
Continuous deployment guides frequently focus on the culture and adoption aspects. What’s less common to see is how teams have addressed practical nuts-and-bolts issues.
In this post, I’ll talk about the hurdles my team had to jump while transitioning to continuous deployment: workflow stuff, tools stuff, and a bunch of “gotchas”. And for those of you looking to convince a reluctant boss, I’ll describe how continuous deployment has benefited our team – spoiler alert: all the effort was worthwhile.
(I also presented this info at an Atlassian User Group in London – slides available here.)
What is continuous integration vs. continuous delivery vs. continuous deployment?
Before we dive in, let’s define what we mean by continuous integration, continuous delivery, and continuous deployment. The terms are often used interchangeably, but they have different meanings which is kind of important for purposes of this post.

Continuous integration
Continuous integration (CI) is the process of automatically building and testing your software on a regular basis. How regularly this occurs varies. In the early days of agile, this meant daily builds, But with the rise of tools like Bamboo, this can be as often as every commit. In the business systems team we builds and runs a full suite of unit and integration tests against every commit. (And because most commits happen on dev branches, we take advantage of Bamboo’s branch builds feature.)
Continuous delivery
Continuous delivery (CD) is the logical next step from continuous integration. If your tests are run constantly, and you trust your tests to provide a guarantee of quality, then it becomes possible to release your software at any point in time. Note that continuous delivery does not always entail actually delivering as your customers may not need or want constant updates. Instead, it represents a philosophy and a commitment to ensuring that your code is always in a release-ready state.
If a guide to continuous delivery is really what you were looking for, head to The Pipeline – a guide to continuous delivery using Jira, Bitbucket, and Bamboo.
Continuous deployment
The ultimate culmination of this process is continuous deployment (CD): the actual delivery of features and fixes to the customer as soon as the updates are ready. Continuous deployment is usually practiced in the SaaS world, as hosted services are easiest to silently update in the background. But some desktop software offers this in the form of optional beta and nightly updates such as Mozilla’s beta and aurora Firefox channels, for example.
In practice, there’s a continuous spectrum of options between these techniques, ranging from just running tests regularly, to a completely automated deployment pipeline from commit to customer. The constant theme through all of them, however, is a commitment to constant QA and testing, and a level of test coverage that imbues confidence in the readiness of your software for delivery.
How to do continuous deployment: workflow steps
Everything here should be treated as a starting point rather than a set of rules. My team iterates on this workflow as our needs change, and yours should too. Because process should serve your goals – not the other way around.
Continuous deployment implies a clear development process, with your main release branch always being in a releasable state. There are any number of methodologies that allow this and I won’t cover them all here, but if you want a deep dive into them I would recommend the book “Continuous Delivery” by Jez Humble and David Farley.
The model we follow is “release by feature”: every distinct change we wish to make results in a separate release, containing only that change. Here is our current workflow and the tools we’re using to enable it.
While we’re using Atlassian tools wherever possible (naturally), all of this can be done with other tools. Our tools do have some nice integrations that make CD a little easier, however, so I’ll point these out as we go along.
#1: Use an issue tracker for everything
For every development task – bug, feature request, whatever – we create a unique issue to track it. Long-running projects have an “epic” issue that all the discrete task issues link to. Obviously all this is best practice anyway, mostly because you can use each issue’s unique ID to track the change from concept to deployment. Having a single reference point makes it easier to track the state of work, and enables some of the tool integrations I’ll describe below. As you may have guessed, we use Jira for this purpose.
#2: Create a separate branch for this work, tagged with the issue number
In your version control system, create a branch which contains the issue number and a short description of the change – I’m on the Business Platform team, so our branches have names like “BIZPLAT-64951-remove-smtp-logging”.
It should go without saying at this point that you should be using a distributed version control system (DVCS) such as Git. Older version control systems like Subversion handle branching ok, but really make merging difficult (which effectively makes branching workflows a non-starter). Without the ability to separate work into streams, keeping the main branch releasable becomes untenable.
We use Git for version control, and Bitbucket to manage our repositories. Jira has a useful integration point here: from within the tracking issue we created in step 1 we can just press a button and Bitbucket will create a branch for us. Sourcetree also has the ability to pick up and checkout these new branches. Then Jira will query Bitbucket and list all branches associated with a given issue in the issue itself, along with number of commits to the branch. This turns Jira into a convenient dashboard for the state of your development.
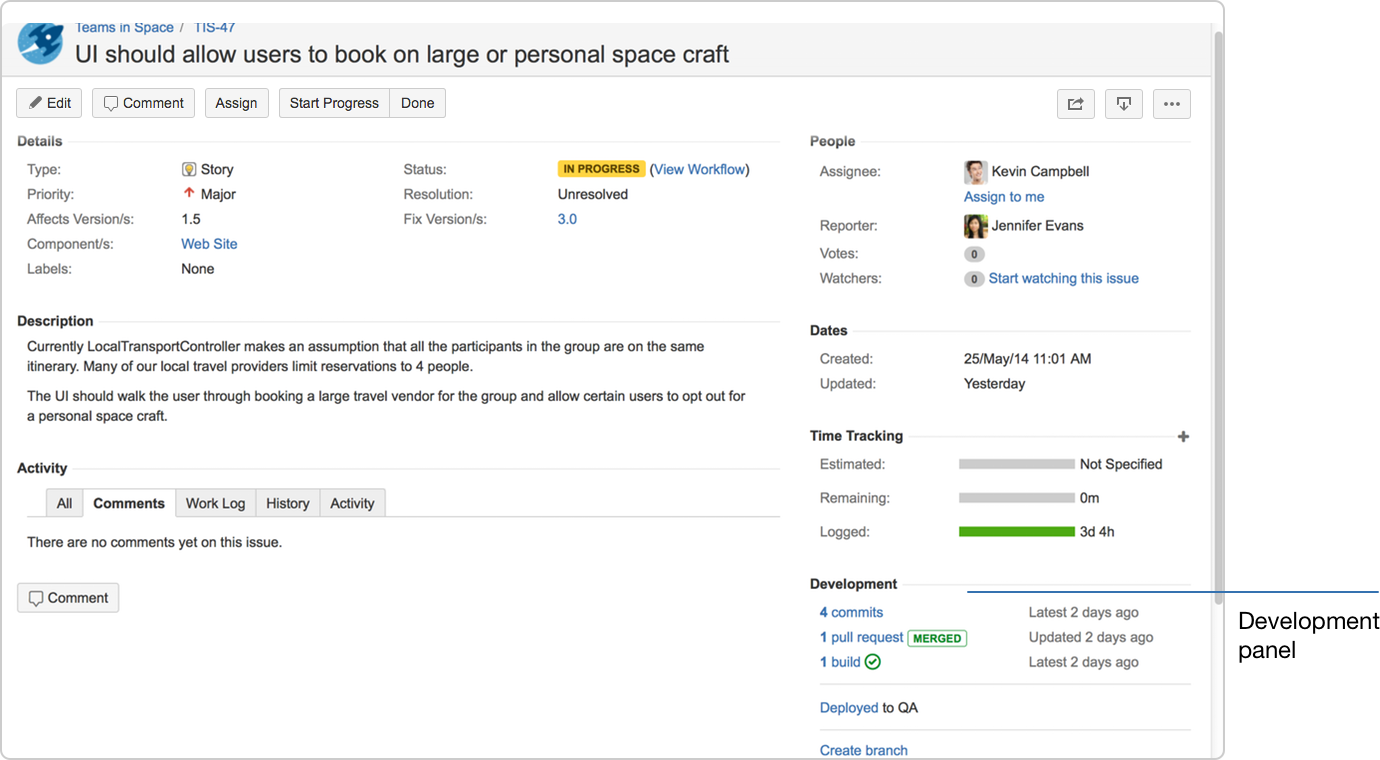
#3: Develop on your branch, including continuous integration
Git allows you to easily make many commits on a branch, and then only merge when ready. But that doesn’t mean you should skimp on continuous integration. We run our full integration test suite against every commit on all active branches. We use Bamboo to do this, taking advantage of its branch builds feature to automatically create the build configs for each branch.
Again, there are useful integration points here. One is that, as with the branches and commits, Jira can display the state of any branch plans associated with tickets, creating an at-a-glance view of the feature development. But a more powerful one (in my opinion) is that Bamboo can also inform Butbucket of the state of builds for a branch. The importance becomes evident when we come to pull requests, down in step #4…
#3a (optional): Push your changes to a rush box
Rush boxes are used as staging servers for ongoing work that is not yet ready for QA or staging. This step is particularly useful when you have a customer or internal stakeholder involved in the development of the feature. By pushing out work in progress to a viewable stage environment you give them visibility of changes and allow them to review. You can do this automatically using the same infrastructure and tooling you use to perform other deployments.
#4: When ready, create a pull request for the branch
Pull requests are the DVCS world’s version of code review. Inexperienced developers tend to dislike the idea, but many experienced developers love them, as they provide a safety net when working on critical code and infrastructure.
On our team we have a “no direct merge/commit to master” rule that we enforce through Bitbucket’s branch access controls. This means that all merges must come through a pull request. On top of this we define a couple of extra quality rules:
- All pull requests must have approval from at least one reviewer.
- The Bamboo tests for this branch must pass.
Both of these are enforced by Bitbucket. In particular, the second one is enforced by the Bamboo to Bitbucket pass/fail notification mentioned in step #3.
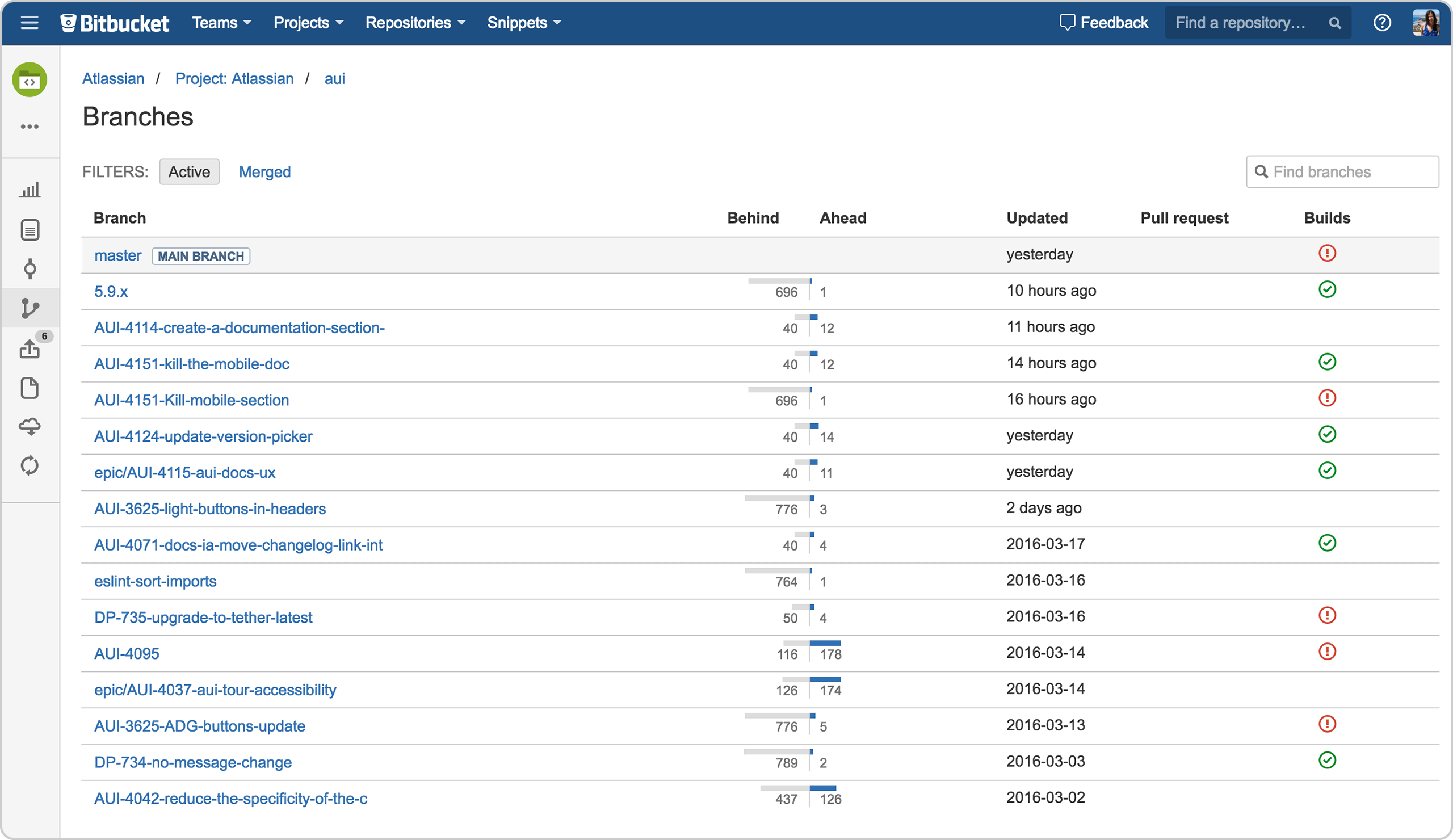
#5: Merge and package as a release
Once the pull request has passed, the merge to the release branch can be performed. At this point, we perform full release of the software. We use a separate dedicated Bamboo build plan for this, which first runs the full test suite before incrementing the version and pushing to our build repository.
#6: Deploy to staging
Because we’re talking about continuous deployment, this stage is also fully automated. (In a continuous delivery context, this step may be push-button instead of triggered automatically.) Building a released version of the software triggers an automatic deployment to our pre-production staging servers. This allows additional QA to be performed on it, and possible review by customers or other interested parties.
More on the actual nuts and bolts of how we perform these deployments is below in the Managing Deployments section.
#7: Promote to production
One of our rules is that we never push builds directly out to production. The binaries that go to production must first go through QA on our staging servers. Thus, we don’t so much “release” to production as “promote” once we’re happy with the quality. Again, the mechanics of this will be covered in more detail below, but suffice to say that we use Bamboo to manage which builds are deployed where, and Bamboo communicates this information back to Jira where it’s displayed inside the issue tracking that piece of work.
A deep-dive into managing deployments
So now you have your release being built and deployed to development, staging, QA, and production environments – but how do you know which versions of the software are deployed where? How do you arrange the promotion of QA and staging builds up to production? And how do you ensure only certain users can perform these promotions?
Tracking versions through environments
Early on, we used bastardized build plans to deploy versioned, packaged binaries. But when Bamboo added specific deployment capabilities, we replaced these with the new deployment environments.
These look a lot like standard build plans in that they’re composed of stages and tasks, but they support concepts necessary for effective deployments. In particular, they support the idea that a single build may be deployed to multiple locations (e.g., QA and staging), and then migrated onto other locations (e.g., production).
The UI shows you which versions are live on each environment. Or you can flip that and view things through the lens of the version: namely, which environments is this version running on right now?
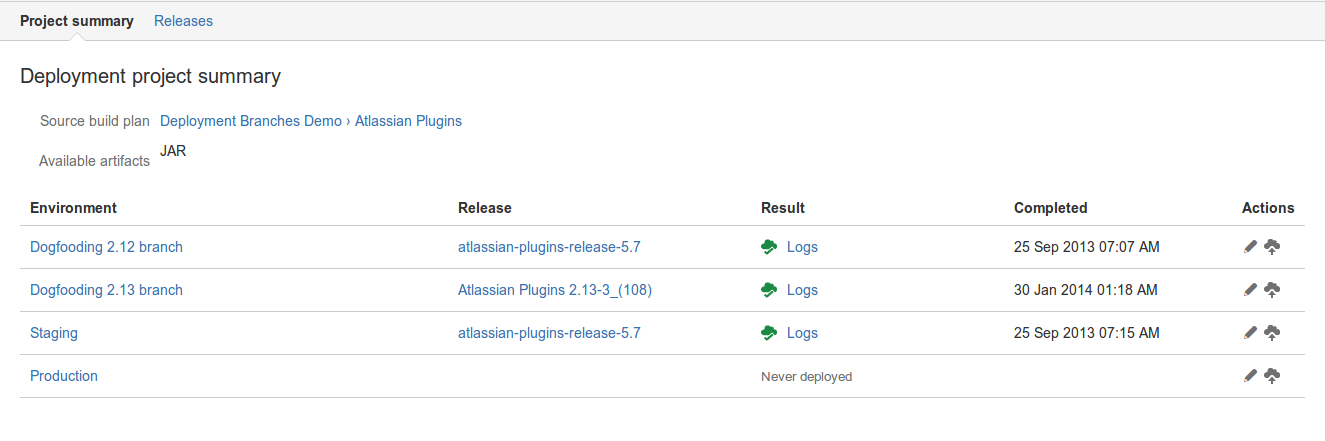
Like the other stages of the build pipeline, deployment environments have their own integration and feedback points. Notably, the original Jira issue can display which environments the code for that issue has been deployed to.
Going the last mile with Ansible and Bamboo
Something I seldom see addressed is how to actually get the software onto your servers. It’s assumed that if you’re doing continuous deployment, you already have the “deployment” part taken care of. But even if this is the case, your existing tools may not necessarily fit with a fully automated deployment pipeline – especially if you’ve historically been on a fixed-window schedule.
This is known as the ‘last mile’ problem, and it’s one of the hurdles we encountered on the Business Platform team.
We had a set of Python tools that had been in use for several years which performed upgrades on our hosts. However, they were not end-to-end automated, and had no concept of cross-host coordination. Rather than perform a rewrite of these scripts, we decided to look around for newer options.
In simple single-server cases, it’s possible to use your Bamboo (or Jenkins, etc.) agents themselves as the last mile system. By placing an agent on the target servers and binding that to that server’s deployment environment, you can script the deployment steps as agent tasks.
When consulting with your sysadmin team, the immediate temptation will probably be to use Puppet or Chef to perform the upgrades, as software configuration management. But these didn’t suit our team because they work on the model of eventual convergence – i.e., they’ll eventually get to the state that you desire, but not immediately. In a clustered system, however, you usually need events to happen in the correct order and be coordinated across hosts. For example:
- Take server A out of the balancer pool
- Upgrade A
- Check that A is operational
- Put A back into balancer pool
- Take B out of the balancer pool
- And so on…
This is difficult to do with configuration management tools (yes, even in 2017).
Luckily, a lot of work has been done in this area by the DevOps community over the last few years. Going into a full review of the options would make this already-too-long post even longer. Suffice to say that we trialled a few options and eventually settled on Ansible for automation. The deciding factor was that it has explicit support for a number of tools we already use including Hipchat and Nagios, and that it was explicitly designed to perform rolling upgrades across clusters of servers.
Ansible uses YAML playbooks to describe sequences of operations to perform across hosts. We maintain these in their own Git repository that we pull as a task in the deployment environment. In total, our deployment environment task list looks like:
- Download the build artifacts from Bamboo
- Fetch Ansible from our Git repo
- Fetch Ansible playbooks from Git
- Run the necessary playbook
That said, we do use Puppet for the base-line configuration of the hosts, including the filesystem permissions and SSH keys that Ansible uses. Personally, I’ve never understood the Puppet/Chef vs. Ansible/Salt/Rundeck dichotomy – I see them as entirely complementary. For example, I use Ansible to create clusters of AWS servers, place them in the DNS and behind load-balancers, and then bootstrap Puppet on the host to manage the OS-level configuration. Once that’s complete, Ansible is then used to manage the deployment and upgrade of the application-level software.
Preventing continuous downtime with clustering and failover

We went through this process, too. Earlier versions of the Business Platform team’s systems were running as a single instance, largely for historical reasons. Prior to moving to the new development model, we had been following a weekly release cycle, with the deployment happening on a Monday morning. This infrequency, along with the fact that the deployment happened during Australian business hours, meant that this didn’t affect most customers unduly.
Not that we were proud of this downtime, mind you. But it was never so painful for us that we wanted to invest in turning it into a clustered system. But the move to continuous deployment meant we had to address this deficiency, splitting out the stateful parts of the order system (such as batch-processing) and clustering the critical parts.
When clustering systems, it’s important to select components for your network stack that will work with your deployment automation tools. For example, our original HA (high-availability) stack used Apache with mod_proxy_balancer. While this can theoretically be automated via HTTP calls to the management front-end, it was never built with this in mind and proved unreliable in practice. In the end, we moved our critical services behind a HAProxy cluster, which provides a reliable (albeit Unix-socket based) API for managing cluster members.
A note about continuous deployment tools
In case you’re not taking notes on the side, the tools my team uses for our continuous deployment workflow include:
- Jira Software for issue tracking
- Git for version control
- Bitbucket for repository management
- Bamboo for build, test, and deploy automation
- Ansible for cross-host coordination
- Nagios for monitoring
While I’ve pointed out a number of places where Atlassian products integrate together, our “open company, no bullshit” value compels me to point out that these integration points are available to other tools, as well.
The interoperability is enabled by REST APIs that are documented online, so it’s perfectly possible enable these features with a little work, possibly via curl. For example, if you’re using Bitbucket for Git management and Jenkins for CI, you can still enable the build status integration mentioned in step #3 by calling out to Bitbucket’s build status API.
Procedural considerations
There are some additional management-flavored questions to take into account. What these are will depend a lot on your organization. For us, the big issues were around security and separation of duties.
Deployment security

However, the company is growing and we went public in late 2015. And regulatory bodies tend to have a less trusting attitude toward such things. In particular, the software we produce modifies the company financials, and so must have strict access controls associated with it.
Although we investigated methods of remaining open-but-secure, in the end we decided that we should err on the side of safety. We identified all systems subject to Sarbanes-Oxley (SOX) compliance, and placed them into a dedicated build environment separated from the more liberal policies of the master Bamboo server.
Separation of duties
Historically, the Business Platform team has been quite self-sufficient. In some ways, we were doing DevOps before the idea came to wider recognition. However, SOX contains some strict rules about separation of duties. In particular, the implementers of a software change are subject to oversight and cannot themselves sign off on the deployment to production.
Our solution to this was to hand off the production deployments to our team of business analysts. The analysts are almost always involved in the triage and specification of software changes, and are therefore in a good position to judge the readiness of features. to be deployed. And the use of automated deployment, in particular Bamboo’s deployment environments, makes this role available to them rather than just sysadmins.
In practice, we use the the deployment environment permission system to restrict production deployments to specific group of users within Bamboo. We can then add and remove members as required.
So, why should you do continuous deployment?
As you can see, there’s a metric tonne of considerations around continuous deployment and a lot of work required up front. When bringing up the subject adoption, there will inevitably (and rightly!) be questions about what the benefits are. For my team, the main drivers were:
- Moving to feature-driven releases rather than a weekly “whatever happens to be ready” release. This is allows faster and finer-grained upgrades, and assists debugging and regression detection by only changing one thing at a time.
- The weekly release process was only semi-automated. While we have build tools such as Maven to perform the steps, the actual process of cutting a new release was driven by developers, following instructions on a Confluence page. By automating every step of the process, we make it self-documenting and repeatable.
- Similarly, the actual process of getting the software onto our servers was only semi-automated. We had detailed scripts to upgrade servers, but running these required coordination with the sysadmin team (who had quite enough work already, thanks). By making the deployment to the servers fully automated and driven by Bamboo rather than by humans, we created a repeatable deployment process and freed the sysadmins of busywork.
- By automating the release and deployment process, we can constantly release ongoing work to staging and QA servers, giving visibility of the state of development.

- Customers: By releasing features when they’re ready rather than waiting for a fixed upgrade window, customers will get them faster. By releasing constantly to a staging server while developing them, internal customers have visibility of the changes and can be part of the development process.
- Management: When we release more often, managers will see the result of work sooner and progress will be visible.
- Developers: This removes the weekly/monthly/whatever mad dash to get changes into the release window. If a developer needs a few more hours to make sure a feature is fully working, then the feature will go out a few hours later, not when the next release window opens.
- Sysadmins: Not only will sysadmins not have to perform the releases themselves, but the change to small, discrete feature releases will allow easier detection of what changes affected the system adversely.
The last point should probably be expanded upon, as it is such a powerful concept. If your release process bundles multiple features together, it becomes much harder to nail down exactly what caused regressions in the system.
Consider the following scenario… On a Monday, a release is performed with the changes that were made the previous week. Shortly afterwards, however, the sysadmin team notices a large increase in load on the database server. While triaging the issue they notice the following changes were included:
- Developer A added a new AJAX endpoint for the order process.
- Developer B added a column to a table in the database.
- Developer C upgraded the version of the database driver in the application.
Identifying which one is the cause would require investigation, possibly to the point of reverting changes or running git bisect. However, if each change is released separately, the start of the performance regression can be easily correlated with the release of each feature, especially if your release process tags each release in your monitoring system.
Continuous deployment means continuously improving
Continuous deployment as a practice is so broad, a single blog post can’t do it justice. Each team’s recipe for continuous deployment will vary based on their existing tech stack, customers’ needs, and team culture. (For that matter, the same is true of continuous integration and continuous delivery.) The important thing is to start somewhere and keep iterating. Continuous improvement for the win!
Although I’ve only scratched the surface here, I hope this post has answered some of the questions your team is facing around continuous deployment. I’ll leave you with a few bits of further reading that dive into greater detail on various facets of the practice.
- 5 tips for CI-friendly Git repos
- Git hooks for CI
- Feature branching your way to greatness
- Getting Git Right (a collection of free Git tutorials)
If you’re interested in (or already using) Atlassian tools, check out The Pipeline: a guide to continuous delivery with Jira, Bitbucket, and Bamboo