
Advancing modern teamwork
AI thinking and product news to unleash the potential of teams

Why individual AI speed isn’t delivering the ROI CIOs expected
89% of executives say AI has increased speed. Only 6% can point to org-wide ROI. IDC’s Wayne Kurtzman and Atlassian’s Liz Fosslien unpack what’s missing – and where CIOs should start. Everyone on your team is faster. So why isn’t your organization moving further? That’s the provocation at the center of a recent fireside chat […]

Why AI alone isn’t enough for enterprises (and what Mercedes-Benz did about it)



Latest by topic

How Atlassian and Dropbox are driving effective AI transformation
Adopting AI technology without an effective strategy is costing the Fortune 500 an estimated $161 billion a year.* Enterprises are making big investments in this space but are struggling to realise the returns. We know the technology is designed to make businesses more efficient, but we’re still seeing the opposite because most businesses are treating […]
What 5M+ daily MCP tool calls taught us about the future of AI at work
Over a million users trust Atlassian’s Rovo MCP server every month to do real work through agents. We dug into those interactions: how AI agents are actually used at enterprise scale, and who gets the most value.
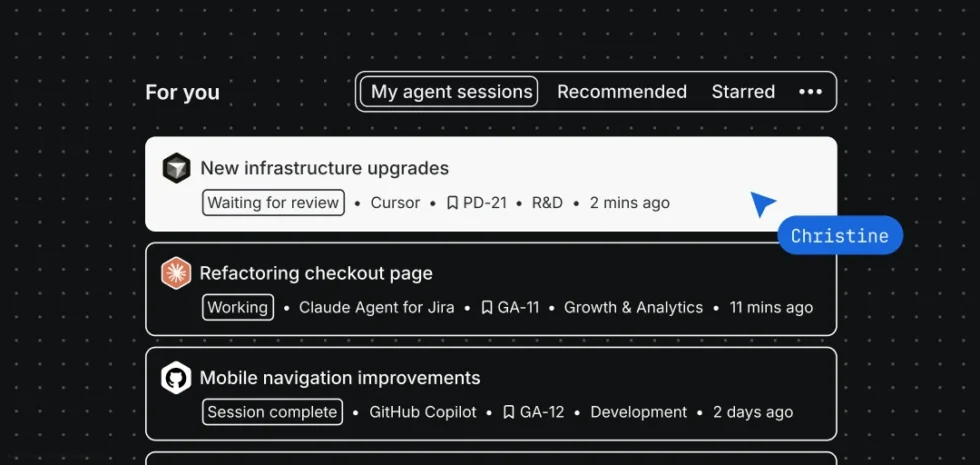
Every agent. Every state. Full visibility in Jira.
See what’s stuck, what’s shipping, and what’s complete. All in one place. Starting today, every software team working in Jira can get visibility into agents they’re running across their spaces and repos in a single view, grouped by what needs attention first. Validating agent output at scale Engineering orgs are rapidly scaling from working manually […]

AI that knows your business
How Atlassian connects your organizational memory across tools, teams, and decisions
Subscribe for more
Inside Atlassian
Get the latest research and insights on AI, teamwork, and more.

Introducing Claude Agent for Jira
Delegate coding tasks to Claude, anywhere in Jira

Meet the Knowledge Architect: The Role Every AI-First Organization Will Need Soon
While most enterprises are talking about how they approach AI transformation, increasingly knowledge management and arranging the required context are important factors in whether or

New research shows honesty about AI use at work is backfiring
New research from Atlassian’s Teamwork Lab finds that workers who disclose using AI are judged as 10x lazier than peers doing identical work, unless their

Teaching AI to speak our design language
Atlassian’s use AI to design and build every day, but AI tools are only as good as the context they have. We translated the Atlassian

Stop counting who uses AI. Start finding who’s transforming with it.
At Atlassian, we’ve gone through three evolutions of how we measure employee AI adoption. Each time we changed the metrics, we learned something telling about

The AI-native SDLC is paying off: 19% more PRs and 2–3 hours saved per developer per week
Reimagining software development around an AI-native SDLC AI is now a core part of how software gets built. 93% of developers use AI tools and

Atlassian Design System: Building the context engine for the AI era
Design systems are no longer ‘just’ about consistent UI and component libraries. They’re strategic capabilities that harness design intent, drive coherence and accelerate a team’s

How to minimize the impact of manager changes
Outcomes hinge on how the transition is handled, not how often it happens.

Advice for first-time managers, from leaders who’ve been there
If you’re new to leading a team, take these 29 tips from a slew of seasoned managers.

How executives can bridge the strategy-execution gap for tech-driven organizations
Learn how C-levels can remove chaos and drive clarity by building a truly connected enterprise and optimizing their approach to AI.

How to handle team conflict as a first-time manager
Three scenarios specific to new managers, plus what to do when all else fails.

75 inspirational leadership quotes you haven’t heard yet
For something to inspire and support your work, take a look at these quotes from true leaders.

Your employees might not feel like they matter. These are the subtle signs
As humans, the only way to survive and thrive is through our relationships with other people. That means mattering to others is a survival instinct,

The Dunning-Kruger effect: why and how we overestimate our own abilities
We all have the tendency to overestimate our own abilities (yes, even you). Here’s how to make sense of this cognitive bias.

Brain drain: Are Zombie Projects eating your team’s productivity alive?
Picture the scene: You’ve returned from a wonderful holiday break, invigorated to tackle ambitious projects, and then it hits you. Maybe it’s pinned to your

Toxic positivity at work: how to spot it and squash it
Though well-intended, extreme optimism can hurt more than it helps. Here’s how you can trade false reassurance for true resilience.

All brains on deck: 10 best practices for knowledge-sharing
One person’s knowledge isn’t enough to execute the work that really matters. Even your team can’t go it alone. To make great things happen, your

How hands-on workshops boost teamwide AI confidence
When teams learn by doing, AI stops feeling abstract and starts driving real behavior change, from higher usage to stronger everyday skills.

Better together: 8 essential teamwork skills to master
Use these strategies to align expectations, streamline communication, and crush your goals.


Accelerating government modernization with AWS
Government technology teams face a growing mandate: modernize faster, strengthen security, and prepare for an AI-powered future all without disrupting mission-critical systems. To help agencies

Agentic Pipelines now supports OpenAI Codex
Bring your Codex agent into Bitbucket Pipelines. A few weeks ago, we announced support for Claude agents in Bitbucket Pipelines. Today, we’re adding OpenAI Codex


Trace packages back to their source pipeline
When we introduced native Pipelines authentication for Bitbucket Packages, we made it easier to publish artifacts from CI/CD without relying on personal credentials. Now we’re

Improving Code Reviewer with Atlassian PR Context
Code Reviewer already knew the rules. We gave it history. Rovo Dev Code Reviewer catches PR issues related to code bug, code design, code readability,

Build AI-powered Forge apps with Atlassian-hosted LLMs
LLMs have become a core tool in every app developer’s stack, powering features that feel almost magical. Users can query data with natural language, summarize

How We Cut up to 80% of Engineering “Chores” Using AI Agents in Jira
Flaky tests and stale feature flags drain engineering time quietly. Here is how Atlassian’s engineering team uses AI agents in Jira to automate both.

From Ambiguous Questions to Action: Research Mode in Rovo Dev CLI
Not every developer question starts as a coding task. Sometimes the hard part is figuring out where to look: Jira for work history, code for

Accelerated frontend development with RovoDev in a practical example
How it started What happens when a project estimated at two to three quarters gets built in 14 working days? In 2022, the team built

Rovo Dev in Jira as my Spec Driven executor
Intro – my standard flow In my daily work, I have consistently followed the same workflow (also before AI era). With this method, I consistently

Optimisation Tools for Jira: Reducing Configuration Bloat and Enhancing Performance
As Jira Cloud grows to support larger and more complex customers, so does the configuration that powers their work: custom fields, work types (formerly issue

The bottleneck keeps shifting: What AI is changing about how we build
Over the past few decades in the technology industry, some of the biggest constraints to building products have been about having enough engineers, time, or

Designing In Variables: How Control Panels Accelerate The Way We Design
A year ago, my workflow looked very different. When a design problem opened up, I explored it by hand. Multiple screens. Multiple flows. Sometimes two

Designing AI products you can depend on
Everyone is shipping AI products now, and most look impressive in demos but fail in the messy reality of daily work. The problem often isn’t

Inside Atlassian’s Merge Queues: How we ship faster with fewer incidents
At Atlassian, we use Merge Queues to ship frequent changes with confidence and streamline pull request merges. Across some of our busiest codebases, Merge Queues
Design Technologists: The role that turns creativity into code
At Atlassian, a new kind of role is collapsing the gap between idea and reality and changing how quickly teams can move from ‘what if’

See our newest AI research

New research reveals how AI is making jobs bigger
New research from Atlassian’s Teamwork Lab finds that the more people use AI, the more their capabilities expand—suggesting AI is broadening what workers can do, not simply replacing them.

AI made your people faster. But it’s your office that’s slowing them down.
AI made individuals faster, but your office is still designed for the old bottleneck. Atlassian research reveals a new framework for the AI-enabled office.
Watch, listen, and learn

How CTOs and CHROs will drive the next wave of AI value
AI is everywhere, but 96% of business leaders say it has not translated into company-wide ROI. Join this webinar for a research-backed look at how CHROs and CTOs can partner to drive the kind of AI adoption that delivers meaningful business impact.

Atlassian’s Chief Product & AI Officer on building AI with enterprise context
What gives one enterprise an AI advantage over another? According to Atlassian Chief Product & AI Officer Tamar Yehoshua, it’s not simply access to the latest models, it’s the depth of enterprise context. In this episode of Technovation, Tamar joins Peter High to discuss how Atlassian is leveraging decades of workflow history through its Teamwork […]

AI Working Agreements Play
Without clear expectations, AI adoption and outcomes may be limited. This Team Playbook Play helps align your team on why, when, and how to use AI so it becomes a seamless, trusted part of your workflow.

Designing for the beautiful mess of modern work
The best ideas often come from false starts, conflicting opinions, and rapid iteration. Teamwork is messy, and AI might make it even messier. But the Chief Design Officers of Atlassian and Figma are designing for that reality to turn friction into a creative edge. In this conversation, Charlie Sutton (Atlassian) and Loredana Crisan (Figma) discuss […]
Explore more

Atlassian named a 4x Leader in the 2026 Gartner® Magic Quadrant™ for DevSecOps Platforms

Atlassian named a Strong Performer in The Forrester Wave™: Strategic Portfolio Management Tools, Q2 2026

Prevent container image overwrites with immutable tags in Bitbucket Packages

How Loom turns customer support into a driver of business growth with Atlassian Customer Service Management

How 24 Hour Fitness transformed IT operations with Jira Service Management and Rovo Ops


Subscribe to unleash the potential of your team
Inside Atlassian
Research and insights on how teams can deliver with AI.