如何使用 git 处理大型存储库

Nicola Paolucci
开发人员推广人员
Git 是跟踪代码库演变以及与同行高效协作的绝佳选择。但是,如果您要跟踪的存储库非常庞大,会发生什么情况?
在这篇文章中,我会为您提供一些处理这个问题的技巧。
两类大型存储库
仔细想想,存储库变得庞大的主要原因大致有两个:
- 他们积累了很长的历史记录(项目发展了很长一段时间,历史记录越来越多)
- 其中包括需要跟踪的大量二进制资产,并与代码配对。
…或者可能两者兼而有之。
有时,第二类问题会因为旧的、过时的二进制构件仍存储在存储库中而变得更加复杂。但是有一个比较简单的(尽管很烦人)的解决方法(见下文)。
每种场景的技巧和解决方法各不相同,但有时是互补的,下面我将分别介绍。
克隆历史记录很长的存储库
尽管将存储库限定为“大规模”的门槛相当高,但克隆起来仍然很痛苦。而且您不可能总能避免很长的历史记录。出于法律或监管原因,某些代码存储库必须保持不变。
简单的解决方案:git 浅层克隆
快速克隆并节省开发人员和系统时间和磁盘空间的第一个解决方案是只复制最近的版本。Git 的浅层克隆选项允许您只拉取代码存储库历史记录中最新的 n 次提交。
您是怎么做的?只需使用 –depth 选项即可。例如:
git clone --depth [depth] [remote-url]
想象一下,您在存储库中积累了十年或更长时间的项目历史记录。例如,我们将 Jira(已有 11 年历史的代码库)迁移到了 Git。像这样的代码存储库节省的时间可以加起来,而且非常明显。
Jira 的完整克隆容量为 677MB,工作目录为 320MB,构成了超过 47,000 次提交。代码存储库的浅层克隆需要 29.5 秒,而包含所有历史记录的完整克隆需要 4 分 24 秒。随着时间的推移,优势会随着您的项目容纳了多少二进制资产而成比例增长。
相关资料
如何移动完整的 Git 存储库
查看解决方案
了解 Bitbucket Cloud 的 Git
提示:构建连接到 Git 代码存储库的系统也会受益于浅层克隆!
过去,浅层克隆在 Git 中会受到一定程度的损害,因为有些操作几乎得不到支持。但是最近的版本(1.9 及更高版本)极大地改善了这种情况,现在即使是从浅层克隆也可以正确地拉取和推送到存储库。
详细解决方案:git filter branch
对于那些错误地提交了大量二进制文件或者不再需要旧资产的大型存储库来说,不妨试试 git filter-branch。通过该命令可以浏览项目的整个历史记录,根据预定义的模式筛选、修改和跳过文件。
一旦您确定了自己的代码存储库量很大,那它就是一个非常强大的工具。帮助脚本可用于识别大型对象,因此该部分应该足够简单。
语法如下所示:
git filter-branch --tree-filter 'rm -rf [/path/to/spurious/asset/folder]'不过,git filter-branch 有一个小缺点:一旦您使用 _filter-branch_,就可以有效重写项目的整个历史记录。也就是说,所有提交 ID 都会改变。这要求每个开发人员重新克隆更新后的存储库。
因此,如果您打算使用 git filter-branch 执行清理操作,则应该提醒团队,计划在操作进行时短暂冻结,然后通知所有人再次克隆存储库。
提示:更多关于 git filter-branch 的信息,请阅读这篇文章中关于拆除 Git 代码存储库的信息。
Git 浅层克隆的替代方案:仅克隆一个分支
从 git 1.7.10 开始,您也可以通过克隆单个分支来限制克隆的历史记录量,如下所示:
git clone [remote url] --branch [branch_name] --single-branch [folder]当您使用长时间运行和分散的分支时,或者如果您有很多分支而只需要使用其中几个分支时,这个特定的技巧会很有用。如果您只有少数几个分支,差异很小,那么使用这个可能不会有太大的区别。
处理包含大量二进制资产的存储库
第二种类型的大存储库是那些拥有大量二进制资产的存储库。这是许多不同类型的软件(和非软件!)团队相遇。游戏团队必须处理庞大的 3D 模型,Web 开发团队可能需要跟踪原始图像资产,CAD 团队可能需要操作和跟踪二进制交付成果的状态。
Git 在处理二进制资产方面并不是特别差,但也不是特别好。默认 Git 会压缩并存储所有后续完整版本的二进制资产,而如果您有很多,这显然不是最佳选择。
有一些基本的调整可以改善这种情况,比如运行垃圾回收 (‘git gc’),或者调整 .gitattributes 中某些二进制类型的增量提交的用法。
但重要的是要反思项目二进制资产的性质,因为这将有助于您确定制胜方法。例如,以下几点需要考虑:
- 对于变化显著的二进制文件,而不仅仅是一些元数据头,增量压缩可能毫无用处。因此,对这些文件使用 ‘delta off’,以避免在重新打包时进行不必要的增量压缩工作。
- 在上面的场景中,这些文件很可能也不能很好地压缩,所以您可以使用 ‘core.compression 0’ 或 ‘core.loosecompression 0'关闭压缩。这是一个全局设置,它会对所有实际压缩效果好的非二进制文件产生负面影响,所以如果您将二进制资源拆分成一个单独的存储库,这是有道理的。
- 请务必记住,“git gc”将“重复的”松散对象转换为单个打包文件。但是同样,除非文件以某种方式压缩,否则这可能不会对生成的打包文件产生任何重大影响。
- 探索 ‘core.bigFileThreshold’ 的调整。无论如何,任何大于 512MB 的东西都不会被增量压缩——无需设置 .gitattributes,所以也许这值得调整。
大文件夹树的解决方案:git sparse-checkout
Git 的稀疏签出选项(自 Git 1.7.0 起可用)对二进制资产问题略有帮助。此技术允许通过明确详细说明要填充的文件夹来保持工作目录的整洁。可惜的是,它不会影响整个本地存储库的大小,但是如果您有一个庞大的文件夹树,可能会有所帮助。
涉及哪些命令?下面有一个示例:
- 克隆完整存储库一次:'git clone'
- 激活该功能:‘git config core.sparsecheckout true’
- 添加明确需要的文件夹,忽略资产文件夹:
- echo src/ › .git/info/sparse-checkout
- 按照说明读取树:
- git read-tree -m -u HEAD
完成上述操作后,您可以返回使用普通的 git 命令,但您的工作目录将只包含您在上方指定的文件夹。
控制何时更新大文件的解决方案:子模块
[更新]…或者您可以跳过所有这些然后使用 Git LFS
如果您定期处理大文件,最好的解决方案可能是利用 Atlassian 在 2015 年与 GitHub 共同开发的大文件支持 (LFS)。(是的,没错,我们与 GitHub 合作,为 Git 项目做出了开源贡献。)
Git LFS 是一个指向存储库中大文件的存储指针的扩展(当然!),而不是将文件本身存储在存储库中。实际文件存储在远程服务器上。可以想象,这大大减少了克隆存储代码存储库所需的时间。
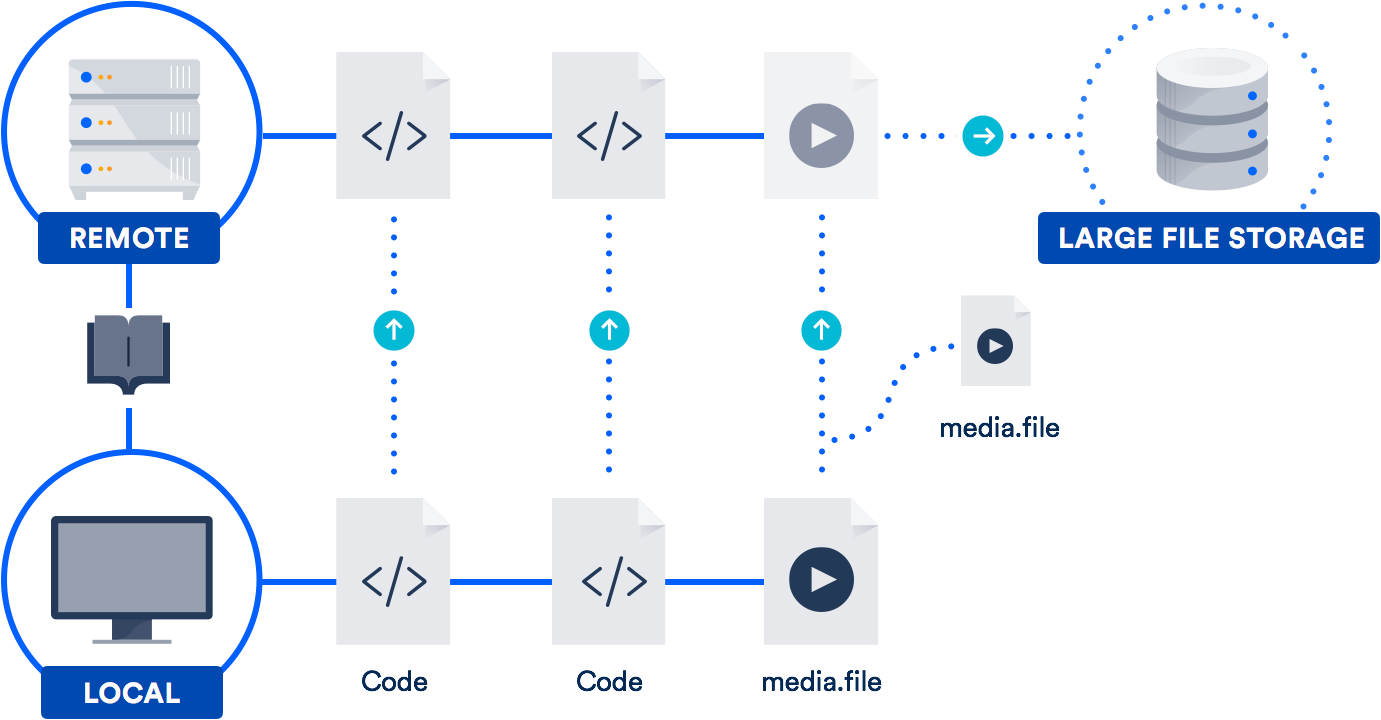
Bitbucket 支持 Git LFS,GitHub 也是如此。因此,您很可能已经可以使用这项技术。它对包括设计师、摄像师、音乐家或 CAD 用户在内的团队特别有用。
总结
不要仅仅因为您有庞大的存储库历史记录或众多文件就放弃 Git 的出色功能。这两个问题都有可行的解决方案。
查看我上面链接的其他文章,了解有关子模块、项目依赖关系和 Git LFS 的更多信息。我们的 Git 微型网站提供了大量教程,供您复习命令和工作流程。祝您编程愉快!
分享此文章
下一主题
推荐阅读
将这些资源加入书签,以了解 DevOps 团队的类型,或获取 Atlassian 关于 DevOps 的持续更新。

Bitbucket 博客

DevOps 学习路径
