This is a guest post from Glen Semino, Customer Success Manager at SYNQ.fm
When I first started working at SYNQ, where we provide APIs that allow software developers to easily incorporate video in their web or mobile applications, one of my first tasks was to find a simple and practical way to communicate the health of our services to our users. There were also a few constraints to solving this problem in that whatever process we chose had to be scalable for using with the various APIs we offer and something that our lean team of less than 10 could handle 24/7. To spite these constraints we were able to build a compelling solution for communicating the health of our services to our clients by using the tools we chose in a smart way, this is the story of how we did it.
In the beginning when I started working on a solution, the SYNQ operations team would communicate any service related issues to clients via email, Twitter and through private Slack channels, however, this was not an effective way to keep everyone to up to date on all service related issues. The existing process was not efficient in two ways. First, due to our small team, it was not possible to keep customers updated on all the channels about the status of a service or services during an outage. Second, since operations and support had to do a lot of manual communication to customers, it meant they had less time to help development solve a problem during an outage.
I started doing a little research on tools out there for doing this and I ended up choosing Statuspage. The reasons for choosing Statuspage were the following:
- I had used Statuspage before and the level of support I received was always exceptional. To the point where at my previous company, one of Statuspage’s founders came out to our office and helped us get started setting up our first status page.
- Statuspage has a vast number of integrations with other tools that are used for alerting, monitoring and testing APIs. Thus, we knew Statuspage would be future proof with any of the tools we currently use and any future tools we want to use to monitor the health of our services.
- After trying out a few things on Statuspage, it was apparent that it would be very simple to add our integrations and customize the look and feel of our status page. Thus we knew getting up and running would not take too much time.
Integrating services with Statuspage
Once I knew Statuspage was the service we would be using to communicate the health of our APIs to our clients, I styled our status page and added components for the services we would be reporting status on. Additionally, I made a list of the main services/tools that we would use to track, report and monitor the health of our APIs. The services are:
- Runscope – we use this service to run tests against our APIs. We are able to run simple test such as hitting URLs to more complicated tests such as uploading an actual video file.
- Pagerduty – we use this service to alert us directly via phone or text message if a test fails in Runscope or any other services we use such as Amazon CloudWatch.
- Slack – we use this chat tool for all internal communication. It also sends us messages in our private Slack channels when a Runscope test fails or if a Pagerduty alert is triggered.
- Twitter – we use this social media platform to report any issues to our clients using a special status handle.
Now that I knew everything that we needed to report into our status page, the next step was seeing what we wanted to connect to Statuspage and how. Going through each tool, I noticed that all the tools/services we were using already reported into Pagerduty. This is where Statuspage comes in since we wanted to alert clients when something is going wrong. Thus, we followed a simple guide provided by Statuspage and both Pagerduty and Statuspage were now connected. The next step was connecting each component in Statuspage to a particular service alert in Pagerduty. After that, we needed a way to communicate any status updates from our status page to our existing communication channels. Once again, Statuspage already had integrations with Twitter and Slack so we followed the Twitter guide and the Slack integration guide. We now had Slack and Twitter integrated with our status page.
Building our process
Now that we had integrated all the pieces we wanted into our status page, we made it our central point for communicating all types of health about our APIs to our clients. As part of our operations process, Statuspage allows us to easily create and update incidents as they are happening. In addition to using the Statuspage feature for scheduling maintenance, we can schedule a maintenance message ahead of time. Since our status page is integrated with Twitter, any updates or messages posted on our status page can automatically go to our Twitter account. Our team is also up to date on everything that is happening since our status page also communicates with Slack.
As part of our operations process, one major advantage of connecting things the way we did with Statuspage is that it automated part of our operations. For example if a test that is connected to one of our APIs fails in Runscope:

This will trigger an alert in Pagerduty:
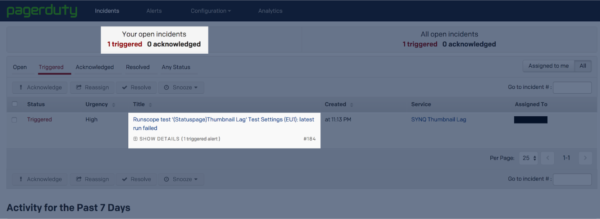
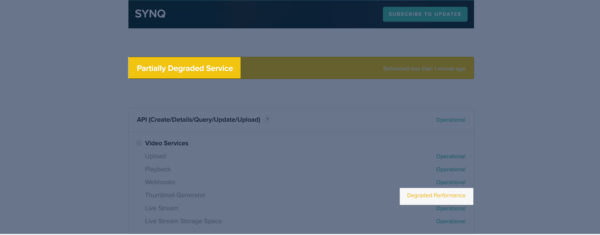
Pagerduty will then alert our operations team via a phone call or text message to let them know what Runscope test failed. The alert also triggers our status page to update the specific component being affected which lets our clients know what API or service is having a problem:
When the test in Runscope that was failing starts passing, everything self resolves:
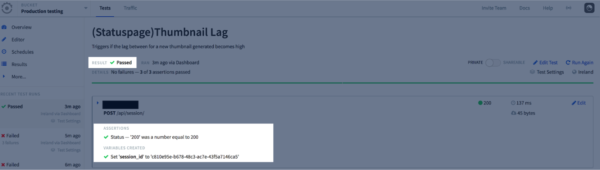
Pagerduty will resolve the service alert:
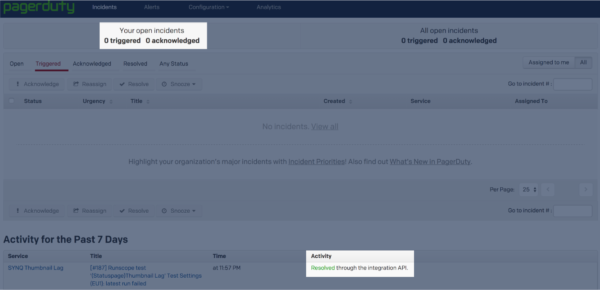
Which then causes the component on our status page to self heal and post a message letting everyone know the incident was resolved:
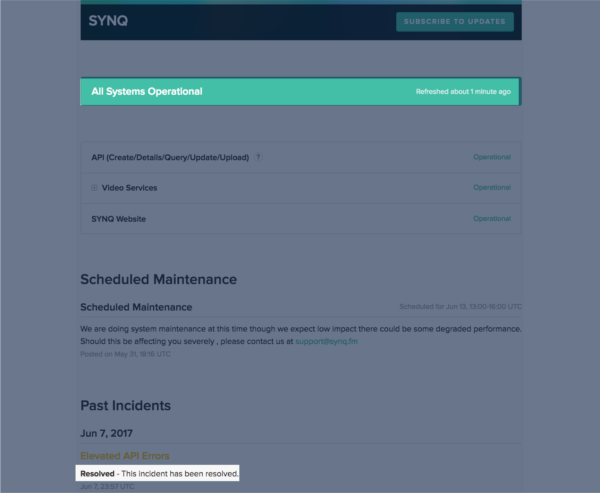
During incidents like outages, this has been indispensable in that it gives our team time to investigate the incident while customers are kept up to date on what is happening. Even after an incident with Statuspage we are able to easily add a link to our root cause analysis (RCA) blog posts in the incident post-mortem section.
What we learned
By using Statuspage in the way that we do, we have built a modern operations process that allows us to be effective at communicating incidents or service maintenance to our clients the moment it is happening. We learned that you do not have to build your own custom status page from scratch, nor does it have to take months to build. With Statuspage, we were able to integrate easily with all the monitoring tools we were already using and putting it all together only took a week at most. Also, as we need to add integrations we know we will be covered.
Finally, we learned that the operations process we created at SYNQ using Statuspage to communicate the health of our services to clients could be applied to any API or SaaS based company that wants to offer their users a compelling and transparent experience.