So funktioniert Vorfallmanagement in Jira Service Management
Überblick
Das Vorfallmanagement ist ein Prozess zur Reaktion auf ein ungeplantes Ereignis oder eine Serviceunterbrechung, um den normalen Servicebetrieb wiederherzustellen.
- Vorfall: Ungeplante Unterbrechung eines Service oder Verringerung der Servicequalität.
- Größerer Vorfall: Ein Vorfall mit erheblichen geschäftlichen Auswirkungen, der eine umgehende koordinierte Lösung erfordert.
Ein Problem ist die bisher nicht bekannte Ursache für einen oder mehrere Vorfälle.
Die Atlassian-Plattform für das Vorfallmanagement stellt alle für die Behebung des Vorfalls benötigten Kontextinformationen und Daten schnell und effizient bereit.
- Innerhalb von Jira Service Management können Agenten Vorgänge und von Benutzern gemeldete Vorfälle problemlos verwalten.
- Größere Vorfälle können sie schnell als Warnung an das Bereitschaftsteam eskalieren. Jira Service Management bietet IT- und DevOps-Teams zentrale Warnmeldungen, benachrichtigt die richtigen Personen und ermöglicht Zusammenarbeit und schnelles Ergreifen von Maßnahmen, sodass sie während eines Vorfalls die Kontrolle behalten.
- Mithilfe der nativen Funktionen für das Asset- und Konfigurationsmanagement von Jira Service Management (enthalten im Premium- und Enterprise-Tarif) können Agenten Abhängigkeiten innerhalb ihrer IT-Infrastruktur nachvollziehen, um mögliche Ursachen des Vorfalls zu ermitteln.
- Darüber hinaus werden in gemeinsamen Arbeitsumgebungen Vorfallmanagementpraktiken, -prozesse und -verfahren an einem Ort gesammelt – von Runbooks über Wissensdatenbanken bis hin zu PIRs (Post-Incident Reviews – Überprüfungen nach Vorfällen).
Diese nahtlose End-to-End-Lösung für das Vorfallmanagement erleichtert es Teams, Vorfälle zu eskalieren, die richtigen Verantwortlichen einzubeziehen, zusammenzukommen und schließlich die Ausfallzeit zu minimieren.
Der Vorfallmanagementprozess
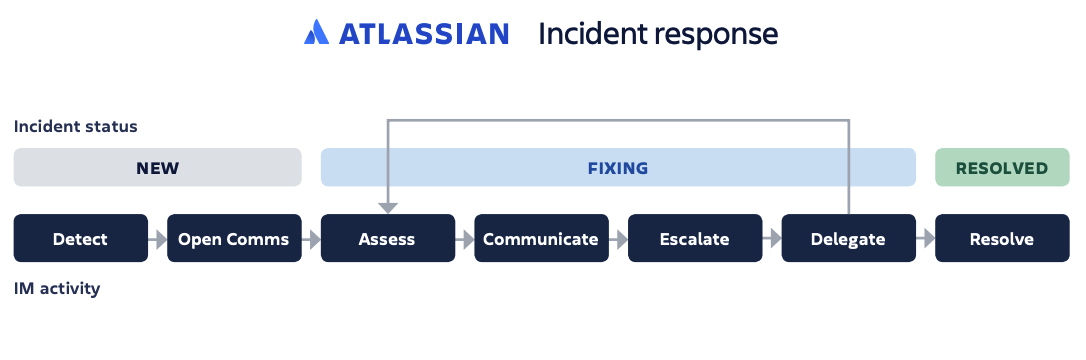
Beim Vorfallmanagement kommt es hauptsächlich darauf an, einen gut funktionierenden Prozess zu erstellen und sich an diesen zu halten. Die Incident Response ist ein ziemlich breit gefasster Begriff, deshalb werden wir sie auf die Schritte herunterbrechen, die du mit großer Wahrscheinlichkeit ausführen wirst, sobald du einen Vorfall identifiziert, kategorisiert und priorisiert hast.
- Erstdiagnose: DevOps-Teams bearbeiten einen Vorfall in der Regel von der Diagnose bis zur Lösung, während bei mehrstufigen Servicedesks ein Frontline-Team dies zwar ebenfalls versucht, den Vorfall aber bei Bedarf an Supportteams einer zweiten oder dritten Ebene eskalieren kann.
- Eskalation: Bei Bedarf setzt das nächste Team die Diagnose anhand der protokollierten Daten fort. Wenn dieses Team den Vorfall nicht diagnostizieren kann, eskaliert es ihn an das nächste Team.
- Kommunikation: Das Team gibt regelmäßig Mitteilungen an die betroffenen internen und externen Stakeholder weiter.
- Untersuchung und Diagnose: Dieser Prozess wird fortgesetzt, bis die Art des Vorfalls feststeht. Manchmal ziehen Teams externe Ressourcen oder andere Abteilungsmitglieder hinzu, um sich beraten zu lassen und Hilfe bei der Lösung zu erhalten.
- Lösung und Wiederherstellung: In diesem Schritt gelangt das Team zu einer Diagnose und ergreift die zum Lösen des Vorfalls nötigen Maßnahmen. Die Wiederherstellung bezieht sich schlicht auf den Aufwand, der nötig ist, damit ein Service vollständig wiederhergestellt werden kann. Bestimmte Fehlerkorrekturen (wie Bug-Patches usw.) erfordern eventuell noch Tests oder müssen erst bereitgestellt werden, obwohl die richtige Lösung bereits identifiziert wurde.
- Abschluss: Wenn der Vorfall eskaliert wurde, wird er abschließend an die die erste Anlaufstelle zurückgegeben, damit er geschlossen werden kann. Um die Qualität aufrechtzuerhalten und einen reibungslosen Ablauf zu gewährleisten, dürfen nur Servicedesk-Mitarbeiter Vorfälle schließen. Vorfallsverantwortliche sollten sich bei der Person, die den Vorfall gemeldet hat, erkundigen, ob die Lösung zufriedenstellend war und der Vorfall tatsächlich geschlossen werden kann.

Weitere Informationen findest du auf unserer Seite über das Vorfallmanagement.
Erste Schritte im Vorfallmanagement in Jira Service Management
Erste Schritte im Vorfallmanagement
Jira Service Management bietet einen mit ITIL (Information Technology Infrastructure Library) konformen Arbeitsablauf für das Vorfallmanagement namens Vorfallmanagement-Workflow für Jira Service Management. Wir empfehlen, mit diesem Workflow zu beginnen und ihn im Laufe der Zeit an deine spezifischen Geschäftsanforderungen anzupassen. Weitere Informationen zum Bearbeiten von Workflows
Standardmäßig befinden sich die folgenden Felder in der Vorfallansicht eines Agenten. Wenn du zusätzliche Felder benötigst, kannst du benutzerdefinierte Felder hinzufügen.
So erstellst du Service Level Agreements (SLAs) für Vorfalldatensätze
Jira Service Management bietet leistungsstarke integrierte SLAs, damit Teams nachverfolgen können, wie gut sie das von ihren Kunden erwartete Serviceniveau erfüllen. Projektadministratoren können SLA-Ziele erstellen und darin die Anfragetypen angeben, die verfolgt werden sollen, sowie die Zeit, die für die Lösung dieser Anfragetypen benötigt wird. Anschließend kannst du die Bedingungen und Kalender für Start, Pause und Stopp der SLA-Messungen definieren.
So erstellst du eine neue SLA:
- Klicke in deinem Serviceprojekt auf Projekteinstellungen > SLAs. Alle vorhandenen SLAs werden hier angezeigt.
- Wähle Service Level Agreement (SLA) hinzufügen.
- Gib in das Feld neben dem Uhrensymbol einen neuen Namen für die SLA ein oder wähle einen vorhandenen Namen aus.
- (Du kannst den Namen deiner SLA nach der Erstellung nicht mehr ändern. Achte deshalb darauf, dass daraus klar hervorgeht, was gemessen wird.)
- Setze Ziele und Bedingungen für die SLA. Erfahre mehr über das Einrichten von SLA-Zielen und das Einrichten von SLA-Zeitmetriken.
- Klicke auf Speichern.
So kennzeichnest du Vorfälle als größere Vorfälle in Jira Service Management
Wenn kritische Services ausfallen, bietet Jira Service Management Cloud die nötigen Tools, damit Agenten Vorfälle schnell beheben können. Einen Vorfall als größeren Vorfall zu kennzeichnen, hebt diesen von anderen Vorfällen ab. Diese Vorfälle werden zudem in ihrer eigenen JQL-basierten Warteschlage "Größerer Vorfall" gruppiert.
So kennzeichnest du einen Vorfall als größeren Vorfall:
- Navigiere zu dem Vorfall, den du als größeren Vorfall kennzeichnen möchtest.
- Aktiviere im Abschnitt "Details" des Vorgangs den Schalter "Größerer Vorfall".
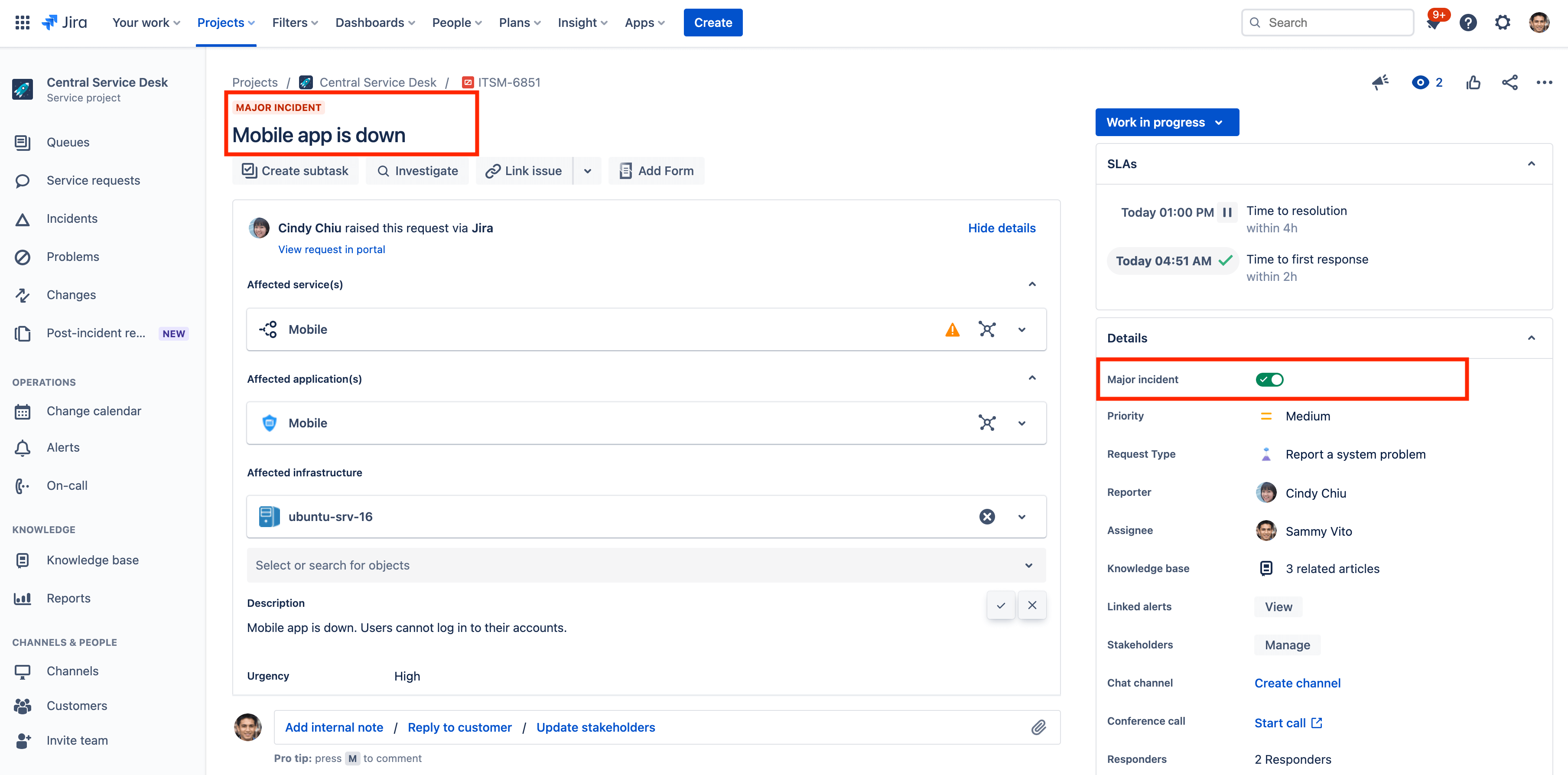
Hinweis: Wenn das Feld Größerer Vorfall für deine Vorfälle nicht zur Verfügung steht, stelle sicher, dass du das Feld in deiner Vorgangsansicht hinzugefügt hast. Nur Jira-Administratoren können einem Vorgangstypen Felder hinzufügen.
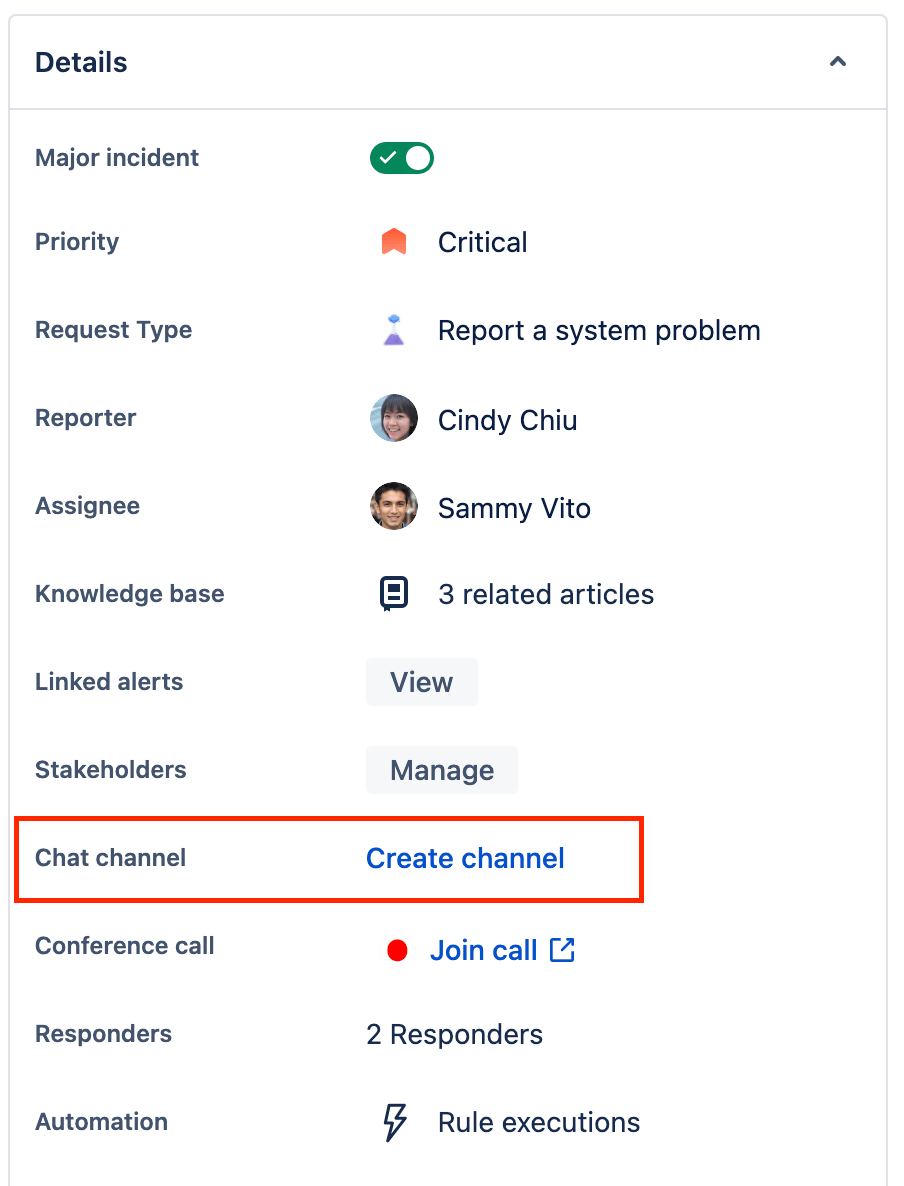
So erstellst du Updates und sendest sie an einen Slack-Channel – direkt vom Vorfall aus
Mit Jira Service Management kannst du dich mit deinem Arbeitsbereich verbinden und einen fest zugeordneten Slack-Channel für jeden Vorfall erstellen. Indem du Slack-Arbeitsbereiche mit deinem Serviceprojekt verbindest, kannst du Slack-Channel für deine Vorfälle erstellen, deinen Slack-Channeln Vorfallsverantwortliche hinzufügen, Vorfallsprioritäten aktualisieren, Vorfallmaßnahmen ergreifen und dein Team dabei unterstützen, schneller auf Vorfälle zu reagieren.
So erstellst du einen Slack-Channel für einen Vorfall:
- Navigiere zu dem Vorfall, für den du einen Slack-Channel erstellen möchtest.
- Wähle im Abschnitt "Details" des Vorgangs Create channel (Channel erstellen) aus.
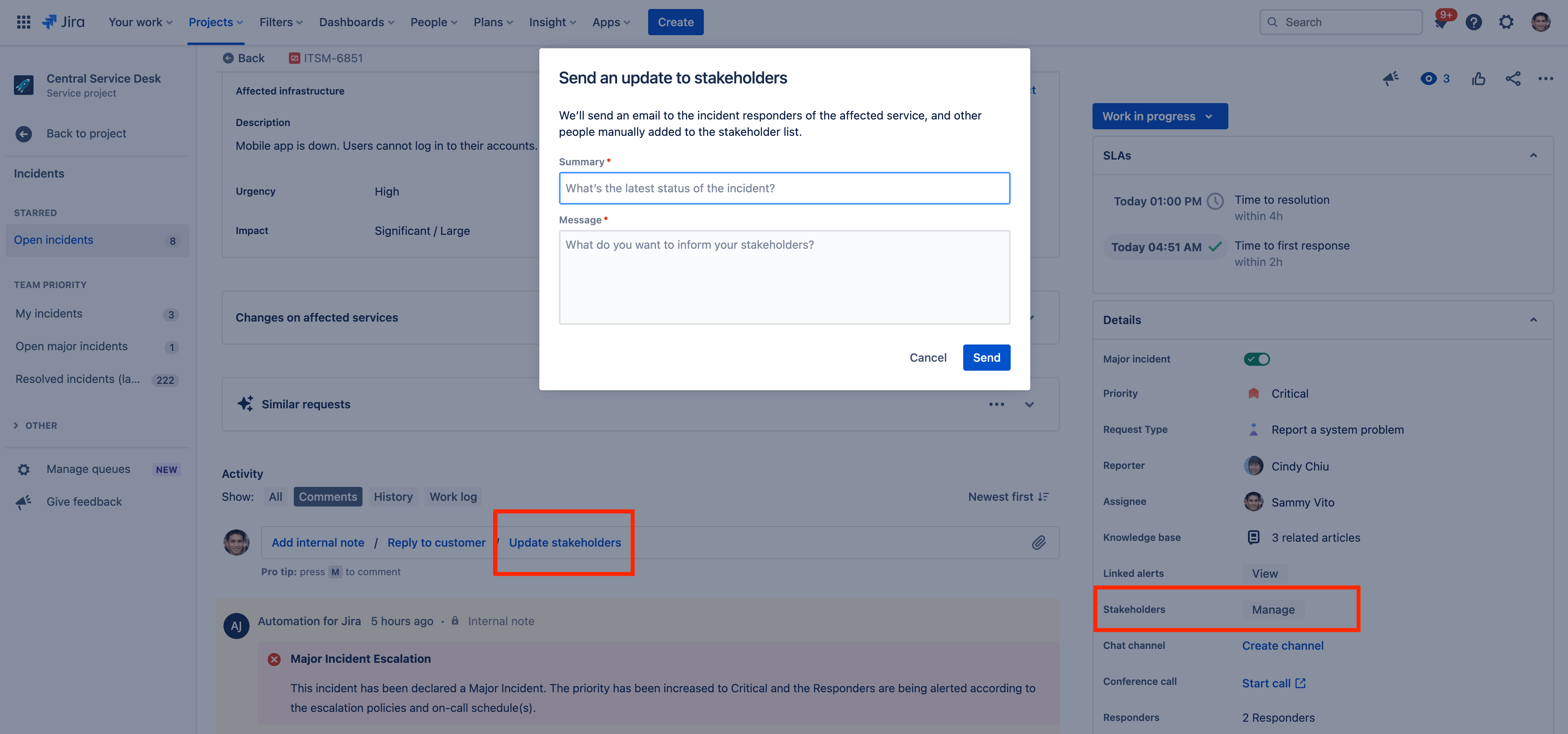
So sendest du Vorfall-Updates an interne Stakeholder
Interne Stakeholder zählen nicht zu den Reagierenden, müssen aber dennoch über den Fortschritt des Vorfalls im Bilde sein, um Vorkehrungen und Maßnahmen treffen zu können. Jira Service Management ermöglicht es dir, Personen als Stakeholder hinzuzufügen und sie über E-Mails auf dem Laufenden zu halten.
So kannst du interne Stakeholder hinzufügen/entfernen:
- Navigiere zu dem Vorfall, dem du interne Stakeholder hinzufügen möchtest.
- Wähle unter "Details" neben dem Feld "Stakeholder" die Option Verwalten aus.
- Suche nach Personen, die du als Stakeholder hinzufügen möchtest.
So sendest du ein Update an interne Stakeholder:
- Wähle im Abschnitt Aktivitäten in der Vorgangsansicht Update an Stakeholder senden aus.
- Gib eine Zusammenfassung und eine Nachricht ein.
- Wähle Senden aus.
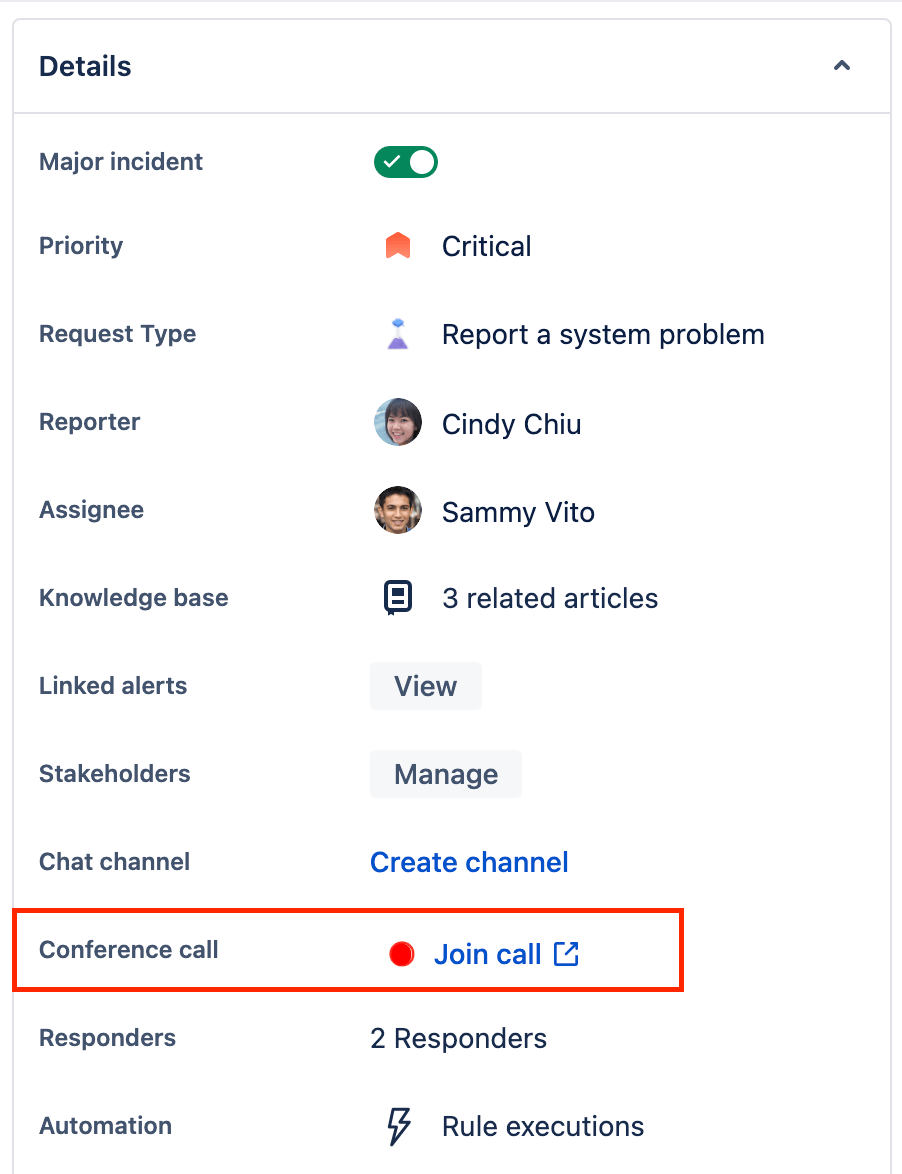
So bearbeitest du Vorfälle mit deinem Team in Telefonkonferenzen
Jira Service Management bietet die Möglichkeit für Video-/Telefonkonferenzen, um Vorfälle an einem zentralen Ort zu koordinieren und verwalten.
So startest du eine Telefonkonferenz:
- Navigiere zu dem Vorfall, zu dem du eine Telefonkonferenz starten möchtest.
- Wähle unter "Details" neben dem Feld "Telefonkonferenz" die Option "Anruf starten" oder "Anruf beitreten" bei einem laufenden Anruf) aus.
Erfahre, wie du PIRs (Post-Incident Reviews – Überprüfungen nach Vorfällen) erstellst und auf diese zugreifst
PIRs sind ein wichtiger Schritt im Lebenszyklus eines ständig verfügbaren Services. Sie ermöglichen es dir, Schwachstellen in deinem System zu finden, wiederholte Vorfälle zu stoppen und die Zeit für die Behebung eines Vorfalls zukünftig zu reduzieren. Die Erkenntnisse der Überprüfung sollten in deinen Planungsprozess einfließen, damit sichergestellt ist, dass kritische Behebungen bei zukünftigen Aufgaben bedacht werden. Die Dokumentation des Vorfalls und seiner Lösung gibt Hinweise darauf, wie mit zukünftigen Vorfällen umgegangen werden sollte. Teams können langfristige Lösungen für Probleme, die zu einem Vorfall führen, erstellen und den PIR mit dem Vorfall in Jira Service Management verknüpfen.
So aktivierst du die PIR-Funktion:
- Navigiere zu Projekteinstellungen > Funktionen.
- Aktiviere Überprüfungen nach Vorfällen unter ITSM-Kategorien.
Durch die Aktivierung dieser Kategorie hast du Zugriff auf neue Funktionen für deine Anfragen. Bevor du loslegen kannst, musst du einen neuen Anfragetyp erstellen oder deine bestehenden Anfragetypen der PIR-Kategorie zuweisen.
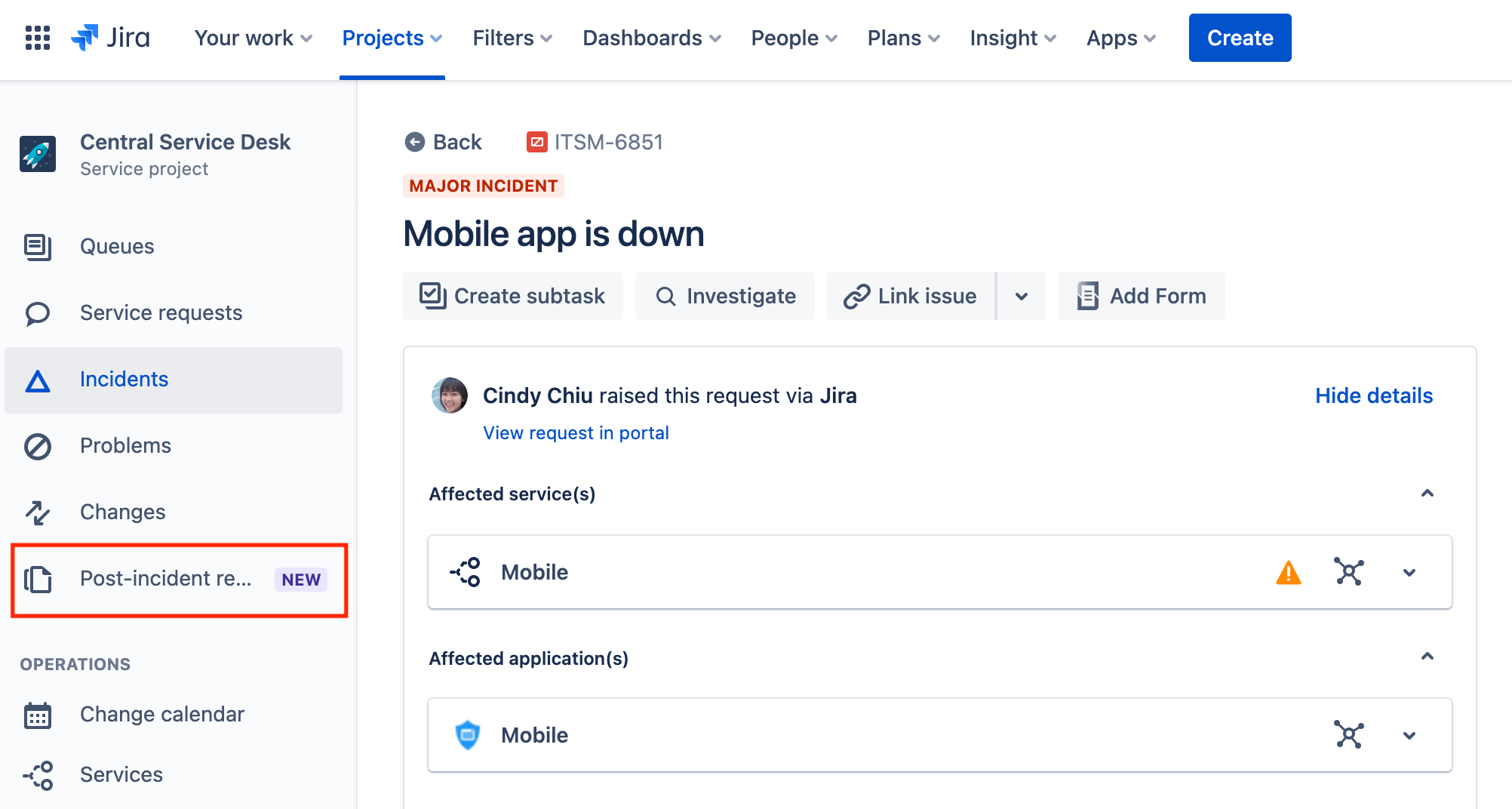
So kannst du auf deine PIRs zugreifen:
- Wähle Überprüfungen nach Vorfällen in der Seitenleiste deines Projekts aus.
- Wähle die entsprechende Warteschlange für PIRs aus.
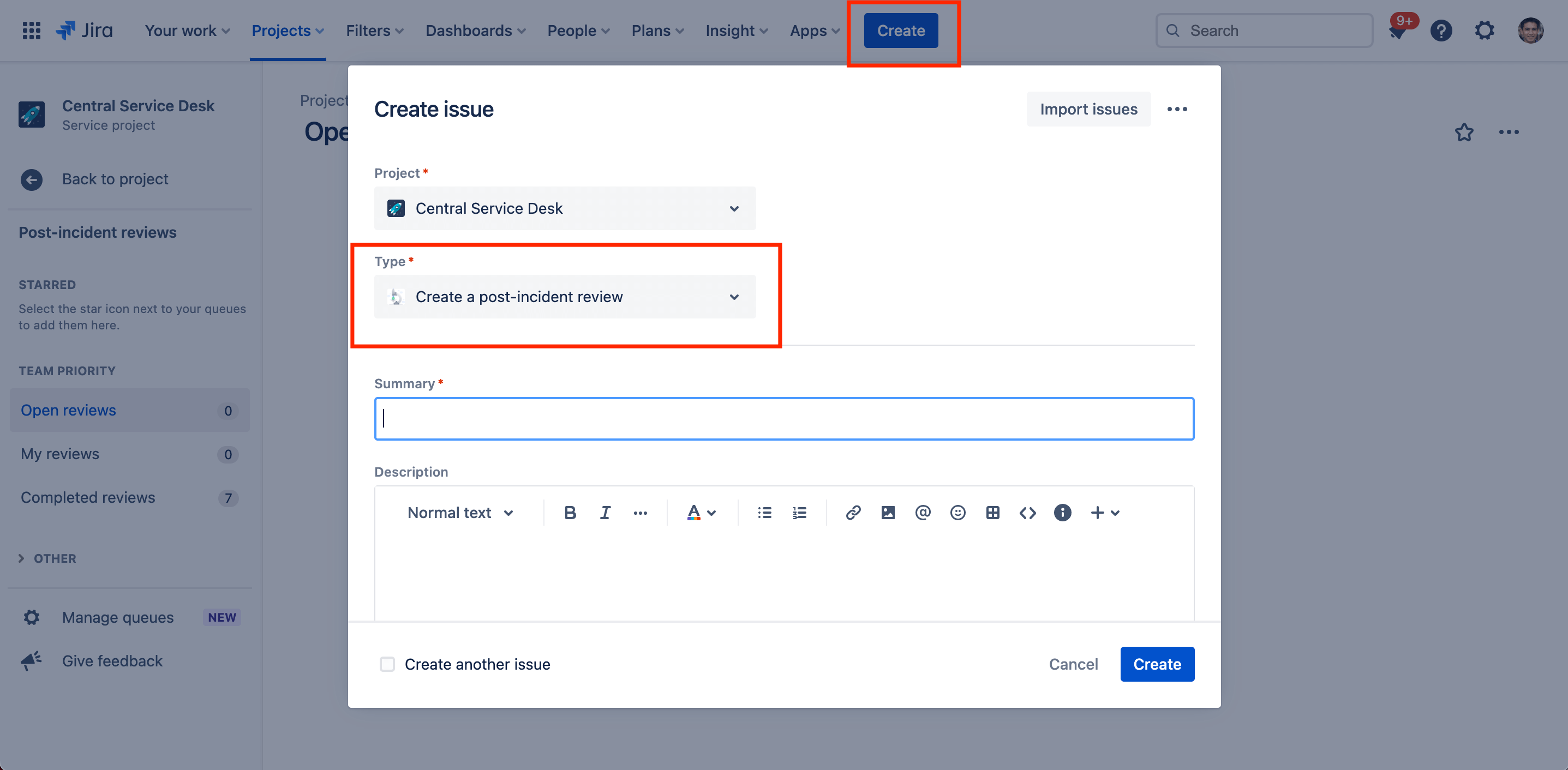
So erstellst du einen neuen PIR:
- Wähle in der oberen Menüleiste Erstellen aus.
- Wähle den von dir festgelegten PIR-Anfragetyp aus dem Drop-down-Menü aus.
- Trage die erforderlichen Informationen ein und verknüpfe den entsprechenden Vorfall mit dem PIR im Feld Verknüpfte Vorgänge.
- Wähle Erstellen aus, sobald du fertig bist.
Profi-Tipp: PIRs können auch mit der nativen Automation-Engine von Jira Service Management erstellt werden. Du kannst zum Beispiel eine Automatisierungsregel einrichten, damit jedes Mal, wenn dein Team einen größeren oder kritischen Vorfall löst, ein PIR erstellt wird.
So verknüpfst du mehrere Vorfälle mit einem Problembericht
Mit Jira Service Management kannst du mehrere Probleme miteinander verknüpfen. Du hast beispielsweise die Möglichkeit, mehrere Vorfalldatensätze mit einem größeren Problembericht zu verknüpfen.
Befolge diese Schritte, um mehrere Vorfälle mit einem Problembericht zu verknüpfen:
- Rufe den Vorfalldatensatz auf.
- Wähle Vorgang verknüpfen.
- Wähle im Feld Verknüpfter Vorgang die Option Wird verursacht von aus.
- Gib den Vorgang, den du verknüpfen möchtest, in das Feld Vorgang ein (oder wähle ihn aus dem Drop-down-Menü aus).
- Wähle Verknüpfen aus.
Best Practices und Tipps für das Vorfallmanagement
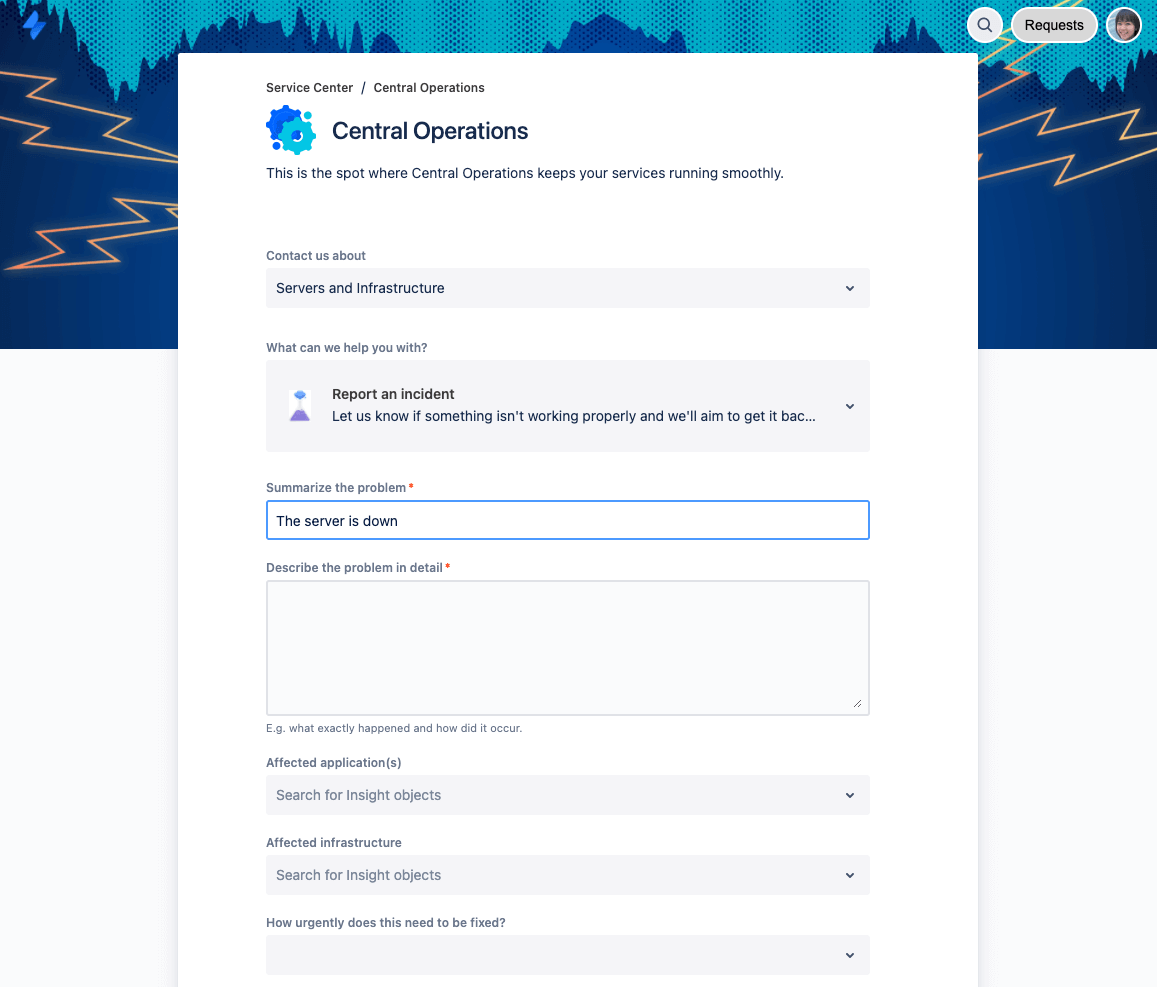
Leichtere Erfassung der von Benutzern oder vom System gemeldeten Vorfälle
Jira Service Management dient als Informationsquelle sowohl für kleinere als auch größere Vorfälle. Das Kundenportal erfasst von Benutzern gemeldete Vorfälle vollständig und konsistent mit allen vom Supportteam zur Bewertung des Vorfalls benötigten Informationen. Wenn Mitarbeiter oder Kunden einen Vorfall bemerken, können sie diesen in Jira Service Management melden. Von dort werden Vorfälle an die richtigen Agentenwarteschlangen weitergeleitet.
Für die Früherkennung von Vorfällen und Ausfällen dient ein effektives Monitoring dem IT-Betriebsteam als Augen und Ohren. Für vom System erkannte Vorfälle sind über 200 App- und Webservices wie Slack, Datadog, Sumo, Logic und Nagios in Jira Service Management leicht integrierbar, um Daten aus Warnmeldungen zu synchronisieren und den Vorfall-Workflow zu optimieren.
Reduzieren Sie Alarm-Fatigue mit intelligenter Bereitschaftsplanung.
Wenn die Bereitschaftsmitarbeiter in einer Flut irrelevanter Warnmeldungen versinken, entwickeln sie eine gewisse Alarm-Fatigue und es besteht die Gefahr, dass sie wichtige Benachrichtigungen übersehen. Die integrierten Vorfallmanagementfunktionen von Jira Service Management sorgen dafür, dass dein Team niemals einen kritischen Alarm verpasst.
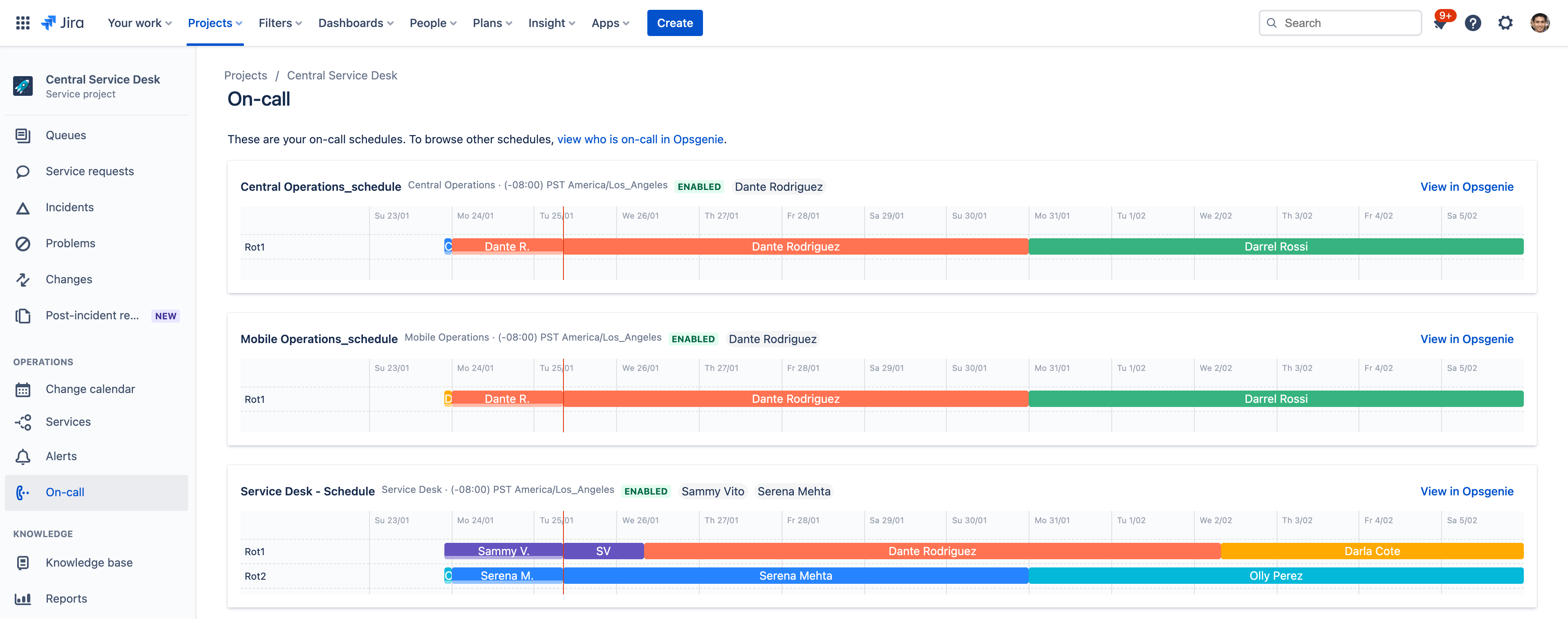
Über nur eine Oberfläche kannst du Pläne erstellen und Eskalationsregeln festlegen. So weiß dein Team bei Vorfällen immer, wer gerade Bereitschaft hat und zuständig ist. Die Lösung fasst Warnmeldungen zu Gruppen zusammen, filtert Unwichtiges heraus und benachrichtigt Teammitglieder über mehrere Kanäle, wie SMS, Anrufe, Push-Nachrichten auf Mobilgeräte oder E-Mail, zusammen mit relevantem Kontext für einen umgehenden Beginn der Problemlösung.
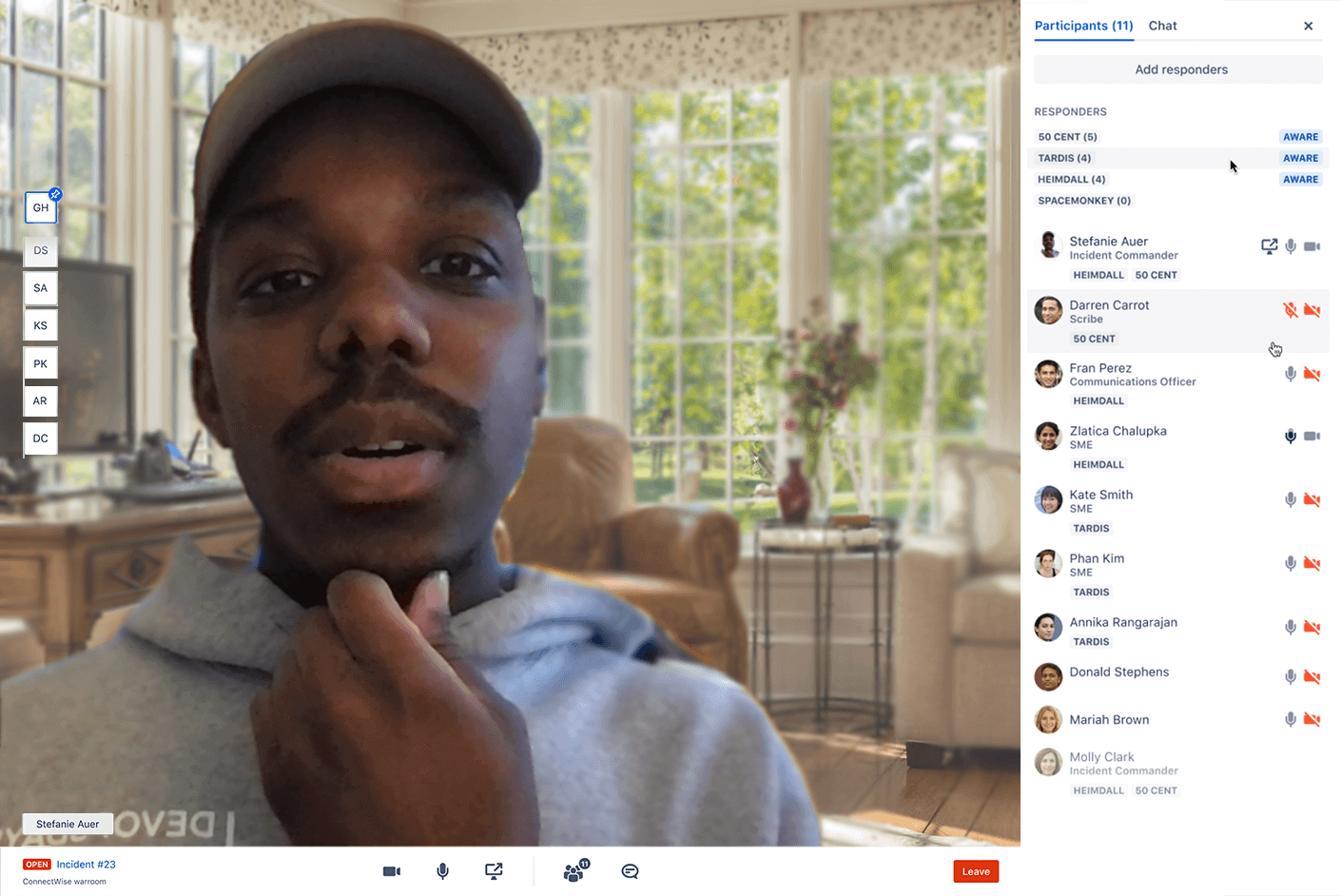
Verbessern Sie mit ChatOps und Runbooks die Teamkoordinierung.
Jira Service Management bietet Teams mit dem Incident Command Center einen zentralen Ort für die Zusammenarbeit, den Informationsaustausch in Echtzeit und schnelle Lösungen. Anstatt sich durch fragmentierte persönliche Chat-Updates oder lange Gesprächsverläufe zu wühlen, kannst du direkt über die Benutzeroberfläche einen Videokonferenzraum für dynamische Teamunterhaltungen vordefinieren, Rollen zuweisen und sogar Entscheidungen treffen. Das Anhängen von Runbooks an Warnmeldungen ermöglicht Teams, schnell automatisch oder On-Demand mit der Fehlerbehebung zu beginnen.
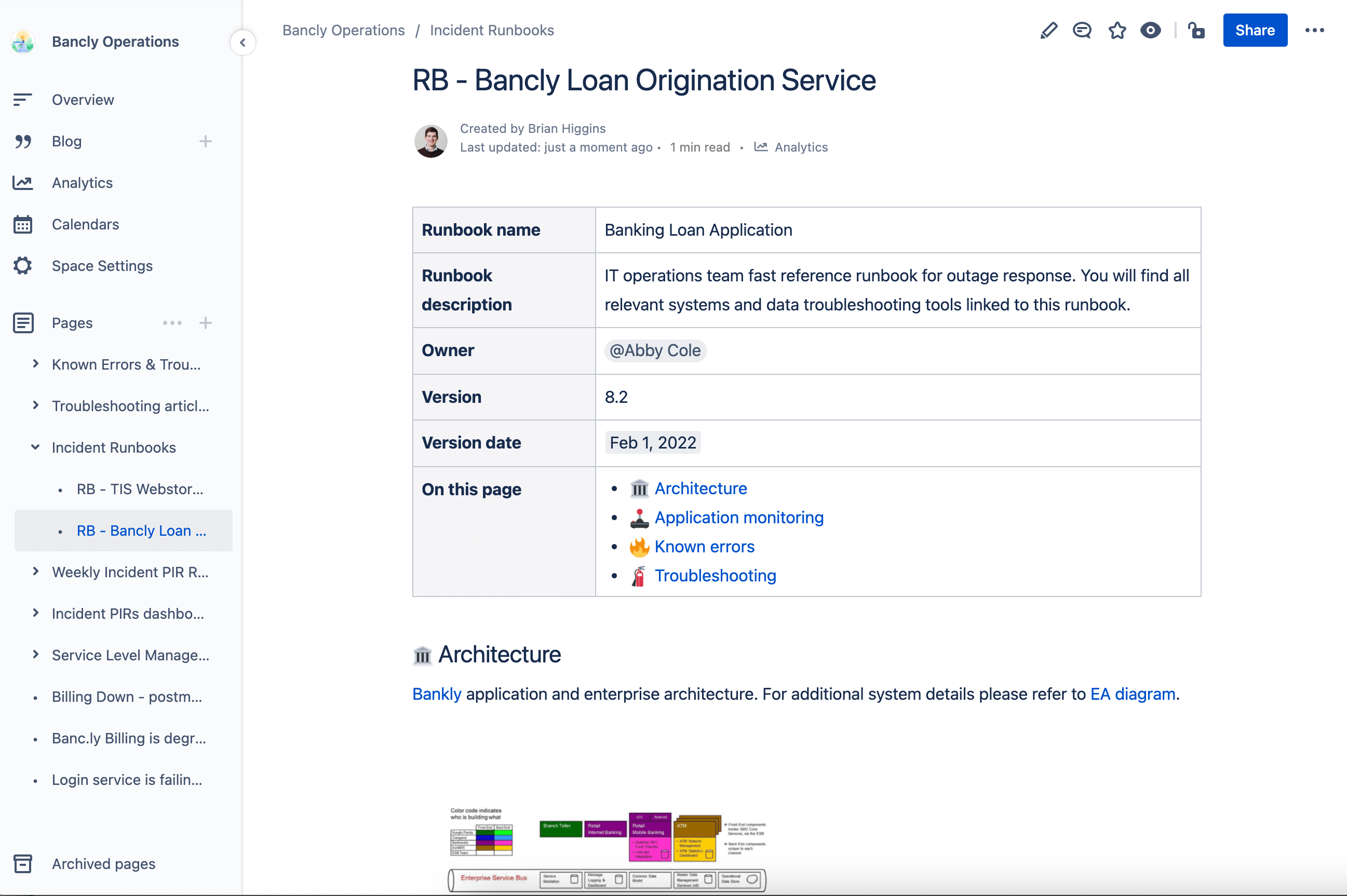
Runbooks sind ebenfalls hervorragend für die Dokumentation gängiger Fehlerbehebungsmethoden zur Reaktion auf Warnmeldungen und Bearbeitung von Ausfällen geeignet. Mit Runbooks stehen deinen Mitarbeitern sofort alle Informationen zur Verfügung, die sie zur schnellen Selektierung von Vorfällen benötigen. In vielen Fällen können die Teams die Vorfallslösungszeiten um 40 % verkürzen.
Erstellen Sie ein proaktives Incident Management Playbook.
Plane deine Incident-Response-Strategie im Voraus. So sorgst du für weniger Stress, dein Team verliert während Vorfällen nicht den Fokus und die Problemlösungszeiten verkürzen sich. Beziehe unbedingt betriebliche und teambasierte Zusammenarbeitspraktiken mit ein:
- Bringe in Erfahrung, welche Werte für dein Team bei der Incident Response besonders wichtig sind, und erarbeite einen Plan, damit diese Werte konsequent umgesetzt werden können. Solche Werte können zum Beispiel sein: Zusammenarbeit, Kommunikation und PIRs ohne Schuldzuweisungen.
- Definieren Sie eindeutig, was als Major Incident gilt.
- Dokumentieren Sie Ihre Major Incident Practices.
- Etabliere eine Incident-Response-Kommunikation, wie z. B. Response-Vorlagen und Mitteilungen für Stakeholder (extern und intern).
- Bestimmen Sie das Kernteam für Ihr Incident-Response-Team-of-Teams.
- Legen Sie Ihre PIR-Practices fest.
- Führen Sie für alle Major Incidents PIRs ohne Schuldzuweisungen durch.
- Veröffentlichen und teilen Sie Erkenntnisse aus den PIRs.
- Führen Sie Simulationsübungen zu Major Incidents durch.
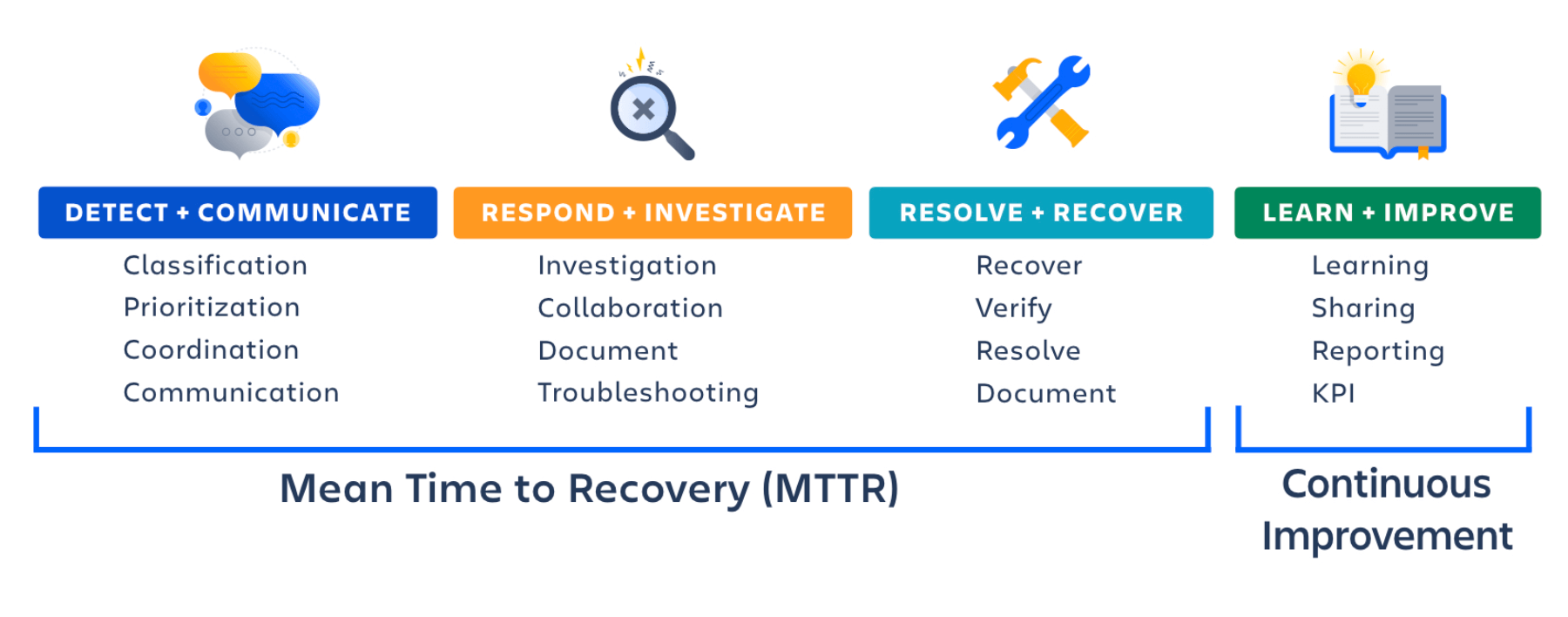
Fokus auf die Verbesserung der mittleren Wiederherstellungszeit (MTTR)
Ein leistungsstarker Vorfallmanagementprozess ist entscheidend für eine Reduktion der Auswirkungen von Vorfällen und die schnelle Wiederherstellung der Services. Der Schlüssel zu einer besseren Reaktion ist die Verkürzung der mittleren Wiederherstellungszeit (MTTR) und Optimierung der Ursachenanalyse zur Vermeidung zukünftiger Ausfälle. Eine Forrester-Studie ergab, dass 70 % der Incident-Response-Zeit für die Nachforschungs- und Diagnosephase verwendet wird.
Bauen Sie mit einer zentralen externen Kommunikation Vertrauen auf.
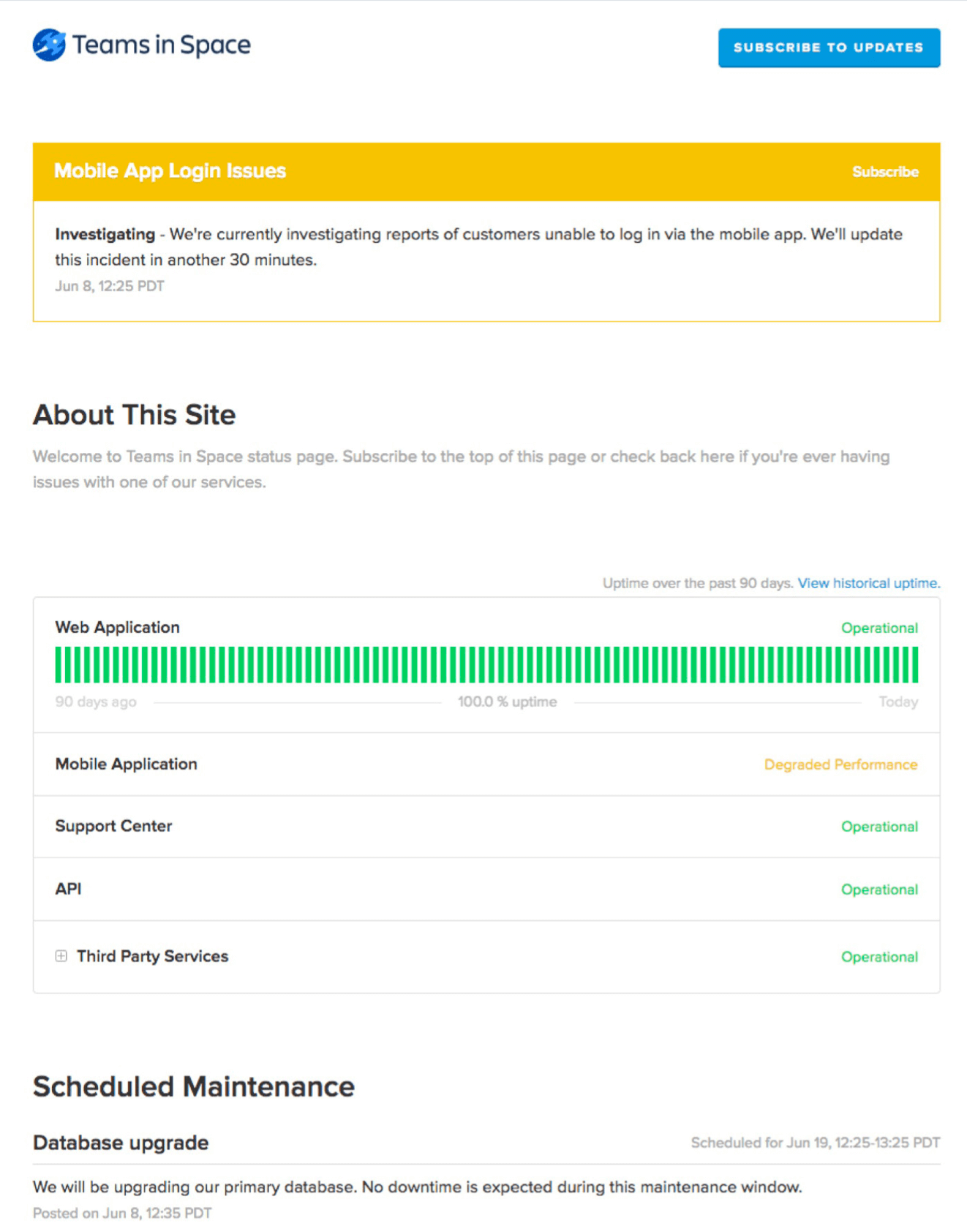
Viele Teams nutzen für Statusmeldungen zu kritischen Services ein zentrales Dashboard wie Statuspage. Statuspage dient als einziger Kanal für eine klare, proaktive Massenkommunikation mit internen und externen Benutzern sowie für automatisierte Benachrichtigungen und Updates.
Statuspage hält interne Teams zu geplanten und ungeplanten Ausfällen auf dem Laufenden. Kunden und Mitarbeiter können Updates abonnieren, was für eine einheitliche Kommunikation sorgt und den Bedarf an manuellen Updates reduziert.
Weitere Informationen findest du auf unserer Seite "Best Practices für das Vorfallmanagement".
Erste Schritte
Management von Serviceanfragen
Erste Schritte
Problemmanagement