
Advancing modern teamwork
AI thinking and product news to unleash the potential of teams

Atlassian CEO on human-AI agent collaboration
Atlassian CEO and co-founder Mike Cannon-Brookes joins Bloomberg Intelligence senior software analyst Sunil Rajgopal to discuss how Atlassian is embedding AI across Jira, Confluence and service-management tools through its Rovo platform and Teamwork Graph.


How customers are using Confluence Agents to turn knowledge into action
Latest by topic

Atlassian Team ’26: Meet the AI-Native Organization
We’re seeing a new kind of organization emerge: the AI‑native organization, where teams are co‑creating alongside agents.

Introducing Product Collection: Built for better decisions, in the AI era
Shipping used to be the hard part. For years, product organizations optimized for speed. Agile transformations, DevOps, and CI/CD removed friction from delivery. Teams got faster, more efficient, and more predictable. Then AI changed the equation. Today, prototypes can be built in hours. Workflows that once took weeks now take days. The barrier to building […]

Atlassian Teamwork Graph: The context engine behind your AI—everywhere
Connections. Insights. Workflows. All mapped, all in context.
Rovo makes AI-native teamwork real for the enterprise
Team up with agents that have the full story behind your work so they can search, reason, and act on what matters most
Subscribe for more
Inside Atlassian
Get the latest research and insights on AI, teamwork, and more.

Built for the Next Era of Teamwork: What’s New in Teamwork Collection
We’ve all been there – toggling between six tabs, copying content from one tool into another, and wondering if anyone actually read the brief. The promise of AI was supposed to fix this. Instead, most teams got a chatbot bolted onto the side of their screen. We think AI should work the way a great […]

Elena Verna on AI growth: Automate the basics, elevate the creative
The former growth leader at Dropbox, Miro, and Amplitude on using AI to automate the basics — so humans can focus on the creative work

Four warning signs your AI and collaboration investments aren’t paying off
Learn to transition from fragmented tools to a connected system of work that makes AI actually work for IT teams.

AI’s speed paradox: why faster individuals don’t mean faster organizations
AI has accelerated execution, but misalignment is quietly eroding shared outcomes. Here’s what leaders can do next.

AI isn’t a productivity hack. It’s a team sport
Four moves leaders can take now to foster time, trust, and clean data so AI can drive results across your team

When doing more with AI isn’t enough: Three patterns quietly undermining your team’s impact
The AI productivity paradox is real. Here’s how to turn AI busywork into real impact.

From pilots to productivity: How one AI leader operationalizes enterprise AI
AI may be helping individual employees work faster, but most organizations still struggle to turn individual wins into enterprise-wide execution gains. The gap between isolated

How executives can bridge the strategy-execution gap for tech-driven organizations
Learn how C-levels can remove chaos and drive clarity by building a truly connected enterprise and optimizing their approach to AI.

How to handle team conflict as a first-time manager
Three scenarios specific to new managers, plus what to do when all else fails.

75 inspirational leadership quotes you haven’t heard yet
For something to inspire and support your work, take a look at these quotes from true leaders.

Your employees might not feel like they matter. These are the subtle signs
As humans, the only way to survive and thrive is through our relationships with other people. That means mattering to others is a survival instinct,

How to avoid “manager crash” in 2025 and beyond
Meaningful steps organizations can take to support wellbeing, bolster resilience, and set the stage for leaders to thrive.

How to delegate when you’re wired to do the work
Getting input from your team about their capacity, strengths, and preferences makes it easier to loosen your grip.

Toxic positivity at work: how to spot it and squash it
Though well-intended, extreme optimism can hurt more than it helps. Here’s how you can trade false reassurance for true resilience.

All brains on deck: 10 best practices for knowledge-sharing
One person’s knowledge isn’t enough to execute the work that really matters. Even your team can’t go it alone. To make great things happen, your

How hands-on workshops boost teamwide AI confidence
When teams learn by doing, AI stops feeling abstract and starts driving real behavior change, from higher usage to stronger everyday skills.

Better together: 8 essential teamwork skills to master
Use these strategies to align expectations, streamline communication, and crush your goals.
How to implement goal refresh cycles on your team
Five steps to shift from annual goal setting to a quarterly refresh rhythm for better results.

How to harness the power of professional development goals
Feeling stuck? Professional development goals might be the remedy you need.

Announcing the 2026 Atlassian Impact Maker Award Winners
Live from Team ’26 in Anaheim | May 6, 2026

Introducing new AIOps integrations with Lansweeper, Coralogix, and Honeycomb
Accelerate incident resolution with unified asset, log, and trace intelligence
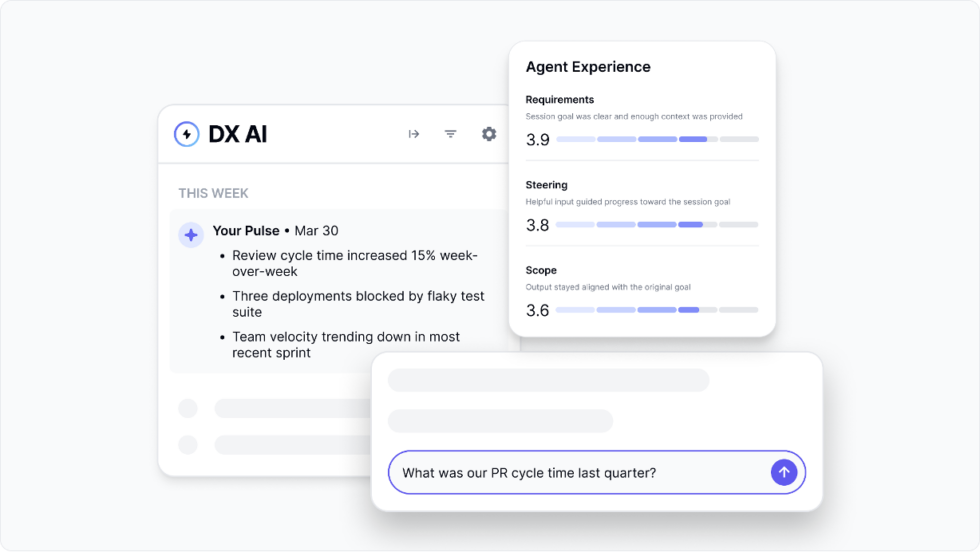
Building for AI‑native engineering: What’s new in DX
AI is changing how engineering teams work faster than most organizations can adapt. Coding assistants are now part of the daily workflow, agents are starting
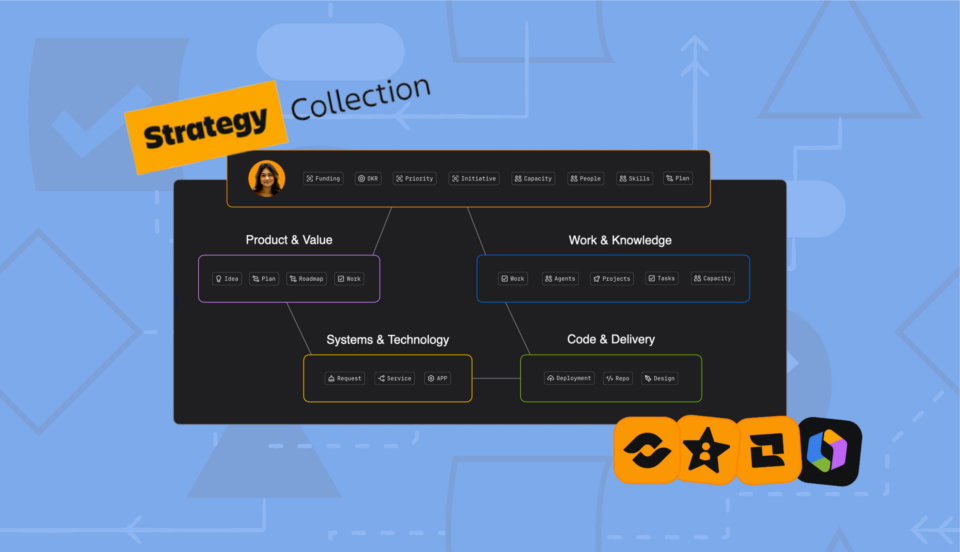
Strategy Collection your executive command center: From insight to action
Turn your strategic vision into measurable reality
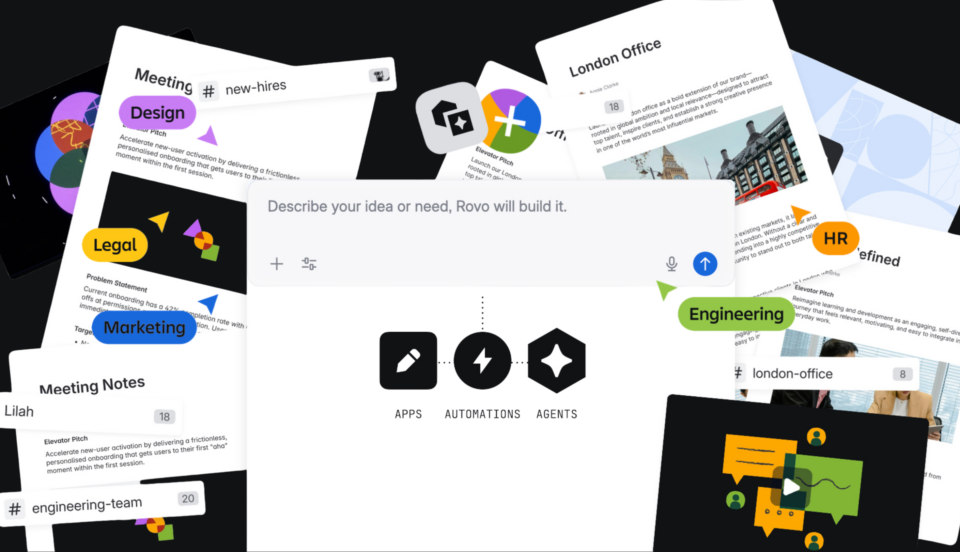
The new, unified Rovo Studio – more to build, easier than ever
Every team knows exactly where AI could help — the onboarding that takes three weeks of manual coordination, the customer feedback no one has time

It’s time to shatter the service quo
The future of AI-native service and operations is here

Agent Context Pruning: How Rovo Dev keeps long sessions useful
AI agents become more useful as they work through longer tasks. But longer tasks also create a memory problem. A serious coding agent accumulates a

MCP Compression: Preventing tool bloat in AI agents
Model Context Protocol (MCP) has made it dramatically easier to connect LLM agents to real tools. The trade-off is that every MCP server tends to

Delivering 120 PRs in two weeks with Rovo Dev in Jira
I’ve had a pretty good experience with our Rovo Dev in Jira solution in the past few weeks. I estimate that I do probably 95%

Using Rovo Dev in VS Code for Architecting Solutions
When we intend to roll out a new software solution that would impact multiple teams, before implementation can start, we need to get overall alignment

Rovo Dev CLI Ralph Wiggums Loop for Large Scale Test Refactoring
How Rovo Dev CLI optimized overnight 160+ files containing hundreds of tests, speeding up our Bitbucket pipelines

From Days to Hours: Accelerated K8s Debugging with Rovo Dev CLI
The Problem We Faced It started with a blocked Jira ticket when two of our service teams tried to onboard their services onto our Google

Engineering the Forge Billing Platform for Reliability and Scale
Introduction Forge is Atlassian’s cloud app development platform. It’s a serverless, Atlassian-hosted environment that allows developers to extend products like Jira and Confluence, and it

Creating with Rovo: How We Built a Collaborative AI Canvas
Learn how Rovo’s collaborative AI canvas was engineered—unifying streaming, structure, and agent-powered workflows to build smarter content creation features.

Advancing semantic search for millions of Rovo users
Rovo brings meaning‑aware search, chat, and agents to Jira, Confluence, and your connected tools, so teams can quickly find the right artifacts and move forward

How Rovo helps teams start work 30% faster
After a year of our users leveraging Rovo’s AI capabilities within Jira, we analysed usage data to identify if and how users’ productivity had been

Building a more resilient, multi-region Bitbucket Cloud
2025 was an impactful year for Bitbucket Cloud. As we enter 2026, Bitbucket will be continuing this momentum by making architectural improvements aimed at two

How we catch and mitigate performance regressions at scale in Jira Cloud
In a huge, multi-tenant product like Jira Cloud, a “small” change anywhere in the system can quietly make life harder for some of our biggest

See our newest AI research

The State of Teams 2026
See how the top 14% of teams use AI differently to deliver results faster, together

New grads are 1.5x more likely to use AI daily. Here’s why that matters for your hiring strategy.
Companies are cutting new grad hiring to save money. Atlassian research suggests they’re actually cutting their fastest path to AI adoption.
Watch, listen, and learn

How to Build an AI Native Team with Mike Cannon-Brookes
Atlassian’s Co-founder and CEO Mike Cannon-Brookes appears on The AI Daily Brief podcast to discuss what separates enterprise AI leaders from laggards, why context is becoming a critical layer of AI adoption, how agents and MCPs are changing the way people work with software, and why 2026 may be the year AI moves beyond chat […]

AI Teammate Play
Realize the full potential of AI teammates by building your first agent, specifically tailored to meet your unique needs and workflows.

How Mercedes-Benz delivers software 10x faster with Atlassian
Mercedes-Benz invented the automobile. Now they’re reinventing it — with software, AI, and Atlassian. With 50,000+ employees collaborating on Atlassian Cloud Enterprise, Mercedes-Benz has transformed from a traditional automaker into a high-performing software organization delivering software-defined vehicles at scale.

Best practices for writing AI prompts
Prompt engineering is essential for anyone looking to use AI tools, and, like any skill, it takes practice to master.
Explore more





Driving AI adoption through trust: Insights from Atlassian designer Rachel Shepard



Subscribe to unleash the potential of your team
Inside Atlassian
Research and insights on how teams can deliver with AI.