

Today, we’re all laser-focused on delivering world-class service, resolving issues faster, and building lasting trust within the organization.
But things break – that’s just a fact. We need to think a lot about how to handle them when they do. So we follow our Incident Management process to restore service quickly and our Post-Incident Review (PIR) Process to learn from failure and become more resilient.
That said, life is unpredictable, and incidents especially so. A process is necessary but can’t (and shouldn’t try to) cover all possible situations. It’s best when your people are also allowed to decide and execute a course of action.
How do you do this? Hire great people, empower them to make decisions, and give them guidance in the form of values.
Such values result in building better systems, which we iterate over time. More automation, more self-service, more effective outcomes, and ultimately, happier customers are the end goal. How can we become better connected to information? How can we build new solutions for every kind of problem, no matter how big or small? These are the questions we consider as we work to solve incidents that occur.
This is the new shape of IT. It varies for each team because each team must be empowered to create it for themselves.
Early Atlassians recognized this and created the Atlassian Values to support the decisions we make daily. (We even have them printed on banners in our offices. It’s serious business.) The Atlassian values have proven to be continually useful in guiding our decision-making. We follow the same pattern for incidents and post-incident reviews, and in doing so, we’re part of the movement that’s reshaping IT. We believe others could benefit from this model, as well.
So in that spirit, we set out to create a specific set of values for Incident Management. Our goals here are to:
- Guide autonomous decision-making by people and teams in incident and PIR situations;
- Facilitate a consistent culture between teams regarding how we identify, manage, and learn from incidents;
- Align teams’ attitude for each part of incident identification, resolution, and reflection.
Thus, without further ado…
The Atlassian Incident Values
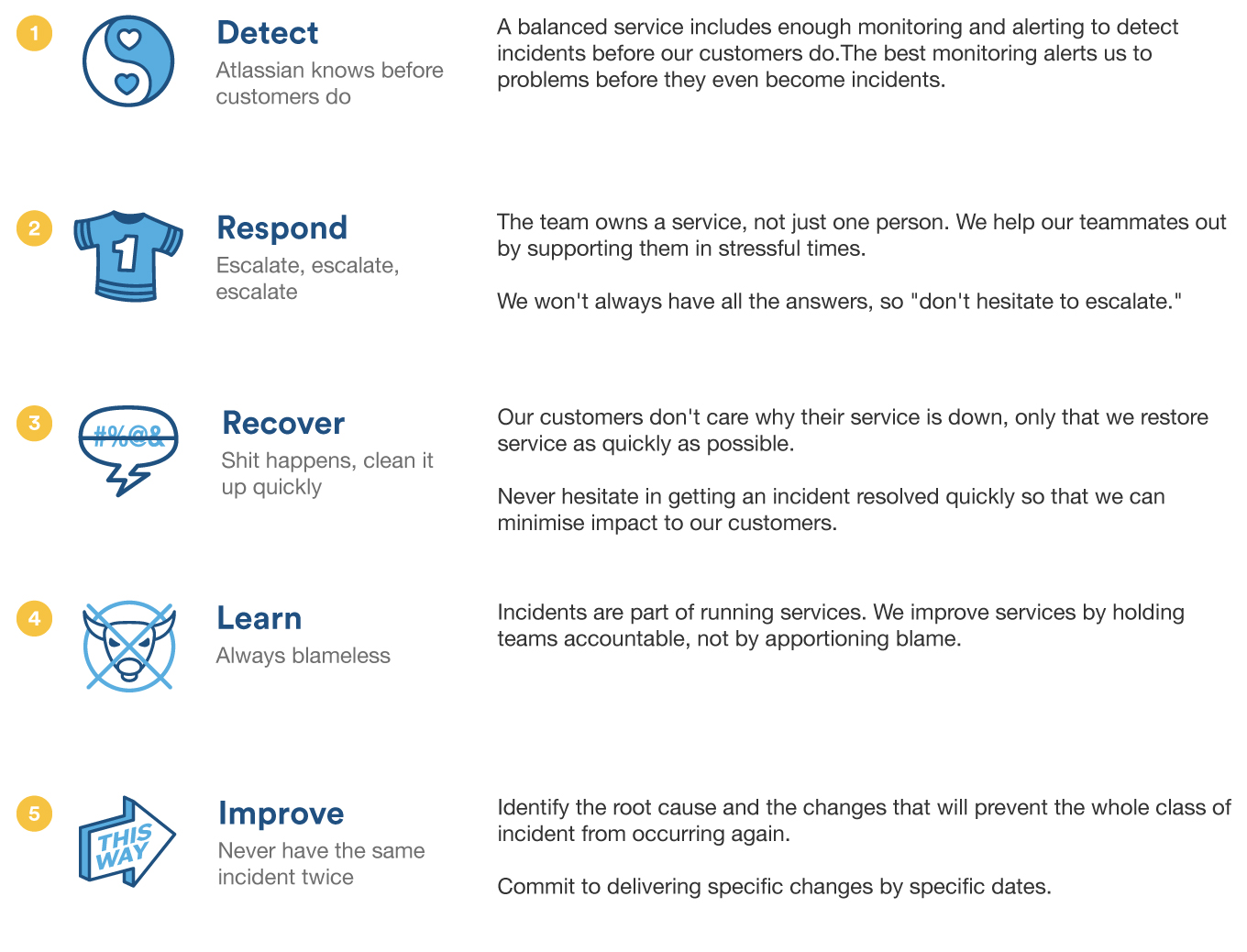
How Are These Useful?
Here are some examples we’ve gleaned from being part of incidents at Atlassian and other companies:
As a service owner, are my services monitored and alerted appropriately?
Value: Detect – Atlassian knows before our customers do.
If your team is only finding out about problems after they impact customers, you should dedicate effort to improving your monitoring and alerting. (“Knowledge is power,” as the old adage goes.)
I know there’s a problem, but it’s the middle of the night and I really don’t like waking people up. It might not even be their problem.
Value: Respond – Escalate, escalate, escalate.
We’re all on the same team, and teammates support each other. One person cannot be expected to carry the weight of an entire service, and when one person tries to, the service – and the whole team – suffers. There is never any shame in asking for help.
A service is down; customers are unable to use it. I’m the tech lead. I know I can restore service with a quick restart, or I can spend time investigating the root cause while the service is down. What should I do?
Value: Recover – Shit happens, clean it up quickly.
Communicate downtime to your customers with a tool like Statuspage and keep them in the loop as you restore service. Then work on figuring out the root cause.
You may be thinking, “A-ha! This contradicts ‘never have the same incident twice.’” Not necessarily – if you know you can restore service with a quick restart, and it’s not going to impede root cause determination, then there’s no downside to fast restoration. You should absolutely pursue it. If restoration of service is going to somehow impede root cause determination, then you probably have two problems: 1) the service failed, and 2) it needs better instrumentation, monitoring, or logging.
An engineer deployed a dev version to prod and caused an incident. What’s the root cause?
Value: Learn – Always blameless.
Human error is never a valid root cause. How was it even possible for the engineer to deploy a dev version to prod? What safeguards are we missing?
Part of the learning process is also helping your users understand the root cause of the incident through a post-mortem. A strong post-mortem will apologize, show understanding of what happened (again, always blameless), and explain your remediation plan.
There was a bug that caused an incident. We put in a post-commit check for that specific bug. Have we resolved the root cause?
Value: Improve – Never have the same incident twice.
Can that same bug bite elsewhere? What situations are likely to lead to a developer introducing this bug? Can we mitigate this risk more broadly than just this specific case?
The new shape of IT
To do all of this, we of course run ChatOps in Stride. With ChatOps, we can monitor our services and receive alerts immediately when they go down, notify our teammates immediately when an incident occurs, work together to restore service ASAP, and do a post-mortem afterward to discuss how we can avoid the same incident in the future.
ChatOps will allow your resolution teams to stay on the same page and resolve incidents more efficiently. But as you live the values from “detect” to “improve”, make sure to also reflect them outwardly through frequent and candid incident communication to your users. We use Statuspage for this, which can also be integrated into your ChatOps process to resolve incidents faster. Keeping your internal/external users informed throughout each stage of the process will give your team the focus necessary to resolve the problem at hand while also building trust.
What will your team value when it matters most? For that, we go back to the beginning: delivering world-class service, resolving issues faster, and building lasting trust within the organization.


