
Behind the Demo: How Cross‑functional Partnerships Turned AI “Golden Prompts” into Real Customer Value
How cross‑functional teams used golden prompts to turn AI hype into reliable, accountable outcomes — on stage and in everyday work.
In the run‑up to Team ’25 Europe, I was working on how to create content with Rovo, an AI‑powered creation experience that turns prompts plus context into ready‑to‑use work in Confluence: pages, plans, PRDs, briefs, and more. As a Product Marketer, my job wasn’t just to make it look magical in a demo. It was to make sure it actually helped real people do their jobs better.
For Team ’25 Europe, we wanted creating with Rovo at the center of our story. That gave us two clear objectives:
- The product needed to work reliably in realistic conditions
- It needed to showcase clear, undeniable value on stage
Essentially, we couldn’t fake it with cherry‑picked moments. The experience had to hold up in the same messy environments where teams actually work, with real stakes and real expectations.
To get there, I partnered closely with Product, Engineering, and other Marketers to optimize the create with Rovo experience so it produced high‑quality outputs tailored to realistic, specific use cases by persona. Together, we built a set of “golden prompts” and story‑first demo scenarios across Marketing, Sales, Program Management, Product, and Engineering, which our Engineers could then rigorously pressure‑test — until we trusted them live.
In this post, I’ll walk through:
- What “golden prompts” are — and when they actually matter
- How to design prompts around real workflows and personas (with examples)
- A repeatable process for testing AI outputs across tools
- How we mapped realistic demo scenarios using Confluence Whiteboards
- How cross‑functional teams share responsibility for AI‑assisted decisions
What is a “golden prompt” — and when should you use one?
A golden prompt is a specifically phrased request that reliably produces a high‑quality, high‑stakes output for a well‑defined use case.
We knew we didn’t need unrealistically clever prompts. We needed the right prompts — the ones that would matter when people were actually accountable for outcomes. It means:
- The stakes are real (the output will be used in front of customers, leaders, or in live execution).
- The goal is clear (we can describe what a “good” output looks like in advance).
- The inputs are grounded in trustworthy context (work data, docs, and examples).
- The output is repeatable across tools and runs, not a one‑off lucky win.
Golden prompts are not for every AI interaction. If the work is one‑off, low‑risk, or easily fixed by a single person, you probably don’t need golden prompts yet. As soon as AI starts influencing shared plans, decisions, or customer‑visible work, it’s worth treating a small set of prompts as strategic assets.
Why we started with golden prompts (with examples)
In other words: golden prompts aren’t about showing off what AI can do in a vacuum. They’re about designing the few, critical interactions where AI touches decisions, customers, and delivery in a visible way.
We defined 10–15 golden prompts per persona. Each one captured:
- A specific outcome (campaign plan, PRD, sprint board, report)
- The real‑world constraints (channels, segments, timeframes, stakeholders)
- The minimum quality bar we’d be proud to show live and ship to real teams
Here are a few golden prompt examples.
For Marketing
- Create a reactivation campaign plan for [user segment], using [marketing channels], referencing their previous usage and new features released since they left
- Create a webinar outline for [topic] targeting [audience]. Include: compelling title, 5-slide agenda, key talking points for each section, audience engagement moments (polls/Q&A), strong CTA, follow-up resources.
For Sales
- Create a report extracting from [CRM tool] to include my deals for [timeframe], including the customer, segment, ACV/TCV, and a summary of each
- Analyze previous call recordings, footprint, and CRM notes on [customer] to further personalize discovery questions tailored to this account towards a potential solution
For Product
- Create a PRD for [feature]. Include sections for 1. User Stories (at least 3, in ‘As a… I want… so that…’ format), 2. Acceptance Criteria for each story, 3. Success Metrics (KPIs) for the feature, and 4. Technical Considerations
- Identify 3-5 emerging trends relevant to [theme/category]. For each trend, explain its potential impact on our product strategy and suggest a strategic response
For Engineering
- Create a sprint planning whiteboard for the upcoming release cycle for [project/launch], listing team members, sprint goals, prioritized backlog items, story point estimates, and capacity planning
- Generate API documentation for [Service]. Include details for Request Parameters, Response Body (JSON schema), Error Codes (404, 500), and a cURL example.
For any Knowledge Worker
- Start a Retro Board for the upcoming retrospective session with my team
- Create an Out of Office page for these [dates], with the right back ups for the priorities I’m working on
We treated these golden prompts as an alignment device. They forced clarity on:
- The user’s actual goal
- The available context (first‑ and third‑party knowledge, work data)
- What “great” looks like in the final artifact — not just “good enough” for a screenshot
These prompts became our north star for quality. If creating content with Rovo could reliably handle these, we knew we were building something teams could trust when the stakes were real.
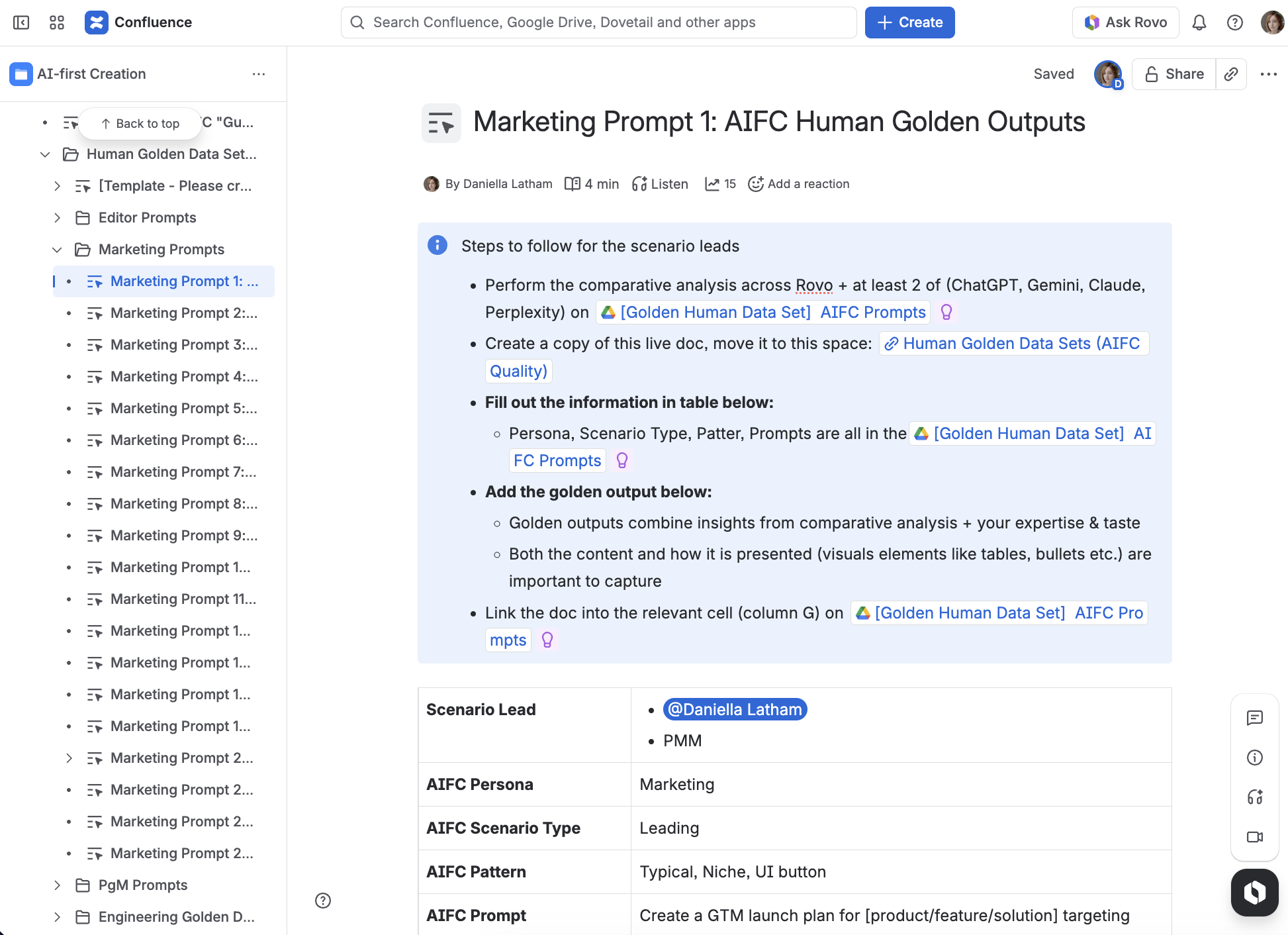
How we defined prompt “quality” — and why it mattered
Next, a braintrust of folks across Marketing, Product, and Engineering tested the prompt output relentlessly across multiple AI tools, including ChatGPT, Claude, Gemini, Perplexity, and our very own Rovo. We documented outputs in Confluence and tracked progress in Jira. Using multiple tools served a purpose:
- It reduced over‑reliance on any single model
- It helped us spot recurring weaknesses (e.g., missing sections, hallucinated details)
- It showed where our context and prompts needed tightening
The bar was simple and unforgiving: if a golden prompt didn’t yield an output we’d be proud to show live—and put in front of our customers!—we refined the prompt, clarified the task, or improved the context. We also merged outputs from various AI tools to get the best possible outcome.
For us, a “high‑quality” output needed to:
- Work consistently across tools and runs
- Match the real needs of that persona (not an abstract persona sketch)
- Be immediately actionable in the work context where it would be used
Our step‑by‑step Golden Prompt evaluation process
We ended up with a repeatable process that any team can adapt:
- Define target output and audience upfront
Who will use this, and what decision or task should this output move forward? - Specify inputs clearly
What context should AI pull from? What’s in scope, out of scope, or off‑limits? - Run across multiple tools
Compare outputs for clarity, structure, and actionability. Note where each tool struggles or overreaches. - Tighten phrasing to remove ambiguity
Replace soft asks (“help with”, “improve”) with specific instructions, formats, and required sections. - Re‑test until the output is top‑tier
If the output still feels like something you’d hesitate to share with stakeholders, keep iterating.
This process did more than improve prompts. It forced shared ownership of what “good” looks like — and where AI should stop so humans can take over.
Designing real‑world scenarios with Confluence whiteboards
Here’s where Product Marketing could really shine. I mapped our top scenarios end‑to‑end to bring the creating with Rovo experience to life:
- Where the human starts (an executive ask, a noisy board, a half‑baked idea)
- How Rovo shapes the work (synthesis, structure, first drafts, options)
- Where alignment happens (review, critique, decisions)
- How outcomes turn into artifacts (plans, PRDs, boards) that drive execution
We focused on two persona stories in particular:
- Marketing: turning executive asks into collaborative outreach plans and content
- Product: synthesizing research, generating PRDs, and orchestrating work across teams
In both journeys, we deliberately toggled between:
- Divergent phases (brainstorming, exploration, synthesis)
- Convergent phases (formatting, structuring, decisions, and next steps)
That produced plausible demos and “magic moments.” This is where many “AI stories” break down in the real world—showing the messy back‑and‑forth prompting where humans and AI refine, question, and adjust together.

Once our prompts were more stable, we optimized scenarios for the live event environment. Using Confluence whiteboards first before creating screens and animations helped us define human/AI handoffs, decide where to pause for impact and where to streamline so the story kept momentum.
By mapping those loops on a whiteboard first — before we built screens, animations, or keynote flows — we could:
- Make human/AI handoffs explicit
- Decide where to pause for impact in the live demo
- Streamline so the story kept its momentum
The result was demos that felt real because they were real: grounded in workflows that would still make sense the morning after the event.
Why this work went beyond “a good demo”
From the outside, this might look like “just” a demo prep story. In reality, the work reflects how we think about AI‑assisted experiences more broadly.
- Golden prompts are most useful where accountability is highest.
These aren’t everyday experiments. They’re the prompts that produce plans, reports, and decisions you’d still stand behind weeks later. - Quality is a shared responsibility, not a prompt‑writer’s problem.
Our strongest prompts came from combining product truth, technical constraints, and go‑to‑market realities — not from a lone expert tweaking wording in isolation. - Scenario design matters as much as model choice.
By mapping journeys end‑to‑end, we saw exactly where AI should help, where it should defer, and where humans must remain clearly responsible.
Cross‑functional partnership: our unfair advantage
The best prompts didn’t come from one person. They came from a cross‑functional braintrust that stayed involved from idea to stage to product:
- Product Managers brought the product truth: what’s feasible today, what’s coming, and which workflows actually matter to teams.
- Engineers stress‑tested feasibility and edge cases, and helped us understand how prompts interacted with real data and systems.
- Product Marketing kept us anchored on real use cases, narrative flow, and user relevance, making sure we were solving for accountable, not hypothetical, work.
Using our cross-functional braintrust early paid off immediately. It showed up in:
- The confidence we had going into the live demo — we weren’t hoping it would work, we’d already done the hard testing
- The shared standard we built around responsible, reliable AI in the places where delivery actually has consequences.
- The experience customers get now, when they create content with Rovo in the same kinds of scenarios we rehearsed on stage
The good news is that creating and editing with Rovo is now live and available to all! Read this blog to learn more, and start creating content with Rovo today by clicking here.
This work was deeply cross‑functional, and I owe a huge thank‑you to everyone who helped us design, test, and harden these golden prompts.
Product management: Aniket Vaidya (who led much of the early work) and John Murnen
Engineering: Paul Borza, Velu Alagianambi, Peter Martigny, and Dhanraj Jadhav
Sales: Scott Silver
Marketing: Shelley Wang and Nidhi Chaudhry
And our Program Managers: Manjiri Soman and Guru Prakash Nagarajan