Hier erfährst du alles, was du für den Einstieg in Assets for Jira Service Management Data Center wissen musst.

Erste Schritte mit Assets for Jira Management Data Center
Dieser Leitfaden richtet sich an alle, die im Begriff sind, Assets for Jira Service Management Data Center einzurichten. Mit Assets können Teams ihre Assets, Konfigurationselemente und Ressourcen nachverfolgen, um einen Einblick in kritische Beziehungen zwischen Anwendungen, Services, zugrunde liegender Infrastruktur und anderen wichtigen Assets zu erhalten. Assets basiert auf Jira und bietet Teams eine einfache und schnelle Möglichkeit, Assets und Konfigurationselemente mit Serviceanfragen, Vorfällen, Problemen, Änderungen und anderen Vorgängen zu verknüpfen, um wertvollen Kontext zu erhalten.
Schritt 2: Herausfinden, wie Assets strukturiert ist
Dieser Abschnitt gibt einen Überblick darüber, wie die Assets-Datenbank strukturiert ist.
Objekte
Objekte sind deine tatsächlichen Assets/Konfigurationselemente. Diese können mit deinen Jira-Vorgängen verknüpft werden, sodass du für eingehende Vorgänge sofort mehr Kontext hast.
Sie können auch mithilfe von Objektreferenzen miteinander verknüpft werden, um zu zeigen, welche Abhängigkeiten zwischen den Objekten bestehen.
Objektschemata
Ein Objektschema ist die tatsächliche Configuration Management Database (CMDB), die deine Objekttypen (mehr dazu weiter unten) und Objekte umfasst. Du kannst in Assets mehrere Objektschemata erstellen. Das ist aus mehreren Gründen nützlich:
- Die Aufteilung der Daten in kleinere Einheiten erleichtert die Überprüfung der Daten und die Gewährleistung ihrer Genauigkeit.
- Bei vertraulichen Daten wie z. B. Mitarbeiterinformationen ist es möglicherweise einfacher, all diese Daten in einem einzigen Objektschema mit eingeschränkten Zugriffsberechtigungen zu speichern.
Berücksichtige bei der Organisation der Daten in Assets, wie die Daten verwendet werden und wer sie aktualisiert, damit die Daten in logische Objektschemata gruppiert werden können.
Für Assets (und damit auch für Jira Service Management) spielt es keine Rolle, welches Objektschema welche Informationen umfasst. Assets nimmt diese nur als einen großen Datenpool wahr. Daher kannst du für einen Anwendungsfall einfach mehrere Objektschemata verwenden und Verknüpfungen zwischen Objekten in verschiedenen Objektschemata erstellen.
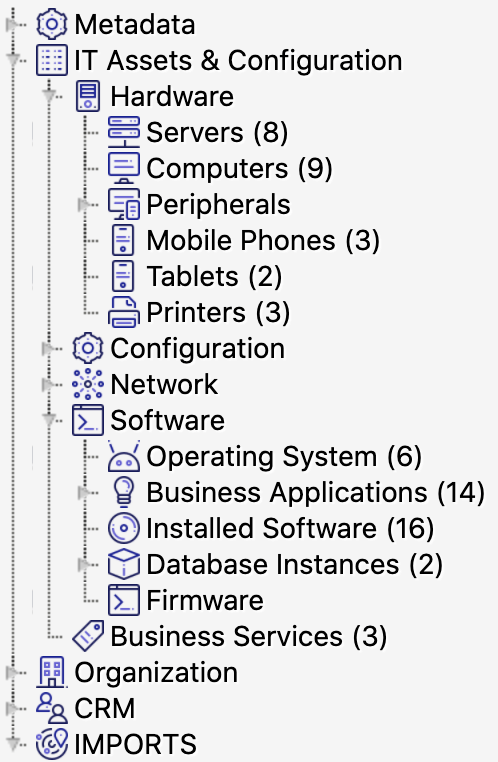
Objekttypen
Objekttypen werden einem Schema zugewiesen und definieren die darin enthaltenen Objekte. Du kannst sie selbst definieren oder eine Objektschemavorlage verwenden, die mit bestimmten anpassbaren Objekttypen vorausgefüllt ist. Objekttypen fungieren als Container für deine tatsächlichen Objekte. Da Assets sehr offen und flexibel ist, kannst du Objekttypen ganz nach Belieben anpassen. Zu den häufigsten zählen jedoch Folgende:
- Unternehmensservices
- Hosts
- Laptops
- Software
Doch dabei muss es sich nicht um IT-Assets handeln. Viele Benutzer fügen andere hilfreiche Informationen hinzu, wie z. B.:
- Anbieter
- Standorte
- Mitarbeiter
- Geschäftliche Prioritäten
Du kannst Objekttypen in der Hierarchiestruktur so organisieren, wie es für dich sinnvoll ist. Diese Struktur dient hauptsächlich der Navigation und Lesbarkeit. Zu diesem Zweck kann sie auch leere Objekttypen enthalten. Sie kann jedoch auch für die Vererbung von Attributen konfiguriert werden, um die Erstellung von Objekttypen zu erleichtern.
Objekttyp-Attribute
Objektattribute definieren einen Objekttyp. Jeder Objekttyp hat seine eigenen Attribute. Der Objekttyp "Laptops" könnte beispielsweise folgende Attribute haben: Modell, Seriennummer, Benutzer, Ablaufdatum der Garantie usw.
Durch die Eingabe von tatsächlichen Werten für das Attribut wird ein Objekt definiert. Dies kann manuell oder automatisch erfolgen (siehe Schritt 4).
Alle Objekttypen haben vier obligatorische Attribute:
- Name
- Schlüssel
- Erstellungsdatum
- Datum der letzten Aktualisierung
Die letzten drei Attribute werden automatisch festgelegt. Alle anderen können vom Administrator definiert werden. Da es ein eindeutiges Schlüsselattribut gibt, muss der Name der einzelnen Objekte nicht eindeutig sein.
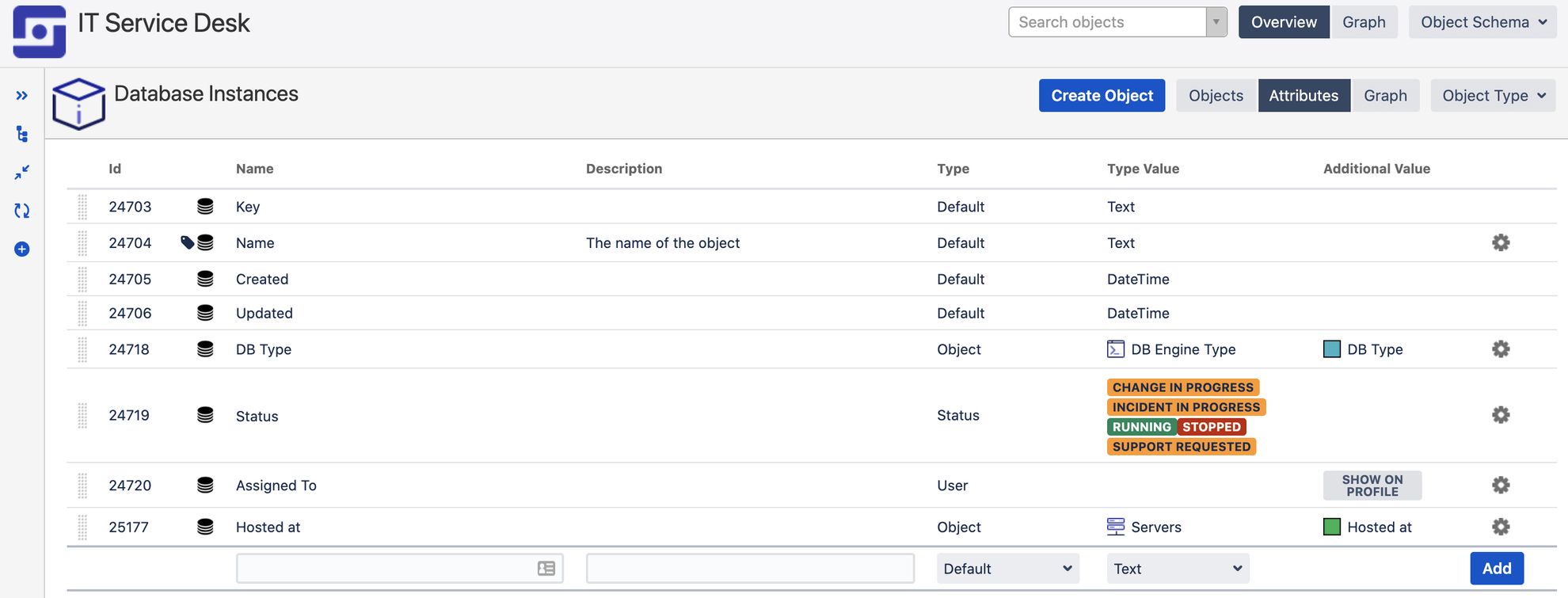
Attribute können viele verschiedene Datentypen umfassen, wie z. B. Text, Daten, numerische Werte, URLs (gut für die Verknüpfung mit anderen Informationsspeichern oder Serviceverträgen), Jira-Benutzer (hervorragend zum Festlegen der Besitzer von Objekten), Status (auf Lager, zugewiesen, außer Betrieb usw.) und andere Objekte (mehr dazu im nächsten Abschnitt).
Objektreferenzen
Eine besondere Art von Objektattribut ist der Attributtyp "Objekt". Dadurch wird eine Referenz zu anderen Objekten erstellt und du kannst mit der Zuordnung der Abhängigkeiten zwischen deinen Objekten beginnen.
Wenn "Standort" beispielsweise ein eigener Objekttyp ist, kann jedes Objekt vom Typ "Standort" einer der Bürostandorte deines Unternehmens sein. So kannst du schnell den Standort der einzelnen Laptops festlegen, z. B. durch die Auswahl von "Stockholm".
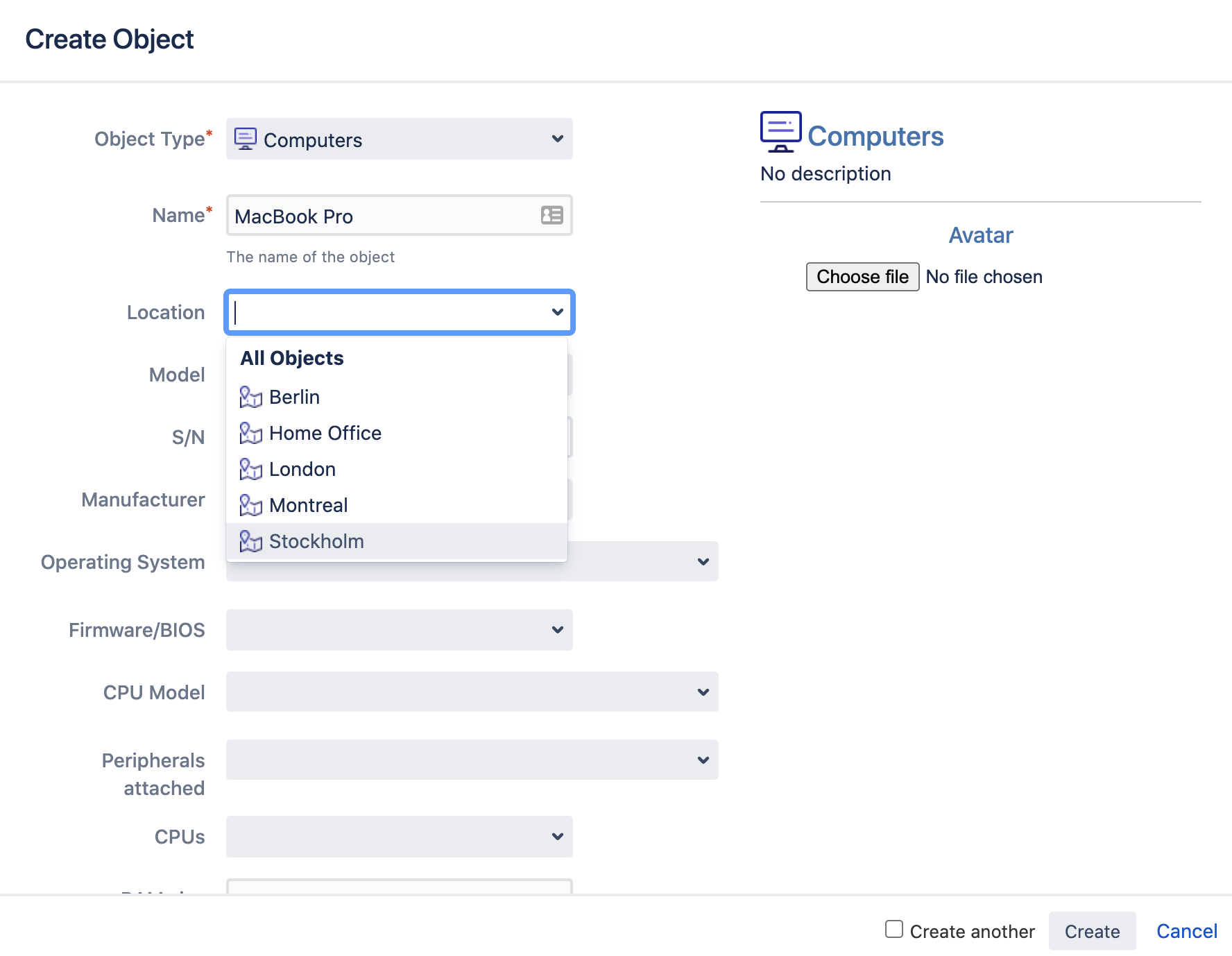
Objektreferenzen müssen nicht manuell festgelegt werden. Sie können automatisch mithilfe von Netzwerkscannern, Importern, Automatisierungsregeln usw. hinzugefügt werden. Weitere Informationen dazu findest du in Schritt 4.
Referenzen zwischen Objekten haben zwei wichtige Vorteile:
Hauptvorteil: Du kannst Abhängigkeiten zwischen deinen Objekten nachvollziehen. Beispielsweise kannst du deine Unternehmensservices den verschiedenen Hosts, Betriebssystemen und Dateien zuordnen, von denen sie abhängen. Das kann unglaublich nützlich sein, um die Auswirkungen von Änderungen auf nachgelagerte Bereiche zu verstehen (wie z. B. die Folgen der Änderung eines Betriebssystems) und die Ursachen von Vorfällen und Problemen zu ermitteln. Da jedes Objekt mit einem Jira-Vorgang verknüpft werden kann, erstellst du außerdem im Laufe der Zeit eine umfassende Historie deiner Infrastruktur oder anderer Unternehmensressourcen, sodass du besser in der Lage bist, Vorgänge und Probleme zu lösen.
Nebenvorteil: Sie erleichtern die Verwaltung. Wenn ein Büro also von Montreal nach Toronto umzieht, musst du nur das Objekt "Montreal" aktualisieren und nicht jeden einzelnen Laptop von "Montreal" in "Toronto" umändern.
Es gibt zwei Arten von Objektreferenzen:
- Ausgehende Referenzen, bei denen es sich um Referenzen vom aktuellen Objekt zu anderen Objekten handelt
- Eingehende Referenzen, bei denen andere Objekte auf das aktuelle Objekt verweisen
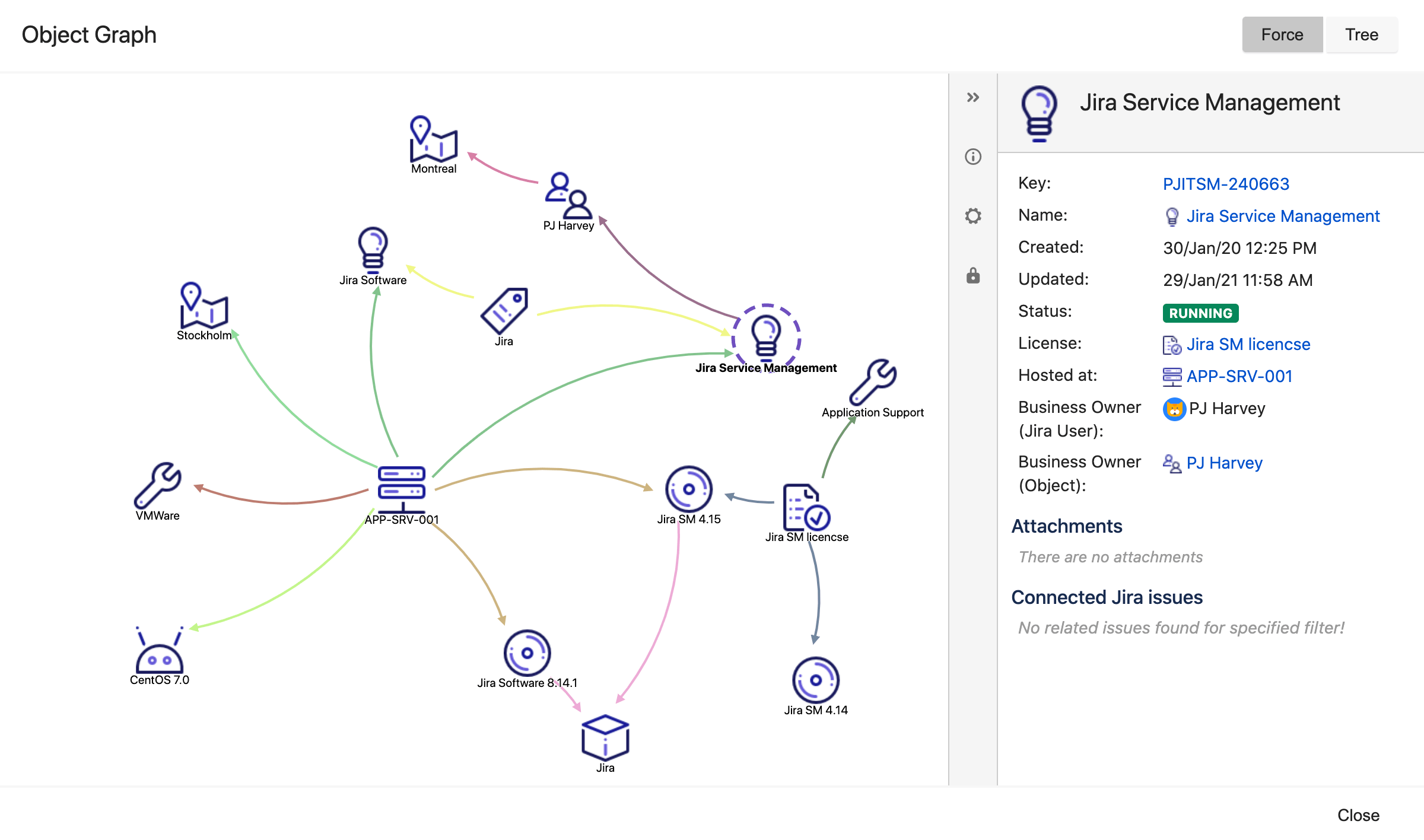
Referenzen zwischen Objekten können mit dem grafischen Viewer angezeigt werden. Du kannst deine Referenztypen auswählen (z. B. Installationsort, Besitzer, Anbieter) und diese in den Objektschemaeinstellungen mit verschiedenen Farben kennzeichnen.
Berechtigungen in Assets
In Assets gibt es drei Berechtigungstypen
- Globale Berechtigungen – Du kannst in den globalen Einstellungen festlegen, wer in Assets über Administratorberechtigungen verfügen soll. Benutzer mit der Rolle "Assets-Administrator" können in Assets alle Aktionen ausführen.
- Objektschema-Berechtigungen: In den Einstellungen für Objektschemata kannst du festlegen, wer über Administratorberechtigungen für ein bestimmtes Objektschema verfügt, wer Objektschemadaten aktualisieren und wer die Daten nur anzeigen kann.
- Objekttyp-Berechtigungen: Manchmal möchtest du vielleicht, dass Jira Service Management-Kunden bestimmte Informationen in einem Objektschema sehen können, aber keinen Zugriff auf alle Daten in diesem Schema haben. Das kannst du mit Objekttyp-Berechtigungen erreichen.
Schritt 3: Entscheiden, welche Daten einbezogen werden
Jede Instanz von Assets ist einzigartig, da in jedem Unternehmen andere Informationen verfolgt werden müssen. Assets kann alle Informationen speichern, die dir und deinem Unternehmen hilfreiche Einblicke geben.
Welche Assets oder Konfigurationselemente du einbeziehen solltest, hängt davon ab, was du erreichen möchtest. Eine Assets-Instanz für die Bestandsverwaltung sieht vollkommen anders aus als eine Instanz, mit der Unternehmensservices und ihre Abhängigkeiten zugeordnet werden, um schneller Änderungen vornehmen und Vorfälle lösen zu können.
Hier sind unsere Top-Tipps für die Einbeziehung von Daten:
Das Problem definieren
Die meisten Tools werden implementiert, um ein Problem zu lösen, und Assets bildet dabei keine Ausnahme. Möglicherweise werden deine Vorfälle nicht so schnell gelöst, wie du es dir wünschen würdest, oder vielleicht führen Änderungen an einem bestimmten Service häufig zu unerwarteten Ergebnissen, da du die Serviceabhängigkeiten nicht einfach erkennen kannst.
Ermittle zuerst dein Problem und definiere dann auf dieser Grundlage alles andere – von den beteiligten Personen bis hin zu den Assets und Informationen, die du in deine Datenbank aufnimmst. Sieh dir das Problem genau an, um zu verstehen, welche zusätzlichen Informationen Mitarbeiter benötigen, um es zu bewältigen. Diese Informationen definieren deine Objekttypen.
Wenn du zu viele Informationen auf einmal hinzufügst, kann es schwierig sein, ihre Genauigkeit zu überprüfen. Versuche daher, dich immer nur auf ein Problem zu konzentrieren. Sobald dein erstes Problem gelöst ist, kannst du Assets ausbauen, um weitere Probleme zu lösen.
Mit Services beginnen
Für das Konfigurationsmanagement empfehlen wir, mit den Services zu beginnen, die mit dem zu lösenden Problem zusammenhängen. Services sind klar definiert, und es ist relativ einfach, die verschiedenen Assets hinzuzufügen, die für ihre Ausführung erforderlich sind. Dies gilt auch für die Assets, von denen diese Assets abhängen, und so weiter. Schließlich kannst du dir ein vollständiges Bild von jedem relevanten Service und dessen Abhängigkeiten machen.
Du musst entscheiden, wie weit du gehen möchtest. Überlege dir, wie viele Details du wirklich brauchst, um deine Services zu verstehen. Die Zuordnung der spezifischen Racks und Kabel ist für manche zu detailliert, während dies für andere erforderlich sein kann.
Du musst auch nicht sofort alle deine Services aufnehmen. Du könntest zum Beispiel nur mit deinen geschäftskritischen Services oder den Services mit den meisten Ausfallzeiten beginnen.
Wenn du mit Services beginnst, beschränkst du dich zunächst auf eine festgelegte Menge an Assets/Konfigurationselementen. Dann kannst du beim Auftreten neuer Probleme nach Bedarf weitere Assets hinzufügen. Es empfiehlt sich, deine CMDB nach und nach aufzubauen, da es einfacher ist, die Genauigkeit kleiner Datenmengen zu bestätigen, als deine gesamte Infrastruktur und alle Assets auf einmal zu überprüfen.
Objektschemavorlagen verwenden
Assets umfasst Objektschemavorlagen für IT-Asset- und Konfigurationsmanagement, HR und Kundenbeziehungsmanagement.
Diese Vorlagen können auch an deine Anforderungen angepasst werden und sind ein guter Ausgangspunkt für die Objekttypen, die Benutzer häufig in Assets speichern. Gehe die Liste der Objekttypen durch und entferne alle, die du nicht verwenden möchtest.
Tipps und Tricks
Auf Unnötiges verzichten
Überlege dir ganz genau, was du erreichen möchtest und welche Informationen du dafür brauchst. Jedes Objekt und die zugehörigen Attribute müssen einen Nutzen haben.
Setze dich mit deinem Team und den Stakeholdern zusammen, um sicherzustellen, dass jedes Attribut von jemandem oder für einen bestimmten Zweck verwendet wird. Wenn ein Attribut von niemandem speziell gebraucht wird, landet es im Papierkorb. Es kann immer noch später hinzugefügt werden!
Musst du wirklich den genauen Standort deiner Server kennen? Oder den Hersteller deines Betriebssystems? Vielleicht ist das so und du hast einen triftigen Grund dafür. Wenn du allerdings auf der Grundlage dieser Daten keine Entscheidungen treffen oder Abfragen erstellen möchtest, haben sie hier nichts verloren!
Zu viele Daten bringen Herausforderungen mit sich:
- Je mehr Objekte und Attribute du hast, desto mehr Arbeit ist erforderlich, um ihre Genauigkeit zu gewährleisten.
- Viele ungenutzte Daten beeinträchtigen die Sichtbarkeit wertvoller Daten und könnten in Extremfällen sogar negative Auswirkungen auf die Leistung haben.
- Es ist einfacher, Daten später hinzuzufügen als sie zu entfernen. Wenn du also feststellst, dass dir etwas fehlt, kannst du es später hinzufügen, anstatt "für alle Fälle" mit einer riesigen Datenmenge zu beginnen. Niemand löscht gerne Daten.
Zukünftige Verwaltbarkeit berücksichtigen
Überlege dir, wie du die Daten in Assets verwalten wirst. Wie oft ändern sich die Attribute eines Objekts und wie einfach wird es sein, sie in Assets auf dem neuesten Stand zu halten?
Wenn sich ein bestimmtes Detail eines Objekts häufig ändert, es aber selten verwendet wird, ist es möglicherweise sinnvoller, es nicht in Assets zu importieren und es nur in den seltenen Fällen nachzusehen, in denen es tatsächlich benötigt wird. Bei einem Detail, das nur ab und zu verwendet wird, aber sehr statisch ist, kann sich der Import möglicherweise lohnen, da so der Zugriff erleichtert wird.
Sehen wir uns beispielsweise Laptop-Software an. Theoretisch könntest du Assets mithilfe eines Scan-Agenten und durch Softwareanfrage-Vorgänge sowie Automatisierungsregeln so aktualisieren, dass jede auf dem Laptop installierte Software importiert wird. Bei einer offenen Installationsrichtlinie kann sich das jedoch relativ schnell ändern. Außerdem wird die neue Software mit den Scan-Mustern unter Umständen gar nicht erkannt, sodass die erfassten Informationen möglicherweise nicht ganz aktuell sind. Es wäre stattdessen wahrscheinlich sinnvoller, dich mit einer wichtigen Software zu beschäftigen, deren Nutzung dich ganz besonders interessiert.
Falls in deinem Unternehmen strenge Installationsrichtlinien gelten und die Software nur bei der Einrichtung des Laptops und im Rahmen von Servicedesk-Anfragen installiert wird, kann es sinnvoll sein, alle Informationen in Assets zu speichern, da die Änderungsrate langsamer ist und Änderungen leichter nachverfolgt werden können.
Über physische Aspekte hinausgehen
Da du in Assets die benötigten Objekte definieren kannst, bist du weder auf herkömmliche noch auf physische Assets beschränkt. Unternehmensservices sind beispielsweise keine physischen Assets – dennoch ist es oft von entscheidender Bedeutung, dass Personen sie im Detail verstehen. Du kannst alle physischen und nicht-physischen Abhängigkeiten eines Services mit diesem verknüpfen. So erhältst du beim Anzeigen eines Unternehmensserviceobjekts einen umfassenden Überblick über seine Funktionsweise.
Dir sind keine Grenzen gesetzt. Zu den gängigen Beispielen von Assets-Benutzern zählen Objekte, die für das Unternehmen wichtig sind, Umgebungstypen, Abteilungen/Teams, Standorte usw.
Ein weiteres Beispiel aus der Praxis ist die Kategorisierung von Unternehmensservices. Nehmen wir an, alle deine Unternehmensservices werden unter dem Objekttyp "Unternehmensservices" zu Assets hinzugefügt. Vielleicht möchtest du diese Unternehmensservices in die Kategorien "Finanzen", "Logistik", "Vertrieb", "Infrastruktur" usw. einteilen. Du könntest sie anhand eines Attributs im Objekttyp "Unternehmensservices" kategorisieren oder für diese Kategorien einen eigenen Objekttyp namens "Servicekategorie" erstellen.
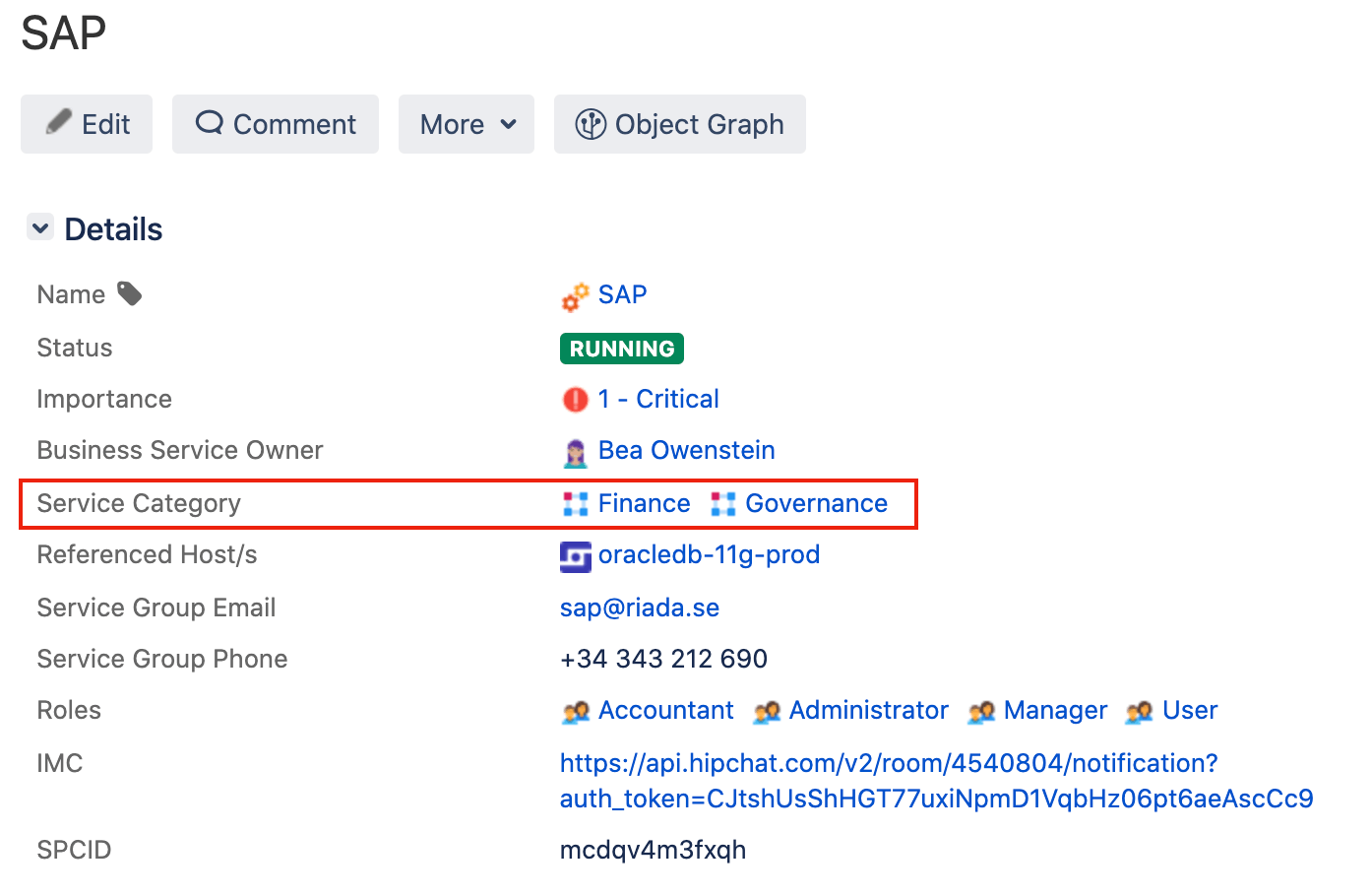
Dies hat den Vorteil, dass du Details (Attribute) hinzufügen kannst, die sich speziell auf die Unternehmensservice-Kategorie beziehen. Vielleicht gibt es jemanden, der für alle Unternehmensservices im Finanzbereich verantwortlich ist. Es empfiehlt sich nicht, diese Person direkt zu jedem "Unternehmensservice"-Objekt mit finanziellem Bezug hinzuzufügen, da dies die Verwaltung erschwert. Stattdessen kannst du sie einfach einmalig dem Objekt "Finanzen" im Objekttyp "Servicekategorie" hinzufügen. So musst du sie nur noch an einem Ort aktualisieren, ohne wiederholt Daten einzugeben.
Du kannst auch Regeln erstellen, die den operativen Status jedes einzelnen Unternehmensservice aus dem Finanzbereich in einem Gesamtstatus für die Kategorie "Finanzen" zusammenfassen. Jetzt kannst du durch die Anzeige der Objekte in den Kategorien schnell erkennen, ob in den einzelnen Servicekategorien Probleme bei einem Service vorliegen.
Du musst diese Objekttypen nicht zu Assets hinzufügen. Allerdings ist es gut zu wissen, dass du nicht durch herkömmliche Assets/Konfigurationselemente eingeschränkt bist. Alles hängt davon ab, was du tun möchtest. Deshalb ist es so wichtig, dass du deine Ziele und die Informationen verstehst, die du brauchst, um diese zu erreichen.
Vorausplanen und schrittweise wachsen
Denke an alle Erweiterungen, die du in Zukunft vielleicht vornehmen möchtest. Dies wirkt sich darauf aus, welche Daten du einbeziehst, aber auch darauf, wie du deine Daten strukturierst.
Auch wenn es nicht schadet, das im Hinterkopf zu behalten, empfehlen wir, Assets schrittweise aufzubauen. Ein enormes Release mit einer Genauigkeit der Daten von 100 % für Tausende von Objekten zu realisieren ist äußerst schwierig. Es ist deutlich einfacher, klein anzufangen und im Laufe der Zeit neue Attribute, Objekte und Objektschemata hinzuzufügen.
Wir empfehlen, ein Problem zu identifizieren und die Datenbasis in Assets entsprechend zu erweitern, damit es gelöst werden kann. Dann kannst du zum nächsten Problem übergehen und Assets nach Bedarf weiterentwickeln.
Realistische Anforderungen an die Genauigkeit stellen
Genauigkeit zu 100 % sollte immer das oberste Ziel sein. In der Praxis ist das jedoch nicht immer möglich und das ist auch nicht weiter schlimm. Solange die Daten genau genug sind, um einen höheren Geschäftswert zu bieten, als ohne sie möglich wäre, bist du im positiven Bereich. Viele CMDB-Projekte können sich verzögern oder sogar scheitern, da vor der Einführung darauf gewartet wird, dass sie "perfekt" sind.
Schritt 7: Automatisierungen einrichten
In diesem Abschnitt behandeln wir die beiden Optionen, die du in Assets zum Automatisieren von Routineaufgaben nutzen kannst.
Assets-Automatisierungen
Assets-Automatisierungen beziehen sich auf ein konkretes Objektschema. Typische Anwendungsbeispiele sind:
- Das Senden von Benachrichtigungen basierend auf bestimmten Triggern oder Änderungen an den Assets-Objekten im Schema. Beispiel: Das Senden einer E-Mail, bevor eine Lizenz oder Garantie abläuft, oder das Erstellen eines Jira-Vorgangs, wenn ein Service ausfällt.
- Das Ordnen und Standardisieren von Assets-Daten, um den Berichterstellungs- und Abfrageprozess zu erleichtern.
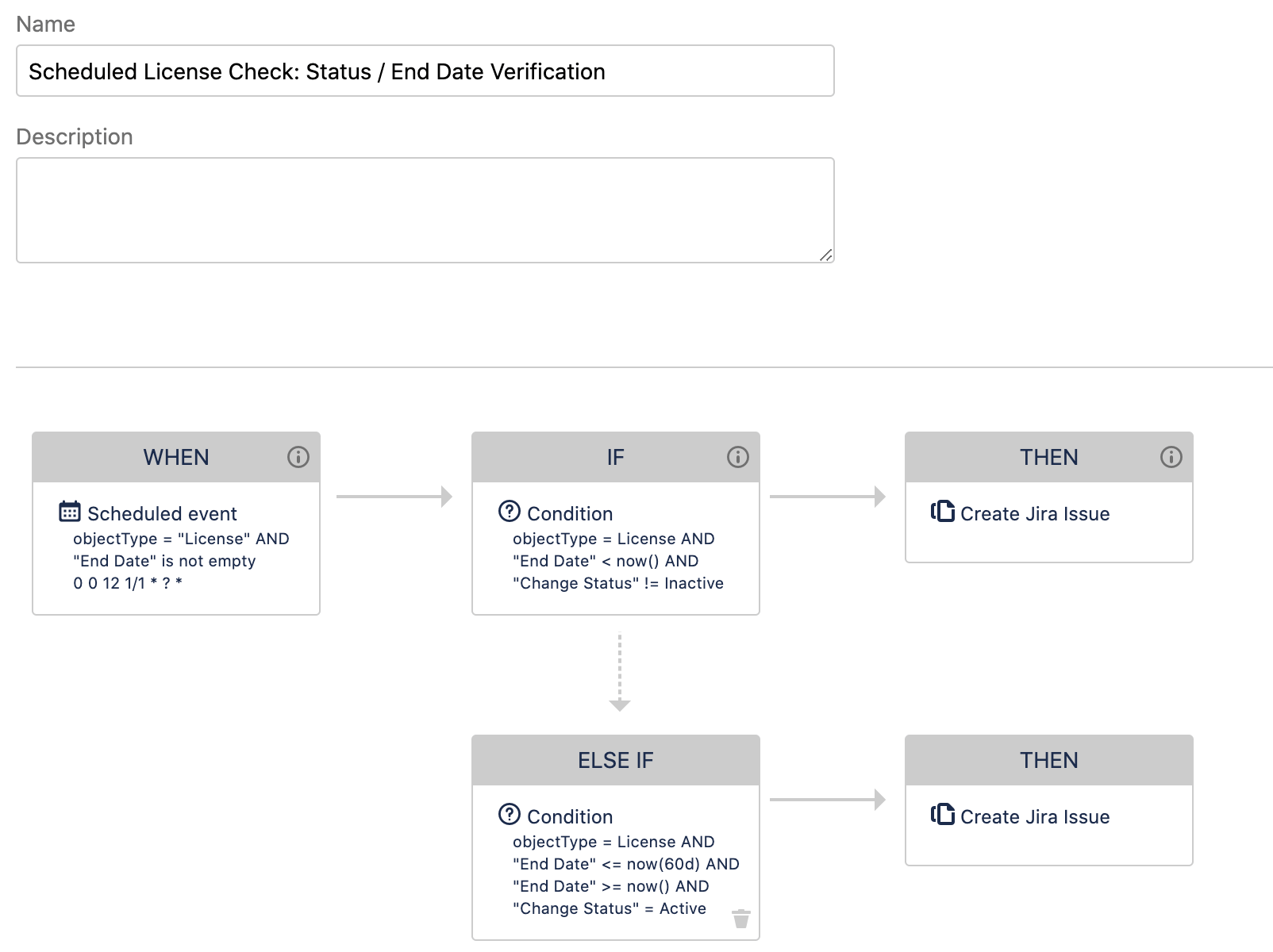
Mit Automatisierungsregeln kannst du Objektinformationen aktualisieren, Vorgänge erstellen, E-Mails senden, HTTP-Anfragen stellen, Groovy-Skripte ausführen und vieles mehr.
Hier kannst du dich mit dem Erstellen von Automatisierungsregeln vertraut machen:
Folgefunktionen
In Assets sind außerdem neue Folgefunktionen verfügbar. Ähnlich wie bei Automatisierungsregeln kannst du mit Folgefunktionen die Ausführung von Aktionen automatisieren.
Der Unterschied besteht darin, dass die Aktionen stattfinden, wenn sich der Status eines Vorgangs im Rahmen eines Jira-Workflows ändert (Vorgangsweitergabe). Zu diesen Aktionen gehört das Aktualisieren eines Assets, das Senden einer Benachrichtigung und das Ausführen eines Skripts.
Wenn jemand beispielsweise einen Vorgang erstellt, bei dem das Onboarding eines Mitarbeiters angefordert wird, kannst du Tasks erstellen, um dem neuen Benutzer die erforderlichen Assets zuzuweisen – einschließlich Laptop, Mobiltelefon und Mobilfunkabonnement. Dabei werden die einzelnen Assets mit Assets-Objekten verknüpft.
Tipps und Tricks
Wenn du Vorgangstextfelder verwendest, um Daten in Assets einzugeben oder zu aktualisieren, oder du Objekte gelegentlich manuell in Assets eingibst, werden die Daten möglicherweise etwas unübersichtlich. Nutze in diesen Fällen Automatisierungen.
Ein gutes Beispiel hierfür sind Servernamen. Diese sind in der Regel standardisiert und können leicht falsch geschrieben werden. Du kannst Automatisierungsregeln erstellen, die ausgelöst werden, wenn ein Objekt vom Typ "Server" erstellt oder aktualisiert wird, um sicherzustellen, dass der Name der Benennungskonvention entspricht und Fehler gemeldet werden.
Schritt 9: Berichterstellung einrichten
Bei der Berichterstellung kommt es ganz auf deine Anforderungen, dein Unternehmen und die Probleme an, die du mit Assets lösen möchtest. Assets umfasst einige vorkonfigurierte Berichte, die dir helfen, deine Assets und Konfigurationsdaten zu verstehen. Du kannst Berichte für deine Assets-Objekte, die damit verbundenen Vorgänge und Projekte sowie den entsprechenden Zeitaufwand erstellen.
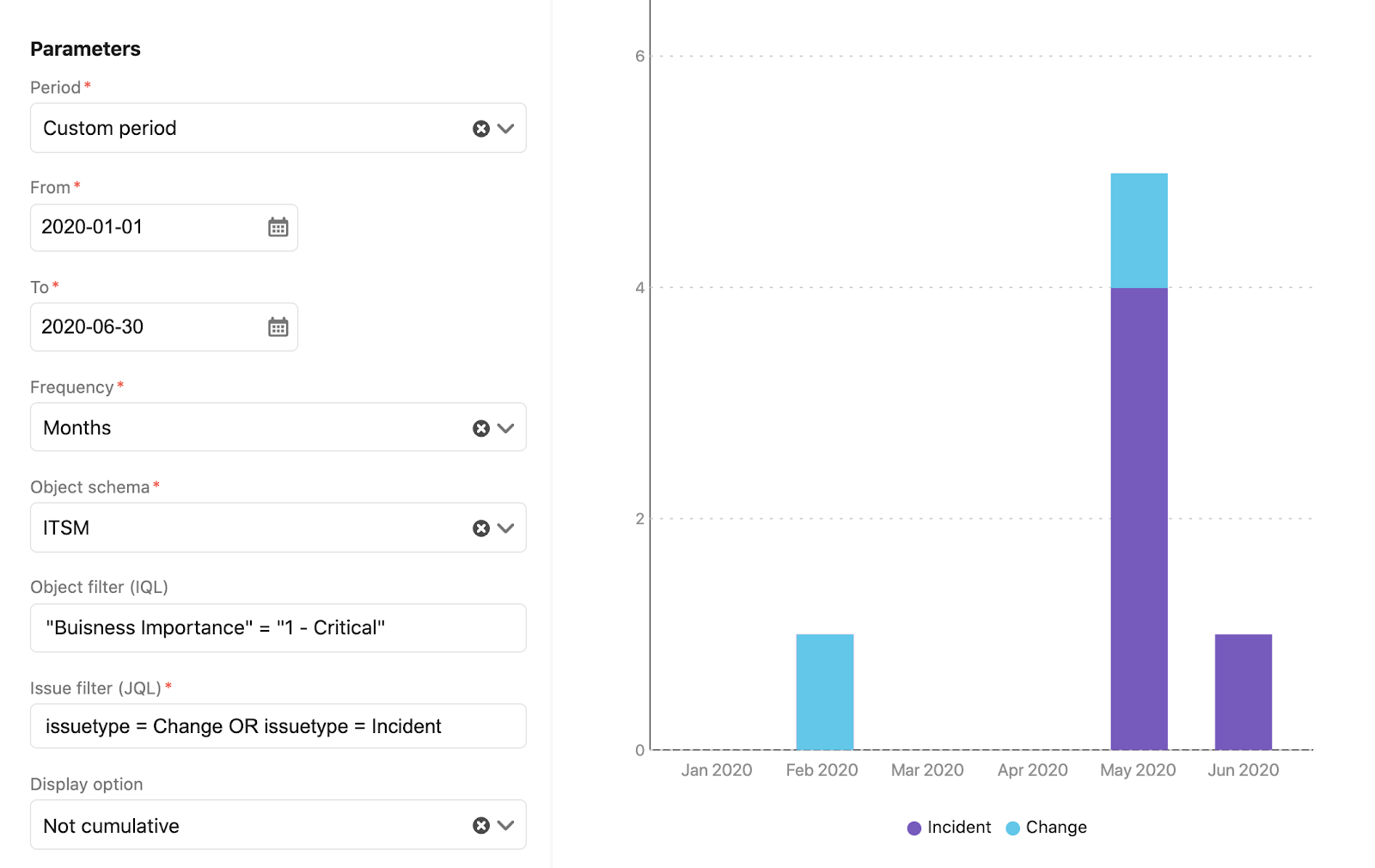
Möglicherweise möchtest du verstehen, wie viele Änderungen und Vorfälle bei deinen kritischen Unternehmensservices aufgetreten sind oder ob mit Serviceanfragen ein bestimmter Zeitaufwand verbunden ist und bei welchen Arten von Assets dies der Fall ist. Anhand dieser Berichte könntest du erkennen, mit welchen kritischen Unternehmensservices die meisten Vorfälle verknüpft sind, sodass du weißt, worauf du etwaige Verbesserungsmaßnahmen konzentrieren solltest.