
 I’m part of a team called Service Enablement, which is a special project group within the broader support team at Atlassian. We work closely with the support, engineering, product, and design teams to ensure that we provide a feedback loop between customers and the product. Most importantly, we try to prevent major incidents from happening before they happen – because we care about you as customers, and we want you to be customers for life.
I’m part of a team called Service Enablement, which is a special project group within the broader support team at Atlassian. We work closely with the support, engineering, product, and design teams to ensure that we provide a feedback loop between customers and the product. Most importantly, we try to prevent major incidents from happening before they happen – because we care about you as customers, and we want you to be customers for life.
As you may already know, Atlassian is not your traditional company. We don’t have a sales force like many traditional enterprise software vendors, so it’s especially critical that we have a way to gather, analyze, and disseminate feedback from customers across the company.
Let me share with you an analogy to explain why we created the service enablement team. My wife and I had a gym membership, and initially, it was great. There was always a spare lane within the pool, yoga classes were only 20-25% full, and I could always get a locker. But then the lines got longer, the classes busier, and the lockers less plentiful. I ended up cancelling my membership with the reason “no longer useful to us,” but it was really because there was no space. Because I had no feedback mechanism, the gym probably didn’t foresee that I was going to cancel, and when I cancelled, there was no way for them to know the real problem.
We aspire to not only identify problems before they occur – but also identify the real reason a customer is experiencing issues.
Why proactive support matters
Support teams love to help and love to solve riddles. But finding a team that does proactive support is a challenge. A survey completed by inContact (a leading provider of cloud contact center software and agent optimization tools) in the United States found that:
87 percent of U.S. adults want to be contacted proactively by an organization or company.
I would have been open to talking to the gym about my frustration in not being able to get a swim lane. They may have had a chance to solve the problem and I would have had been able to swim!
Proactive support matters for a few reasons:
- Customers are able to get their real issues addressed.
- Customers can get their work done.
- Companies are able to prevent major incidents.
- Companies can retain customers… and stay in business.
I’m going to share with you a major component of how we do proactive support: a unique categorization system. But before I get into that…
Why (great) categorization is important
Once upon a time, we didn’t have a great way to categorize tickets. We had many labels for many things. We even had one-off categories that were never used again. Users were aware of the categories and used the wrong categories.
What happened is that we were unable to do useful or thoughtful data analysis – and we were unable to provide value to other teams inside Atlassian.
Our team needed a consistent and controlled categorization system so that we could do data analysis and deliver customer feedback to product and design teams. It is through great categorization that our team can uncover the most impactful opportunities to deliver proactive support to customers.
A new categorization system
So, what did we do? We sat in a room and decided to work on a new system. The first thing we realized was that we needed a way to identify where in the product the issue occurred and what kind of issue it was.
We had a few guidelines for a great categorization system. It needed to be:
- Scalable: categories would last for a long time
- Consistent: categories could be applied to multiple products
- Specific: categories that are specific and could explain where in the product an issue was happening
- Accurate: categories that could be appropriately mapped to each kind of issue
We chose a derivative of the Software Quality Model, which we call R.U.F.

It allows our customers’ voices to be:
- Assessed quickly from the customers’ description, allowing components to be applied early
- Aligned to bug and feature resolution, allowing accuracy monitoring of component application
- Combined with breadcrumbs to the affected area of the product, providing qualitative analysis
We were then able to apply this to many issues and quickly see at a glance what issues customers were experiencing.
For example, here’s a monthly view of Jira Service Desk‘s categorized issues:
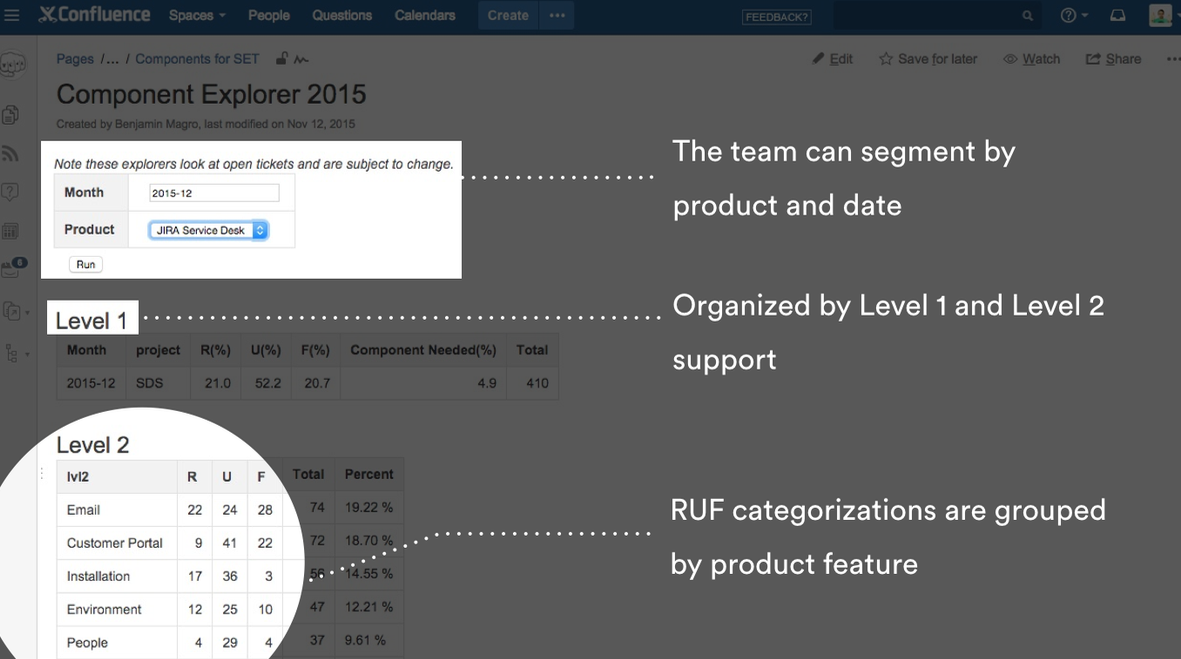
Our service enablement team now has data to guide our conversations with product, development, technical writing, and marketing teams. We are able to quantify opportunities and provide a qualitative value as to the product area and pain type which had driven a customer to reach out to support.
We are even able to start cross referencing with other metrics, including Overall Resolution Time (ORT). We can now understand how resolution time is impacted by certain categories.
Results
Let me give you just two examples of how we have successfully influenced changes in the product, and have seen a drop off in reported issues.
Proactive messaging
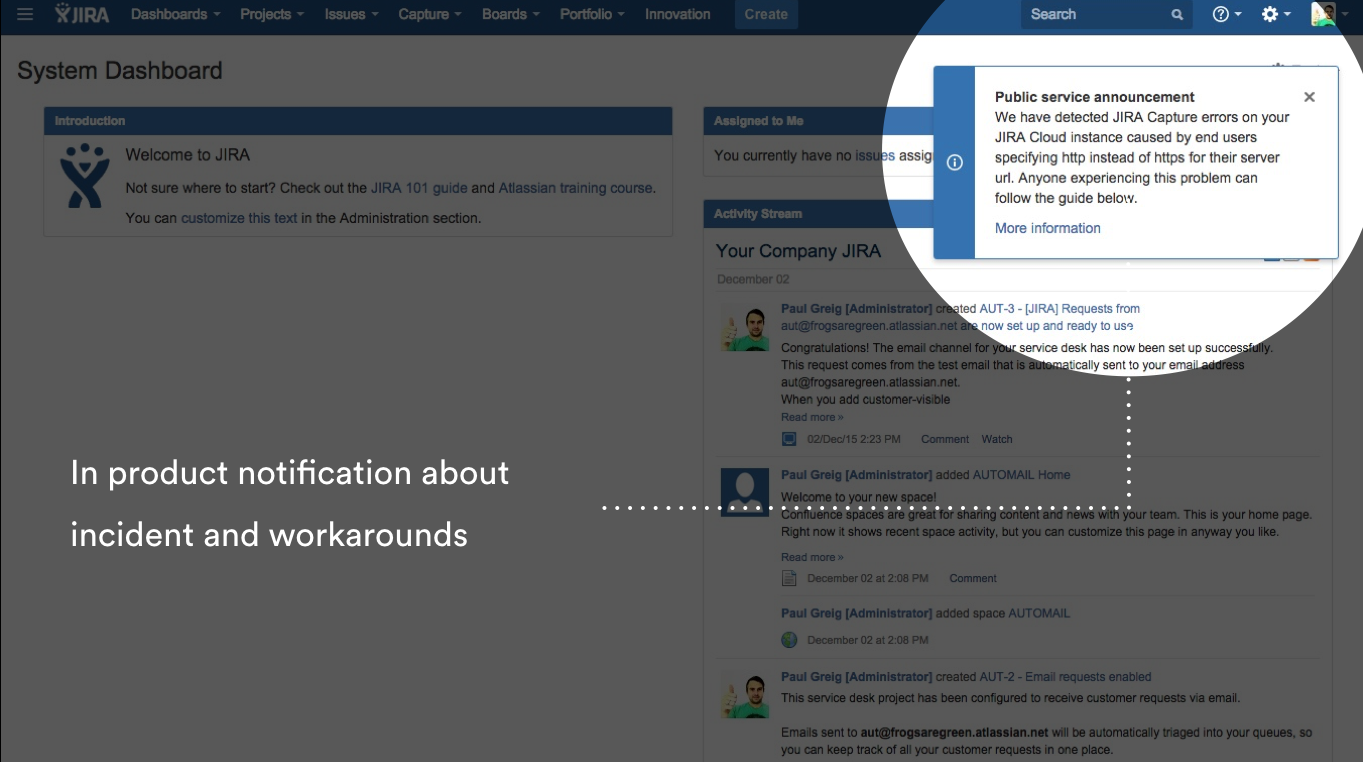
Incidents were accounting for approximately 30% of cloud support reliability tickets. Our support often gave customers ideas for workarounds, but this wasn’t scalable and wasn’t available to all customers affected.
Utilizing the existing public announcement plugin within Cloud, our support team built a notification which allowed us to communicate to the affected customers in-app, advising of the available workaround.
Customers knew immediately what was up, and they had an easy way to learn about a temporary workaround.
We delivered the service to Cloud late 2015 and have used it multiple times to convey an incident with workarounds to the relevant users. We were able to reduce tickets related to an incident by over 70% when using the service. Because we reduced the time spent by an engineer answering the same query 16+ times per incident, our support team has more time to spend on important strategic initiatives — and teams are able to continue working.
Service Desk notifications
This isn’t just the case for our platform, but also for specific products. With Jira Service Desk, we noticed that there was a pattern of email functionality tickets. We dug deeper and realized that customers wanted less noise with regard to Jira Service Desk notifications.
In addition to research by our product teams and customer interviews, the service enablement teams were able to help quantify and qualify the impact of delivering the solution “Simplified request notifications.” Customers were no longer on the receiving end of a barrage of updates for each transition of an issue, but only informed when necessary action was required. We’ve observed a decline in functionality-based requests by over 10% from the peak and continue to review for additional opportunities in any of the RUF categories.
Now customers have a better experience when using Jira Service Desk – they’re able to get the right amount of notifications from email, and are able to use it to get the help they need.
But our real victories? Keeping customers’ confidence and support.
It’s the reason I go to work every day, and when I know I have personally made a difference in a customer’s experience – that’s the real win.
If you’re interested in learning how Atlassian’s IT and support teams use Confluence, Jira Service Desk, and Jira Software to provide legendary service, join our webinar and fireside chat with CEO Mike Cannon-Brookes on February 18th. It’s free and open to all!

