
Take a page from our (hand)book.


Our mission at Atlassian is to unleash the potential of every team. One thing we know great teams have in common? They use playbooks to manage the many processes formulated to keep their organizations running smoothly.
This article covers 5 critical steps to creating an effective incident response playbook. We’ll be using our own Atlassian Incident Management Handbook as a template to develop an incident response plan.
Why agile teams need an incident playbook
An incident response playbook empowers teams with standard procedures and steps for responding and resolving incidents in real time. Playbooks can also include peacetime training and exercises, which will prepare the team for the next incident.
At Atlassian, our incident teams are constantly training, refining, testing, and improving our incident management process. We developed our incident response playbook to:
- Guide autonomous decision-making people and teams in incidents and postmortems.
- Build a consistent culture between teams of how we identify, manage, and learn from incidents.
- Align teams as to what attitude they should be bringing to each part of incident identification, resolution, and reflection.
What’s in an incident response playbook?
Playbooks are a key component of DevOps and IT Ops incident management, as well as cybersecurity. They set the organization’s policies and practices for responding to unplanned outages, help teams bring order to chaos and make sure everyone’s responding to incidents and security threats consistently.
Building an Incident Response Playbook
In creating our own Atlassian Incident Management Handbook, we’ve identified 5 best practices when it comes to managing an incident. These steps can be translated to a variety of DevOps and IT Ops teams and help guide the process of building an effective incident response playbook.
1. Define incidents for your organization
What to include: A specific definition of what constitutes an incident
Why: You can’t effectively resolve an incident if you don’t know when it’s happening. Different teams define incidents in different ways. If something goes wrong, every second matters, and you don’t need colleagues fighting over semantics.
Example:
The definition of an incident as it appears in the Atlassian Incident Management Handbook:


This definition not only what constitutes an incident, but also defines when an incident is resolved and remediated.
2. Establish predesignated roles
What to include: Incident roles and responsibilities
Why: A proper incident response playbook designates clear roles and responsibilities. Individuals on the incident response team are familiar with each role and know what they’re responsible for during an incident.
Example:
The roles we use at Atlassian are in place to ensure all necessary steps are covered, no duplicate work occurs, and communication runs smoothly and effectively.
- Incident Manager, has overall responsibility and authority for the incident. Empowered to take any action necessary to resolve the incident, which includes paging additional responders in the organization and keeping those involved in an incident focused on restoring service as quickly as possible.
- Tech Lead, a senior technical responder. Responsible for developing theories about what’s broken and why, deciding on changes, and running the technical team. Works closely with the incident manager.
- Communications Manager, a person familiar with public communications, possibly from the customer support team or public relations. Responsible for writing and sending internal and external communications.
3. Enforce a consistent process
What to include: Process steps and workflows
Why: No two incidents are exactly alike. But that doesn’t mean your responders can’t introduce a consistent workflow for responding to incidents.
Outline key steps and phases and make sure team members are clear on what’s expected during each phase – and what comes next. For example, Atlassian outlines the incident response flow over seven steps through three phases in order to drive the incident from detection to resolution.
Example:

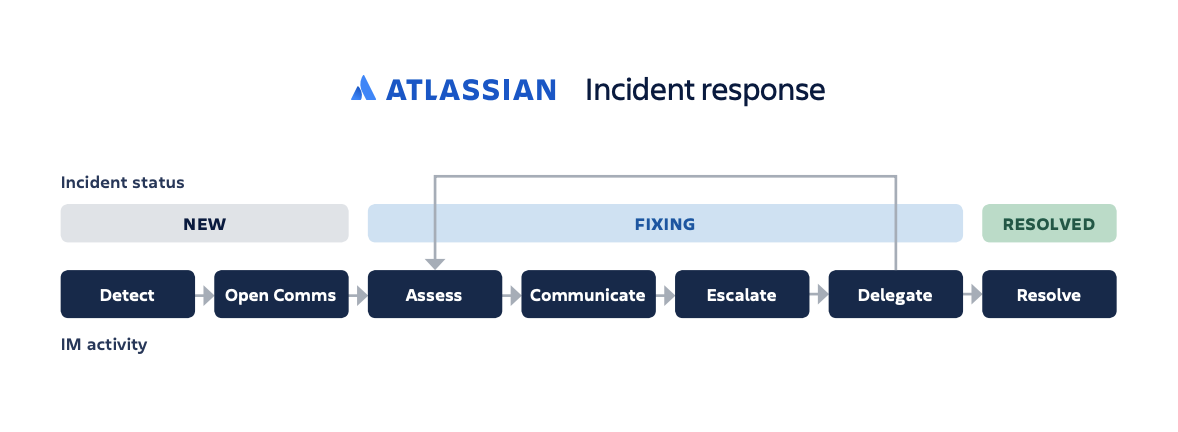
As a new incident is detected, the incident manager begins initiating internal communication and response organization. This the team can begin working on fixing the cause of the incident and reaching a resolution. Strong organization in this stage facilitates action, which is powered by frequent communication. Adhering to a consistent process leads to a faster resolution, including a postmortem exercise we will cover below.
4. Enable rapid response
What to include: Templates and checklists
Why: Incident playbooks need to be simple enough for teams to follow in times of stress. Our own process includes a major incident manager “cheat sheet,” which outlines key steps like assessment, escalation, and delegation in a one-page format.
Following a predetermined incident response process doesn’t mean there’s no room to improvise. You have to be flexible and know when to adapt to a changing situation. Incidents, by definition, are scenarios where things don’t go according to plan, but that doesn’t mean you can’t plan for them. The teams who train and practice a set of plays are typically the ones who succeed.
Use this:
Try running an Incident Response Values play to improve team cohesiveness and work out any potential misunderstandings prior to an incident. Use our resource, the Atlassian Team Playbook, to better understand your team’s process in order to build a dynamic playbook.
5. Facilitate comprehensive postmortems
What to include: Outline of the postmortem process and issue fields
Why: A postmortem seeks to maximize the value of an incident by understanding all contributing causes, documenting the incident for future reference and pattern discovery, and enacting effective preventative actions to reduce the likelihood or impact of recurrence.
If you think of an incident as an unscheduled investment in the reliability of your system, then the postmortem is how you maximize the return of that investment.
Try this:
For postmortems to be effective, the process has to make it easy for teams to identify causes and fix them. The exact methods you use depend on your team culture; at Atlassian, we’ve found a combination of methods that work for our postmortem teams:
- Face-to-face meetings help drive appropriate analysis and align the team on what needs fixing.
- Postmortem approvals by delivery and operations team managers incentivize teams to do them thoroughly.
- Designate priority actions with assigned Service Level Objectives (SLO) with reminders and reports to ensure they are completed.
A step-by-step outline of the Atlassian incident response postmortem can be found on page 46 of our Incident Management Handbook.
Ultimately, an incident response playbook should be used to drive teams to work together effectively to resolve incidents as fast as possible. When an incident occurs, no one has time to debate best practices and point fingers. Thorough, well designed playbooks empower teams to do their best work. At Atlassian, our guide to all of these plays is detailed in our Incident Management Handbook.