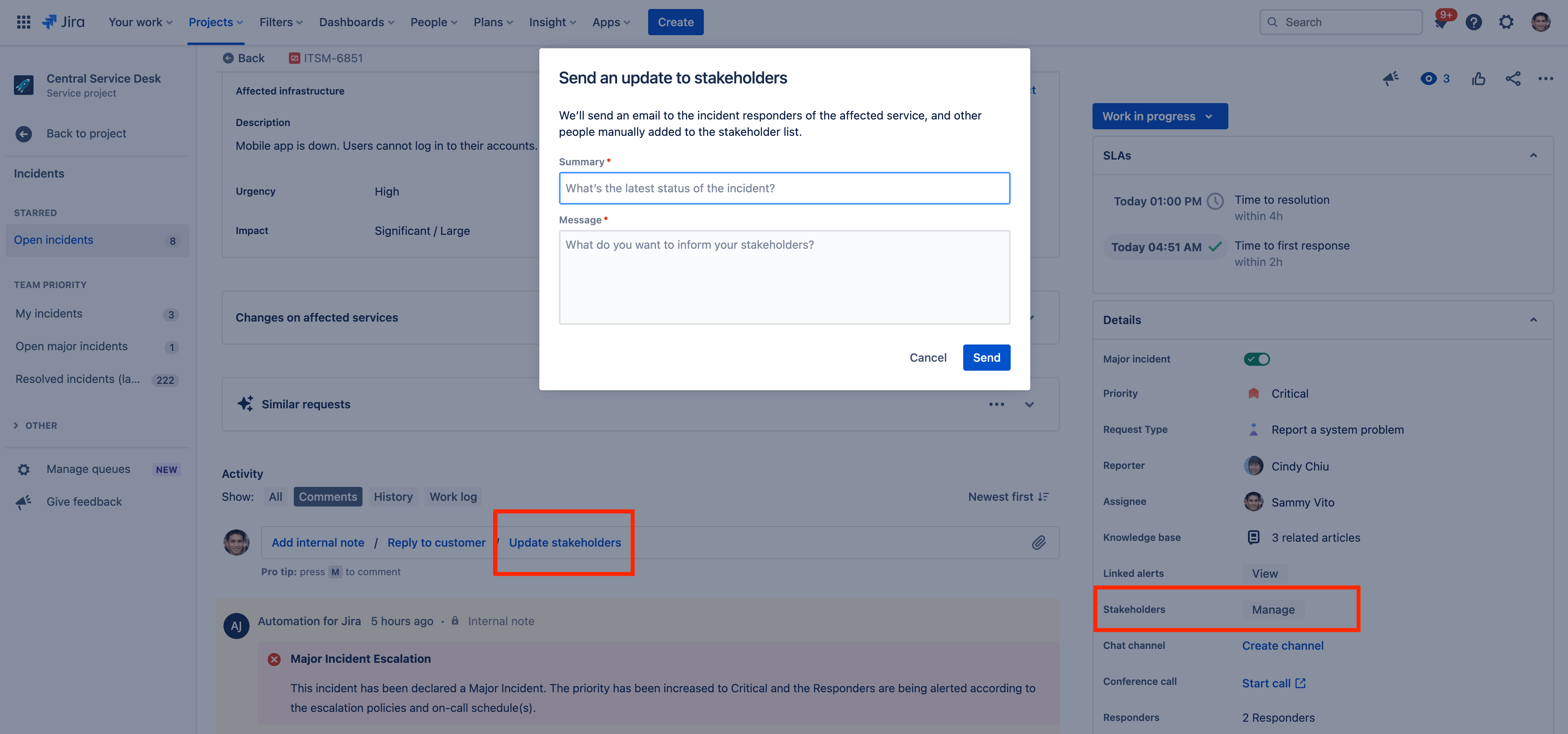
- В разделе Activity (Активность) представления задачи выберите Update stakeholders (Уведомить заинтересованных лиц).
- Добавьте сводку и сформулируйте сообщение.
- Выберите Send (Отправить).
Командный штурм инцидентов с помощью конференц-звонков
В Jira Service Management доступны переговорные комнаты для аудио- и видеозвонков, с помощью которых можно координировать работу над инцидентами и управлять ими в одном месте.
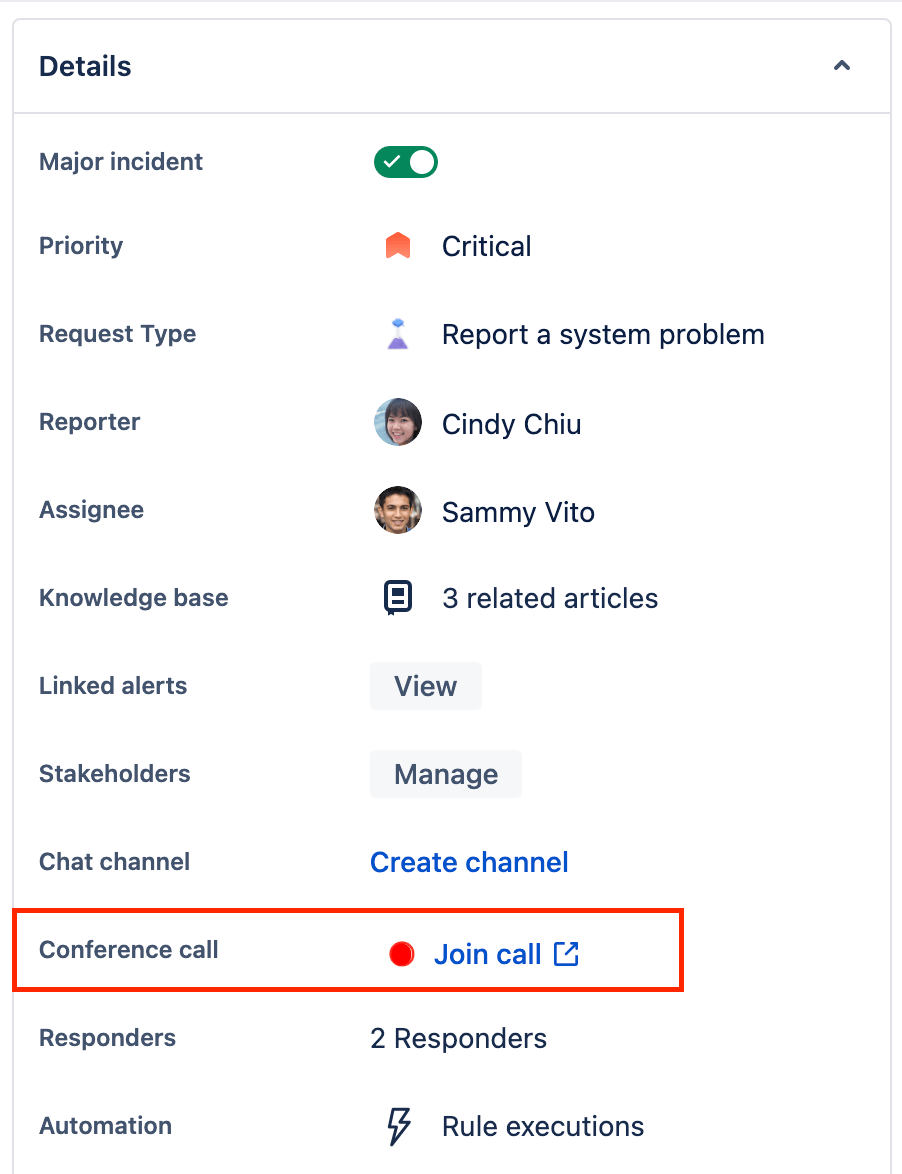
Чтобы начать конференц-звонок:
- Перейдите к инциденту, для которого необходимо начать конференц-звонок.
- Затем начните звонок или присоединитесь к существующему, нажав соответствующую кнопку напротив поля конференц-звонка в разделе сведений.
Создание анализа результатов реагирования на инцидент (PIR) и получение доступа к нему
Анализ результатов реагирования на инцидент является важным этапом жизненного цикла непрерывно работающей службы, а также позволяет выявить уязвимости в системе, предотвратить повторные инциденты и сократить время на устранение будущих инцидентов. Для учета критических исправлений результаты анализа должны использоваться при планировании предстоящей работы. Документирование инцидента и действий по его разрешению поможет выработать стратегию по устранению инцидентов в будущем. Команды могут создавать долгосрочные решения проблем, которые привели к инциденту, и привязывать анализ результатов реагирования к инциденту в Jira Service Management.
Чтобы включить функцию анализа результатов реагирования на инцидент:
- Перейдите в раздел Project settings > Features (Настройки проекта > Возможности).
- Включите категорию Post-incident reviews (Анализ результатов реагирования на инцидент) в разделе ITSM categories (Категории ITSM).
Включив эту категорию, вы получите доступ к новым возможностям для запросов. Чтобы начать, создайте для категории Post-incident reviews (Анализ результатов реагирования на инцидент) новые типы запросов или назначьте существующие.
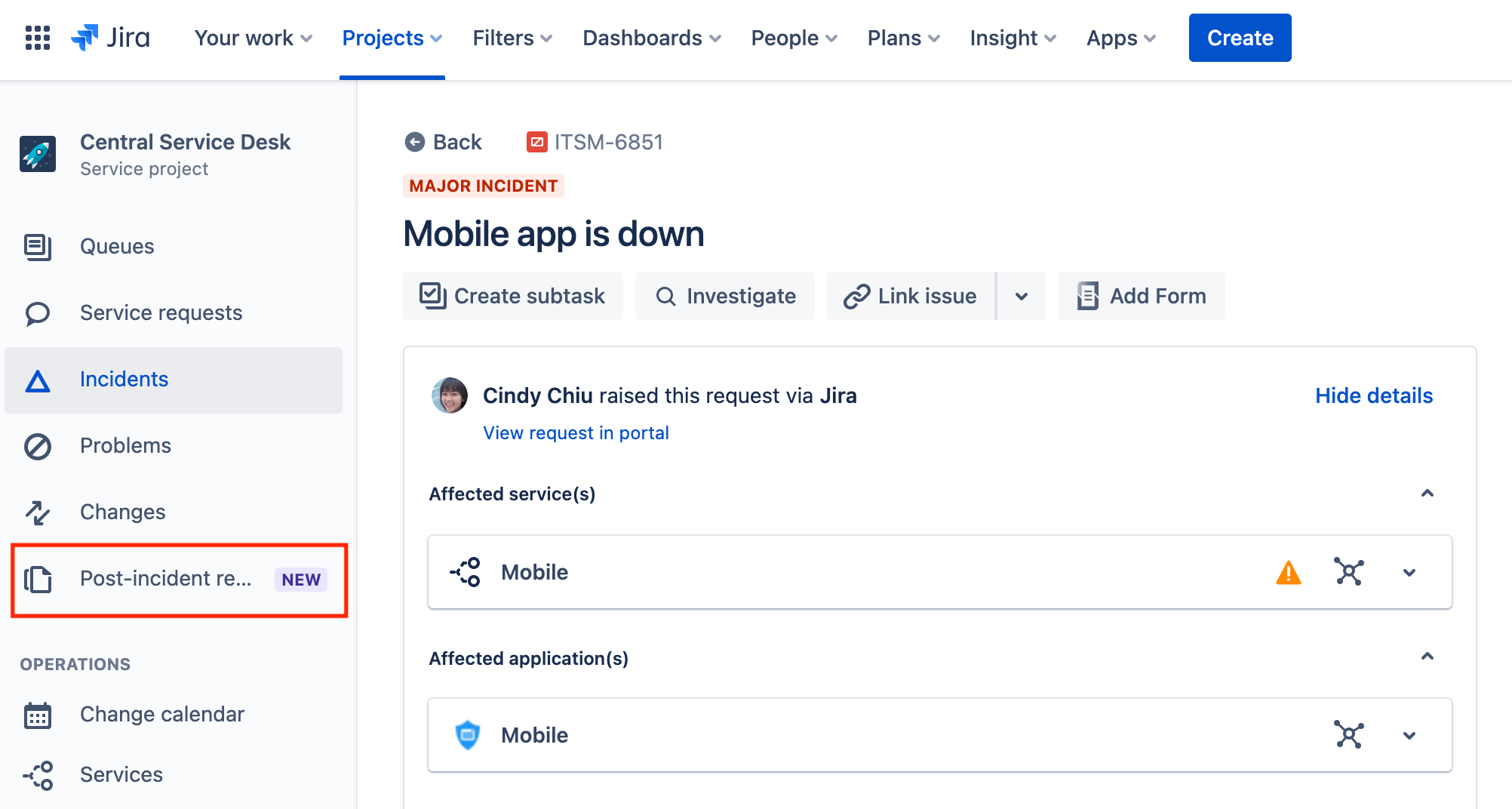
Чтобы получить доступ к анализу результатов реагирования на инцидент:
- В боковом меню проекта выберите Post-incident review (Анализ результатов реагирования на инцидент).
- Выберите подходящую очередь для анализа результатов реагирования на инцидент.
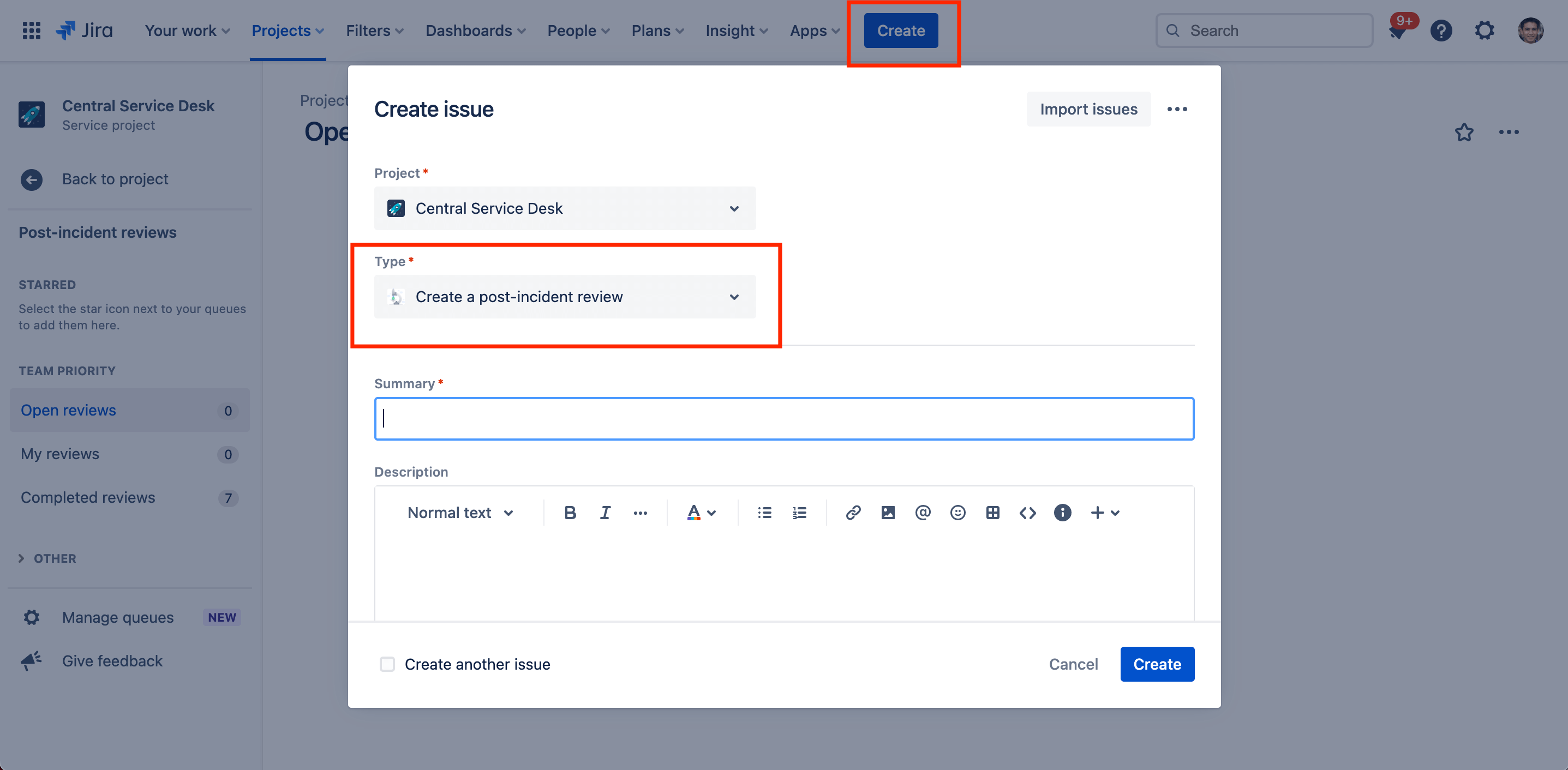
Чтобы создать новый анализ результатов реагирования на инцидент:
- В верхней строке меню выберите Create (Создать).
- В раскрывающемся списке выберите тип запроса для анализа результатов реагирования на инцидент.
- Укажите необходимую информацию и свяжите соответствующий инцидент с PIR в поле связанных задач.
- По завершении выберите Create (Создать).
Профессиональный совет. Анализ результатов реагирования на инциденты также можно создавать с помощью встроенного модуля автоматизации Jira Service Management. Например, вы можете задать правило автоматизации, чтобы создавать анализ результатов каждый раз при разрешении командой серьезного или критического инцидента.
Связывание нескольких инцидентов с отчетом о проблеме
Jira Service Management позволяет связать несколько задач. Например, можно связать несколько записей об инцидентах с более объемным отчетом о проблеме.
Чтобы связать несколько инцидентов с отчетом о проблеме:
- Перейдите к записи об инциденте.
- Выберите Link Issue (Связать задачу).
- В поле связанных задач выберите is caused by (вызвана).
- В поле Issue (Задача) укажите (или выберите из раскрывающегося меню) задачу, с которой вы хотите связать запись об инциденте.
- Выберите Link (Связать).
Рекомендации и советы по управлению инцидентами
Облегчите сбор сообщений пользователей и системы об инцидентах
Jira Service Management является источником достоверной информации как о незначительных, так и о серьезных инцидентах. На портале клиентов выполняется подробная и последовательная регистрация сообщений пользователей об инцидентах с включением всех сведений, необходимых команде поддержки для оценки инцидента. Сотрудники или клиенты, заметившие инцидент, могут сообщить о нем в Jira Service Management. После этого инциденты добавляются к очередям соответствующих агентов.
При раннем обнаружении инцидентов и сбоев ИТ-команды получают основные сведения благодаря эффективному мониторингу. Для обработки сообщений системы об инцидентах можно легко интегрировать с Jira Service Management более 200 приложений и веб-сервисов, таких как Slack, Datadog, Sumo Logic и Nagios, чтобы синхронизировать данные оповещений и оптимизировать рабочий процесс управления инцидентами.
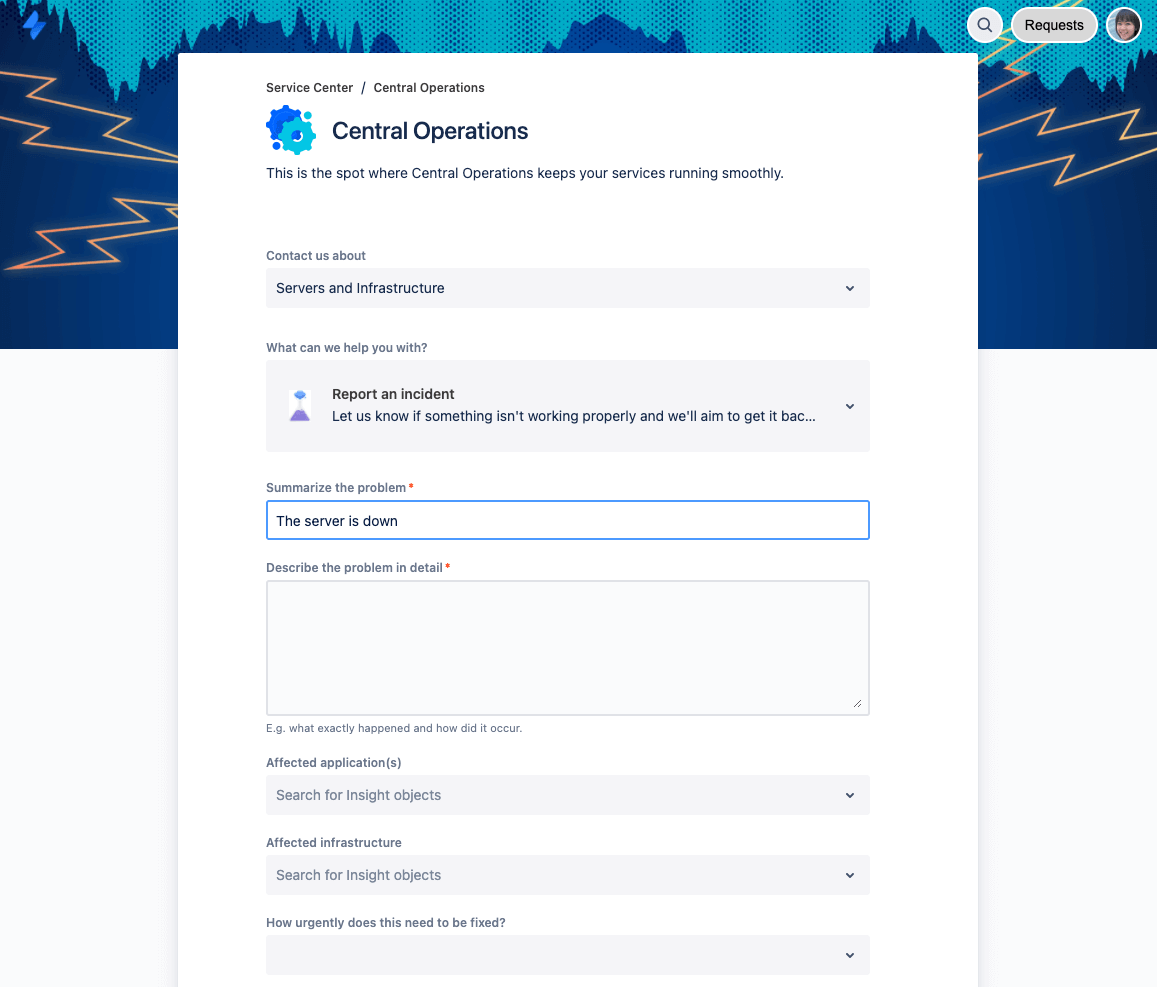
Используйте интеллектуальное планирование дежурств, чтобы снизить усталость от оповещений
Если дежурным сотрудникам сыплются ненужные оповещения, они начинают уставать и пропускать важные уведомления. Благодаря встроенным средствам управления инцидентами в Jira Service Management ваша команда не пропустит ни одного критического оповещения.
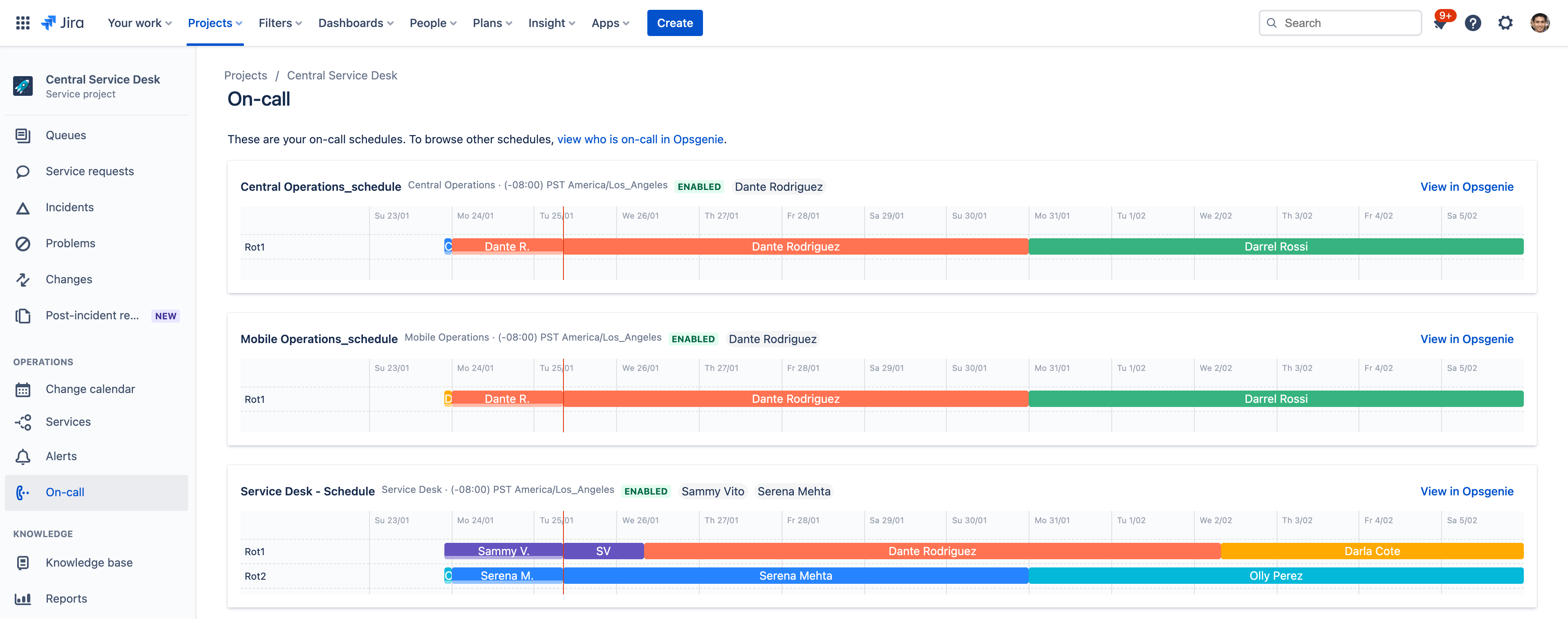
Составление графика дежурств и правил эскалации ведется в одном интерфейсе, поэтому ваша команда всегда будет знать, кто дежурит и несет ответственность во время инцидентов. Решение объединяет оповещения в группы, отсеивает лишнюю информацию и передает уведомления участникам команды по нескольким каналам. Это могут быть SMS-сообщения, телефонные звонки, мобильные push-уведомления, электронные сообщения и т. д. Кроме того, команда получает необходимый контекст и может немедленно приступить к устранению инцидента.
Используйте ChatOps и перечни процедур, чтобы эффективнее согласовать действия команды
Благодаря Jira Service Management у команд появляется единый центр для совместной работы, обмена информацией в режиме реального времени и быстрого устранения инцидентов с помощью центра управления инцидентами. Вместо того чтобы просматривать отдельные разрозненные обновления в чате или прокручивать длинную историю беседы, создайте комнату для видеоконференций, чтобы команды могли динамично общаться, распределять роли и даже предпринимать решительные действия прямо в интерфейсе инструмента. Прикрепив перечни процедур к оповещениям, команды смогут быстро запускать стандартные задания по устранению недостатков автоматически или по требованию.
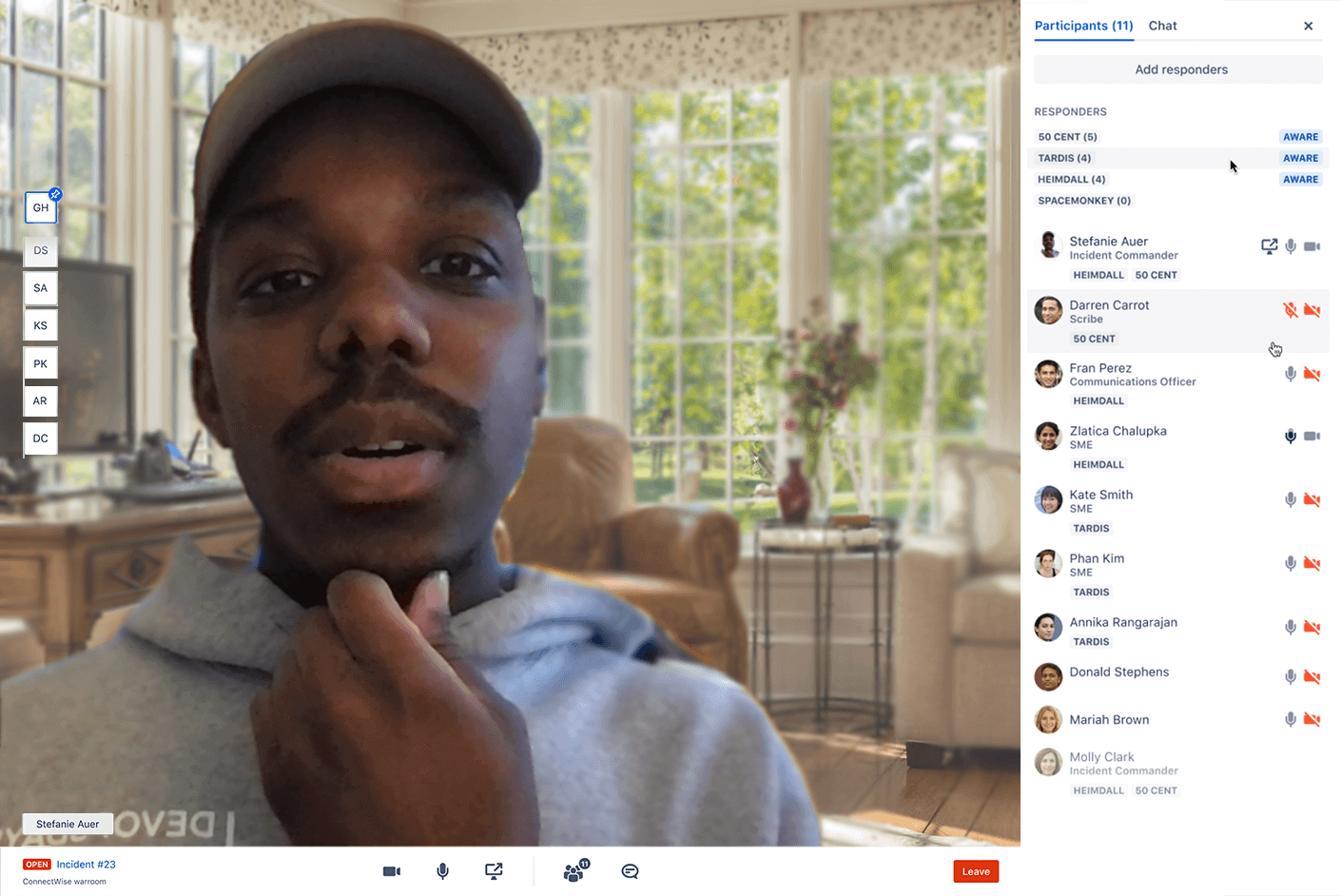
С помощью перечней процедур также удобно документировать распространенные методы устранения неполадок, чтобы реагировать на оповещения и устранять сбои. С перечнями процедур у сотрудников всегда будет под рукой необходимая информация, чтобы быстро присвоить инциденту нужный приоритет. В большинстве случаев командам удается сократить время устранения инцидентов на 40 %.
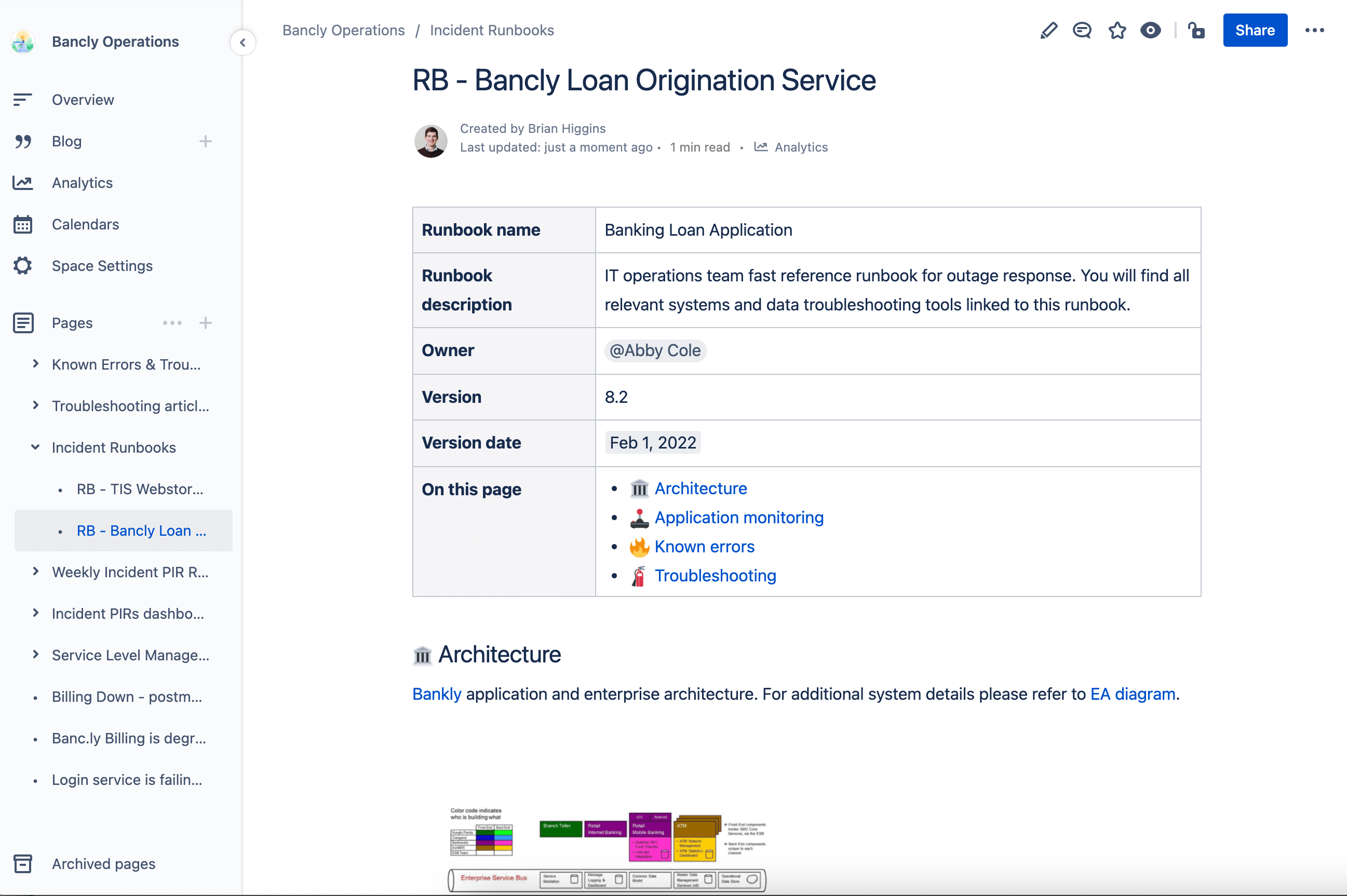
Создайте сборник сценариев по упреждающему управлению инцидентами
Заранее спланируйте стратегию реагирования на инциденты. Так вы снимете стресс, сохраните концентрацию команды во время инцидента и сократите время его устранения. Обязательно используйте как методы оперативного сотрудничества, так и командной работы:
- Определите, что для вашей команды важнее всего при реагировании на инциденты, и создайте план, который позволит вам действовать в соответствии с этими ценностями. В число этих ценностей может входить совместная работа, коммуникация, разбор результатов реагирования на инцидент без поиска виновных и многое другое.
- Четко определите, что можно считать серьезным инцидентом.
- Документируйте практики в отношении серьезных инцидентов.
- Разработайте взаимодействие при реагировании на инциденты, например шаблоны реагирования и информирование заинтересованных сторон (внутренних и внешних).
- Определите основных участников «команды команд» по реагированию на инциденты.
- Разработайте практики PIR.
- Проводите PIR без поиска виновных для всех серьезных инцидентов.
- Публикуйте результаты PIR и делитесь полученным опытом.
- Проводите учения по моделированию серьезных инцидентов.
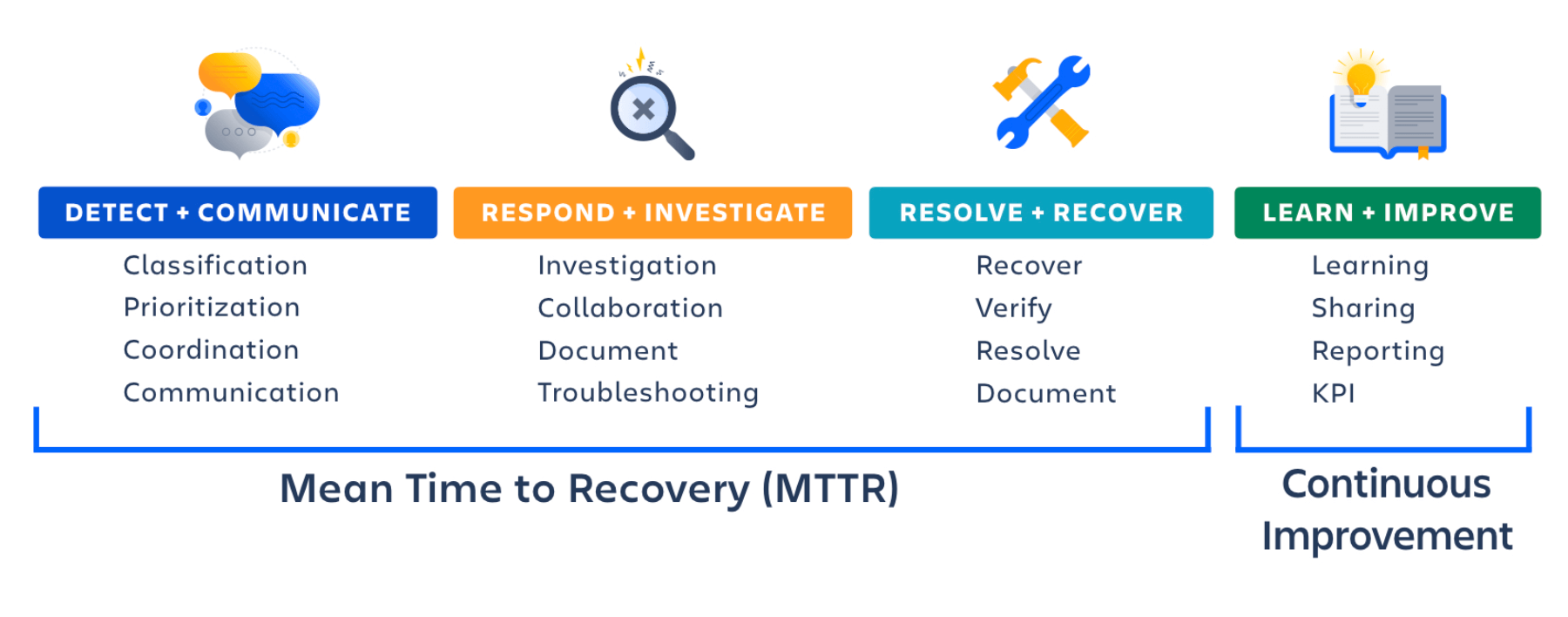
Сосредоточьтесь на сокращении среднего времени восстановления (MTTR)
Создание надежного процесса управления инцидентами имеет решающее значение для смягчения последствий инцидентов и быстрого возобновления работы услуг. Чтобы повысить скорость реагирования, необходимо сократить среднее время восстановления (MTTR) и оптимизировать анализ основных причин, который проводится для предотвращения будущих сбоев. И действительно, по данным Forrester, 70 % времени реагирования на инциденты занимают этапы расследования и диагностики.
Укрепляйте доверие благодаря централизованному взаимодействию с внешними пользователями
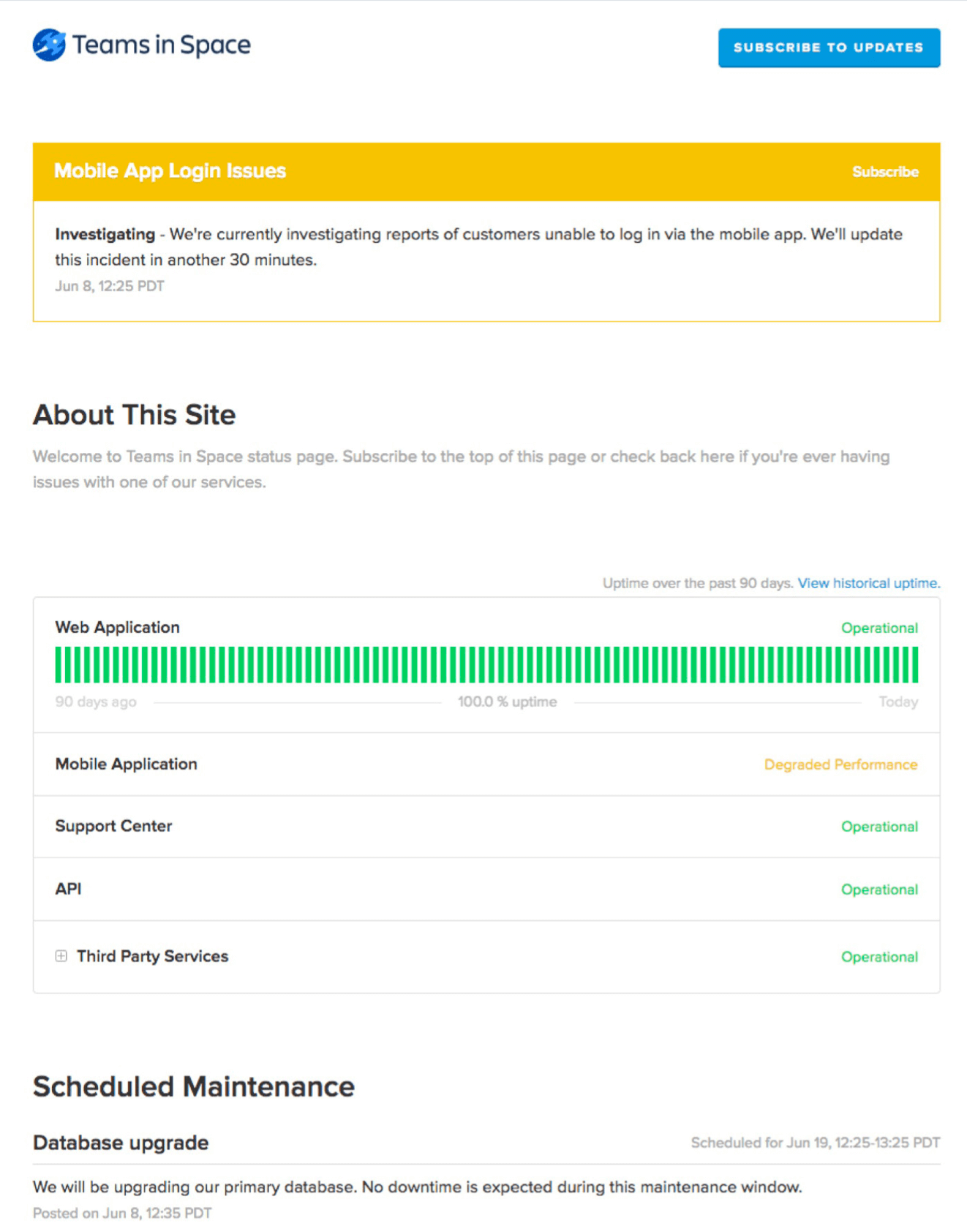
Многие команды используют централизованный дашбоард, например Statuspage, чтобы сообщать о состоянии критически важных услуг. Statuspage предлагает автоматические уведомления и обновления, а также работает как единый канал для четкой и упреждающей массовой коммуникации как с внутренними, так и с внешними пользователями.
Кроме того, Statuspage информирует внутренние команды о плановых и внеплановых простоях. Клиенты и сотрудники могут подписываться на обновления. Это способствует четкому информированию и сокращает количество обновлений в ручном режиме.
Подробнее см. на странице рекомендаций по управлению инцидентами
Начало работы
Управление заявками на обслуживание
Начало работы
Управление проблемами