ATLASSIAN CLOUD
Atlassian Cloud architecture and operational practices
Learn more about the Atlassian Cloud architecture and the operational practices we use
Introduction
Atlassian cloud apps and data are hosted on industry-leading cloud provider Amazon Web Services (AWS). Our products run on a platform as a service (PaaS) environment that is split into two main sets of infrastructure that we refer to as Micros and non-Micros. Jira, Confluence, Jira Product Discovery, Statuspage, Guard, and Bitbucket run on the Micros platform, while Opsgenie and Trello run on the non-Micros platform.
Distributed services architecture
With this AWS architecture, we host a number of platform and product services that are used across our solutions. This includes platform capabilities that are shared and consumed across multiple Atlassian products, such as Media, Identity, and Commerce, experiences such as our Editor, and product-specific capabilities, like Jira Work Item service and Confluence Analytics.
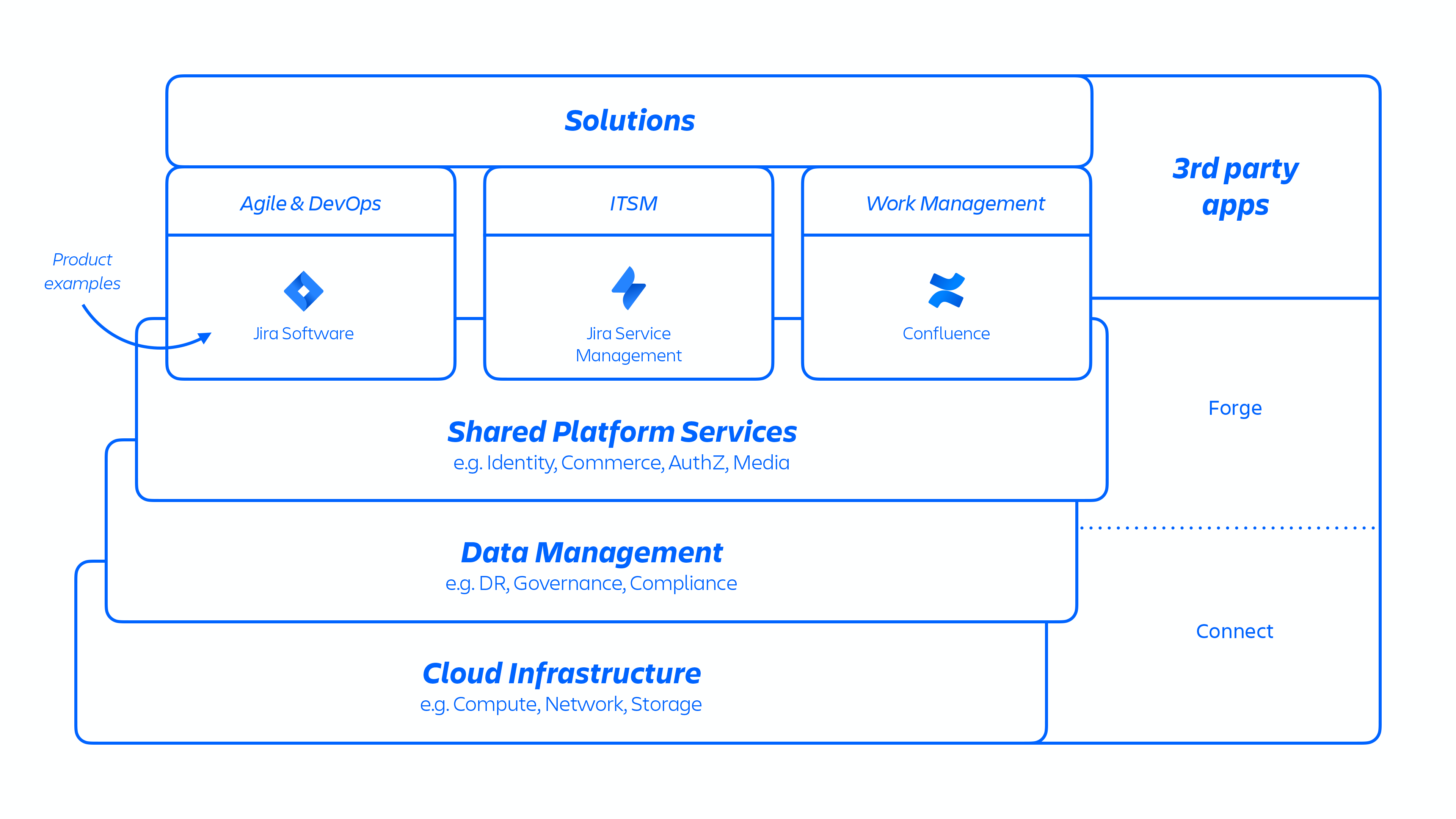
Figure 1
Atlassian developers provision these services either through kubernetes or using an internally developed platform-as-a-service (PaaS), called Micros, both of which automatically orchestrates the deployment of shared services, infrastructure, data stores, and their management capabilities, including security and compliance control requirements (see figure 1 above). Typically, an Atlassian product consists of multiple "containerized" services that are deployed on AWS using Micros or kubernetes. Atlassian products use core platform capabilities (see figure 2 below) that range from request routing to binary object stores, authentication/authorization, transactional user-generated content (UGC) and entity relationships stores, data lakes, common logging, request tracing, observability, and analytical services. These micro-services are built using approved technical stacks standardized at the platform level:
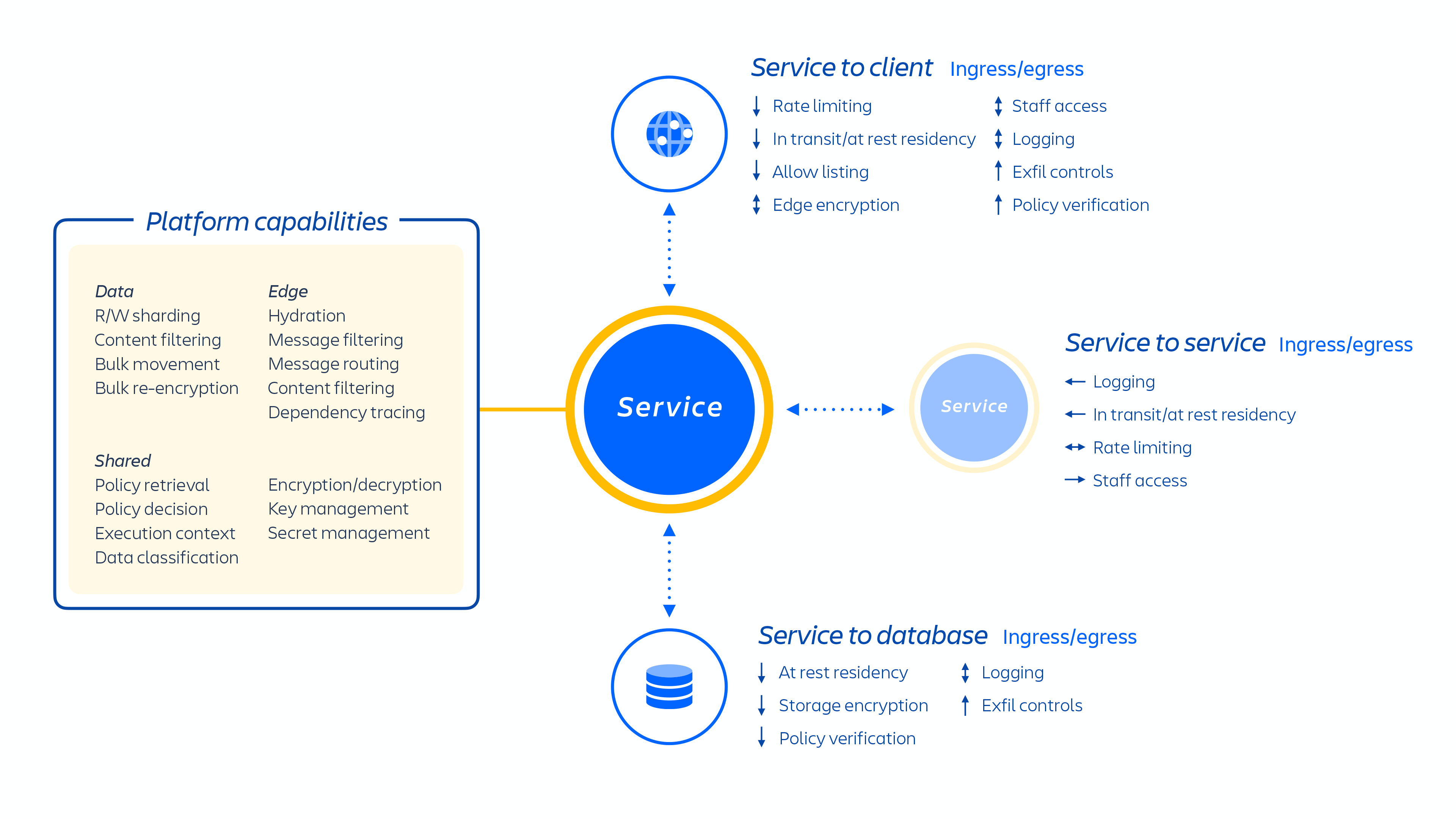
Figure 2
Multi-tenant architecture
On top of our cloud infrastructure, we built and operate a multi-tenant micro-service architecture along with a shared platform that supports our products. In a multi-tenant architecture, a single service serves multiple customers, including databases and compute instances required to run our cloud apps. Each shard (essentially a container – see figure 3 below) contains the data for multiple tenants, but each tenant's data is isolated and inaccessible to other tenants. It is important to note that we do not offer a single tenant architecture.
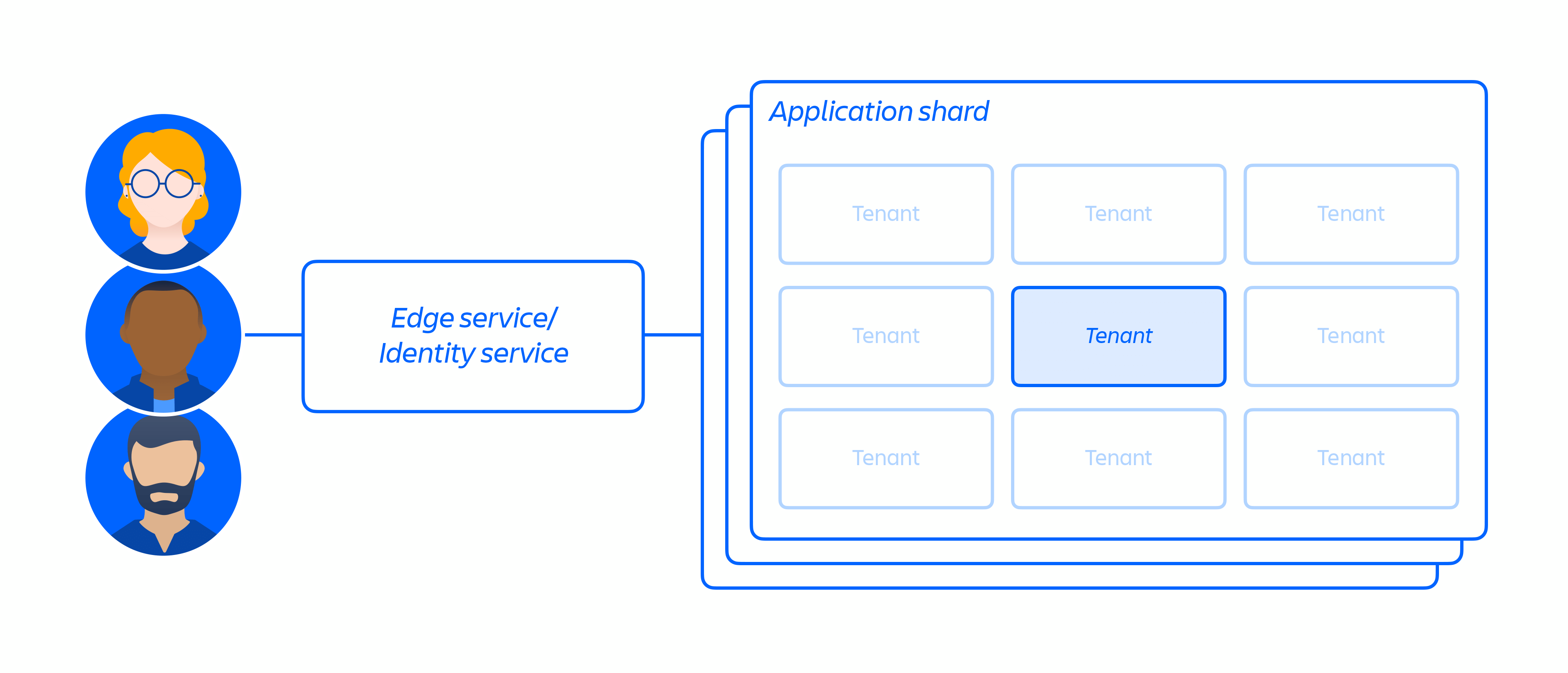
Figure 3
Our microservices are built with least privilege in mind and designed to minimize the scope of any zero-day exploitation and to reduce the likelihood of lateral movement within our cloud environment. Each microservice has its own data storage that can only be accessed with the authentication protocol for that specific service, which means that no other service has read or write access to that API.
We’ve focused on isolating microservices and data, rather than providing dedicated per-tenant infrastructure because it narrows the access to a single system’s narrow purview of data across many customers. Because the logic has been decoupled and data authentication and authorization occurs at the application layer, this acts as an additional security check as requests are sent to these services. Thus, if a microservice is compromised, it will only result in limited access to the data a particular service requires.
Tenant provisioning and lifecycle
When a new customer is provisioned, a series of events trigger the orchestration of distributed services and provisioning of data stores. These events can be generally mapped to one of seven steps in the lifecycle:
1. Commerce systems are immediately updated with the latest metadata and access control information for that customer, and then a provisioning orchestration system aligns the "state of the provisioned resources" with the license state through a series of tenant and product events.
Tenant events
These events affect the tenant as a whole and can either be:
- Creation: a tenant is created and used for brand new sites
- Destruction: an entire tenant is deleted
Product events
- Activation: after the activation of licensed products or third-party apps
- Deactivation: after the de-activation of certain products or apps
- Suspension: after the suspension of a given existing product, thus disabling access to a given site that they own
- Un-suspension: after the un-suspension of a given existing product, thus enabling access to a site that they own
- License update: contains information regarding the number of license seats for a given product as well as its status (active/inactive)
2. Creation of the customer site and activation of the correct set of products for the customer. The concept of a site is the container of multiple products licensed to a particular customer. (e.g. Confluence and Jira Software for <site-name>.atlassian.net).
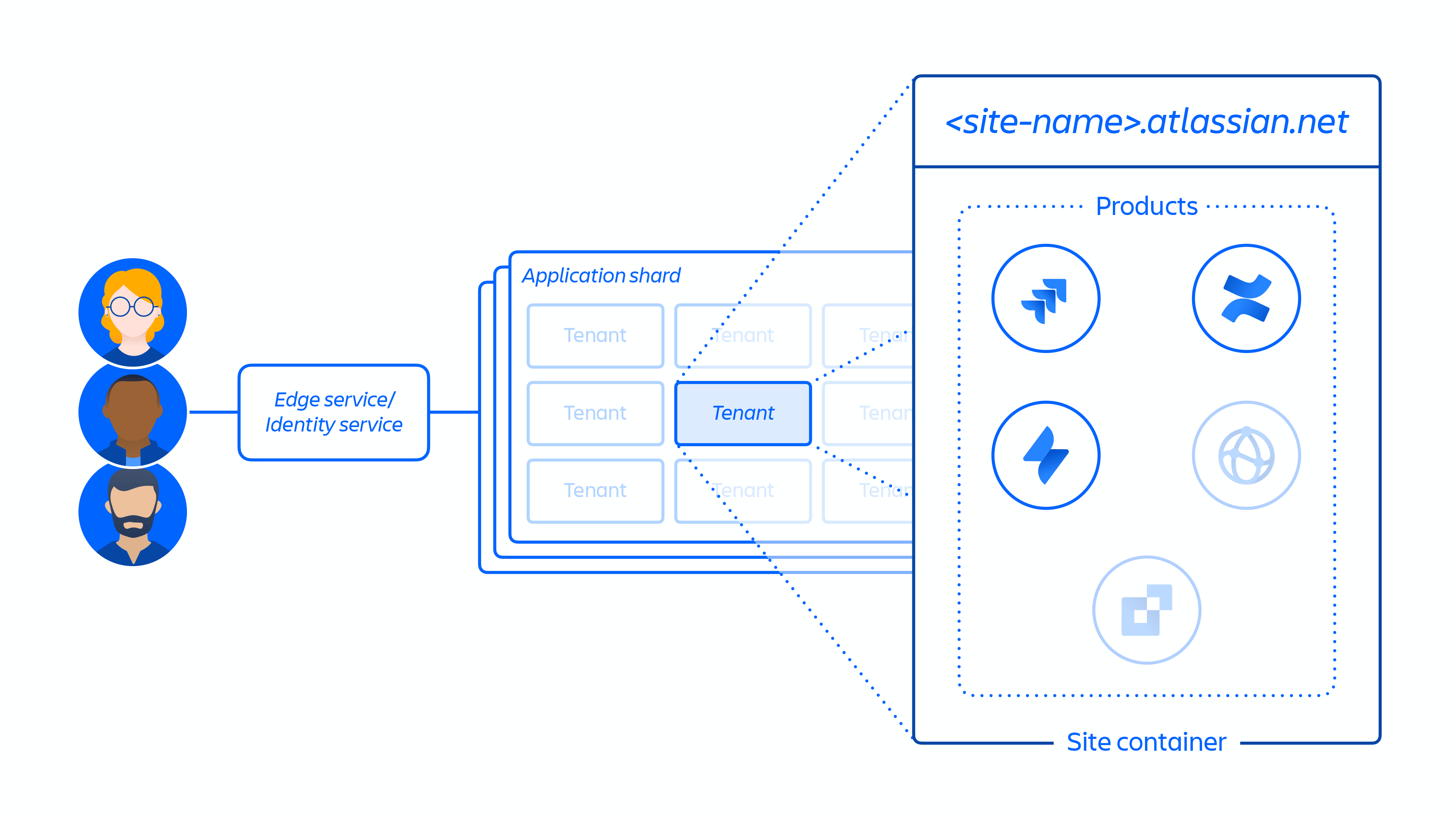
Figure 4
3. Provisioning of products within the customer site in the designated region.
When a product is provisioned it will have the majority of its content hosted close to where users are accessing it. To optimize product performance, we don't limit data movement when it's hosted globally and we may move data between regions as needed.
For some of our products, we also offer data residency. Data residency allows customers to choose whether product data is globally distributed or held in place in one of our defined geographic locations.
4. Creation and storage of the customer site and product(s) core metadata and configuration.
5. Creation and storage of the site and product(s) identity data, such as users, groups, permissions, etc.
6. Provisioning of product databases within a site, e.g. Jira family of products, Confluence, Compass, Atlas.
7. Provisioning of the product(s) licensed apps.
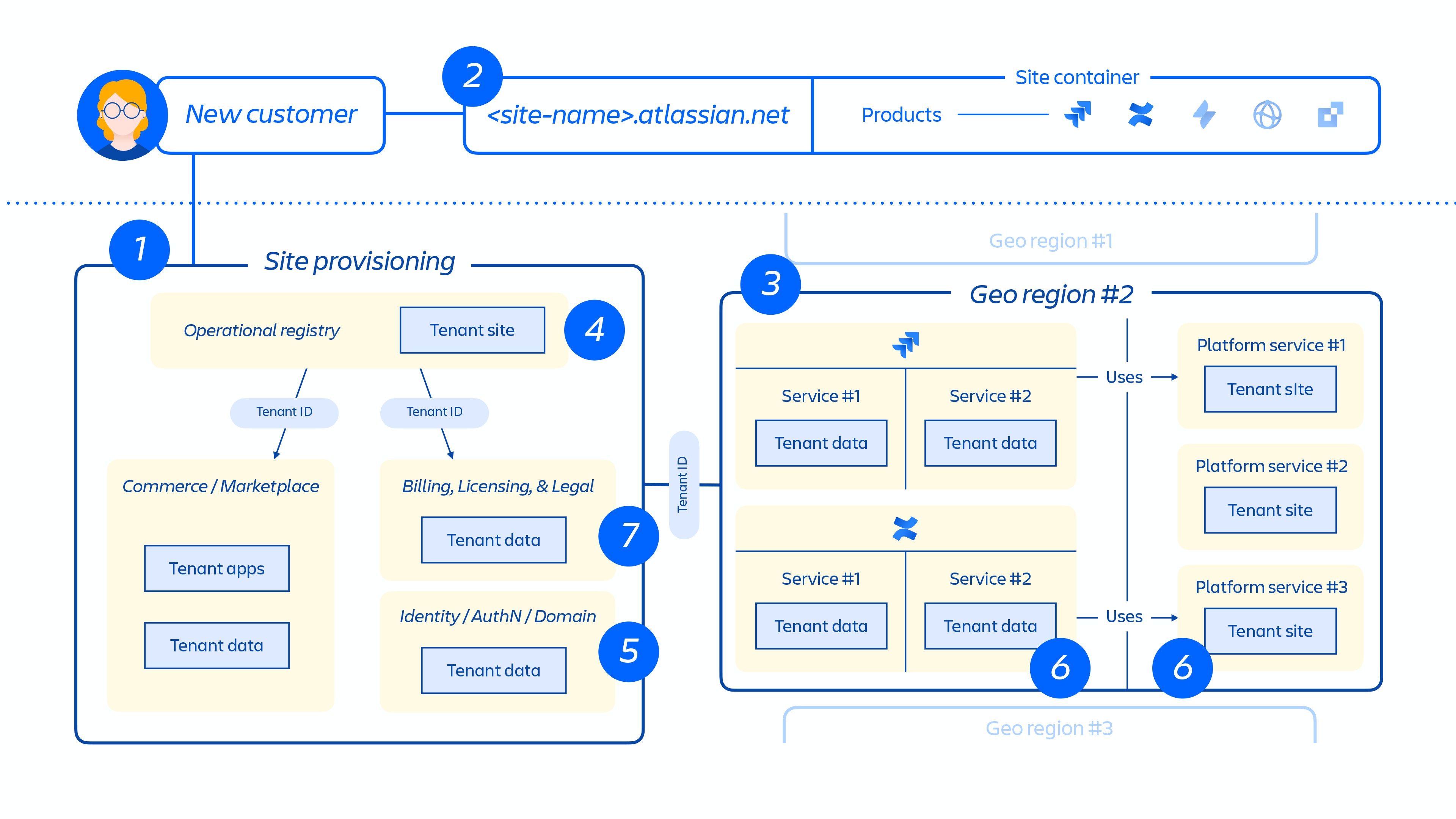
Figure 5
Figure 5 above demonstrates how a customer's site is deployed across our distributed architecture, not just in a single database or store. This includes multiple physical and logical locations that store meta-data, configuration data, product data, platform data and other related site info.