Continuous delivery pipeline 101
Learn how automated builds, tests and deployments are chained together in one release workflow.

Juni Mukherjee
Developer Advocate
What is a continuous delivery pipeline?
A continuous delivery pipeline is a series of automated processes for delivering new software. It’s an implementation of the continuous paradigm, where automated builds, tests, and deployments are orchestrated as one release workflow. Put more plainly, a CD pipeline is a set of steps your code changes go through to make their way to production.
A CD pipeline delivers, as per business needs, quality products frequently and predictably from test to staging to production in an automated fashion.
For starters, let’s focus on the three concepts: quality, frequency, and predictability.
We emphasize quality to underscore that it’s not traded for speed. Business doesn’t want us to build a pipeline that can shoot faulty code to production at high speed. We will go through the principles of “Shift Left” and “DevSecOps”, and discuss how we can move quality and security upstream in the software development life cycle (SDLC). This will put to rest any concerns regarding continuous delivery pipelines posing risks to businesses.
Frequency indicates that pipelines execute at any time to release features since they are programmed to trigger with commits to the codebase. Once the pipeline MVP (minimum viable product) is in place, it can execute as many times as it needs to with periodic maintenance costs. This automated approach scales without burning out the team. This also allows teams to make small incremental improvements to their products without the fear of a major catastrophe in production.
See solution
Build and operate software with Open DevOps
Related material
What is the DevOps pipeline?
Cliche as it may sound, the nation of “to err is human” still holds true. Teams brace for impact during manual releases since those processes are brittle. Predictability implies that releases are deterministic in nature when done via continuous delivery pipelines. Since pipelines are programmable infrastructure, teams can expect the desired behavior every time. Accidents can happen, of course, since no software is bug-free. However, pipelines are exponentially better than manual error-prone release processes, since, unlike humans, pipelines don’t falter under aggressive deadlines.
Pipelines have software gates that automatically promote or reject versioned artifacts from passing through. If the release protocol is not honored, software gates remain closed, and the pipeline aborts. Alerts are generated and notifications are sent to a distribution list comprising team members who could have potentially broken the pipeline.
And that’s how a CD pipeline works: A commit, or a small incremental batch of commits, makes its way to production every time the pipeline runs successfully. Eventually, teams ship features and ultimately products in a secure and auditable way.
Phases in a continuous delivery pipeline
The architecture of the product that flows through the pipeline is a key factor that determines the anatomy of the continuous delivery pipeline. A highly coupled product architecture generates a complicated graphical pipeline pattern where various pipelines get entangled before eventually making it to production.
The product architecture also influences the different phases of the pipeline and what artifacts are produced in each phase. Let’s discuss the four common phases in continuous delivery:
Even if you foresee more than four phases or less than four in your organization, the concepts outlined below still apply.
A common misconception is that these phases have physical manifestations in your pipeline. They don’t have to. These are logical phases and can map to environmental milestones like test, staging, and production. For example, components and subsystems could be built, tested, and deployed in the test. Subsystems or systems could be assembled, tested, and deployed in staging. Subsystems or systems could be promoted to production as part of the production phase.
The cost of defects is low when discovered in test, medium when discovered in staging, and high in production. “Shift Left” refers to validations being pulled earlier in the pipeline. The gate from test to staging has far more defensive techniques built-in nowadays, and hence staging doesn’t have to look like a crime scene anymore!
Historically, InfoSec came in at the end of the software development life cycle, when rejected releases can pose cyber-security threats to the company. While these intentions are noble, they caused frustration and delay. “DevSecOps” advocates security be built into products from the design phase, instead of sending a (possibly insecure) finished product for evaluation.
Let’s take a closer look into how “Shift Left” and “DevSecOps” can be addressed within the continuous delivery workflow. In these next sections, we will discuss each phase in detail.
CD component phase
The pipeline first builds components -- the smallest distributable and testable units of the product. For example, a library built by the pipeline can be termed a component. A component can be certified, among other things, by code reviews, unit tests, and static code analyzers.
Code reviews are important for teams to have a shared understanding of the features, tests, and infrastructure needed for the product to go live. A second pair of eyes can often do wonders. Over the years we may get immune to bad code in a way that we don’t believe it’s bad anymore. Fresh perspectives can force us to revisit those weaknesses and refactor them generously wherever needed.
Unit tests are almost always the first set of software tests that we run on our code. They do not touch the database or the network. Code coverage is the percentage of code that has been touched by unit tests. There are many ways to measure coverage, like line coverage, class coverage, method coverage, etc.
While it is great to have good code coverage to ease refactoring, it is detrimental to mandate high coverage goals. Contrary to intuition, some teams with high code coverage have more production outages than teams with lower code coverage. Also, keep in mind that it is easy to game coverage numbers. Under acute pressure, especially during performance reviews, developers can revert to unfair practices to increase code coverage. And I won’t be covering those details here!
Static code analysis detects problems in code without executing it. This is an inexpensive way to detect issues. Like unit tests, these tests run on source code and have low run-time. Static analyzers detect potential memory leaks, along with code quality indicators like cyclomatic complexity and code duplication. During this phase, static analysis security testing (SAST) is a proven way to discover security vulnerabilities.
Define the metrics that control your software gates and influence code promotion, from the component phase to the subsystem phase.
CD subsystem phase
Loosely coupled components make up subsystems - the smallest deployable and runnable units. For example, a server is a subsystem. A microservice running in a container is also an example of a subsystem. As opposed to components, subsystems can be stood up and validated against customer use cases.
Just like a Node.js UI and a Java API layer are subsystems, databases are subsystems too. In some organizations, RDBMS (relational database management systems) is manually handled, even though a new generation of tools have surfaced that automate database change management and successfully do continuous delivery of databases. CD pipelines involving NoSQL databases are easier to implement than RDBMS.
Subsystems can be deployed and certified by functional, performance, and security tests. Let’s study how each of these test types validate the product.
Functional tests include all customer use cases that involve internationalization (I18N), localization (L10N), data quality, accessibility, negative scenarios etc. These tests make sure that your product functions per customer expectations, honors inclusion, and serves the market it’s built for.
Determine your performance benchmarks with your product owners. Integrate your performance tests with the pipeline, and use the benchmarks to pass or fail pipelines. A common myth is that performance tests do not need to integrate with continuous delivery pipelines, however, that breaks the continuous paradigm.
Major organizations have been breached in recent times, and cybersecurity threats are at their highest. We need to buckle up and make sure that there are no security vulnerabilities in our products - be that in the code we write or be that in 3rd-party libraries that we import into our code. In fact, major breaches have been discovered in OSS (open source software) and we should use tools and techniques that flag these errors and force the pipeline to abort. DAST (dynamic analysis security testing) is a proven way to discover security vulnerabilities.
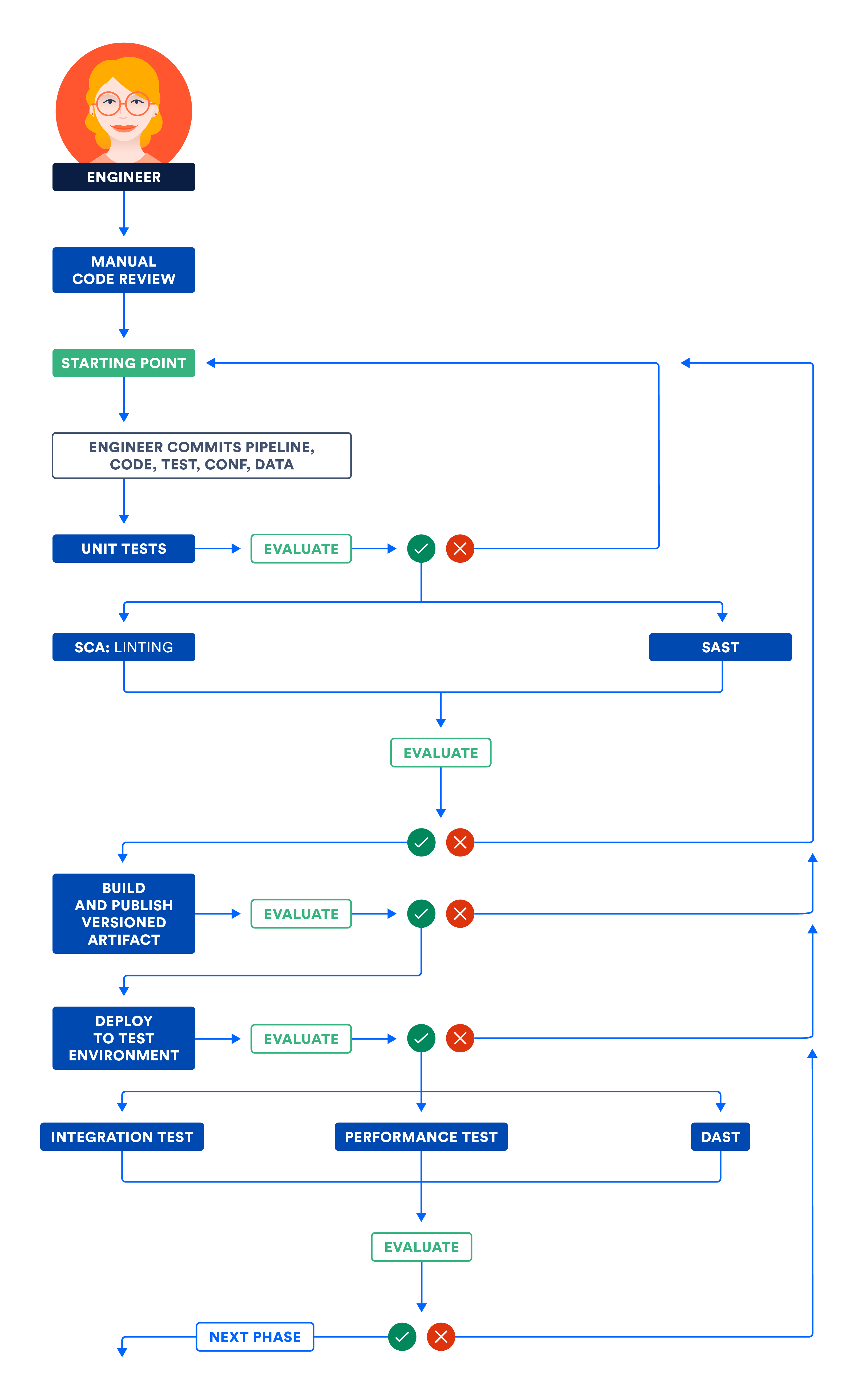
The following illustration articulates the workflow discussed in the Component and Subsystem phases. Run independent steps in parallel to optimize the total pipeline execution time and get fast feedback.
A) Certifying components and/or subsystems in the test environment
CD system phase
Once subsystems meet functional, performance, and security expectations, the pipeline could be taught to assemble a system from loosely coupled subsystems when the entire system is released as a whole. What that means is that the fastest team can go at the speed of the slowest team. This reminds me of the old saying, “a chain is only as strong as its weakest link”.
We recommend against this composition anti-pattern where subsystems are composed into a system to be released as a whole. This anti-pattern ties all the subsystems at their hips for success. If you invest in independently deployable artifacts, you will be able to avoid this anti-pattern.
Where systems need to be validated as a whole, they can be certified by integration, performance, and security tests. Unlike the subsystem phase, do not use mocks or stubs during testing in this phase. Also, it's important to focus on testing interfaces and networks more than anything else.
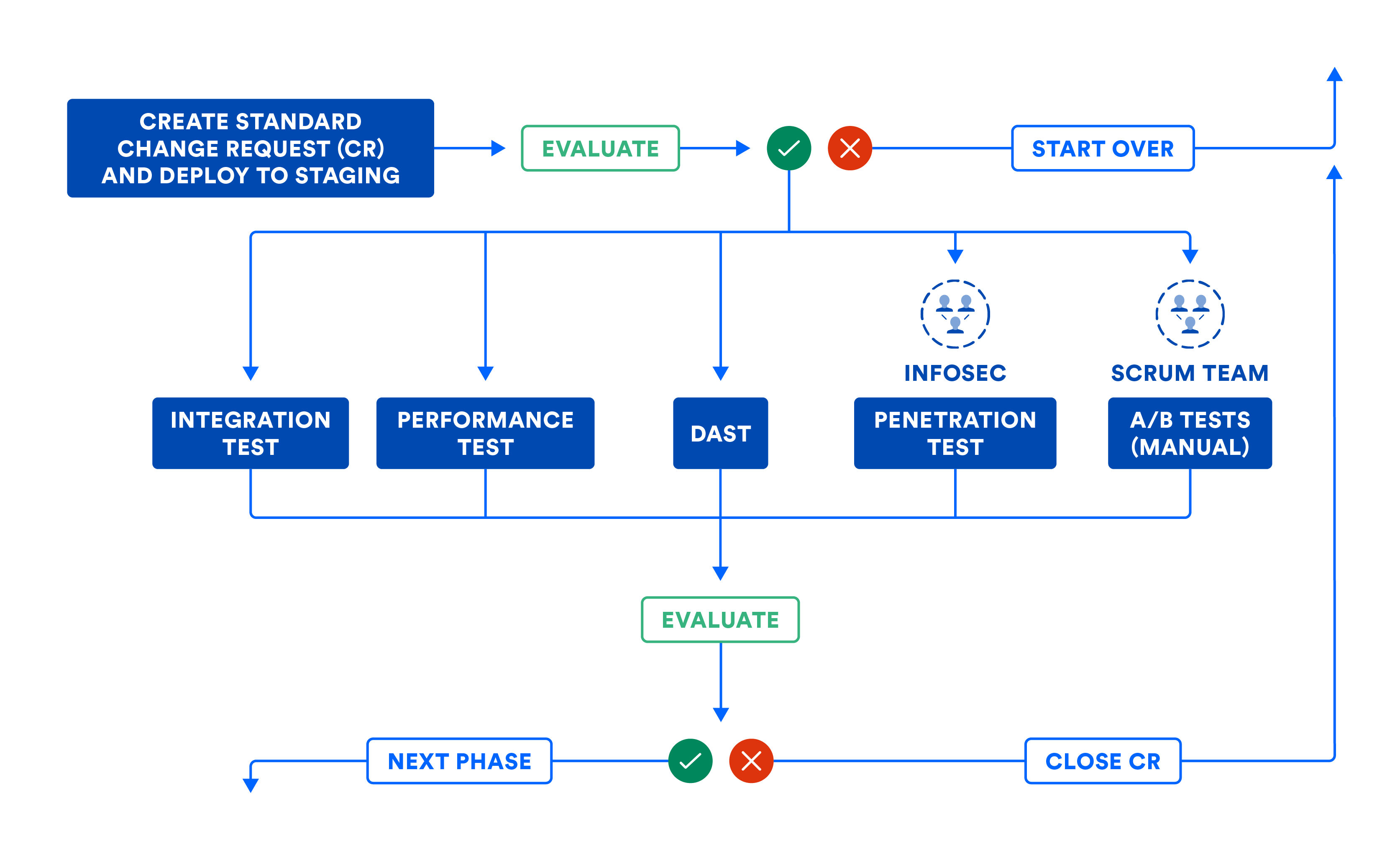
The following illustration summarizes the workflow in the system phase, in case you have to assemble your subsystems using composition. Even if you can roll your subsystems to production, the following illustration helps establish software gates needed to promote code from this phase to the next.
The pipeline can automatically file change requests (CR) to leave an audit trail. Most organizations use this workflow for standard changes, which means planned releases. This workflow should also be used for emergency changes, or unplanned releases, although some teams tend to cut corners. Note how the change request is closed automatically by the CD pipeline when errors force it to abort. This prevents change requests from being abandoned in the middle of the pipeline workflow.
The following illustration articulates the workflow discussed in the CD system phase. Note that some steps could involve human intervention, and these manual steps can be executed as part of manual gates in the pipeline. When mapped in its entirety, the pipeline visualization is a close resemblance to the value stream map of your product releases!
B) CERTIFYING SUBSYSTEMS AND/OR SYSTEM IN THE STAGING ENVIRONMENT
Once the assembled system is certified, leave the assembly unchanged and promote it to production.
CD production phase
Whether subsystems can be independently deployed or assembled into a system, the versioned artifacts are deployed to production as part of this final phase.
Zero downtime deployment (ZDD) prevents downtime for customers and should be practiced from test to staging to production. Blue-green deployment is a popular ZDD technique where the new bits are deployed to a tiny cross-section of the population (called “green”), while the bulk is blissfully unaware of “blue”, which has the old bits. If push comes to shove, revert everyone back to “blue” and very few customers will be affected, if any. If things look good on “green”, dial everyone up slowly from “blue” to “green”.
However, I see manual gates being abused in certain organizations. They require teams to get manual approval in a change approval board (CAB) meeting. The reason is, more often than not, a misinterpretation of segregation of duties or separation of concerns. One department hands off to another seeking approval to move forward. I have also seen some CAB approvers demonstrate a shallow technical understanding of the changes going to production, hence making the manual approval process slow and dreary.
This is a good segway to call out the difference between continuous delivery and continuous deployment. Continuous delivery allows manual gates whereas continuous deployment doesn’t. While both are referred to as CD, continuous deployment requires more discipline and rigor since there is no human intervention in the pipeline.
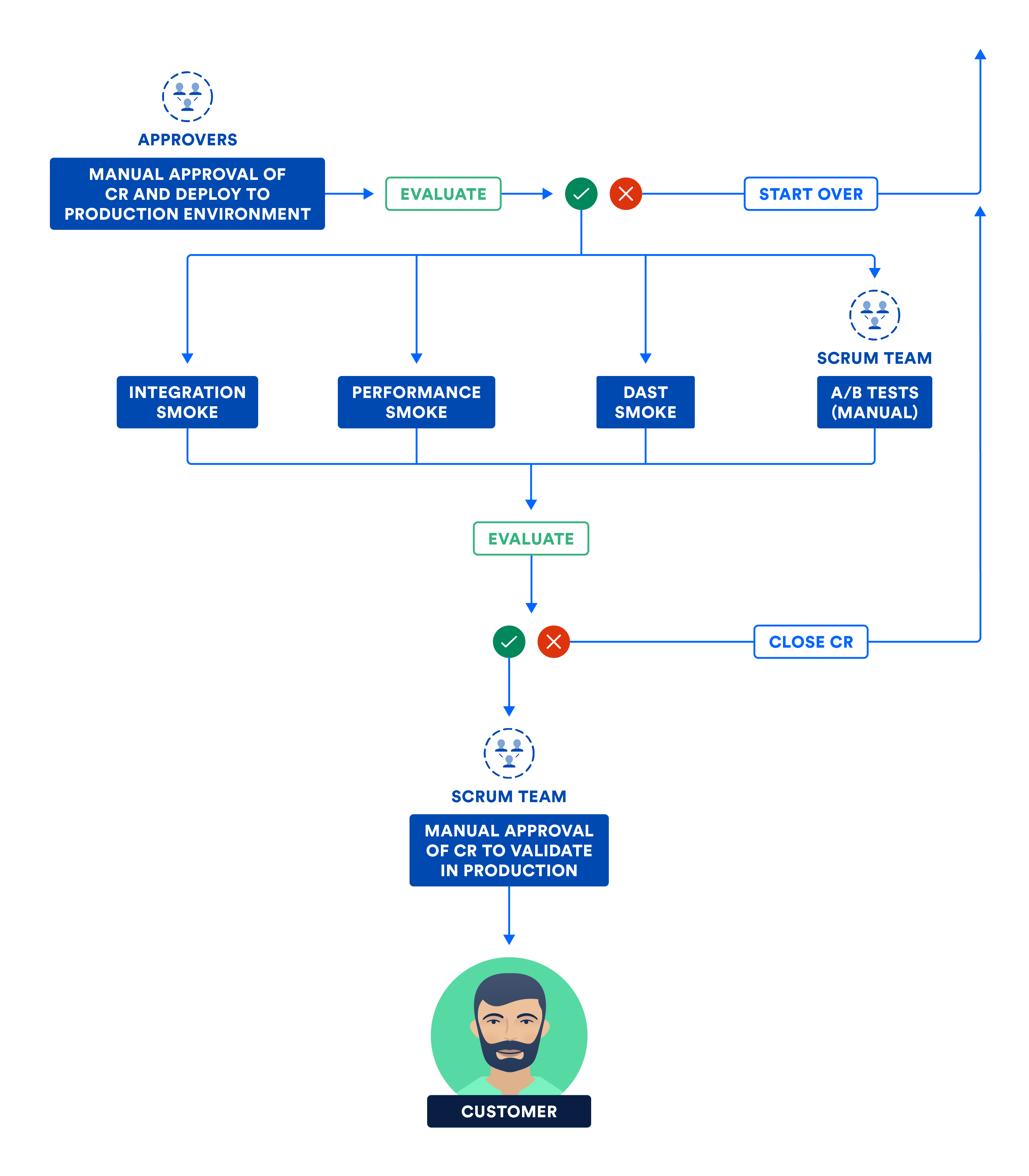
There is a difference between moving the bits and turning them on. Run smoke tests in production, which are a subset of the integration, performance, and security test suites. Once smoke tests pass, the bits turn on, and the product goes live to customers!
The following diagram illustrates the steps carried out by the team in this final phase of continuous delivery.
C) CERTIFYING SUBSYSTEMS AND/OR SYSTEM IN THE PRODUCTION ENVIRONMENT
Continuous delivery is the new normal
To be successful at continuous delivery or continuous deployment, it is critical to do continuous integration and continuous testing well. With a solid foundation, you will win on all three fronts: quality, frequently, and predictability.
A continuous delivery pipeline helps your ideas become products through a series of sustainable experiments. If you discover your idea isn’t as good as you thought it was, you can quickly turn around with a better idea. Additionally, pipelines reduce the mean time to resolve (MTTR) production issues, thus reducing downtime for your customers. With continuous delivery, you end up with productive teams and satisfied customers, and who doesn’t want that?
Learn more in our Continuous Delivery tutorial.
Share this article
Next Topic
Recommended reading
Bookmark these resources to learn about types of DevOps teams, or for ongoing updates about DevOps at Atlassian.

DevOps community

Read the blog