Bitbucket’s usage is growing
Two services at the core of Bitbucket are gu-bb and gu-api, responsible for serving the Bitbucket website and our public REST API. These services are built on the Django web framework, serving millions of requests every hour. On average, each of these requests represents over 10 database queries, putting significant load on our database. Our database architecture is one of the areas we are trying to improve to help Bitbucket scale.
A stressed primary database
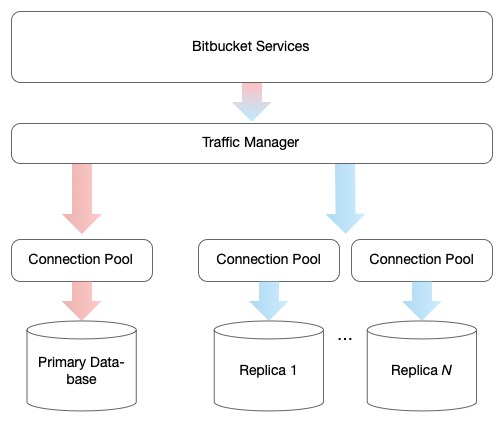
Bitbucket uses PostgreSQL with one primary read-write database and N read-only replicas. This is a good foundation to build on.

However, traffic from gu-bb and gu-api is routed almost entirely to the primary database (developers have the ability to force the use of replicas in their code paths, but this is rarely used and not a scalable solution). This routing is done at the service level, reducing the benefit of replicas to failover scenarios. The primary database is protected from this load by connection pooling, but performance degrades during peak hours as clients wait for a connection from the pool.
Moving 80 percent of the load to replicas
To improve scalability and performance, we are experimenting with an approach to using our replicas more.
When a user is in Bitbucket, she is making requests to gu-bb and gu-api. From a database point of view, each of these requests is a sequence of read/write operations. Our goal is to route all reads in a request to a replica until a write happens. A write, and anything afterward in that request, will go to the primary. This is to avoid a race condition where a user might fail to see data they’ve just written.
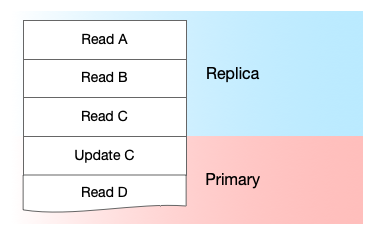
Doing this for all requests should take the majority of the load off our primary database. Analyzing our production traffic showed us that 80 percent of the traffic from the primary database can be moved to replicas.
Choosing the right replica
Replication from the primary to replicas is quite fast, but it’s not instantaneous. This means that if we start using replicas, we could run into issues with stale data as a result of replication lag. The race condition we mentioned earlier within a single request could happen during multiple requests. Imagine creating a pull request, then going to the pull request list page and not seeing what you just created, because we chose a replica that didn’t have that data yet. We must be careful to choose a replica that is up to date, at least from the point of view of the user making the request.
Postgres has a write-ahead log (WAL), and entries in this log have a log sequence number (LSN). When a user performs a write operation, it’s recorded in the WAL and we can save the LSN.
How we find the current user LSN:
def _current_db_lsn(cls):
...
cursor.execute(
'SELECT '
' CASE '
' WHEN pg_is_in_recovery() '
' THEN pg_last_xlog_replay_location() :: VARCHAR'
' ELSE pg_current_xlog_location() :: VARCHAR'
' END')
return cursor.fetchone()[0]When the same user makes a subsequent request, we find a replica that is as up to date as the user’s saved LSN and use that for read operations.
How we evaluate a replica with a saved user LSN:
def caught_up(self, replica, user_lsn, lsn_manager):
"""Check to see if given replica is up to date or promoted to
master."""
query = dedent("""
SELECT NOT pg_is_in_recovery()
OR pg_xlog_location_diff(
pg_last_xlog_replay_location(),
'%s') >= 0
AS result
""" % user_lsn)
try:
with timeout(
settings.DATABASE_LSN_QUERY_TIMEOUT_SEC, ReplicaTimeoutError):
cursor = connections[replica].cursor()
cursor.execute(query)
return cursor.fetchone()[0]
except ...This approach is executed at the routing level, so we send most of the read operations, across all requests, to replicas instead of the primary. There’s no extra work for developers, and existing and new code will automatically benefit from this.
Django’s middleware allows us to save LSNs at the end of a user request and look them up at the beginning of a user request. We chose Redis as our LSN store. We store the LSNs keyed by the user’s Atlassian ID, so routing is on a per user basis.
We originally shared an existing Redis cluster in our datacenter with other services. The configuration of that cluster and our load/needs soon pushed us out to Elasticache, an Amazon-hosted Redis cluster. Even though LSNs don’t use much storage, we update them frequently, and sharding helps us spread this write load. We use a proxy called envoy to pool connections from our services to this cluster.
Along with LSNs, we also store a blacklist of replicas. This allows us to catch any operational errors with a particular replica and blacklist it for a configurable time, routing around it to others.
Tradeoffs
The extra logic we’ve introduced to route to a replica isn’t free. We have to query Elasticache and replicas, which add latency. Our tolerable margin for this was roughly 10ms. If we can shift the majority of the load from the primary database while avoiding race conditions, we considered this worth the additional small latency.
The other tradeoff was the introduction of dependencies like envoy and Elasticache. These add additional operational overhead, but we felt this was worthwhile to help Bitbucket scale.
Results
We did indeed shift the majority of traffic to replicas while keeping added latency close to 10ms. Below is a snapshot of requests, grouped by the database that was used for reads, before our new router was introduced. As you can see, most of the requests (the small squares) are using the primary database.
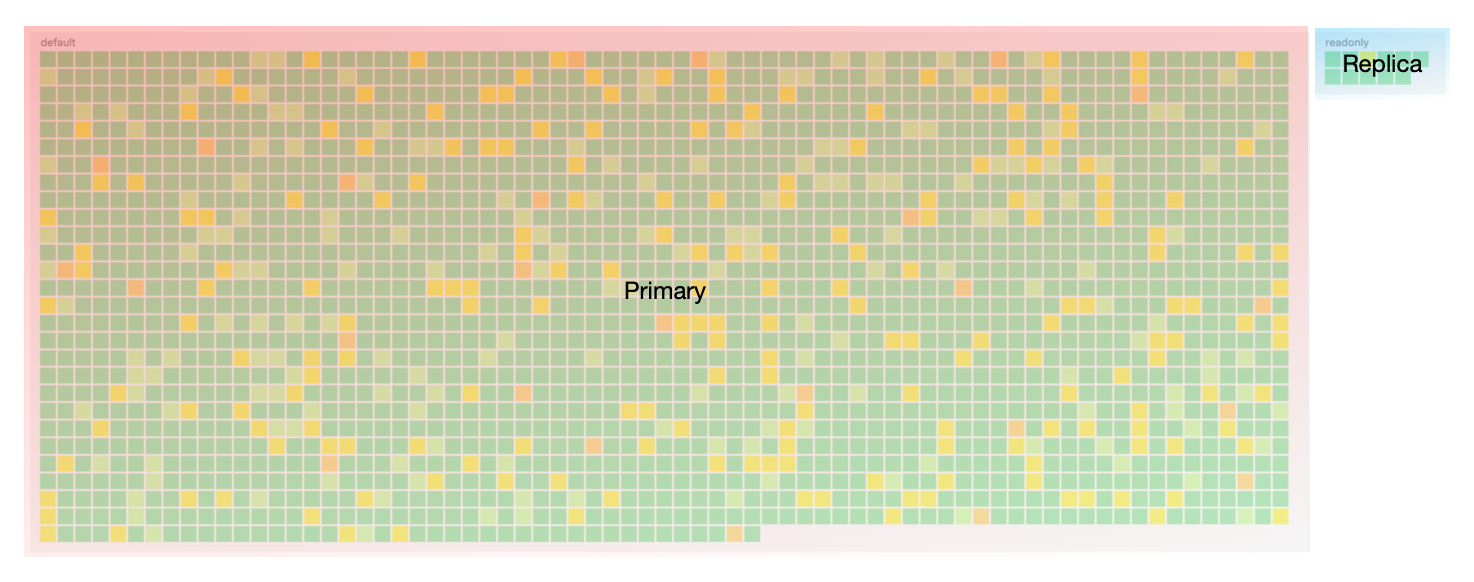
This is a snapshot of requests once we rolled out the new router.

You can see the load being spread more to the replicas.
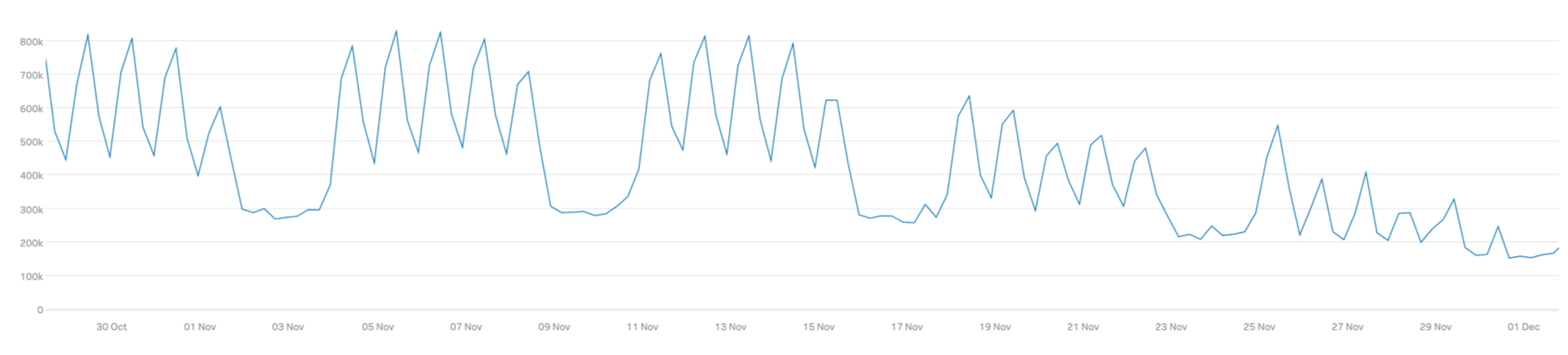
Looking at the primary database on a typically busy Wednesday, we can see a reduction in rows fetched too, from over 800,000 to 400,000.
Future work
We mentioned earlier that Django’s middleware allows us to look up LSNs at the beginning of a request. The middleware that does this is used primarily for authentication. Once we authenticate a user, we use their Atlassian ID to look up LSNs. Bitbucket supports a number of different auth methods and even anonymous users – we haven’t covered all of them yet. So, some traffic to gu-bb and gu-api isn’t benefiting from this new routing.
There are other services that use the primary database but don’t use LSN-based routing. We can predict the effectiveness and add this new router to those additional services.
Once we address the above, we can get as close to a stress-free primary database as possible.