Consejos para hacer scripts de tareas con Bitbucket Pipelines

Sten Pittet
Escritor colaborador
Con Bitbucket Pipelines, puedes adoptar rápidamente un flujo de trabajo de integración continua o de entrega continua para tus repositorios. Una parte esencial de este proceso consiste en convertir los procesos manuales en scripts que pueden ejecutarse automáticamente con una máquina y sin necesidad de intervención humana. A veces, sin embargo, puede ser complicado automatizar tareas, ya que podría haber incidencias con la autenticación, al instalar dependencias o notificar incidencias. En esta guía encontrarás consejos prácticos para escribir tus scripts.
Duración
30 minutos
Público
Usuario sin experiencia en la implementación continua y/o Bitbucket Pipelines
Paso 1: ¡No registres información confidencial!
Antes de seguir adentrándote en el mundo de la automatización, debes revisar tus registros y asegurarte de que no haya salida de datos confidenciales, como credenciales, claves API o cualquier información que pueda poner en riesgo el sistema. En cuanto comiences a usar Bitbucket Pipelines para ejecutar tus scripts, los registros se almacenarán y podrá leerlos cualquier usuario que tenga acceso a tu repositorio.
Paso 2: Usa claves SSH para conectar con servidores remotos
La autenticación suele ser una de las partes más problemáticas de la automatización. Las claves SSH tienen la doble ventaja de facilitar la gestión de las conexiones con servidores remotos y de ser muy seguras. Con Bitbucket Pipelines puedes generar fácilmente un nuevo par de claves que se utilicen cada vez que se ejecute una canalización para conectar con servidores remotos.
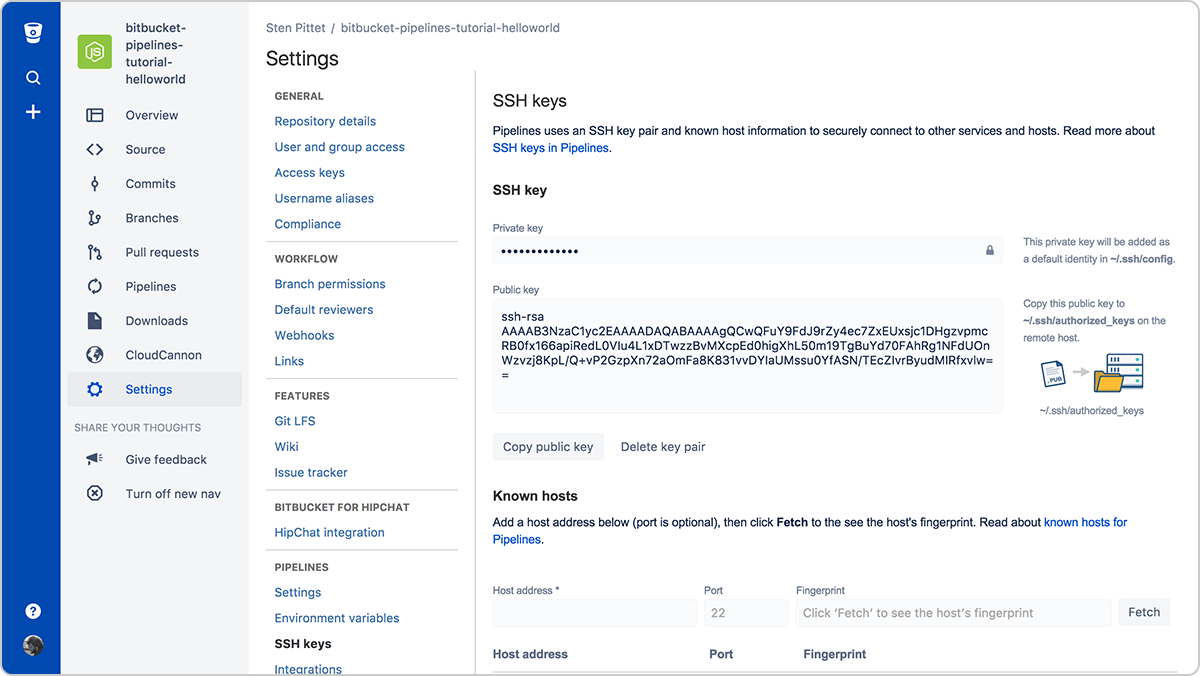
Solo tendrás que copiar la clave pública en el servidor remoto para conectarte desde la canalización que se esté ejecutando. Por ejemplo, con las claves SSH configuradas en el servidor (puedes usar una dirección URL o IP), el script siguiente mostraría archivos en el directorio /var/www sin tener que introducir contraseña.
bitbucket-pipelines.yml
image: node:4.6.0
pipelines:
default:
- step:
script:
- ssh <user>@<server> ls -l /var/wwwRecuerda registrar todos los servidores a los que tengas que conectarte en la sección Known hosts (Hosts conocidos). Si no lo haces, cuando intentes conectar con el servidor remoto, la canalización se bloqueará a la espera de aprobación.
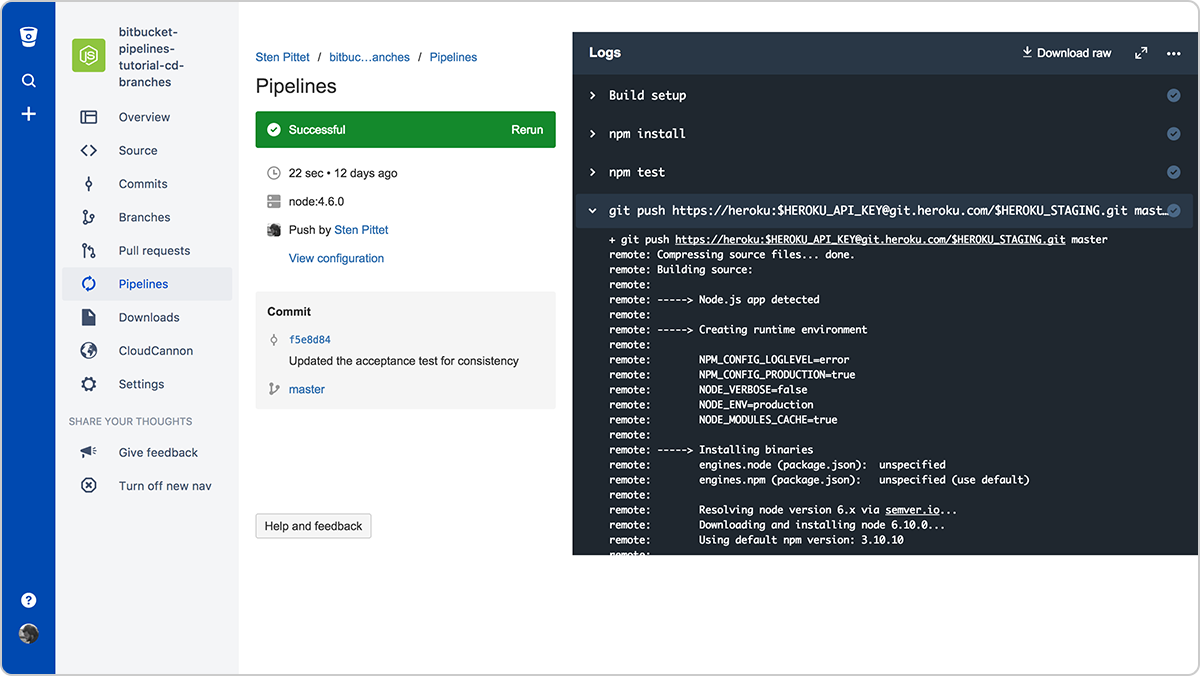
Paso 3: Usa variables de entorno seguras para credenciales y claves API
Si tienes que utilizar una API remota en tus scripts, lo más probable es que tu proveedor de API te permita utilizar sus recursos protegidos con una clave API. Puedes añadir credenciales de forma segura a Bitbucket Pipelines mediante variables de entorno seguras. Cuando las hayas guardado, puedes invocarlas en tus scripts y permanecerán enmascaradas en la salida del registro.
Paso 4: Ejecuta comandos en modo no interactivo
Si tienes que instalar dependencias en tu script, asegúrate de que no piden validación o entrada de datos al usuario. Consulta la documentación de los comandos que utilizas para ver si hay una marca que permita ejecutarlos de manera no interactiva.
Para ejemplo, la marca -y del siguiente comando instalará PostgreSQL en un servidor Debian.
apt-get install -y postgresqlLa marca -q permite ejecutar comandos de Google Cloud SDK de forma no interactiva.
gcloud -q app deploy app.yamlPaso 5: Crea tus propias imágenes de Docker listas para usar
Instalar las dependencias necesarias para que tu canalización se ejecute puede llevar mucho tiempo. Sin embargo, puedes ahorrar mucho tiempo de ejecución si creas tu propia imagen de Docker con las herramientas y los paquetes básicos necesarios para compilar y probar la aplicación.
Por ejemplo, en la siguiente configuración de Pipelines, instalamos la CLI AWS al comienzo para usarla después para implementar la aplicación en AWS Elastic Beanstalk.
bitbucket-pipelines.yml
image: node:7.5.0
pipelines:
default:
- step:
script: # Modify the commands below to build your repository.
- apt-get update && apt-get install -y python-dev
- curl -O https://bootstrap.pypa.io/get-pip.py
- python get-pip.py
- pip install awsebcli --upgrade
- npm install
- npm test
- eb init helloworld-beanstalk-bbp -r eu-west-1 -p node
- eb deploy hw-eb-tutorialEl problema aquí es que la CLI AWS no cambia con cada confirmación, con lo que perdemos tiempo instalando una dependencia que podría combinarse por defecto.
El siguiente Dockerfile podría servir para crear una imagen de Docker personalizada y lista para implementaciones de Elastic Beanstalk.
Dockerfile
FROM node:7.5.0
RUN apt-get update \ && apt-get install -y python-dev \ && cd /tmp \ && curl -O https://bootstrap.pypa.io/get-pip.py \ && python get-pip.py \ && pip install awsebcli --upgrade \ && apt-get clean \ && rm -rf /var/lib/apt/lists/* /tmp/* /var/tmp/*Si lo envío con la referencia spittet/mi-custom-image, puedo simplificar mi configuración de Bitbucket Pipelines para que solo tenga los comandos necesarios para compilar, probar e implementar mi aplicación.
bitbucket-pipelines.yml
image: spittet/my-custom-image
pipelines:
default:
- step:
script: # Modify the commands below to build your repository.
- npm install
- npm test
- eb init helloworld-beanstalk-bbp -r eu-west-1 -p node
- eb deploy hw-eb-tutorialRecuerda: los scripts también son código
Estos consejos te servirán para convertir tareas manuales en procesos automatizados que pueden ejecutarse de forma repetida y fiable con un servicio como Bitbucket Pipelines. En última instancia, serán los guardianes de tus publicaciones y unas herramientas capaces de desencadenar la implementación de tus entornos de producción al completo en varios servidores y plataformas.
Por esto, tienes que tratar tus scripts de automatización como código y hacerlos pasar por el mismo proceso de revisión y de calidad que aplicas a tu código. Por suerte, Bitbucket te ayuda a hacerlo fácilmente, ya que la configuración de tu canalización se verificará con el código para que puedas crear solicitudes de incorporación de cambios en el contexto correcto.
Por último, recuerda ejecutar scripts en un entorno de prueba antes de aplicarlos en la producción: esos minutillos extra podrían evitar que borres datos de producción por error.

Compartir este artículo
Tema siguiente
Lecturas recomendadas
Consulta estos recursos para conocer los tipos de equipos de DevOps o para estar al tanto de las novedades sobre DevOps en Atlassian.

La comunidad de DevOps

Ruta de aprendizaje de DevOps