

In one sentence
Agent context pruning is how Rovo Dev keeps long-running coding sessions useful by removing the least valuable context first, preserving the most important parts of the conversation, and only collapsing to a summary when necessary.
AI agents become more useful as they work through longer tasks. But longer tasks also create a memory problem.
A serious coding agent accumulates a growing trail of context: user requests, assistant responses, tool arguments, tool results, file contents, search results, workspace views, and intermediate reasoning steps. Over time, that history can become large enough to crowd out the context that actually matters for the next decision.
That is where context pruning comes in. In Rovo Dev, pruning is the mechanism that maintains long sessions inside the model’s working memory by compacting the least valuable context first – without throwing away the conversation wholesale.
Why pruning matters
Language models have a limited context window. Once a session gets large enough, one of two problems occurs:
- the model can no longer fit all relevant history and starts losing important context; or
- interactions suffer from an increasing tax in tokens, latency, and degraded reasoning quality.
This gets especially acute for coding agents, because they tend to generate and consume large amounts of machine-produced text. A single session may include huge tool outputs, repeated file views, and multiple intermediate tool-calling steps that were useful in the moment but are not equally valuable forever.
The key idea
Not all context is equally valuable. A long tool result from 40 interactions ago is usually much safer to trim than the user’s most recent request or the original setup for the task.
Pruning is not just summarization
When people hear “context management”, they often jump straight to summarization. Summaries are useful, but they are not the first tool we reach for.
Our goal is to preserve as much of the original conversation as possible for as long as possible. That means starting with the least destructive operations first:
- Trim large machine-generated tool outputs before user-authored messages;
- Prefer removing redundant or low-value intermediate steps over removing task-defining context;
- Protect the most recent exchanges so the model keeps local coherence; and
- Use summary collapse only as a last resort.
In other words, pruning is not “compress everything”, it’s structured forgetting.
How pruning works in practice
In Rovo Dev, pruning can happen in two ways:
- Automatically, when the conversation is approaching the model’s context limit.
- Manually, when the user chooses to compact the session more aggressively.
Automatic pruning is important because it means the user does not need to babysit context budgets. The system can monitor the session as it grows and compact it before the next model call would become risky.
Manual pruning is important for a different reason: sometimes users know they have reached a natural checkpoint and want to trade more history for more headroom. In those cases, Rovo Dev can prune moderately, prune aggressively, or migrate the session into a fresh one anchored by a compact summary.
A cascade from least destructive to most destructive
The core design principle is simple: prune in stages, and stop as soon as the history is small enough.
Instead of immediately rewriting the conversation into a summary, Rovo Dev moves through a cascade of increasingly aggressive operations. Early steps target the kinds of content that are usually easiest to remove safely; later steps only kick in if more reduction is still needed.
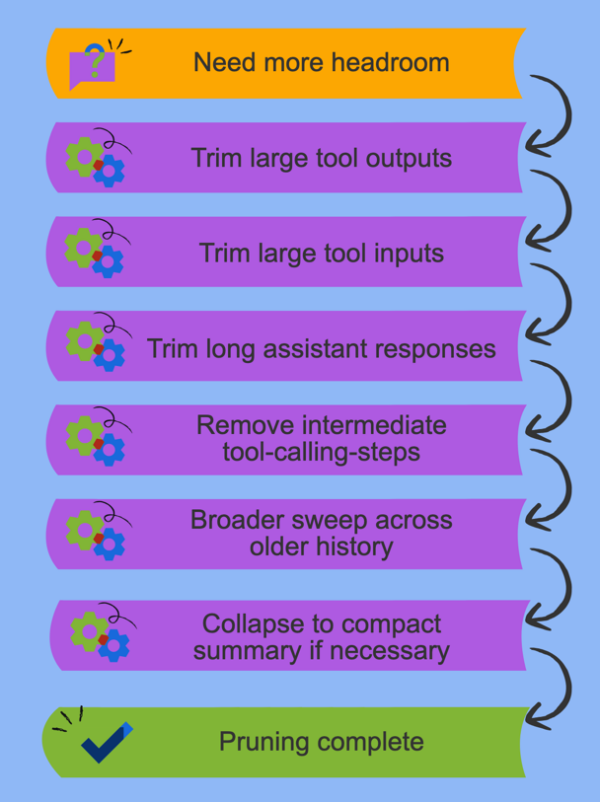
That cascade matters because different content types carry different kinds of value:
- Tool outputs are often large, machine-generated, and already acted on.
- Tool inputs may be helpful in the moment, but are often less important later than the outcome they produced.
- Assistant responses can often be compressed more safely than the user’s original intent.
- Intermediate scaffolding from multi-step tool use is frequently lower value than the final result.
The goal is to keep the session legible while reclaiming as many tokens as possible from the least essential material first.
What we protect
A good pruning system is defined as much by what it refuses to remove as by what it trims.
There are two especially important protections in Rovo Dev:
- The beginning of the conversation, which often contains the original task framing, constraints, or setup instructions.
- The most recent interactions, which are critical for local coherence and immediate next-step planning.
This “protect the edges” strategy turns out to be very important. The first interactions often explain what the agent is trying to do; the latest interactions explain what it should do next. The middle is where much of the bulky, lower-value operational exhaust tends to accumulate.
Practical heuristic: keep the task definition, keep the current thread of work, and compact the bulky middle first.
Practical heuristic
Keep the task definition, keep the current thread of work, and compact the bulky middle first.
Why coding agents need more than naive truncation
Many simple systems handle large contexts by chopping off the oldest messages. This is easy to implement, but it’s a poor fit for coding agents.
In a software task, an early interaction may contain the architectural constraint, the acceptance criteria, or the user’s actual objective. Blindly deleting the oldest part of the conversation can erase the reason the session exists.
At the same time, a coding agent often accumulates a lot of highly compressible content in the middle of a run:
- large search results,
- repeated file views,
- intermediate tool traces,
- oversized command output, and
- assistant messages that are much longer than the final state they produced.
That is why pruning for agents is not just a token-budget trick. It is part of the solution’s memory architecture.
Structure-aware pruning vs. LLM-based compaction
A common alternative to structure-aware pruning is LLM-based compaction: take a long session, feed the conversation back into a model, and ask it to produce a shorter markdown summary.
That approach can work, but we believe structure-aware pruning has several major advantages.
| Approach | Strengths | Trade-offs |
|---|---|---|
| Structure-aware pruning | Instant, free, and preserves the original conversation structure for the parts that remain. | Drops content mechanically rather than rewriting it, so once something is pruned it is gone unless it is still represented elsewhere in the surviving conversation. |
| LLM-based compaction | Can condense a long session into a human-readable markdown narrative. | Adds latency and cost, rewrites structured conversation into plain prose, and discards the original interaction structure entirely. |
The biggest advantage of structure-aware pruning is that it is instant. There is no extra model call, no waiting for a summarization step, and no additional failure mode where the compaction itself is low quality.
The second advantage is that it is effectively free. Mechanical pruning does not require paying another LLM to reprocess the conversation just to make it smaller.
Just as importantly, structure-aware pruning preserves far more of the conversation’s original form. LLM-based compaction takes a sequence of user and assistant messages, tool call JSON, and tool results, then rewrites all of that into markdown. Once that happens, the original structure is gone. Tool calls are no longer tool calls; they become prose. Message boundaries are no longer message boundaries; they become prose. And any detailed information inside bulky tool results is usually dropped anyway – just as it is in pruning – because that is where most of the token savings come from.
That leads to a practical question: if a reasonably capable model is already producing concise summaries of its own progress as it works, why spend another model call to summarize those summaries again? In many sessions, the bulky parts are not the user’s messages or the assistant’s high-level progress updates. They are the large mechanical artifacts around them: oversized tool outputs, repeated file views, intermediate traces, and other low-value operational exhaust.
Our view
If the expensive part of the session is mostly bulky machine-generated text, the best first move is usually to prune that text mechanically rather than asking another LLM to rewrite the whole session.
So overall, we think structure-aware pruning is the better default. It’s faster, cheaper, and less destructive to the parts of the conversation that still matter. LLM-based compaction still has a place as a more aggressive fallback, but it should not be the first thing you reach for.
Summary collapse is a fallback, not the default
There are times when targeted trimming is not enough. In very long sessions, or when a user explicitly asks for maximum compaction, the best option is to collapse the conversation into a compact written summary.
But we think this should be treated as a fallback, not the primary strategy.
Why? Because summaries are lossy by design. They are powerful, but they also convert rich history into a narrower representation. If you can preserve the original conversation structure while removing low-value bulk, that is often a better trade-off.
So the general strategy is:
- Try targeted pruning first;
- Stop as soon as enough headroom has been recovered; and
- Only summarize when the session truly needs a more aggressive reset.
What pruning buys you
When pruning is done well, it improves more than just raw token usage.
| Benefit | Why it matters |
|---|---|
| Longer useful sessions | The agent can stay coherent over more interactions without hitting context limits. |
| Better quality retention | The model keeps the parts of the conversation that are most important for the next decision. |
| Lower context waste | Bulky low-value text stops crowding out high-value task context. |
| Better user experience | Users do not have to constantly start over just because the conversation got long. |
Why we think pruning is a core agent capability
As agents become more capable, they also become more vulnerable to their own success. A useful agent explores, searches, reads files, calls tools, and accumulates evidence. That is exactly what makes context management hard.
So for us, pruning is not a side optimization – it’s part of what makes an agent viable in the real world.
If you want AI agents that can work through complex software tasks over many interactions, they need some way to decide what to remember in full, what to compress, and what to let go. We think least-destructive context pruning is one of the most practical answers to that problem.
Wrapping up
Context windows will keep growing, but so will the ambition of the agents that use them. This is why pruning matters;- it’s not because context is scarce forever, but because long-running agents will always need a disciplined way to decide what deserves to stay in the model’s working memory.
If you haven’t tried Rovo Dev, please give it a go, either in your IDE or your terminal.



