How to tame software sprawl
Three signs you have software sprawl and what you can do about it

Andrew Boyagi
Senior Evangelist
The monolith is rapidly disappearing. Countless companies worldwide now embrace a loosely-coupled architecture for developing software. Distributed, autonomous teams are breaking down monolithic applications into collections of components such as microservices.
Why? A loosely-coupled architecture makes it easier to scale software performance and resilience while reducing risk and lead time to deliver new application features. The benefits aren’t limited to software either. A loosely-coupled architecture enables teams to move independently and frequently release changes that benefit users. Autonomous teams who build software in a loosely-coupled architecture have higher levels of happiness, engagement, and productivity.
However, new ways of working come with new challenges. In creating a dynamic and scalable environment where individual components are built independently from each other, complexity increases, giving birth to a new type of challenge: software sprawl.

Try Compass for free
Improve your developer experience, catalog all services, and increase software health.
What is software sprawl?
Software sprawl is when the number of applications or software components within an environment rapidly grow and change, significantly increasing complexity and causing traditional software management methods to fail. This scenario commonly occurs as pace increases in a distributed software architecture.
Modernizing even a single monolithic application is likely to result in hundreds of microservices managed by multiple teams who independently and frequently release new features to production. Expanding this to an application portfolio potentially means the introduction of thousands of microservices across multiple development teams. It’s no surprise that traditional ways of managing even a small application portfolio are unlikely to lead to long-term success. During Atlassian’s journey towards the thousands of microservices that underpin our products today, we found that taming software sprawl was key to unlocking the power of a loosely-coupled architecture and autonomous teams.
related material
Microservices vs. monolithic architecture
SEE SOLUTION
Improve your DevEx with Compass
The symptoms of software sprawl can be difficult to recognize at first. They can start as minor annoyances that are pushed aside in favor of higher priorities. Yet if left unchecked, software sprawl can cripple development teams with a higher cognitive load, reduce team engagement, and reverse the benefits associated with a loosely-coupled architecture. Like the proverb, “the best time to plant a tree was 20 years ago. The second best time is now,” future success is predicated on taming software sprawl before it becomes an issue.
Below are three signs of software sprawl and what you can do to master the chaos while creating an innovative and dynamic environment that unlocks the potential of every team.
Post Incident Reviews identify upstream changes as root cause
An early symptom of software sprawl is multiple Post Incident Reviews (PIRs) indicating upstream changes as the root cause of an incident. A growing number of microservices and an increased volume of change within an environment can put a strain on existing norms around developer collaboration and coordination of change. Even a small increase in change frequency from monthly to weekly for one modernized application can result in a 100 times increase in releases per month. It’s no surprise that developers need to adapt the way they collaborate. Incidents are more likely to occur in production when developer collaboration norms fail to scale in a fast-paced environment.
Creating a non-intrusive way for developers to be aware of upstream and downstream changes is a great way to tame the impact of software sprawl. Within Atlassian, we use Compass – a developer portal that helps teams navigate distributed architectures – to send an in-app notification to development teams about breaking changes to upstream and downstream services. Acknowledging this notification signals to the change initiator that teams responsible for dependent services are aware of the change. This provides an opportunity to collaborate on the change if any issues are expected, reducing the likelihood of unintended impacts in production. Since incidents are bound to happen in a dynamic environment, developer collaboration during an incident is critical to restoring services quickly.
In post-incident reviews where upstream changes are the root cause, it’s common that the time to restore services is impacted by the time taken to identify the problematic upstream change, along with the team or person who owns the service. Logically, reducing the time it takes to identify the offending upstream change reduces the mean time to restore (MTTR) over time. This is made more difficult in a loosely-coupled architecture, where services have a rich dependency hierarchy and the root cause of an incident could be anywhere along the stack. Traditionally, incident responders trawl through logs or change records to identify a change that may have caused an incident. In a dynamic environment, this is like dismantling an ant hill to find the ant that bit you.
Within Atlassian we use the activity feed in Compass to reduce MTTR. It shows all events for upstream systems along with the details of the team who owns it. This significantly reduces triage time by supporting developer collaboration during an incident. Incidents will happen, but identifying an upstream change as the root cause of an incident in a timely manner is critical to ensuring impact is minimized and services are restored quickly.
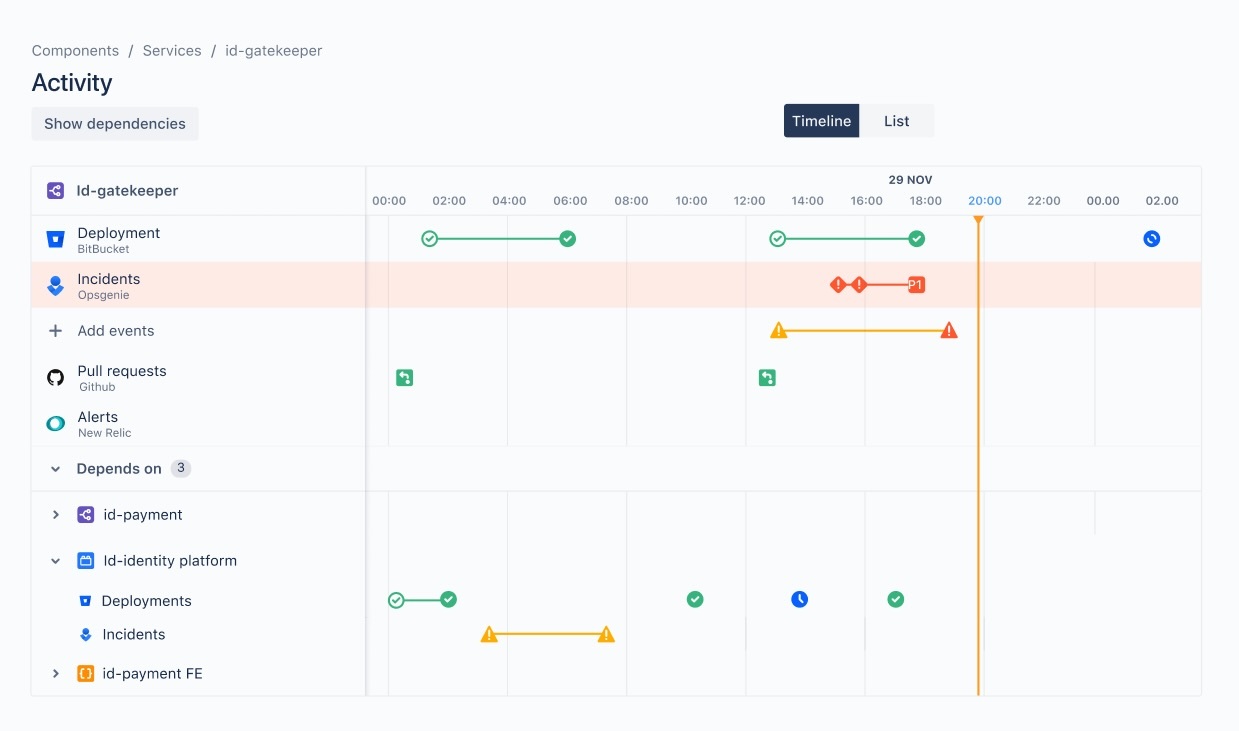
The activity feed in Compass shows all events for upstream systems, reducing triage time during an incident.
Team output is high, but nothing gets done
Moving towards a loosely-coupled architecture is one of the key ingredients for team productivity and happiness – the ability to move independently with high levels of autonomy. Left unchecked, software sprawl can reverse some of these benefits, resulting in a busy but unproductive and unhappy team. A common complaint when speaking with development teams is “everything works fine until we need to engage with another team.” This is amplified when software sprawl becomes an issue. A rapidly expanding and changing environment reduces the ability for developers to keep track of who to engage for upstream or downstream dependencies, resulting in an eventual slowdown and buildup of frustration for teams trying to deliver at pace.
Hypothetically speaking, say Alpha squad and Beta squad have an identical number of issues and story points moved to ‘done’ in Jira each week. The Alpha squad spends 90 percent of its effort shipping new features to production, while the Beta squad spends 30 percent on new features and 70 percent working out how to engage with the many upstream services they depend on. Both squads have the same level of output, but only Alpha is likely to be considered productive. Software sprawl magnifies the need for collaboration between teams. Identifying smart ways for autonomous teams to engage on demand is key to unlocking the power of a loosely-coupled environment.
In a rapidly growing and dynamic environment, the ability to self-serve information is important to team productivity and happiness. One way to achieve this is to implement a centralized software component catalog with decentralized management; this is a centralized catalog where each team is responsible for creating and updating the services they own. Traditional environments commonly have a centralized catalog that is managed by a specific team or function. However, this can't keep pace with the rate of change in a distributed environment, resulting in teams creating shadow wikis on who and how to engage. Within Atlassian, we found that a decentralized approach reduces the invisible and wasted effort across teams, improves self-service capabilities, and creates an engagement-on-demand environment. Taming software sprawl by enabling self-serve information on upstream and downstream dependencies is a great way to improve team productivity with complementary effects on team happiness and engagement.
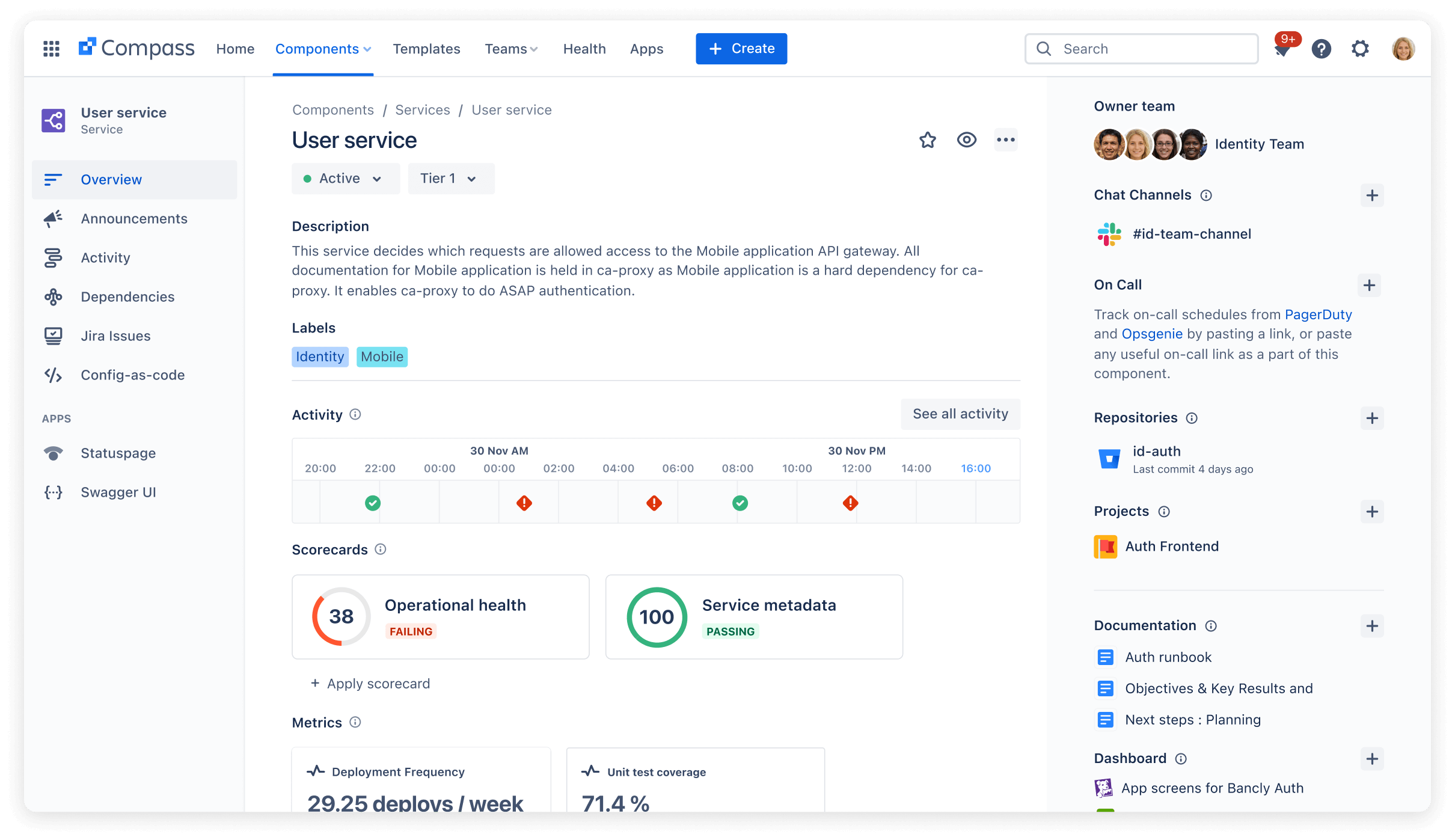
Compass provides a central location for developer-specific information on the software components they own and depend on.
Change management becomes the bottleneck
Another key sign of software sprawl is when governance functions, such as change management and cybersecurity, increasingly become a bottleneck for delivering change to production systems. These functions play a pivotal role in ensuring organizational standards and expectations are met prior to changes being deployed to production. However, they become less effective as software sprawl comes into play. In an environment suffering from software sprawl, governance functions gradually become overwhelmed as the rate of change increases, creating a backlog of changes and requests to be reviewed, which delays deployments to production. The 2022 State of DevOps report found that 56 percent of survey respondents felt that their organization’s software security processes slow down the development process.
Ideally, security practices are baked into development processes but in reality many organizations have humans reviewing changes prior to production deployment. This is not effective at the scale required in a distributed environment. In addition to slowing down the organization’s ability to deliver change, it can result in friction between development teams and those responsible for ensuring organizational standards are met.
In an environment suffering from software sprawl, it’s critical to enable high velocity while achieving desired organizational standards at scale. Automated – or semi-automated scorecards – are a great way to communicate organizational standards and provide a non-intrusive way to inspect compliance across the environment. We use Compass at Atlassian to set organizational quality standards and expectations – the scorecard for each software component provides the organization transparency on compliance. Teams and engineering leaders can add product-specific standards to scorecards, which gives a complete view of organizational quality expectations and statuses for anyone in the organization to view. This is a significant shift from governance and compliance checks at the end of a delivery cycle, to setting expectations early and enabling teams to meet them throughout the development process. Governance teams can set expectations in a dynamic environment while delivery teams have the opportunity to understand and meet requirements during the delivery cycle. Since the impact of software sprawl can be detrimental for both software delivery and governance teams, scorecards provide an opportunity to master sprawl.
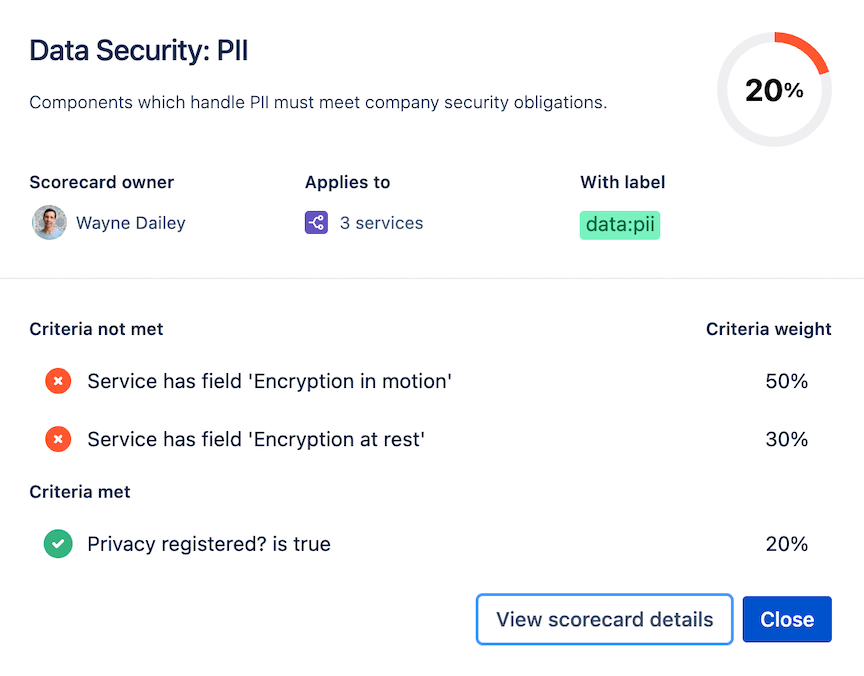
The Compass scorecard is used to understand software component health, against a set of defined expectations.
In conclusion...
There is no silver bullet for taming software sprawl. Yet long-term success is predicated on identifying and addressing the impacts of software sprawl early. Some of the early indicators of software sprawl include multiple incidents caused by upstream or downstream changes, busy teams that don’t hit their goals, and governance bottlenecks. The best way to identify software sprawl is to speak with your developers and understand the challenges they’re facing.
Atlassian developed Compass to help tame software sprawl by managing the complexity of distributed architectures as they scale. It’s an extensible developer experience platform that brings disconnected information about all of the engineering output and team collaboration together in a central, searchable location.

Share this article
Next Topic
Recommended reading
Bookmark these resources to learn about types of DevOps teams, or for ongoing updates about DevOps at Atlassian.

Compass community

Tutorial: Create a component