

As engineers, we face a difficult challenge: balancing rapid delivery of customer-facing features with development speed improvements such as tech debt reduction. We want to continually deliver value to customers, but we can’t achieve this without regular maintenance to keep our systems up and running, and improving our ability to build new features. At Atlassian, we see evolutionary architecture as a means to achieve this balance successfully, i.e. explicit incremental milestones combining both customer and engineering value. What does this actually mean in terms of design patterns, deciding what/when/how to decompose, and keeping teams motivated for an arduous but rewarding journey?
The backdrop: rebuilding Atlassian Cloud’s Identity Platform
Our story focuses on the Identity Platform – the heart of authentication, user management, and product authorization for Atlassian Cloud. Over the last few years, we’ve been rolling out a number of significant features, such as:
- Single account for users across Atlassian – one set of credentials and profile
- Balance between personal and admin controls over profiles and content
- Enterprise authentication methods and provisioning (SAML, SCIM)
- OAuth for APIs
- Privacy controls for GDPR compliance
At the same time we’ve had to evolve our architecture, moving out of Atlassian data centres into AWS and from single to multi-tenanted in order to cost effectively scale and improve our dev velocity. We still continue to face the tough balancing act, but we believe we’ve been pretty successful at it over the last few years (and continue to improve), in most part due to four main learnings presented below.
Master builders working together towards a master plan architecture
The Identity Platform started as a single monolith and one team, evolving rapidly into several teams and distinct components. In order to build a cohesive platform as we expanded, architects and product managers worked closely together on a “master plan” for the platform, taking into account future features we may need to support 18-24 months out. Our goal was to ensure a common vision among current and future teams. As teams built new features, they could also see where the features should reside architecturally, and make necessary architectural decisions to keep technical debt at bay.
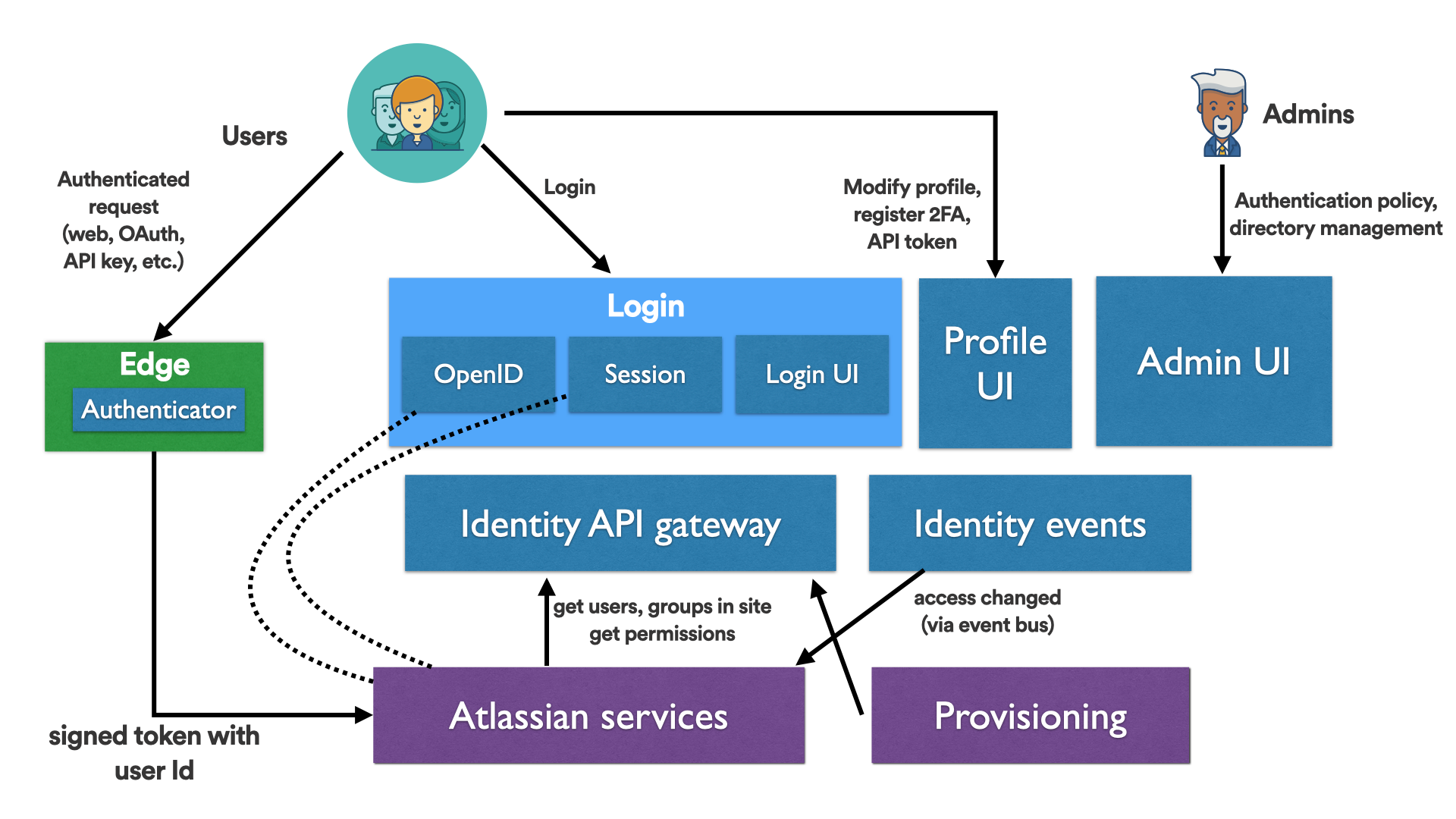
There were three parts to our master plan. Firstly, we clearly defined the domain of the Identity Platform. We identified key functional areas that we considered part of the platform: authentication (user and system), directories (users and groups), and authorization (e.g., who has access to Jira, extending in the future to support more granular in-product and cross-product authorization rules). We also realized we had to serve three independent consumers: end users, administrators configuring Atlassian software, and Atlassian product teams, each with their own potentially conflicting requirements. In particular, we would only target consumers of Atlassian products, and not internal Atlassian engineers. With a clear boundary defined, we could identify functionality to jettison, giving us bandwidth to focus on new areas that needed attention. For example, historically the Identity team owned all users and groups, even replication and management of that data inside Jira and Confluence. This took a lot of coordination effort, as any change required agreement with Jira and Confluence, since we were effectively modifying their codebases. Instead, we defined event and REST APIs with Jira and Confluence, owning user and group functionality in their code. This helped Identity think more like a platform (discussed next) while also allowing engineers to focus on new features we sorely needed.
Secondly, we created guiding principles that we wanted to enforce at all costs in order to enable the platform to have a multiplier effect for products. Some examples are:
- Features should only be built into the platform if it would benefit more than one product. This avoids the ongoing complexity of handling product-specific edge cases, which was commonplace in the past. It has also led to more flexible features that can support newer products in the Atlassian suite. A simple example is we built our single login and signup experience to be easily tailored, such as for Trello, which has a different design language than our other products.
- Identity exposes only a limited set of APIs fronted by an API gateway to support only what products need. There was one set of API docs and a small set of concepts that product engineers need to understand about Identity. This simplified integration between Identity and other teams and gave Identity full flexibility to take care of all the complexity of authentication, directories, and authorization.
- Identity’s goal is to handle all standard forms of request authentication (web session cookies, OAuth, API tokens, etc.) for Atlassian Cloud. Internet-facing services that go through an Atlassian “edge” can simply handle a signed token with the request principal, leaving the complexity of how the request was authenticated to Identity’s “Edge Authenticator.” Identity is able to add new authentication methods in one place for all products to benefit, and provides standard libraries such as for mobile app authentication for any Atlassian product team.
- Use existing industry standards where possible and strive for consistency in our interfaces. Rather than spend time building our own standards and having consumers learn them, we chose to use SCIM and OpenID v2 internally as part of our API. This was helpful initially to focus effort on functionality we needed to build, rather than spending time defining things like field names. We did find that it is important to choose appropriate industry standards that are sufficiently simple and well-defined. For example, we have moved away from SCIM to a custom standard, as it was overly complicated for what we needed, and moved from OpenID v2 to OpenID Connect in alignment with the industry.
- Design for scale and resilience to support Atlassian’s “Big Hairy Audacious Goals.” As a platform, we need to support higher levels of scale and operational maturity much earlier than our consuming services. Not only did we make architecture and technology choices to enable simple horizontal scalability (e.g. stateless services and DynamoDB where possible), but we also spent time ensuring we could expand to multi-active region operation where required (and now have done so for some services) such as through careful data model design for simpler and correct replication. We have also used techniques such as event sourcing that enable us to replay data to recover from outages or bugs.
Thirdly, we developed a high-level architecture showing existing services and services we should build later. Identity teams could see where their services would fit within the whole platform, and the interfaces they needed to consider. We also presented a time-based view in alignment with rough ‘release versions’ of the platform developed with product managers. This simplified the picture and also allowed long-term planning by teams.

Understanding the master plan through EventStorming
Developing a master plan was just the first step. Next, we had to ensure there was shared understanding across all teams of what the plan was so that they could make necessary decisions independently while moving in the same direction. We found EventStorming to be an effective tool to encourage teams to understand flows throughout the system. EventStorming is worth a blog series on its own, but as a short summary, it’s an interactive activity where small groups map out flows through the system, including user experience (business process), data, API calls, and interactions with external systems. The act of working through these flows helped teams:
- identify interfaces that are not immediately obvious from a high-level diagram
- highlight questions and significant decisions to be made
- build empathy for consumers of the platform. Seeing an end user request going through a series of services emphasizes the importance of network and service latency!
One of the challenges of EventStorming sessions was balancing how things happen now versus how things should be working (i.e., for new features or with architectural improvements). Working in cross-functional and experience-level groups helps by allowing sparring during discussions.
With the master plan in place, teams could incrementally make architectural improvements based on the plan as they built out new features on their roadmaps.
From plans to instructions with smart decomposition
When teams decide to work on an item on their roadmap, they are able to work out phases to achieve the target architecture and decide how much evolution they’re willing to take on in an immediate project based on effort and risk appetite.
One example of this approach was a program of work to move our main single-tenanted Identity monolith, called User Management (UM), from our data center to AWS (note: this was the first of our single-tenant to multi-tenant re-architectures). In the end state, we wanted a decomposed set of multi-tenanted services for faster development, and we had two choices to get there:
- “Lift and shift,” where we make minimal code changes and try just to deploy UM in AWS, an assumption being that less change would minimize immediate risk and be faster. Decomposition would be treated as a separate project. However, there remained a risk that UM would need significant change just to work in its new environment. It also meant the team would continue to be hindered in future development velocity until decomposition happened. This is the approach that Jira and Confluence took as part of their migration to AWS.
- Decompose fully, where we try to rebuild the features in UM “right.” While this gets us to an ideal end state sooner with the promise of better development velocity, there would be a significant risk in getting it done in time and maintaining correctness.
We ended up with a combined approach to balance risk, necessity, and ability to accelerate future development. To start with, we identified all the functionality in User Management, and sequenced the decomposition based on the following criteria:
- Do we even need it? We took the opportunity to ignore functions that were no longer useful, and also abstractions that no longer made sense.
- Vertical slices – Finding distinct functionality with minimal overlap so that the decomposition could happen in parallel and independently. For example, user and group management is distinct from user session management. We also favored avoiding refactoring tightly coupled code at this point to reduce risk, and to focus on migrating to AWS rather than solely decomposition.
- Horizontal slices – Within a vertical slice, we could then move business logic out separately from the domain logic. In our case, we moved user and group management business logic to AWS first, talking to the domain logic in legacy UM with its databases still in our data centers. Domain model migration to AWS was then treated as a separate phase. We chose this approach as code migration is simpler than data migration, and it enabled us to reduce the scope and complexity of moving the data.
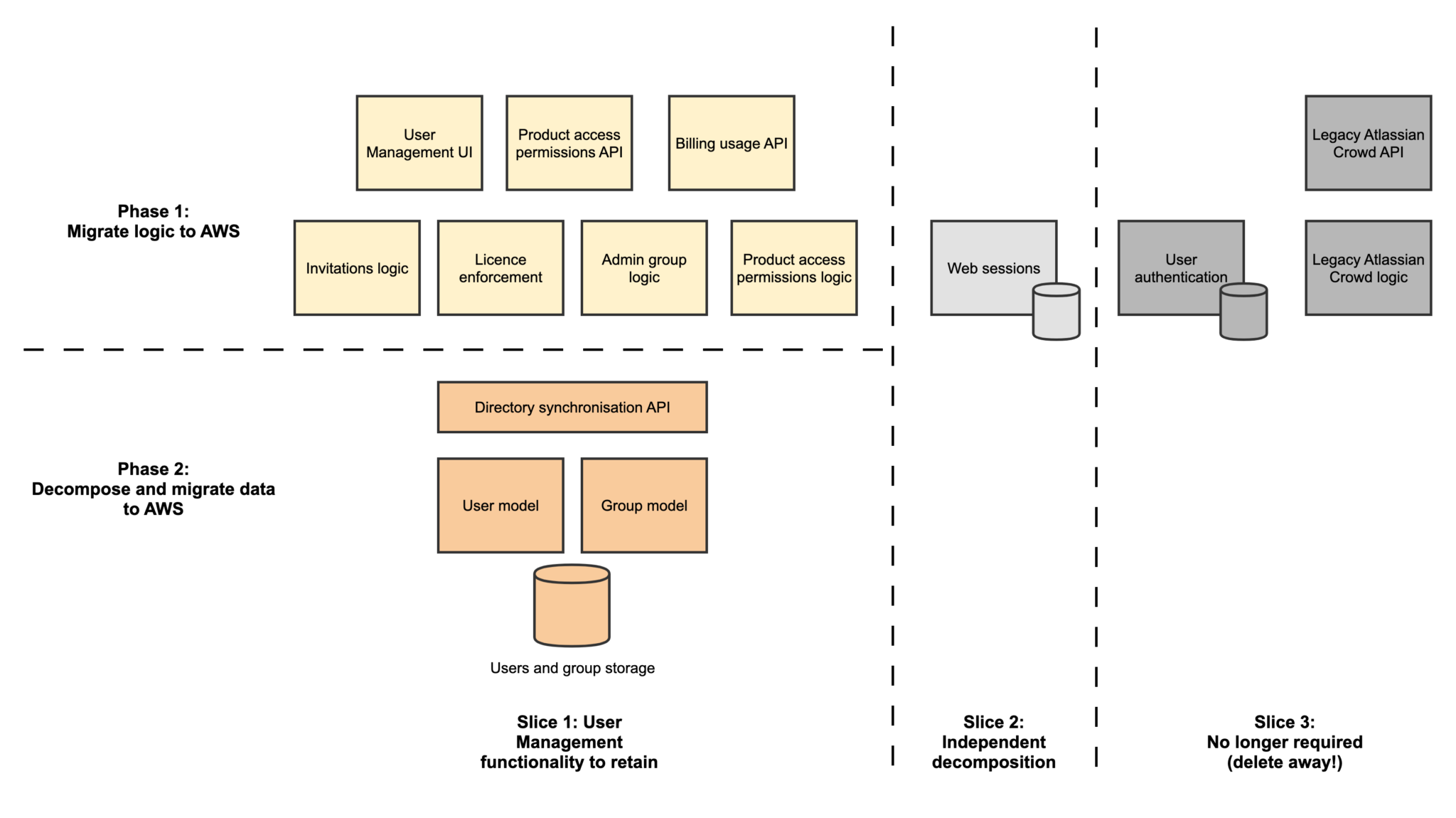
In our case, we reduced the risk of decomposition by taking it only as far as necessary, and leveraged the benefits of decomposition:
- Enabling multiple teams to work on decomposition in parallel to fit into necessary project timelines.
- Flexibility to use different data models and data stores for distinct functions that have different operating characteristics, e.g., user sessions have a much higher transaction rate than group membership changes.
- Enabling out-of-the-box thinking to simplify the overall architecture by changing (or in some cases introducing) our API contracts.
Don’t run out of blocks…finish your migrations!
When building new features, it is very tempting to release it and do most but not all of the migration work before most engineers move onto the next project. After all, the business value has been achieved, so why spend the extra effort? This potentially results in migrations taking a long time to complete (or even running indefinitely), and multiple parallel migrations may need to occur. Not only does this increase the risk of conflicts between migrations, but it also leads to increasing architectural complexity and technical debt dealing with old edge cases. There are also a dwindling number of engineers working on new features, as some are left behind to finish each migration.
The Identity team faced this problem while releasing Atlassian accounts (single unified profile and sign-in across all of Atlassian properties such as Jira, Confluence, and Bitbucket). This migration was ongoing when Project Vertigo was initiated to move all of Atlassian, not just Identity, out from our data centers into AWS. Both migrations had significant risk and complexity, and we could not pause either without poor and inconsistent user experience and more technical debt to clean up. We managed to complete both migrations successfully in parallel, but it is not something we would recommend!
One of the reasons the Atlassian account migration was long-running was that we took an opt-in migration approach, where users elected to migrate to a unified account experience upon their next login. This provided better user experience and enabled the team to develop features as required based on incoming feedback. In our case, moving to the unified account model meant taking away control over user accounts from administrators and giving it to end users, and we used the (very vocal) feedback to find a better balance between the two groups.
Our main lesson learned is to plan for migrations to occur as fast as possible. The faster a migration is, the less likely it will be interrupted. When we plan for migrations now, consider there are roughly three phases:
- Interactive opt-in: User is empowered to start the migration process at a time that is suitable. This could be done via dogfooding (i.e., using new features ourselves), a beta program, or prompting users via emails or banners. This gives the best user experience and allows the capturing of early feedback from customers.
- Interactive forced: Users are forced to migrate but can elect to make decisions. For example, as part of account migration, a user can choose to change some settings.
- Non-interactive forced: An automated process pushes all data into the new system using default choices.
For each phase of migration, it is important to determine up front what suitable cohorts of users are in order to allow carefully staged migration. Cohorts may be based on customer size, feature sets they currently use, etc. We learned it is important to tackle a mix of both simple and complex cases early. The simple cohorts provide quick wins to build momentum and can help smooth out the migration process. The complex cohorts typically require significant effort to support, be it features that need to be built out during the migration process, and leaving it too late could jeopardize timely completion of the project. While building features for the complex cohorts, we were able to migrate the simpler ones.
Don’t underestimate the complexities of non-interactive forced migrations. While it might seem to be “just a script” to run, consider:
- Suitable notifications need to be given to users and customers prior to migration. This may be in the form of emails, but also in documentation and banners throughout products. There may also be legal considerations, such as changes to privacy policies or terms of service.
- User experience for those being force-migrated, e.g., during account migration, the next time they try to log in, they are now seeing a login screen that is unfamiliar. This may result in user confusion, frustration, and support requests. This should be factored into designs, and support engineers should be prepared.
- There’s likely to be unexpected data cleanliness issues that cannot be handled programmatically. Pre-flight checks in migration logic and/or safe rollback are a must before performing any non-recoverable changes. Non-conforming data can be marked for manual handling by an engineer, contacting a user directly if required.
- Planning for zero-downtime migration. During interactive migrations, we may be able to pause operations with a wizard UI. However, in non-interactive forced migration, there is no UI to present, so customers may interrupt an in-progress “stop-the-world” migration. We used several techniques while developing the Identity Platform, including:
- Background incremental copying of data and “optimistic locking” for switchover, i.e., during switchover both new and old systems potentially can perform writes, but for relatively low-frequency writes, conflict is not likely to occur. We perform data validation across both systems before and after switchover. When there is a difference, corrections can be made, or in the worst case, highlighted to users. This is an imperfect but relatively cheap solution compared to alternatives such as coordinating dual writing/reading of data between old and new systems or buffering writes.
- Simply not migrating data that expires, and focus on creating data in the new systems. Web sessions are a good example of this.
Rules of engagement for building together – non-negotiable features
Beyond the guiding principles in the master plan, we (engineering and product management) agreed upon non-negotiable non-functional features to be maintained or built as part of any projects for new functional features. These included:
- Ensuring secure service-to-service authentication. This led to the development of ASAP.
- Request tracing through services to enable easier debugging across decomposed microservices.
- Consistent logging, monitoring, and alerting between services.
- No end user performance degradation. More on this below.
Considering these features early limited the amount of retrofitting required, and also focused efforts onto important end user-facing issues. Maintaining and improving platform performance was a good example: how can we maintain performance when moving away from local storage and a monolithic application to a microservice architecture inevitably introduces latencies? The answer was to focus on performance measured from an end user perspective rather than any service-level metric like latency to the database. For a given user feature, we measure latency as observed in the browser (at various points around the world in production), and give a decimal Apdex score based on bands we have defined based on whether the experience is acceptable, tolerated, or unacceptable to users.
To ensure no end user performance degradation, we set up performance test infrastructure run as part of our build and deploy process (initially using an internal performance tool, now using Locust-based tooling). On master builds (and in some cases on branch builds), a standard set of performance tests are run measuring Apdex in our test environment (results scaled to correspond with expected production performance). Master build results are presented on team dashboards. It is also possible to apply git-ratchet to test results to ensure performance does not degrade (and in fact improves) over time.
While adding constraints may make engineering problems more difficult, it also meant we could identify and remove unnecessary constraints from legacy thinking. For example, to improve performance across a network of services, we decided we no longer needed to stick with legacy chatty APIs, but move to APIs that could batch up data more effectively or support incremental push-based replication of data. We could also move away from thinking about a single relational database serving everything to using command-query responsibility segregation (CQRS) to build high-performance query nodes to specific use cases.
Summary
Code, like Lego blocks, can be manipulated to build amazing creations, but also terribly hard-to-extend beasts without care. Having a well-understood master plan with guiding principles and non-negotiables for architecture decisions empowers teams to deliver features that product managers want, while incrementally building extensible architecture to serve themselves well into the future. Our ongoing challenge is ensuring principles and plans are kept up to date, and continue to be shared with new teams and team members as we expand. We have had success with the experiences presented here, and hopefully it’ll help you and your team too.


