

If you’ve ever created products that can be deployed in different types of environments, you know that it can be challenging to migrate between one and the other since the core architecture often needs to be very different. We learned this the hard way back in 2018 on Confluence, when a large number of customers trying to migrate from server to cloud were having problems. It was a challenging, prone-to-failure process that required a lot of attention and preparation from site admins.
With that being said, we’ve significantly improved the migration path by releasing the Confluence Migration Assistant for Confluence to the Atlassian Marketplace last October.
We’d like to share the engineering journey behind that work. This includes an explanation of the challenges we faced, the solutions explored and implemented, and some of the interesting engineering problems we had to solve in order to increase the migration success rate by nearly 75 percent.
What happened to Server to Cloud migrations?
Back in the good ol’ days – circa 2002 – server applications were all the rage. Atlassian was no exception to this trend, with Jira and Confluence making their debuts as server-only applications. But the wheel of time turns, tech trends come and pass. Cloud offerings were on the rise. To respond to this, we deployed some server applications in a hosted environment, and thus Atlassian Cloud was born.
This worked pretty well for quite some time, but as our Cloud offering started to become more popular, the model started to present its limitations. Specifically, we were maintaining and developing a single codebase that had to perform as an awesome server offering in one environment and an awesome cloud offering in another. The result was a very large amount of compromise for both offerings.
Fast forward to 2016, and we decided to take a big leap and start developing Cloud separately from Server. This was pretty exciting for both Server and Cloud as it allowed us to really start optimising the products for their relevant environment. Unfortunately, this decision did provide one fairly large concern; what if our customers wanted to move between the two offerings? To unblock development, we decided on a simple, short-term approach; a pact. Put simply, both sides of the organisation – which included the products and all of the plugins – agreed that they would not change their database schema until things were stable enough to revisit the decision. With that pact in place, it meant that the existing data import/export format could remain unchanged. Problem solved!
Unfortunately, things weren’t quite that simple. As time went by, we started running into a plethora of migration-related issues:
- Product divergence With code base split came the rapid evolution of our cloud offering, including the commencement of the biggest project in Atlassian’s history – a complete re-architecture of the Cloud infrastructure. Combine this with a massive evolution of our server offerings, and you end up with two completely different products who are trying to maintain a common schema. This meant that a Server export file would often contain data that was simply not recognized in Cloud, such as many of the third-party plugins
- File size Exporting a mature Server instance was seen to frequently result in file sizes upwards of 20GB. Attempting to upload and process such files was extremely error-prone and time-consuming. To make things worse, the complex dependencies and relationships required to reconstruct an instance meant that we would often only learn that things were going to fail several hours into the migration.
- Bad data A huge number of our failures were due to data simply not being right. For example, if a Mac user were to unzip the export file, the OS would automatically insert a .DS_Store file. This violated the expected file structure and caused the migrations to fail. There were also a lot of different versions of Server out there that were trying to migrate to Cloud, with many containing slight variants that resulted in data that Cloud could not understand.
- Inflexibility The primary solution we developed supported a restore of the entire server instance into Cloud. However, we soon learned that there were a lot of different use cases – such as site merges – that such a solution did not support. Confluence provided some additional flexibility by providing space-by-space migrations, yet these imports needed to be performed manually for every space.
The end result was a terrible user experience, with Confluence site migrations failing the majority of the time. We needed to fix this.
Solving migrations
In late 2016 a small team was spun up and charged with solving the migration problem. After some research, we identified the key concerns that needed to be addressed; user experience, flexibility, scalability, and reliability.
From these requirements came the idea to develop a Server plugin that enabled users to incrementally select which data they wished to migrate to a cloud site and trigger that migration directly from their server instance in the form of a “migration plan”. The plugin would be capable of retrying intermittent failures, identifying incompatibilities/bad data upfront, providing real-time metrics on plans’ progress, and actionable details if anything were to go wrong.
To break the problem down, we elected to start by tackling a single product first. With Jira’s failure rate significantly lower, and Confluence already providing manual space-by-space import/export functionality, Confluence seemed like the natural place to start.
Coordinating migrations
For the plugin to perform a migration, a number of steps were required. First, it had to ask its host product to perform an export. That export file then needed to be uploaded to the Atlassian Media Platform; a platform that facilitates the intelligent and reliable storage and retrieval of very large files. An import can then be initiated using the uploaded file as a data source.
From the plugin’s perspective, a single space migration is as follows:
- Export: Exporting the data as a zip file
- Upload: Uploading the zip file to Media, which would issue a Media file ID
- Import: Initiating the import by sourcing the data from the zip file in Media
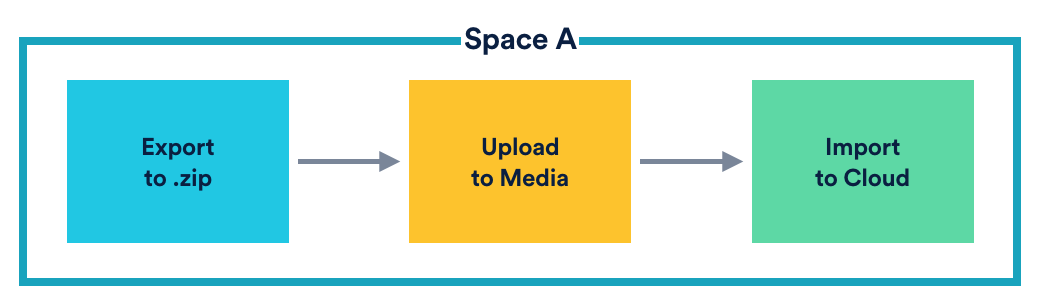
We refer to these as the steps required to migrate a space. So, if you had four spaces, the plugin would need to coordinate 12 steps. Of course, the simplest solution would be to enforce sequential processing of all steps. However, let’s say you wanted to migrate 1000 large spaces, where each step took an average of five minutes to complete. You would end up waiting for more that ten days for the migration to finish, so we figured it made sense to try and paralelise things where we could.
The difficulty here, however, is the number of dimensions that need to be considered. Specifically, the plugin allowed users to create N plans, and the user can run 1..N plans at any time. Each plan could contain 1..M spaces, and it took three steps to migrate each space.
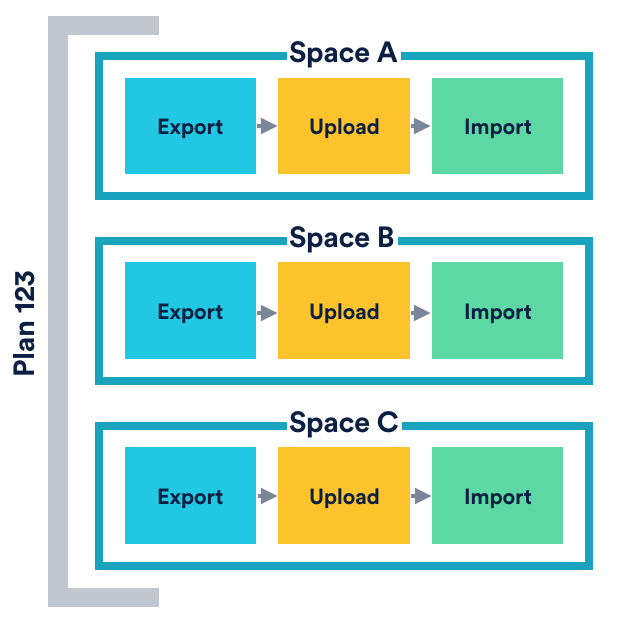
That’s not so bad, right? We could just define some workflow and run it in a different thread for each space. Whilst that would work for a while, it would not scale for all operations. Consider two of the steps that we needed to run; export and upload. Performing an export required many database operations, and so performing too many at once posed risks in overwhelming the product database. Given that this was obviously unacceptable, we needed to be mindful of how many exports we were performing at once. Contrast this to an upload, however, where we were sending data to a platform service that was built to scale massively. In this case, we could embrace concurrency much more aggressively, helping speed up the migration. As a result, we needed to be able to control the concurrency level for each step type.
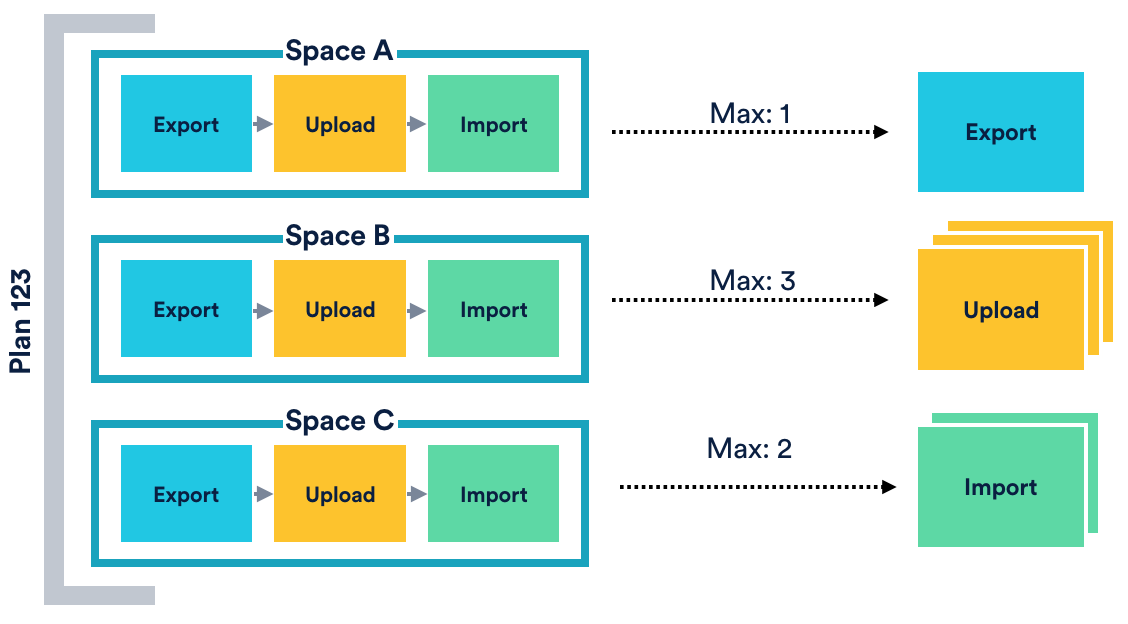
This still didn’t sound too bad. Java has all kinds of support and libraries out there that make stuff like this possible. There’s just one last, small problem: to address the scaling requirement, we needed to engineer our solution to function on multiple nodes, which meant that our design had to work in a distributed environment.
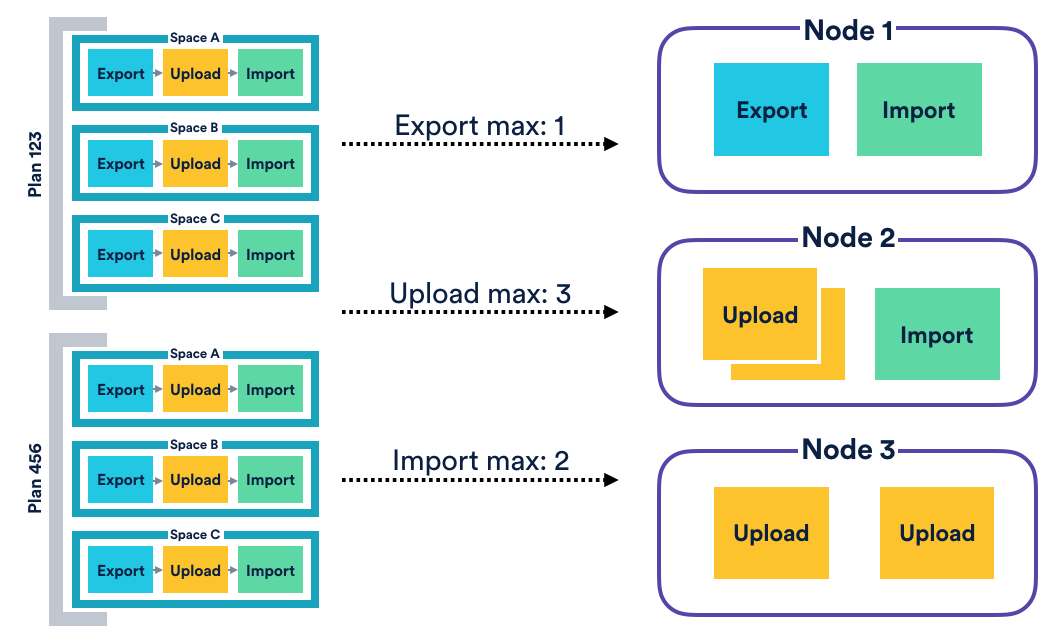
To support this, we assigned each step type a dedicated cluster-aware queue. A broker would be polling each queue type to check for work. Once it saw some unclaimed items, it would claim and dispatch at most M items to that step type’s consumer, where M is the consumer’s concurrency level.
The consumer could then proceed with the execution of its step, reporting its progress along the way. Each consumer would be responsible for implementing its work in a robust manner, performing retries where it knows it makes sense. Each consumer can also determine whether or not it accepts step-level retries for cases where a step failed unexpectedly and had to be re-dispatched by the broker. For example, if a space export failed, it is safe to retry the entire operation. This is not the case for a space import, however, which was not guaranteed to be an idempotent operation.
The contents of each queue would be controlled by the “step coordinator”, which is essentially just some code that defines the sequencing logic. When a user starts a migration, the step coordinator would put the first step for every space onto the queue. Once the consumer had completed its step, it would notify the step coordinator of its result, which would then determine whether or not it needs to enqueue another item onto another queue.
Only after the next step has been successfully enqueued will the previous step be removed. This ensures that if a node was to die, the step will become available for re-dispatching.
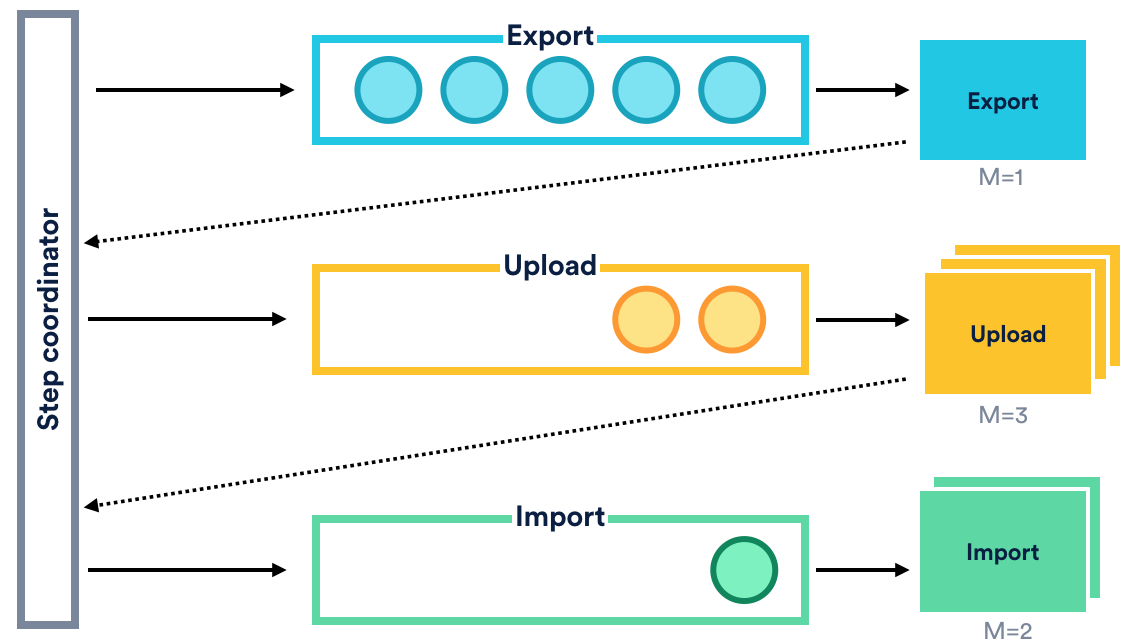
This process would be repeated until all necessary steps have been processed, or the plan had been stopped. If multiple plans were run at the same time, their steps would just be added to the queue.
The end result was a solution capable of reliably migrating many spaces, from many plans, on many nodes, in parallel.
Optimizing migrations
After building the first (internal) version of the plugin, we started to see a significant improvement to the overall migration experience. Unfortunately, it quickly became clear that large file sizes were not only problematic for site-level migrations; very large space imports were shown to have higher rates of failure.
Confluence Cloud export zip files contain all the information about the site – pages, comments, attachments, etc. However, a quick investigation revealed that a huge proportion of the file size came from attachments, making up around 90 percent of the overall export. This made it clear that addressing attachments independently from the rest of the data could present a significant gain in reliability and performance. So, we got to work in investigating how we could handle attachments as a totally separate step in the migration process.
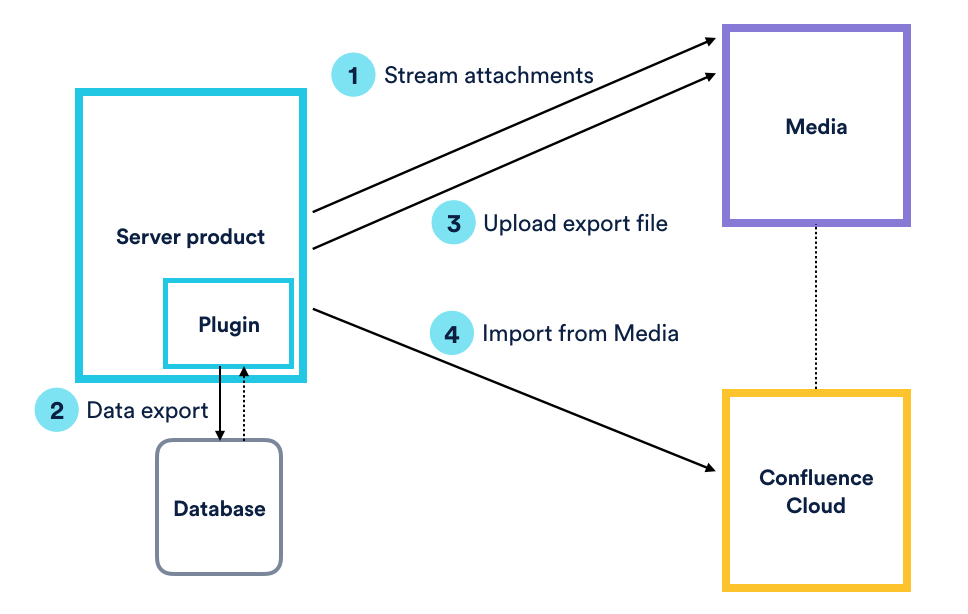
After some research, we discovered that Confluence Server version 5.9 (2015) added a feature to store attachments on remote file systems. The feature was added before the Confluence Server and Confluence Cloud code base was split, and it was retained on both the versions of the product.
The import space functionality in Confluence Cloud is capable of handling export files from Confluence Server and Confluence Cloud, which got us thinking; what if we upload attachments from Confluence Server directly to the Atlassian Media Platform (which basically acts as a remote file system used by Confluence Cloud to store attachments), then use this old unused, version 5.9 functionality to trick the Confluence Server export into thinking that the attachments were actually stored in Media and not in a local file system? As it turns out, this plan worked beautifully! We were able to exclude attachments binary data from the export file, which significantly reduced the export file size and improved the reliability of space export functionality.
This new design came with a number of benefits:
- Increased performance: Attachments could be uploaded in parallel for several spaces, directly from the plugin.
- Increased resilience: If a single attachment failed to upload, the plugin would move on and process the others. That’s right: it would not fail the migration! Additionally, if a space import failed, only the content would need to be corrected and re-uploaded – the attachments would already be there.
- Reduced IO: Behind the scenes, we had a bunch of IO calls that were required to reliably zip and process very large files in Confluence Server and then unzip them in Confluence Cloud. Streaming the attachments directly to media meant that we significantly reduced the number of required IO operations.
With these benefits in mind, we elected to move forward and define a fourth step for each space migration; attachment upload. This step would be performed before all other steps, with each consumer spinning up a number of threads to stream many attachments to media in parallel.
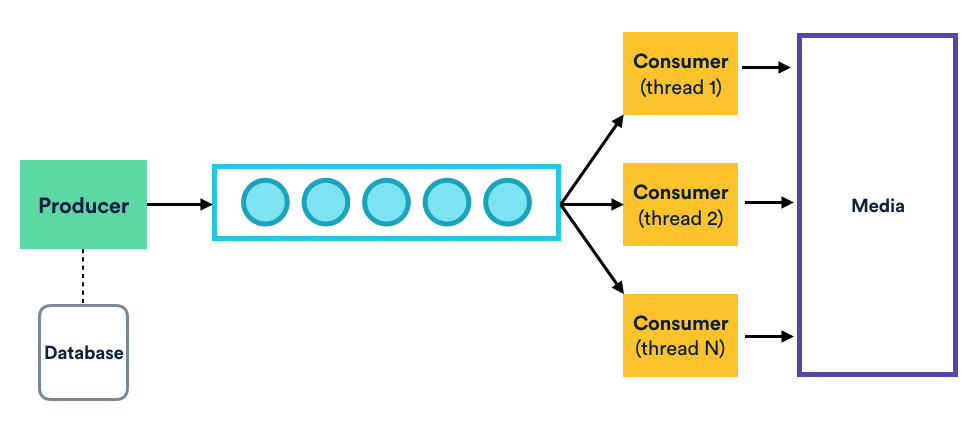
This parallel upload was an interesting engineering problem in itself. In our case, we applied the well-known and battle-tested Producer-Consumer pattern; a worker would find the attachments to upload and publish their details to a shared blocking queue, to which several consumers would be listening to. Each consumer could then claim a file and upload it to Atlassian Media Platform.
The implementation of “One Producer – Many Consumers” algorithm is fairly straightforward. Although, there are several gotchas. For example, how to synchronize work between Producer and Consumers and make sure that fast Consumers (uploading small attachments) will not be blocked by slow Consumers (uploading potentially very large files), and at the same time ensuring the Producer will not generate too much data? In other words, how to guarantee that at any point in time there is enough work in the queue for all Consumers?
Our solution to this requirement was simple: we set queue size to be equal to “consumers count” + “count of attachments added to the queue by Producer in one go.” Using this simple approach we were able to minimize Consumers’ idle time, reduce the load to the database when fetching attachments metadata, and maximize attachments upload speed.
Iterating migrations
After around nine months of development, in October 2018 we released the Confluence Migration Assistant for Confluence to the Atlassian Marketplace. It has since been downloaded nearly 30,000 times, helping more than 1,000 Confluence customers successfully migrate to Cloud.
Given that this wouldn’t be a real engineering blog without some statistics, here’s what we’ve seen since our release:
- To date, over 38,000 spaces have been successfully migrated to Cloud
- Spaces migrated using the plugin experience a success rate of ~90%. Whilst this obviously significantly outperforms site-level import (~10%), it also surpasses the rate for manual space migrations (~70%)
- The introduction of the plugin has seen a 400% increase in space migrations
- The support ticket resolution time for migration-related tickets has reduced significantly
Of course, this is all only just the beginning. At the time of writing, there’s still a lot of work to do; of the problems we explained in the beginning of this post, we are still actively working on issues caused by product divergence and bad data. That said, there are multiple streams of work currently underway to iterate on the existing solution. From there, we will continue to gather customer feedback and insights from support and iterate accordingly.
Now, you may be thinking, “That’s awesome for Confluence, but what about Jira?” We’re on it – we have teams dedicated to shipping the same experience for Jira.
To learn more about the Confluence plugin, you can check out the official Confluence Migration Assistant for Confluence documentation. If you are interested in learning more about the possibilities and benefits of moving from Server to Cloud, you can check out our migration documentation at https://www.atlassian.com/cloud-migration.
Thank you to Leonid Bogdanov for your massive contributions to this article!


