Come gestire repository di grandi dimensioni con git

Nicola Paolucci
Developer Advocate
Git è la scelta perfetta per monitorare l'evoluzione della base di codice e collaborare in modo efficiente con i colleghi. Ma cosa succede quando il repository che si vuole monitorare è di dimensioni davvero enormi?
In questo post illustrerò alcune tecniche per affrontare questo tipo di situazioni.
Due categorie di repository di grandi dimensioni
Se ci pensi, ci sono sostanzialmente due ragioni principali per cui i repository diventano di grandi dimensioni:
- Accumulano una cronologia molto lunga (il progetto cresce in un intervallo di tempo molto lungo e di conseguenza anche la cronologia)
- Includono un numero notevole di risorse binarie che devono essere monitorate e associate al codice.
...Oppure potrebbe essere per entrambe le ragioni.
A volte il secondo tipo di problema è aggravato dal fatto che gli artefatti binari obsoleti sono ancora archiviati nel repository. Ma per questo problema esiste una soluzione relativamente semplice, anche se fastidiosa (vedi sotto).
Le tecniche e le soluzioni alternative per ogni scenario sono diverse, anche se a volte complementari, quindi ne parlerò separatamente.
Clonazione dei repository con una cronologia molto lunga
Anche se la soglia per definire un repository come di "enormi dimensioni" è piuttosto alta, è comunque difficile clonare questo tipo di repository. E non sempre è possibile evitare le cronologie estese. Alcuni repository devono essere mantenuti intatti per motivi legali o normativi.
Soluzione semplice: clonazione minima di git
La prima soluzione per una clonazione veloce e per far risparmiare tempo agli sviluppatori e spazio su disco ai sistemi è copiare solo le revisioni recenti. L'opzione della clonazione minima di Git consente di estrarre solo gli ultimi n commit della cronologia del repository.
Come si fa? Basta usare l'opzione –depth. Ad esempio:
git clone --depth [depth] [remote-url]
Immagina di aver accumulato nel repository dieci o più anni di cronologia del progetto. Ad esempio, abbiamo effettuato la migrazione di Jira (una base di codice di 11 anni) a Git. Il risparmio di tempo per i repository come questo può essere molto evidente.
La clonazione completa di Jira ha una dimensione di 677 MB e la directory di lavoro è almeno altri 320 MB, per un totale di oltre 47.000 commit. La clonazione minima del repository impiega 29,5 secondi, rispetto ai 4 minuti e 24 secondi di una clonazione completa con tutta la cronologia. Il vantaggio diventa maggiore proporzionalmente al numero di risorse binarie che il progetto ha inglobato nel tempo.
materiale correlato
Come spostare un repository Git completo
Scopri la soluzione
Impara a utilizzare Git con Bitbucket Cloud
Suggerimento: anche i sistemi di compilazione connessi al repository Git traggono vantaggio dalle clonazioni minime!
Le clonazioni minime erano in qualche modo i componenti più deboli del mondo di Git, poiché alcune operazioni erano a malapena supportate. Ma le versioni recenti (dalla 1.9 in poi) hanno migliorato notevolmente la situazione e ora è possibile eseguire correttamente le operazioni di pull e push sui repository anche da una clonazione minima.
Soluzione parziale: comando git filtrer-branch
Nel caso dei repository di grandi dimensioni con tanti file binari sottoposti a commit per errore o vecchie risorse non più necessarie, un'ottima soluzione è usare git filter-branch. Questo comando consente di esaminare l'intera cronologia del progetto applicando dei filtri, modificando e ignorando dei file secondo schemi predefiniti.
È uno strumento molto potente, una volta identificato il punto in cui il repository diventa pesante. Sono disponibili script di supporto che consentono di identificare gli oggetti di grandi dimensioni, quindi questa parte dovrebbe essere abbastanza intuitiva.
La sintassi è la seguente:
git filter-branch --tree-filter 'rm -rf [/path/to/spurious/asset/folder]'git filter-branch ha un piccolo inconveniente, però: quando si usa _filter-branch_, si riscrive di fatto l'intera cronologia del progetto e tutti gli ID di commit cambiano. Di conseguenza, ciascuno sviluppatore deve clonare nuovamente il repository aggiornato.
Quindi, se hai intenzione di eseguire un'azione di pulizia utilizzando git filter-branch, dovresti avvisare il team, pianificare un breve blocco durante lo svolgimento dell'operazione e poi avvisare tutti che occorre clonare nuovamente il repository.
Suggerimento: puoi trovare maggiori informazioni su git filter-branch in questo post sulla suddivisione del repository Git.
Un'alternativa alla clonazione minima di git è la clonazione di un solo branch
A partire da git 1.7.10, puoi inoltre limitare il numero di voci della cronologia da clonare clonando un singolo branch, come segue:
git clone [remote url] --branch [branch_name] --single-branch [folder]Questo espediente specifico è utile quando lavori con branch a esecuzione prolungata e divergenti o se hai un numero elevato di branch e devi lavorare solo con alcuni di essi. Se invece hai pochi branch con pochissime differenze, probabilmente non vedrai una grande differenza se scegli di clonare un solo branch.
Gestione dei repository con un numero elevato di risorse binarie
Il secondo tipo di repository di grandi dimensioni è composto da quelli con un numero elevato di risorse binarie. Si tratta di un tipo di repository incontrato da diversi tipi di team software (e non software!). I team di gioco devono destreggiarsi tra modelli 3D di grandi dimensioni, i team di sviluppo Web potrebbero aver bisogno di tenere traccia delle risorse di immagini raw, i team CAD potrebbero dover manipolare e monitorare lo stato dei deliverable binari.
In termini di gestione delle risorse binarie, le prestazioni di Git sono nella media. Per impostazione predefinita, Git comprime e memorizza tutte le versioni complete successive delle risorse binarie, il che ovviamente non è la soluzione ottimale quando si ha un numero elevato di risorse.
Ci sono alcune modifiche di base che migliorano la situazione, come eseguire la garbage collection ("git gc") o modificare l'uso dei commit delta per alcuni tipi binari in .gitattributes.
Ma è importante riflettere sulla natura delle risorse binarie del progetto, poiché ciò aiuterà a determinare l'approccio vincente. Ad esempio, ecco alcuni punti da prendere in considerazione:
- Per i file binari che cambiano in modo significativo, e non solo per alcune intestazioni di metadati, la compressione delta sarà probabilmente inutile. Pertanto, usa il comando "delta off" per questi file per evitare l'inutile lavoro di compressione delta come parte della creazione di un nuovo pacchetto.
- Nello scenario precedente, è probabile che per tali file non vada a buon fine nemmeno la compressione zlib, quindi è possibile disattivare la compressione con "core.compression 0" o "core.loosecompression 0". Questa è un'impostazione globale che influirebbe negativamente su tutti i file non binari che invece vengono compressi correttamente, quindi questo suggerimento ha senso se si dividono le risorse binarie in un repository separato.
- È importante ricordare che "git gc" trasforma gli oggetti sfusi "duplicati" in un unico file di pacchetto. Ma, ripeto, a meno che i file non si comprimano in qualche modo, probabilmente ciò non farà alcuna differenza significativa nel file di pacchetto risultante.
- Esplora il perfezionamento di "core.bigFileThreshold". Qualsiasi elemento superiore a 512 MB non verrà in ogni caso compresso con delta (senza che sia necessario impostare .gitattributes), quindi forse è meglio modificarlo.
Soluzione per alberi di cartelle di grandi dimensioni: git sparse-checkout
Un piccolo aiuto per risolvere il problema delle risorse binarie è l'opzione di estrazione di tipo sparse di Git (disponibile da Git 1.7.0). Questa tecnica consente di mantenere pulita la directory di lavoro specificando in modo esplicito quali cartelle si desidera popolare. Sfortunatamente ciò non influisce sulla dimensione del repository locale complessivo, ma può essere utile se hai un albero di cartelle di dimensioni elevate.
Quali sono i comandi coinvolti? Ecco un esempio:
- Clona l'intero repository una volta: "git clone"
- Attiva la funzione: "git config core.sparsecheckout true"
- Aggiungi le cartelle necessarie in modo esplicito, ignorando le cartelle delle risorse:
- echo src/ › .git/info/sparse-checkout
- Leggi l'albero come specificato:
- git read-tree -m -u HEAD
Dopodiché, puoi tornare a usare i normali comandi git, ma la directory di lavoro conterrà solo le cartelle specificate sopra.
Soluzione per mantenere il controllo quando si aggiornano file di grandi dimensioni: sottomoduli
[AGGIORNAMENTO]... oppure puoi ignorare tutto e usare Git LFS
Se lavori regolarmente con file di grandi dimensioni, la soluzione migliore potrebbe essere sfruttare il supporto per file di grandi dimensioni (LFS) sviluppato da Atlassian in collaborazione con GitHub nel 2015 (sì, hai letto bene. Abbiamo collaborato con GitHub su un contributo open source al progetto Git).
Git LFS è un'estensione che archivia nel repository i puntatori (naturalmente!) ai file di grandi dimensioni, invece di archiviare i file stessi al suo interno. I file effettivi sono archiviati su un server remoto. Come puoi immaginare, ciò riduce drasticamente il tempo necessario per clonare il repository.
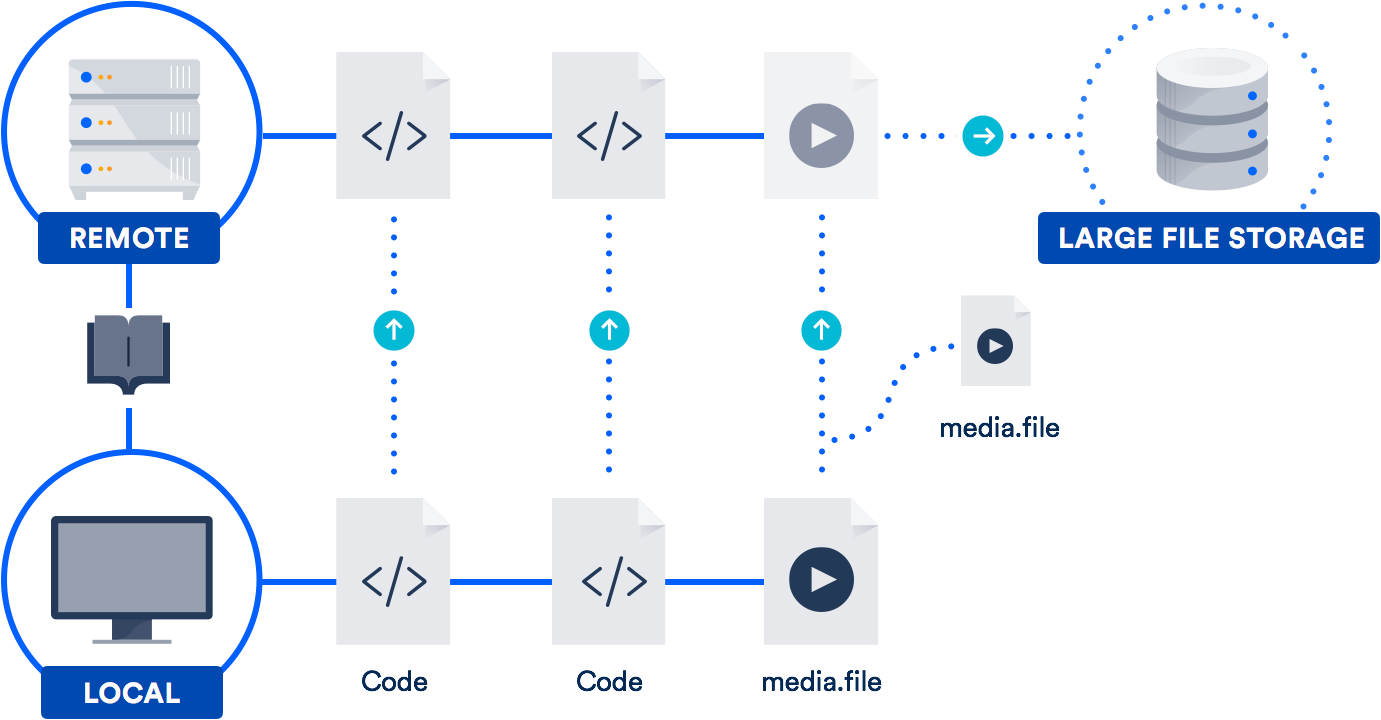
Bitbucket supporta Git LFS, così come GitHub. Quindi è probabile che questa tecnologia sia già a tua disposizione. È particolarmente utile per i team con designer, professionisti video, musicisti o utenti CAD.
Conclusioni
Non rinunciare alle fantastiche funzionalità di Git solo perché la cronologia del repository è di grandi dimensioni o perché disponi di un numero elevato di file. Ci sono pratiche soluzioni per entrambi i problemi.
Dai un'occhiata agli altri articoli a cui ho accennato sopra per maggiori informazioni sui sottomoduli, sulle dipendenze del progetto e su Git LFS. E per gli aggiornamenti sui comandi e sul flusso di lavoro, troverai tantissimi tutorial nel nostro microsito Git. Buona programmazione!
Condividi l'articolo
Argomento successivo
Letture consigliate
Aggiungi ai preferiti queste risorse per ricevere informazioni sui tipi di team DevOps e aggiornamenti continui su DevOps in Atlassian.

Blog di Bitbucket

Percorso di apprendimento DevOps
