Atlassian Cloud
Atlassian Cloud 架构和运营实践
详细了解 Atlassian Cloud 架构以及我们采用的运营实践
简介
Atlassian cloud apps and data are hosted on industry-leading cloud provider Amazon Web Services (AWS). Our products run on a platform as a service (PaaS) environment that is split into two main sets of infrastructure that we refer to as Micros and non-Micros. Jira, Confluence, Jira Product Discovery, Statuspage, Guard, and Bitbucket run on the Micros platform, while Opsgenie and Trello run on the non-Micros platform.
分布式服务架构
With this AWS architecture, we host a number of platform and product services that are used across our solutions. This includes platform capabilities that are shared and consumed across multiple Atlassian products, such as Media, Identity, and Commerce, experiences such as our Editor, and product-specific capabilities, like Jira Work Item service and Confluence Analytics.
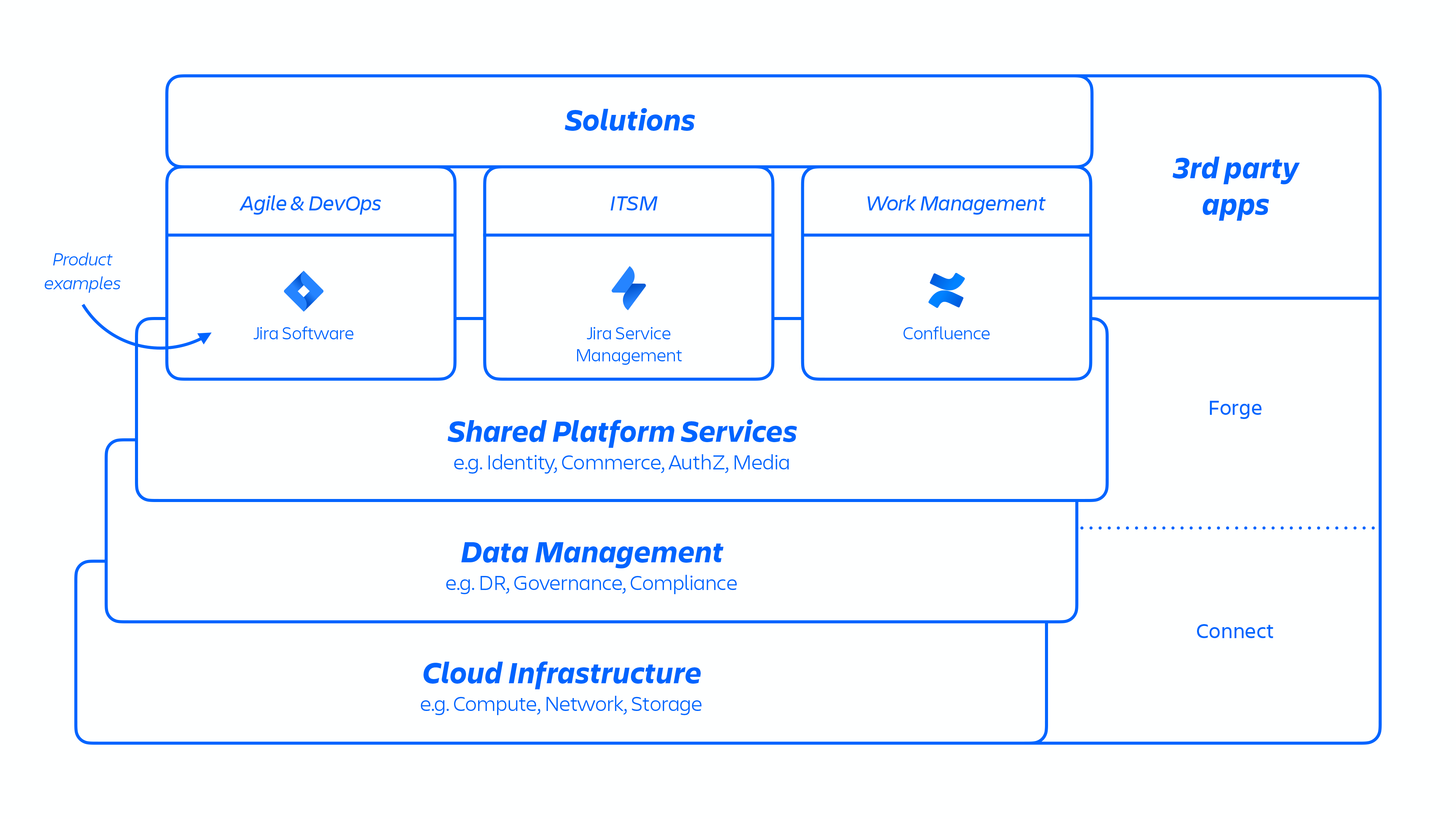
图 1
Atlassian 开发人员通过 Kubernetes 或使用内部开发的名为 Micros 的平台即服务 (PaaS) 来调配这些服务,两者都能自动协调部署共享服务、基础架构、数据存储及其管理功能,包括安全和合规控制要求(见上图 1)。通常,Atlassian 产品由多个“容器化”服务组成,这些服务通过 Micros 或 Kubernetes 部署在 AWS 上。Atlassian 产品使用的核心平台功能(见下图 2)包括请求路由、二进制对象存储、身份验证/授权、事务性用户生成内容 (UGC) 和实体关系存储、数据湖、通用日志记录、请求跟踪、可观察性和分析服务。这些微服务通过经批准的平台级标准化技术堆栈而构建:
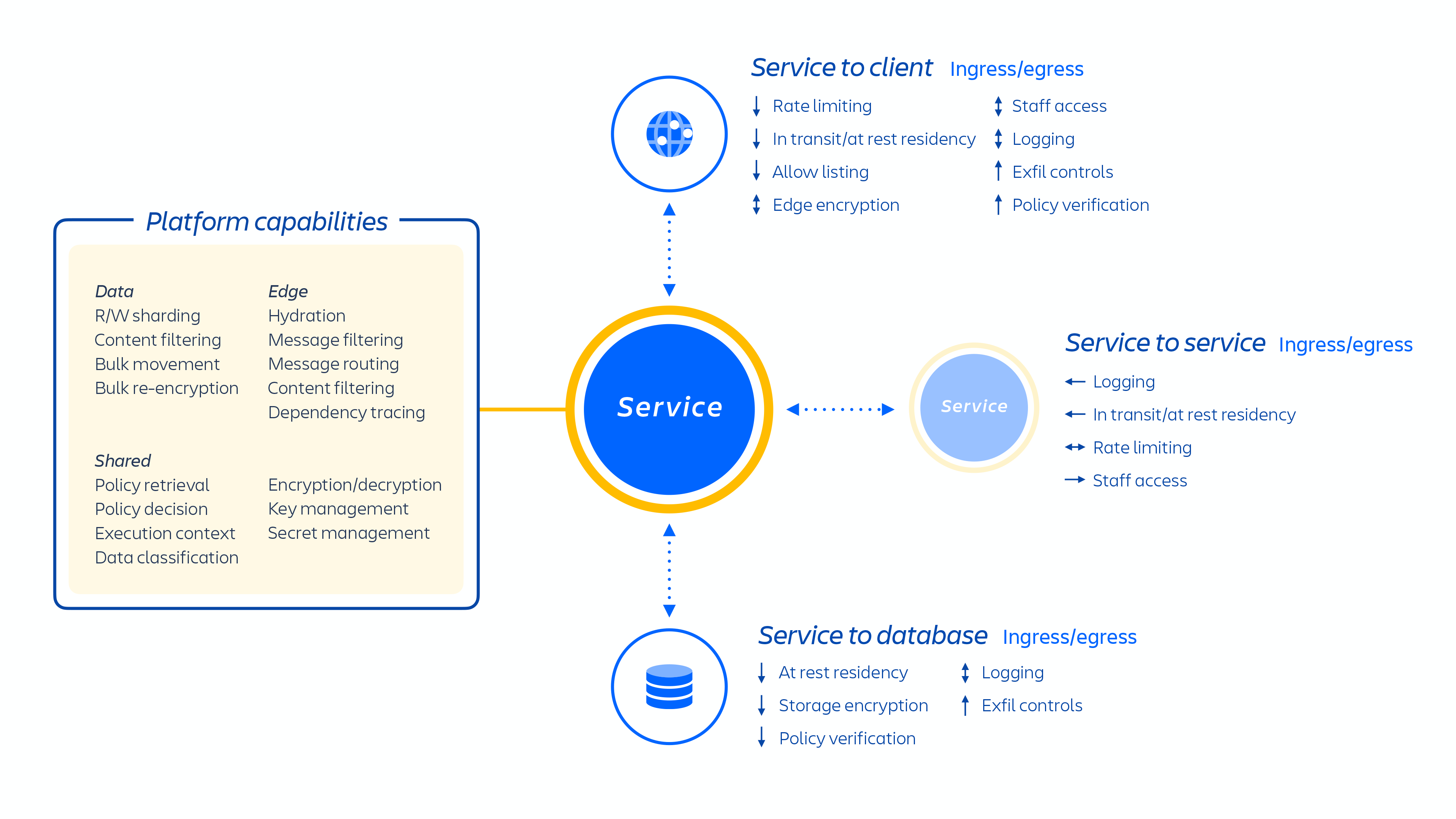
图 2
多租户架构
On top of our cloud infrastructure, we built and operate a multi-tenant micro-service architecture along with a shared platform that supports our products. In a multi-tenant architecture, a single service serves multiple customers, including databases and compute instances required to run our cloud apps. Each shard (essentially a container – see figure 3 below) contains the data for multiple tenants, but each tenant's data is isolated and inaccessible to other tenants. It is important to note that we do not offer a single tenant architecture.
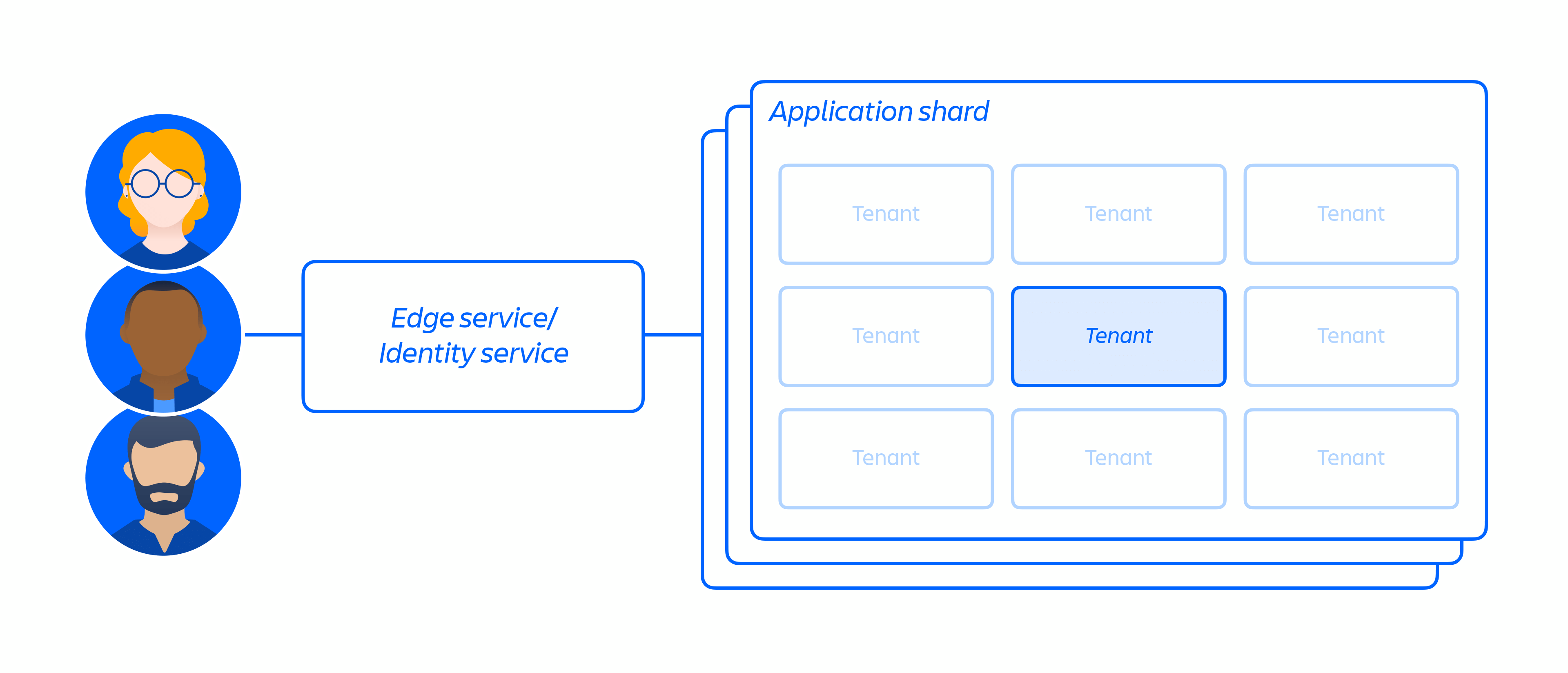
图 3
我们的微服务在构建时考虑了最低权限,旨在最大限度地缩小零日漏洞入侵的范围,并降低在我们的云环境中发生内网渗透的可能性。每个微服务都有自己的数据存储,且由于只能使用该特定服务的身份验证协议来访问该数据存储,因而任何其他服务均无该 API 的读写访问权限。
我们专注于隔离微服务和数据,而不是提供专门的每租户基础架构,以避免缩小众多客户对单个系统的狭窄数据访问范围。由于逻辑已经解耦,且数据授权和身份验证在应用层进行,因此在向这些服务发送请求时,数据授权和身份验证可以充当额外的安全检查。因此,如果微服务遭到破坏,只会导致特定服务所需数据的访问受限。
租户调配和生命周期
调配新客户后,很多事件都会触发分布式服务的编排和数据存储的调配。这些事件通常可映射到生命周期中的七个步骤之一:
1. 商务系统会立即更新相应客户的最新元数据和访问控制信息,然后调配编排系统会通过各种租户和产品事件让“已调配资源的状态”与许可状态保持一致。
租户事件
这些事件会影响到整个租户,具体影响可能是:
- 创建:创建租户并用于全新站点
- 销毁:删除整个租户
产品事件
- 激活:激活许可产品或第三方应用后
- 停用:停用特定产品或应用后
- 暂停:在暂停给定的现有产品后,从而禁用其对所拥有站点的访问权限
- 取消暂停:在取消暂停给定的现有产品后,从而授予其对所拥有站点的访问权限
- 许可更新:包含关于给定产品许可席位数及其状态(活动/非活动)的信息
2. 创建客户站点并为客户激活正确的产品集。站点的概念是指许可给特定客户的多种产品的容器。(例如:面向 <site-name>.atlassian.net 的 Confluence 和 Jira Software)。
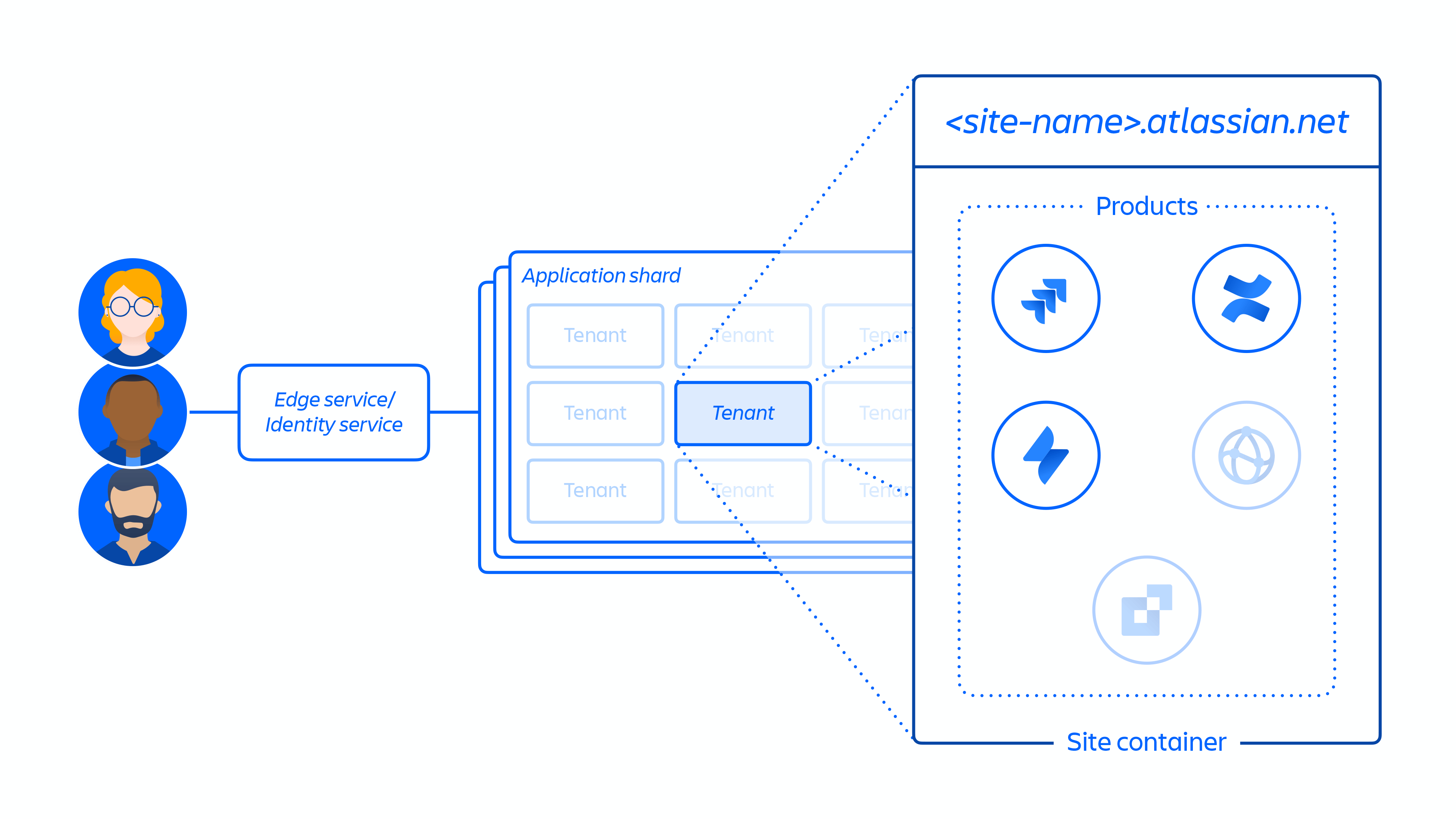
图 4
3. 在指定区域的客户站点内调配产品。
调配产品后,其大部分内容都将托管到靠近用户访问地的位置。为了优化产品性能,我们不会限制在全球托管的数据的移动,但我们可能会根据需要在各区域之间移动数据。
对于我们的某些产品,我们还会提供数据驻留功能。通过数据驻留功能,客户可以选择将产品数据分布到全球,或者保存在我们指定的地理区域。
4. 创建并存储客户站点和产品核心元数据和配置。
5. 创建和存储站点和产品标识数据,如用户、群组、权限等。
6. 在站点内调配产品数据库,例如:Jira 系列产品,Confluence、Compass、Atlas。
7. 调配产品许可应用。
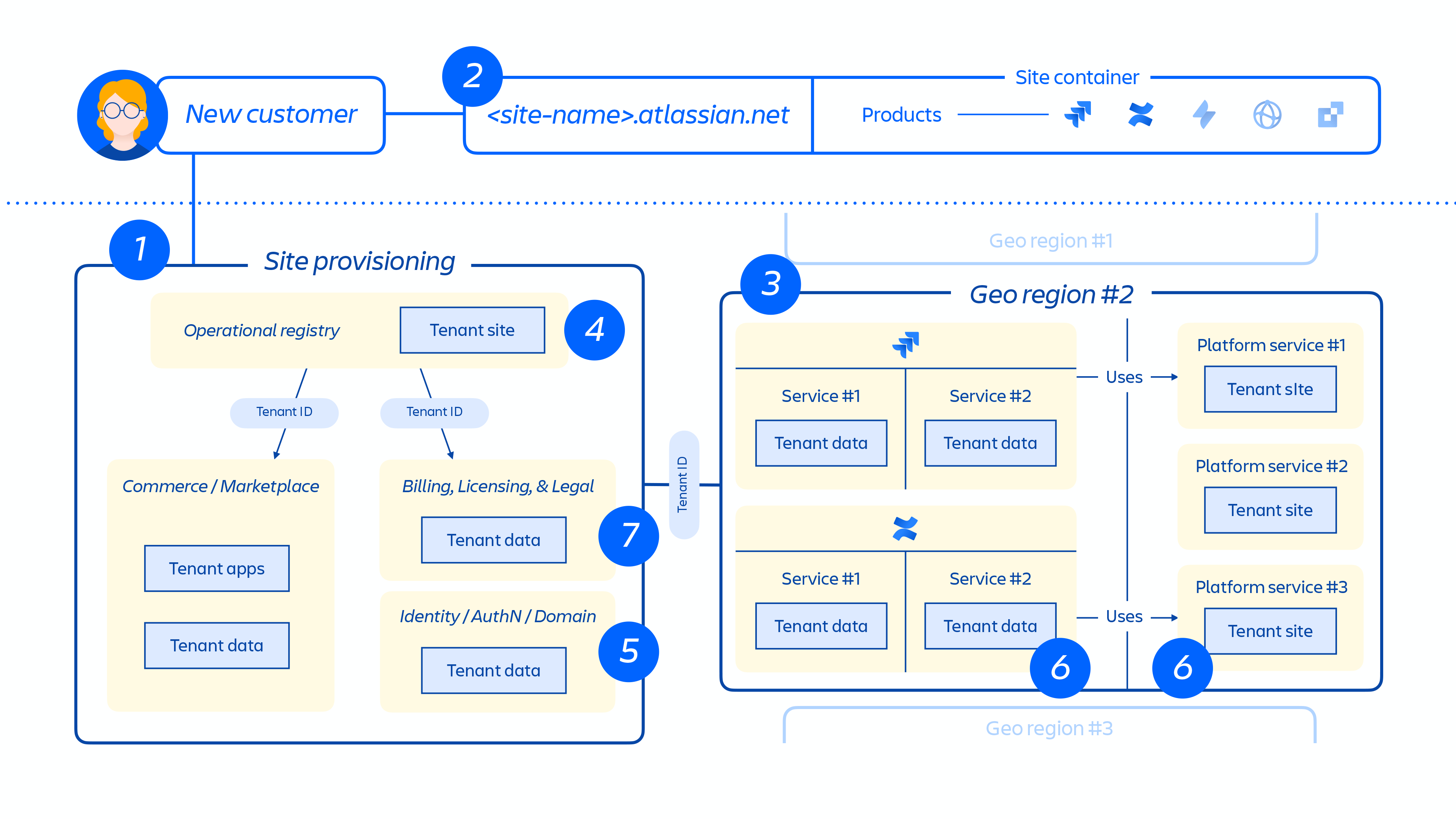
图 5
上图 5 展示了客户站点在我们的分布式架构中(而不仅仅是在单个数据库或存储中)的部署方式。其中包括存储元数据、配置数据、产品数据、平台数据和其他相关站点信息的多个物理和逻辑位置。