
In April 2022, Atlassian experienced an outage and published our post-incident review (PIR) detailing what happened, our response, and what we are doing to prevent future incidents from occurring.
We outlined four immediate areas of investment:
- Establish universal “soft deletes” across all systems. Overall, a deletion of this type should be prohibited or have multiple layers of protections to avoid errors, including staged rollout and tested rollback plan for “soft deletes”. We will strengthen our controls and enhance safeguards around delete operations.
- Accelerate our Disaster Recovery (DR) program to automate restoration for the multi-site, multi-product deletion events for a larger set of customers. We will leverage the automation and learnings from this incident to accelerate the DR program to meet the recovery time objective (RTO) as defined in our policy for this scale of incident. We will regularly run DR exercises that involve restoring all products for a large set of sites.
- Revise incident management process for large-scale incidents. We will improve our standard operating procedure for large-scale incidents and practice it with simulations of this scale of incident. We will update our training and tooling to handle the large number of teams working in parallel.
- Create large-scale incident communications playbook. We will acknowledge incidents early, through multiple channels. We will release public communications on incidents within hours. To better reach impacted customers, we will improve the backup of key contacts and retrofit support tooling to enable customers without a valid URL or Atlassian ID to make direct contact with our technical support team.
Since the PIR, we’ve continued to broaden our learnings and have successfully made strides across all four key areas.
Our progress
1. Establish universal soft deletes across all systems
Strengthened internal controls and enhanced safeguards around delete operations
Our engineering teams have thoroughly reviewed major delete operations in our systems and developed designs for delayed deletions and soft deletions of sites and products. We have already begun implementing these controls and will continue to enhance our internal safeguards.
We also reduced the number of services that can make these types of deletions. Now, only systems that require deletion for business operations such as our customer support systems are permitted.
2. Accelerate our Disaster Recovery (DR) program to automate restoration for the multi-site, multi-product deletion events for a larger set of customers.
Improved Disaster Recovery (DR) targets and simulated exercises planned quarterly
In order to continue meeting our recovery point objective (RPO) standards and to also meet the recovery time objective (RTO) standards in our policy, we accelerated multi-product, multi-site restorations for a larger set of customers. We also committed to more frequent Disaster Recovery (DR) exercises at scale – these will not affect any production customer sites.
Our first DR site deletion exercise is planned for the last quarter of 2022. These exercises will continue to run quarterly, each increasing in scale. In the first exercise, the team will run a simulated multi-site, multi-product deletion event that matches the scale of the April incident. By running DR exercises, we will optimize our recovery plans to help ensure our RPO and RTO are consistently reaching their respective targets
As we redefine and increase our DR standards, we are working towards a consistent, repeatable, and scaleable set of restoration processes and tools.
3. Revise incident management process for large-scale incidents
Improved incident management process for large-scale events
In April, we provided an overview of our large-scale incident management process (Figure 1) and evaluated its operations, escalation architecture, and tooling.
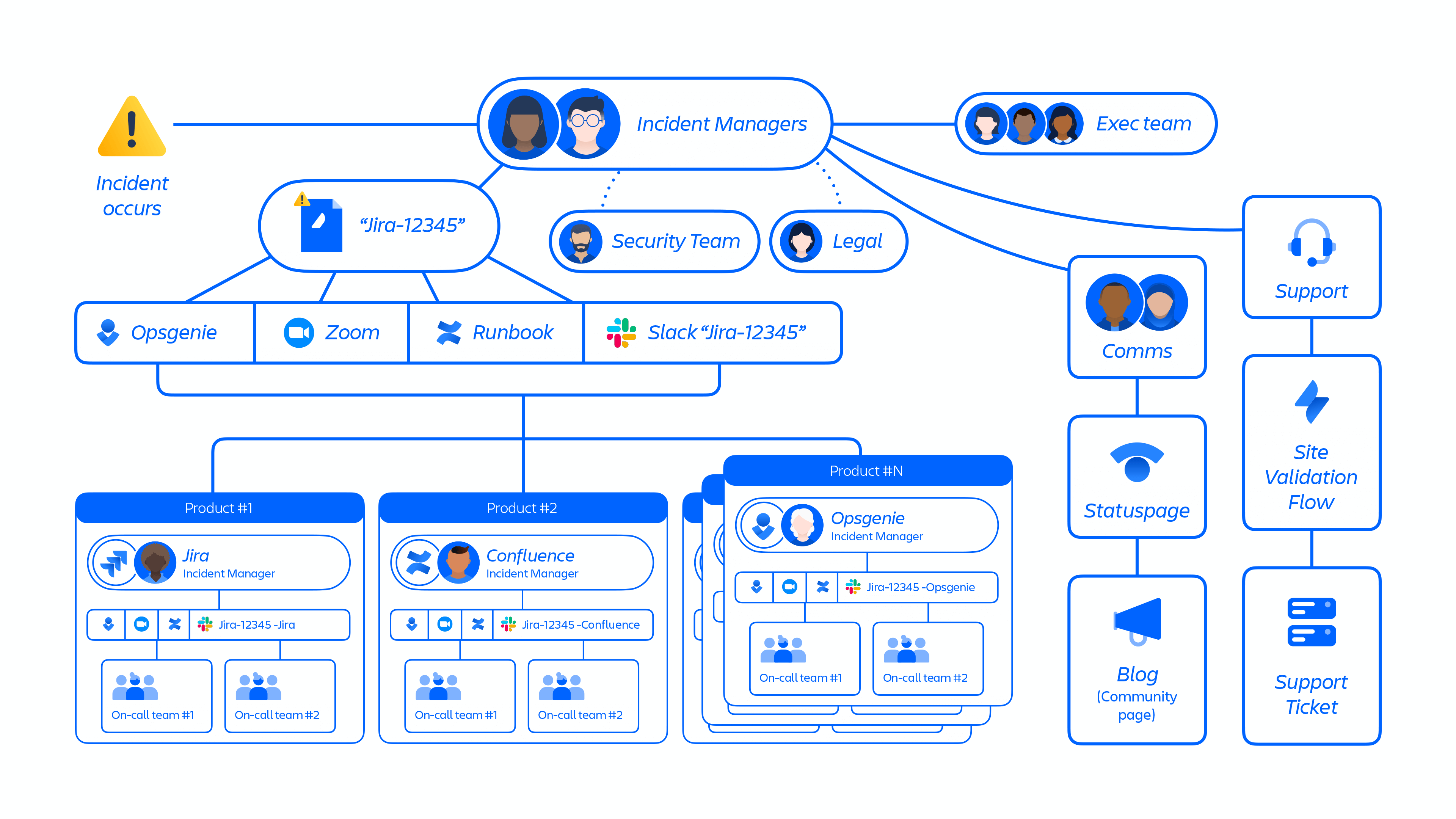
During the last few months, we enhanced the internal tooling we use for Incident Management such as Slack, Opsgenie, and Confluence documentation, improving our coordination across escalation systems for high-complexity events.
We are in the processing of creating a large-scale incident management playbook that brings together elements from our Crisis Management framework and Incident Management process.
Resolved high and medium-priority actions identified from architecture reviews
During our analysis of the incident management escalation architecture, we identified actions that we grouped into different priority tiers. We resolved 100% of the high-priority actions and 85% of the medium-priority actions with the remaining 15% planned to close in the next few months.
4. Create large-scale incident communications playbook.
Implemented internal key customer contact backups
During the April incident, we failed to provide timely communications due to the loss of key contact information during site deletions. To fix this, we now have a recovery process in place for accessing key customer contacts in the event of temporary data loss or deletion. This strengthened our ability to respond quickly and across global systems, and will help prevent the same mistake from reoccurring.
We will continue to improve our communication processes by scaling our escalation management coverage to 24/7, in addition to bringing more improvements to our support tooling and incident communications playbook.
What’s next
First and foremost, thank you for your trust and partnership. We will continue to show our commitment to our values and our customers with regular updates of our ongoing improvements.


