
[Captain’s log August 1, 2117 – somewhere off the Gold Coast. What follows is an account of how I created the agile capacity plan for building the software that will power our mission to boil the oceans – and save humanity.]
. . .
If you’re reading this, it means our mission failed and the crew is dead. Or, I’ve left my logbook laying on the counter by the coffee machine again – equally likely.
We are now 18 months into our attempt to wrench Earth out the ice age she was plunged into just three years ago, after a 200-year period of global warming. (Climate change really keeps you on your toes.) The crack team of scientists aboard this vessel determined with absolute certainty and grave head-nodding that the only option left available is to create a sustained wet-sauna effect by boiling the world’s oceans.
We’ve code-named the mission Project Burndown. It will require sending 2.75 billion1 portable nuclear reactors into meltdown, orchestrated by a highly sophisticated piece of software.
Planning Project Burndown’s software component has fallen to this captain, seeing as severe frostbite has incapacitated our project manager. We have a lean team of developers, DBAs, and sysadmins – and one helluva tight timeline. We’ll need to carefully arrange our work so we’ve got the right people with the right skills doing the right work at the right time. Needless to say, agile methodologies and solid capacity planning are of the essence.
Capacity planning (n.) – The calculus and optimization of your team’s capabilities against the work to be done in a particular timeframe
Need to get grounded in the basics first? Try this post about capacity planning with Jira Software.
Initial set-up and estimation
Here on the S.S. Scrumban, we’ve been using Jira Software throughout the mission thus far. The research team braved many a frozen keyboard to create Jira issues during their spike, then grouped related issues into epics while formulating our ocean-boiling strategy.
There’s no time for mucking about with spreadsheets when the fate of humanity hangs in the balance. We’re at the mercy of the iron triangle (people vs. deadlines vs. scope) like never before, so my best bet is to create our project plan with Portfolio for Jira. It automatically pulls in the epics, user stories, estimates, sprint plans, and releases already in Jira Software, and generates the plan for me. Seeing as we’re giving the term “big-bang release” a whole new meaning, knowing whether we can actually hit our (rather literal) deadline is critical.
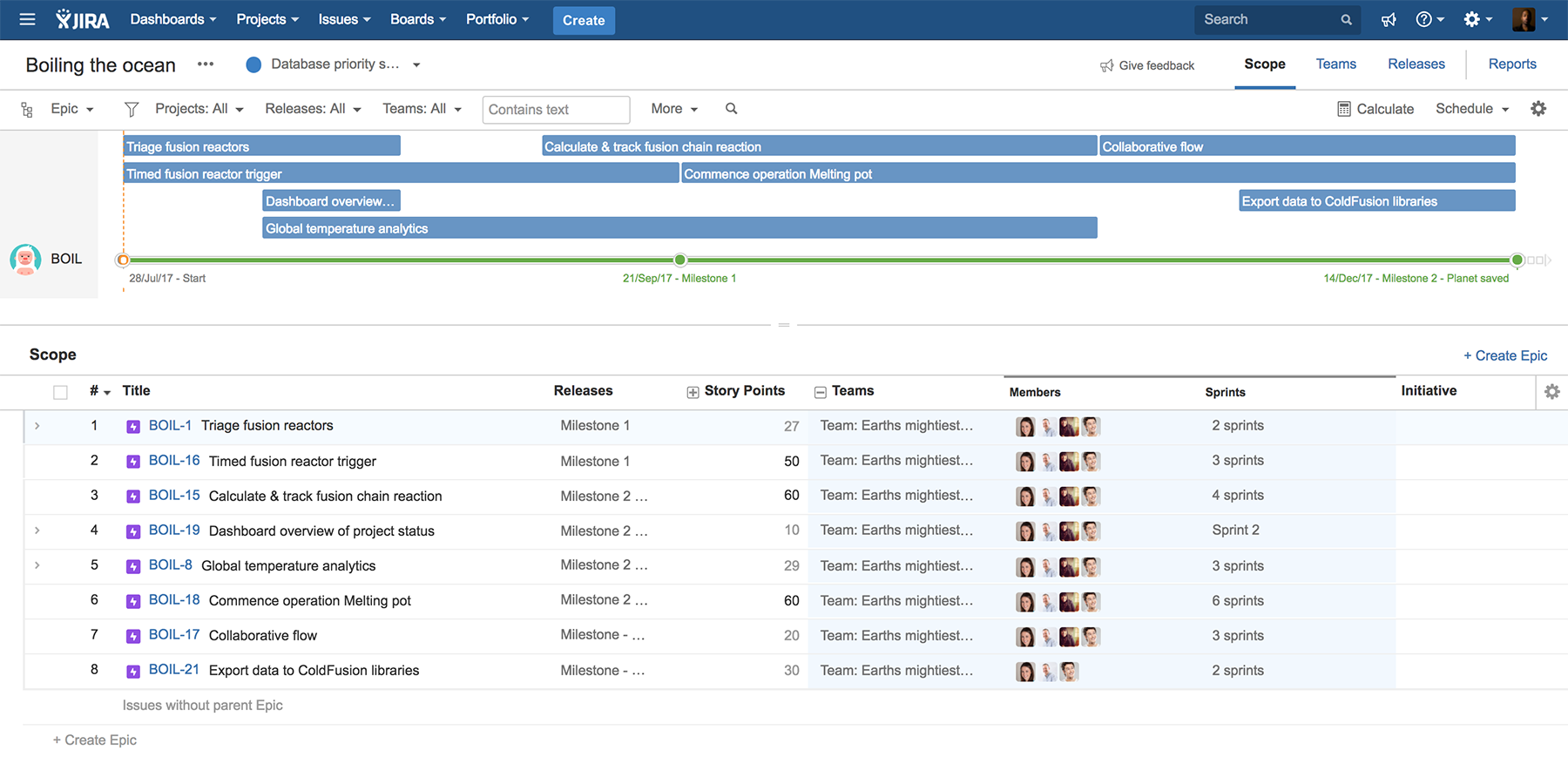
Captain’s pro tip: Remember to set up your team members in Portfolio for Jira so you can navigate all three elements of the iron triangle using one tool.
Estimating the effort each issue requires is essential to building a realistic capacity plan. (Also, estimates seem to be a requirement for using Portfolio for Jira properly.) The developers wanted to use story points to estimate effort and measure the team’s overall velocity. I myself am unfamiliar with these so-called “story points”, but seeing as my suggestion of measuring velocity in knots was a non-starter, I’m rolling with it.
Determining capacity based on available skills
Project Burndown is cross-functional collaboration at its finest. In other words, our team members have specialized skills. And as the team is quite lean, I needed to carefully match specific people with specific tasks. I verified all team members were represented in the plan, assigned to our project, and showed having hours available. I then tagged each of them with the appropriate skills: database administration (Harvey), back-end development (Alana), UI development (Emma), deployment (Kevin).
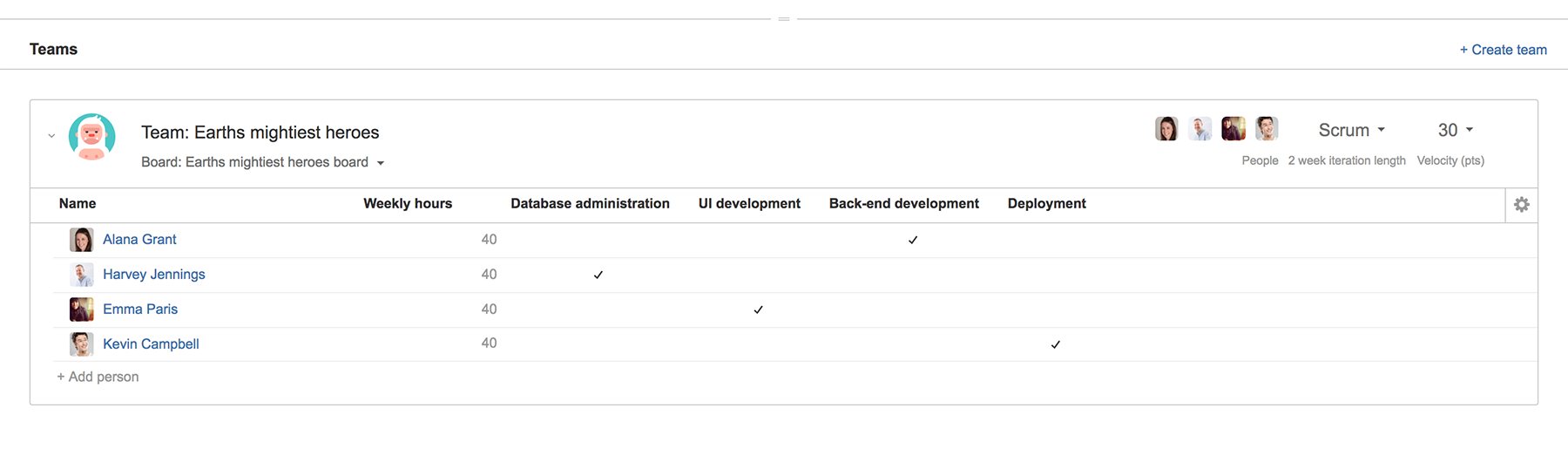
Then I went into each issue to mark which skill/s were required, and their relative importance. For example, the issue about synchronizing each reactor core with the central server is primarily a back-end dev task, but that code also has to be deployed. So I associated eight of the issues’s 13 story points with the “back-end development” skill, and five with the “deployment” skill. From there, Portfolio for Jira’s algorithm assigned each issue to team members based on their specialties.
Captain’s pro tip: If you choose skill-based planning, you’ll need to configure the skills for both team members and tasks before Portfolio for Jira can map out a meaningful capacity plan for you.

It’s likely (inevitable) that new issues will get added along the way (please, just let them not be related to a failing reactor core), but our capacity plan will automatically re-calculate based on their estimates and the capabilities they require.
Captain’s pro tip: Adding skills to the scheduling algorithm introduces complexity that may be hard to navigate at first. Start charting your course at the team capacity level, then once you’ve got your sea legs, move on to skill-based capacity planning.
Fine-tuning the capacity plan
Our project manager had shown me roadmaps in Portfolio for Jira before, which are displayed at the epic or initiative level by default. I looked at our schedule laid out task by task (story by story, in development-speak). Everything from our Jira Software backlog stays in sync with the capacity plan, so all my prep work prioritizing the backlog and parsing issues into sprints was already reflected in the plan. So far, so good.
But high stakes call for high granularity. Besides: the last thing our mission has time for is squabbling over whether the plan is viable. Better to let the data do the talking.
To verify the schedule squared with the realities of imminent doom and nary a redundant team member in sight, I switched to the plan’s capacity view. Imagine my dismay when it showed the team overloaded by several points during the second sprint!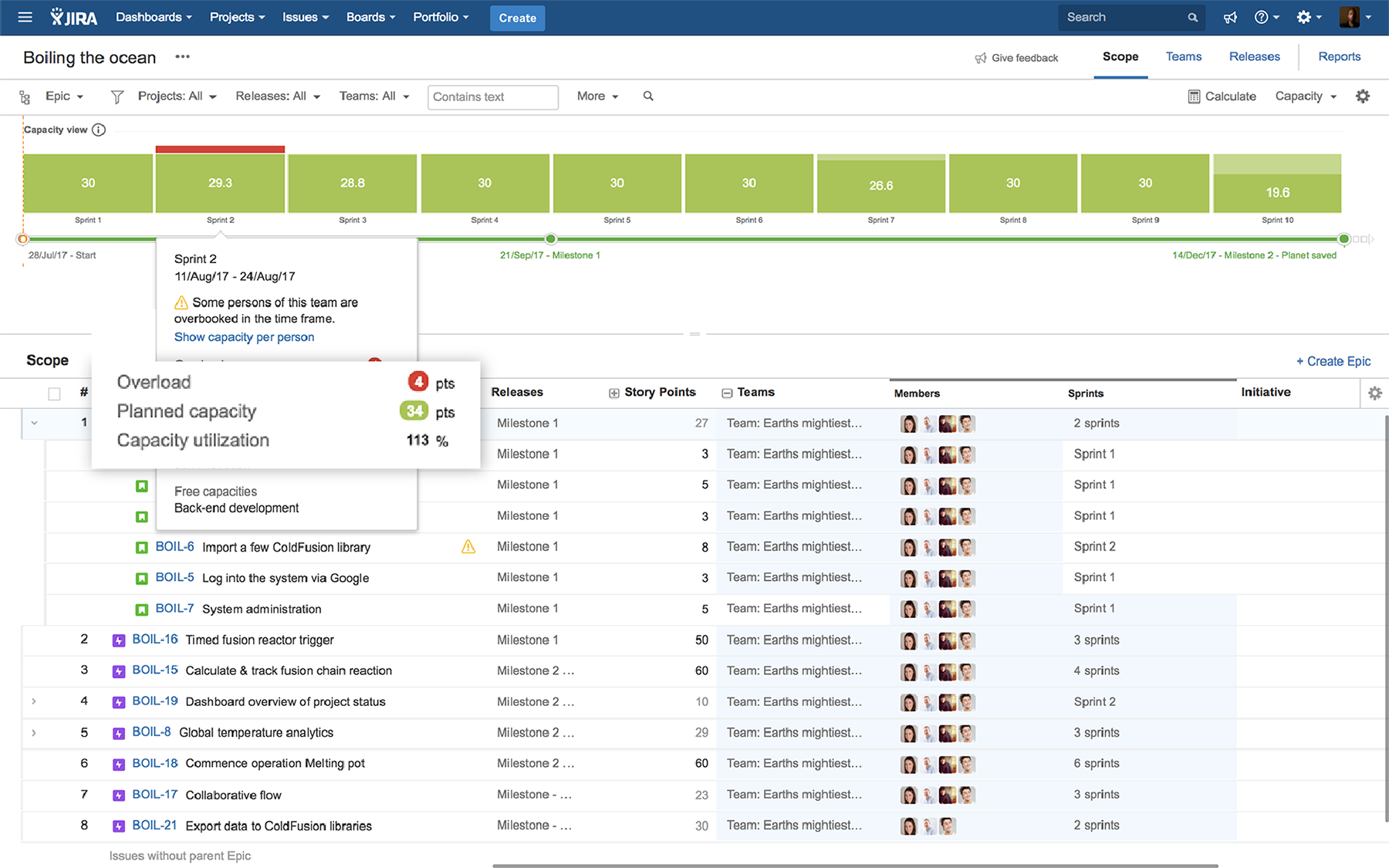
We gathered ’round for a team huddle, and found a way to resolve this crisis-in-the-making with some clever reduction in scope: importing a few ColdFusion libraries would suffice to connect much of the UI to the database. We’ll sacrifice some of the nice-to-have customizations, but technical debt feels rather trivial when the end of the world is quite literally at hand.
I used Portfolio for Jira’s multiple-scenario planning feature to see whether the ColdFusion approach would be enough to make the plan viable. I adjusted the scope in the new scenario by deprioritizing the custom database connector tasks and was relieved to see a lovely green line on the schedule view, indicating we’d be in the clear. I selected that scenario as our official plan and disabled the original.
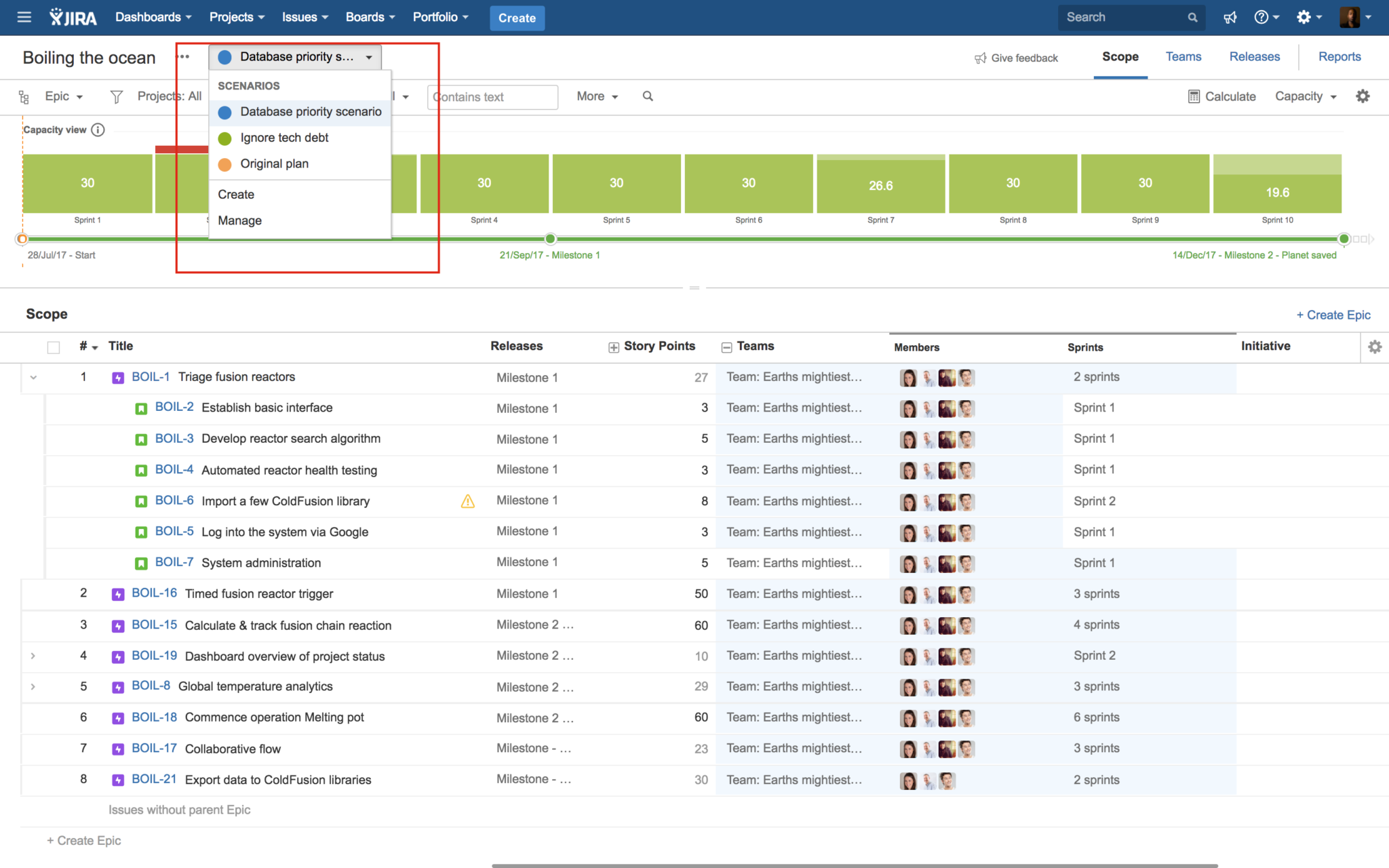
Time to check in on the big picture. I went back to the plan and switched to capacity view. Capacity utilization across the mission (the percentage of available time being used) was 100% – necessary, but zero room for error. Our planned capacity (days, hours, or story points planned for each iteration) was already tight. One slip and this mission will face tighter bottlenecks (places where the flow of work is restricted) than the Strait of Gibraltar.
Last, I pulled up the plan’s capacity report so I could make some detailed cross-checks by sprint, team, and team member. While things looked ok at the team level, I saw our front-end dev was overloaded by several hours in a few sprints. I immediately re-assigned some of her issues to Alana, our other dev. Crisis averted, once again.
Dive in and deliver
With capacity planning in place, we’re now diving into execution mode. Because our capacity plan pulls in the latest data from Jira Software, I’m able to visualize the most up-to-date version of the schedule and see whether we’re on track to win this race against time.
So now, dear reader, I write this log as I gaze at our mission’s schedule report, which is embedded on our planning page in Confluence for all to sea see. The progress bars for epics already underway are steadily filling in as the individual tasks we estimated are completed.

I’m concerned about the “reactor synchronization” epic, which, according to our estimates, should be done by now. But the plan shows the status of its last remaining issue is “In review”, so I should probably just chill out. Pun intended.
From the deck of the S.S. Scrumban, this is Captain Standup, signing off.
. . .
Whatever your mission, Portfolio for Jira helps you match the right people to the right tasks at the right time so you can focus on getting the job done. Haven’t checked it out yet? Don’t delay – that ice age could come sooner than we think.
Take a tour of Portfolio for Jira
1There are roughly 1.4 billion cubic kilometers of water in the world’s oceans, with an average temperature of 4° C. To raise the water to a boiling point of 102° C (accounting for the salt), requires 98 calories per cubic centimeter. The most powerful portable nuclear reactors on the planet release 51026 calories of heat upon meltdown. This mission will require simultaneous meltdown of 2.75 billion of these beasts. We have sent our sincerest apologies to all fish, whales, and coral. The sharks, however, can bite us – they’ve had their run of the place for 420 million years, so time’s up.
Props to the Reddit community for doing the math.



