
It’s a given that customers expect software and IT services to be high-performing and always on. And, because incidents and downtime will always be a thing, we believe that how you respond can make or break the customer experience. We’ve learned this lesson first hand while refining our own incident management process over the last decade.
When an incident occurs, our first instinct is often to move past the discomfort as quickly as possible. The pain of an incident can be brutal, but the opportunity to learn from it is invaluable. Reflecting on what went wrong and what was successful builds trust between team members and customers. And the best way to learn from every incident is to capture all of the details using an incident postmortem – a formal process in which teams take a step back from the chaos of an incident and review every detail to better understand what went wrong and how to improve in the future. When compiling an incident postmortem, it’s important to focus on the details of the incident; a high-level report will miss key information, making the process less effective.
There are several categories of information that should be included in your postmortem, including dates and time frame, services affected, fault, impact, detection, and response (for a complete list, check out our incident postmortem templates). Of all these categories, fault is likely the most controversial. Though any worthwhile incident postmortem depends on teammates coming together to discuss errors, bugs, and mistakes, this can quickly turn into a blame game if you’re not careful. This is why the most effective incident postmortems are blameless.
In a blameless postmortem, it’s assumed that every team involved in the incident response acted with the best of intentions at the time, based on the information that was available. Rather than pointing fingers and trying to find a scapegoat for the incident, blameless postmortems focus on improving performance.
Organizations should provide an easy way for the entire company – including executives – to read a structured report about the incident and detailed plans for process improvement. Doing so will help executives understand the context of the incident and align all teams to drive process improvements across the organization.
Opsgenie customers can now easily share their incident postmortem reports with everyone in their organization by exporting each report to their Confluence Cloud accounts. This feature is available for Opsgenie accounts that were set up from the Atlassian site admin panel, and access for all other customers will be added soon.
Export Incident Postmortem to Confluence
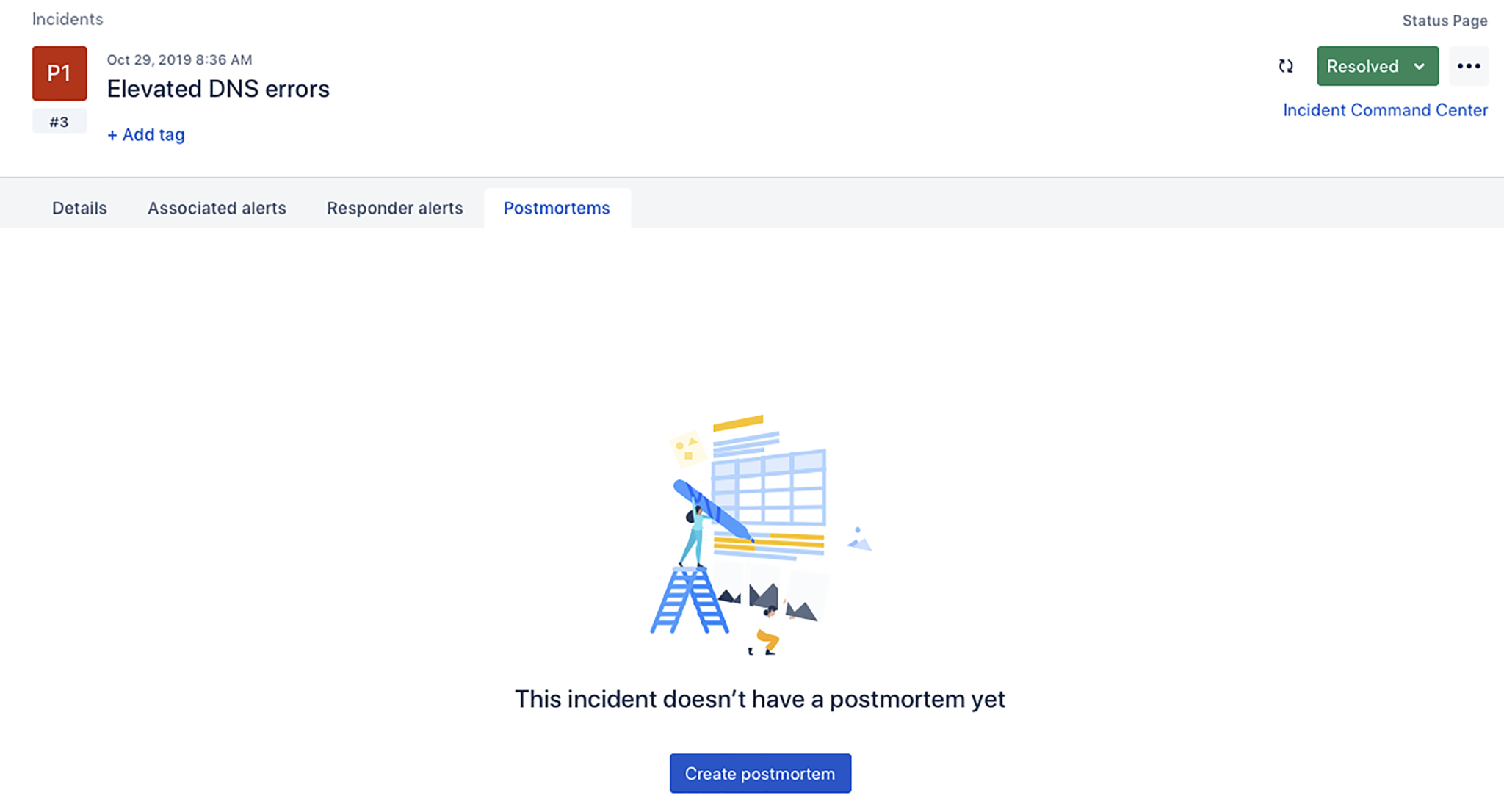
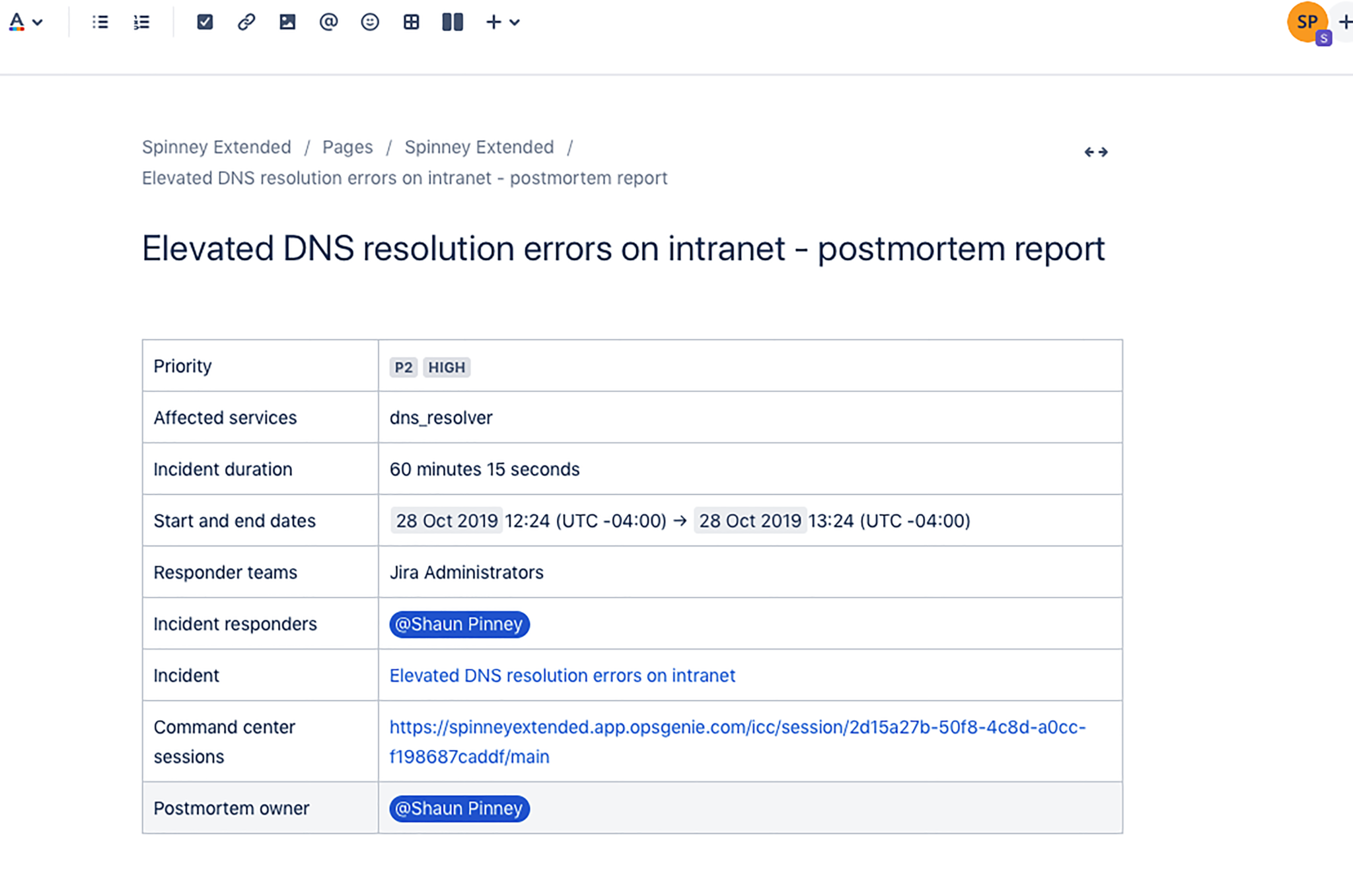
Once an incident has been marked as resolved in Opsgenie, you’ll be prompted to create an incident postmortem.
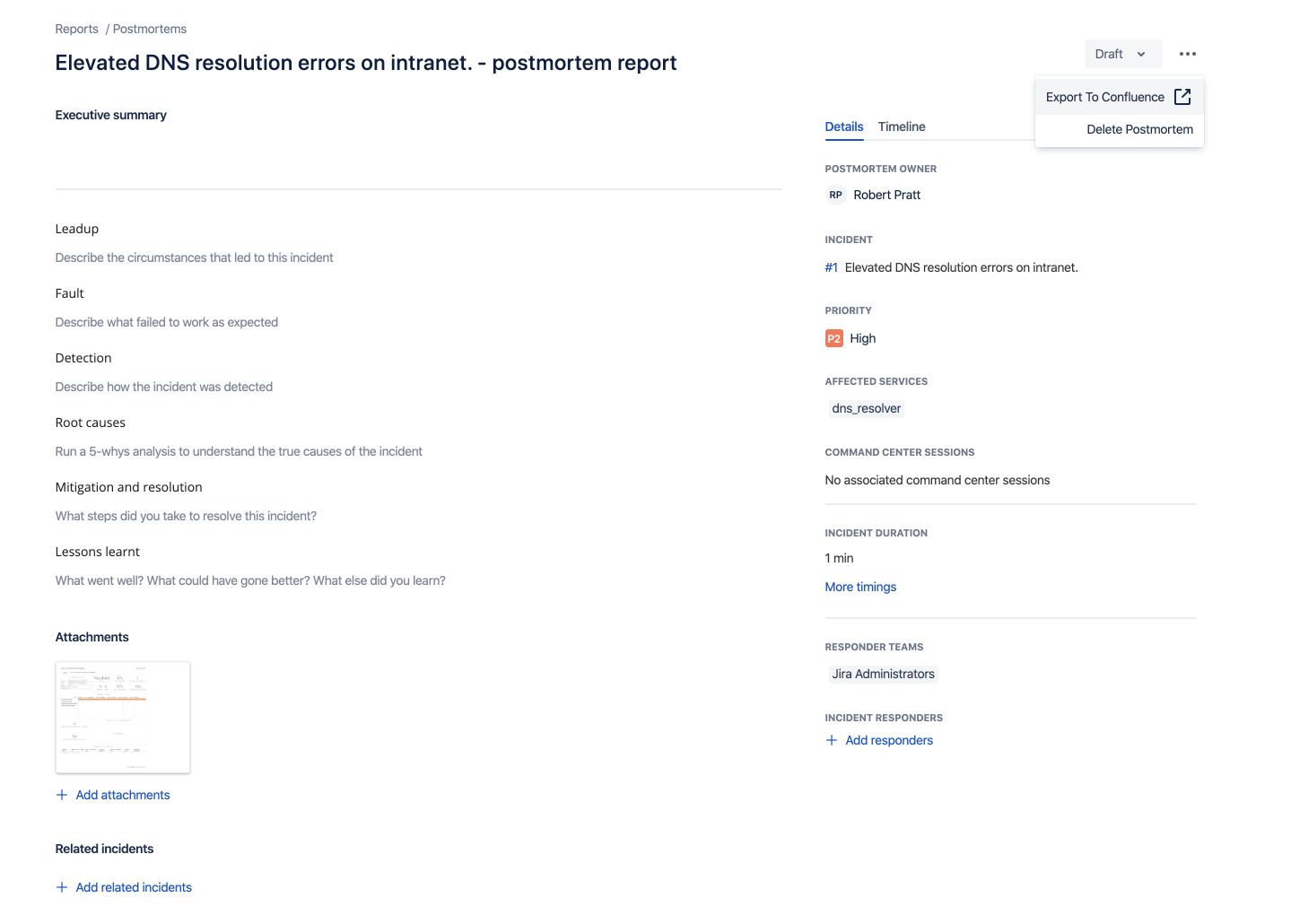
Add in the details of the incident, link related tickets from Jira or Jira Service Desk, and select “Export to Confluence” from the drop-down in the top right portion of the screen.
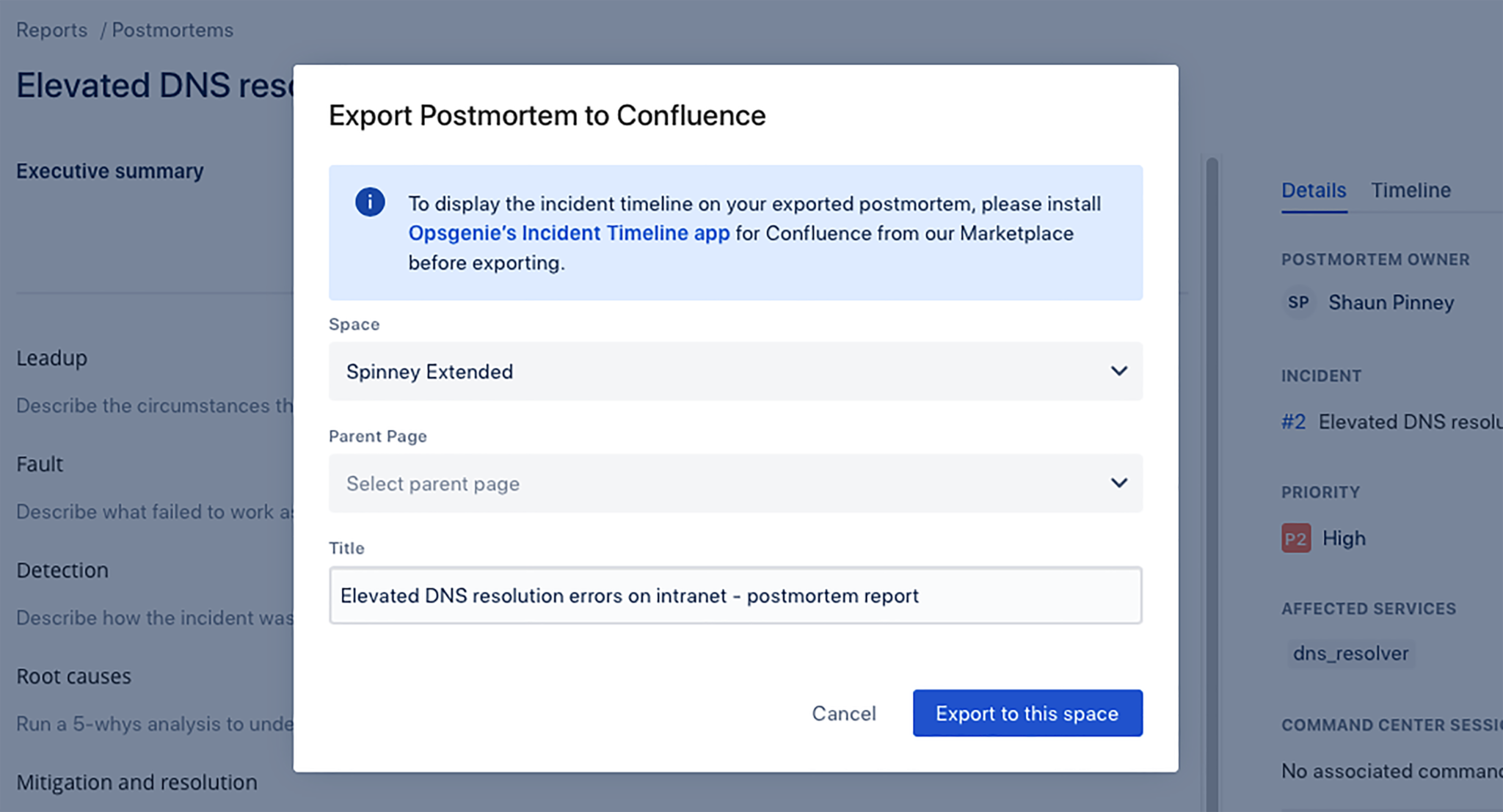
Next, you’ll be prompted to select the Confluence account with which you’d like to sync the incident postmortem. Click “Export to this space.”
All the details of your incident postmortem from Opsgenie are now displayed in your Confluence account.
To display the incident timeline on your exported postmortem, install Opsgenie’s Incident Timeline app for Confluence from the Atlassian Marketplace before you export.

If you have feedback or best practices to share, we’d love to see you in the Community.



