

Revamping Confluence Cloud Search
We are happy to announce that Confluence Cloud Search is now powered by a new, scalable, and improved platform since August 2020. This has played an integral role in achieving our 10K goal (10k users per tenant), which went live on August 17, 2020. This blog describes more reasons for moving to the new platform. It also compares the old vs. new search architecture with a short peek into some of the interesting problems we solved.
The new search platform is intended to be across all products and will provide a one-stop shop for everything search related that all Atlassian products can benefit from.
The reasons why we moved to the new platform are:
- Better operational stability and reliability
- Improved relevance and search experimentation
- Scaling to support large projected customer growth
- Reduce monolithic code complexity
- To build centralized search expertise and consistent search experiences, particularly cross-product, across the Atlassian suite.
So where all do we use search?
If you’ve used Confluence, you’ve used search. More documentation here.

Rest API

Macros
Other UI Experiences



Basically, search is everywhere in Confluence!

Previous Search infrastructure
The old search platform was an Atlassian-managed Elastic search cluster. Confluence cloud’s legacy search implementation was responsible for creating and sending Elastic search documents containing all information required to be indexed (so that it is searchable). Confluence backend service then queried this index using Elastic Search queries.
Architecture

Reasons for changing our search infrastructure
Although our previous search infrastructure had served us well and provided the necessary functionality, we had to move away from it due to the following concerns:
Operational Concerns:
- Developer time was needed to get the Elastic Search cluster into a healthy state in case of issues.
- The legacy implementation was optimized to serve many small tenants but needed custom configuration for larger tenants.
- There have been several incidents with nodes leaving the cluster and high CPU spikes. Lack of easily accessible data for debugging.
- Backing up clusters and switching traffic involved manual effort. Automatic replication and latency-based routing were not supported.
Financial Reasons:
- Operational overhead increased serving cost significantly – especially for larger tenants.
- Additional security licensing cost for Shield Plugin (Elastic Search plugin for auth).
Design/Architectural Complexity:
- The old platform was running in maintenance mode and was on an old version of Elastic Search.
- No rate limiting was in place to control search traffic. This caused clusters to go down.
- Lack of control on incoming requests which could be very expensive in terms of resources.
- The backend code for indexing and querying the search index was quite complex.
Moving to the Cross Product Search Platform
The new search platform was built to address the concerns which we faced with the old platform.
The primary design requirements which needed to be met were:
- Move to AWS-managed Elastic Search.
- Decomposition of monolithic Confluence code through microservices.
- Multi-region, real-time search support.
- More control over traffic patterns – circuit breakers, rate limiting, etc.
Architecture

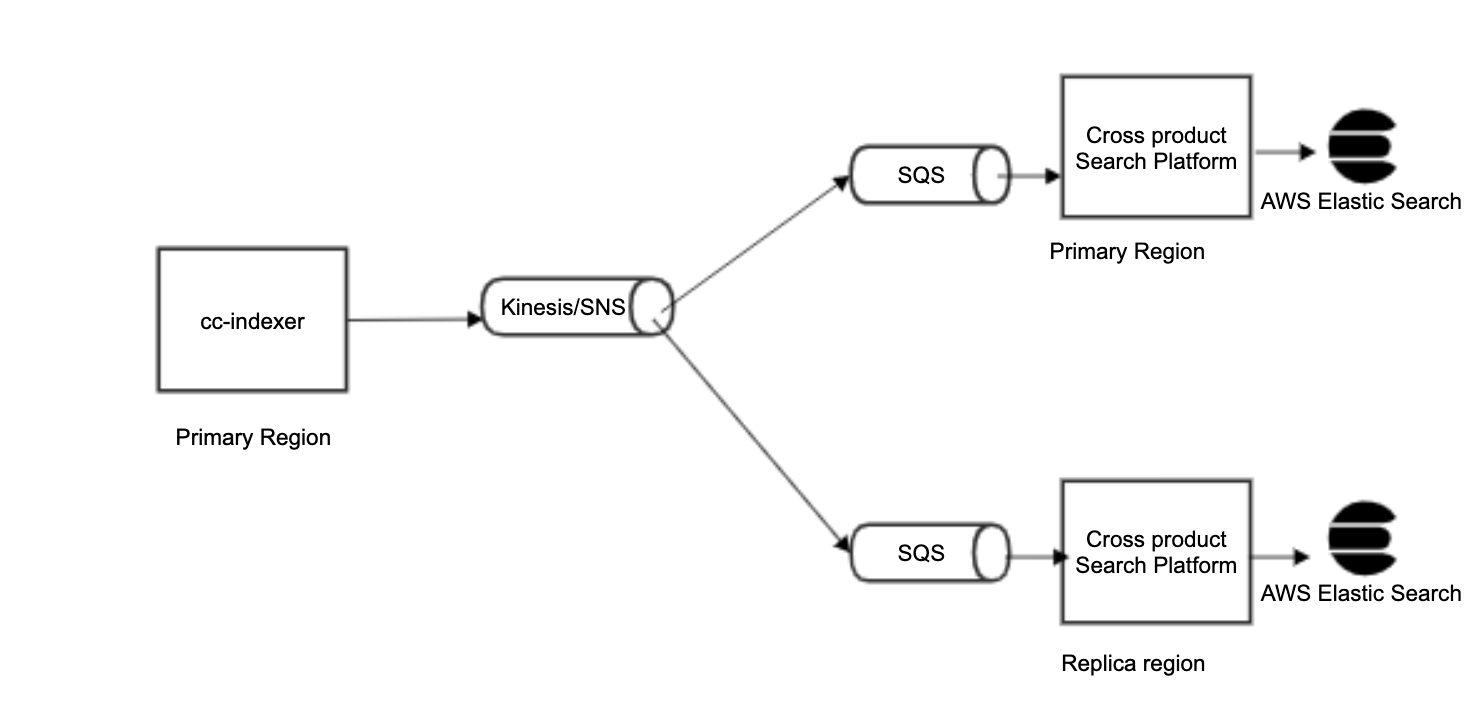
Indexing
Let’s say a user creates a page in Confluence.
- It gets saved to the database and all the searchable fields and permissions are send in a JSON payload to a Confluence microservice. Note that the indexing takes place in the background and the page is published immediately.
- This service validates the fields and sends them to a Kinesis-based streaming service.
- Cross Product indexer service consumes these payloads and indexes into AWS-managed Elastic search service.
Searching
If a user performs a search in Confluence using any of the above mentioned experiences,
- The request first hits the search API gateway.
- Content search goes to the Cross Product Content Search service.
- Cross Product Content Search service validates permissions for the user and fetches results from the Elastic Search index which was populated during the indexing flow above.
- The service also consults a Relevance system that uses various mechanisms to rerank the search results so the user has a better experience. One example of these mechanisms is using the user’s recently viewed history to rerank the results so they can find the content quickly and are satisfied.
Some interesting challenges and how we solved them
Multi-region availability
Problem

The previous search platform managed by Confluence had replication but only within the same region. If a region had to be down for maintenance, the data was copied into another region which would take a couple of hours, and then the new region would receive traffic temporarily. Basically, there was no automatic region failover support and the disaster recovery was slow.e
Solution
With the new platform, we decided to replicate the index into multiple data residency-compliant regions at all times so we have an active backup ready to go in case of any issues. We used multiplexing of the events for this approach so Confluence could send events to a single stream and the search platform was able to subscribe to the same events via SQS queues in multiple regions. Apart from disaster recovery, this is also used for latency-based routing to ensure users who are traveling experience low latency search responses if they are connected to a region that has a copy of the index.
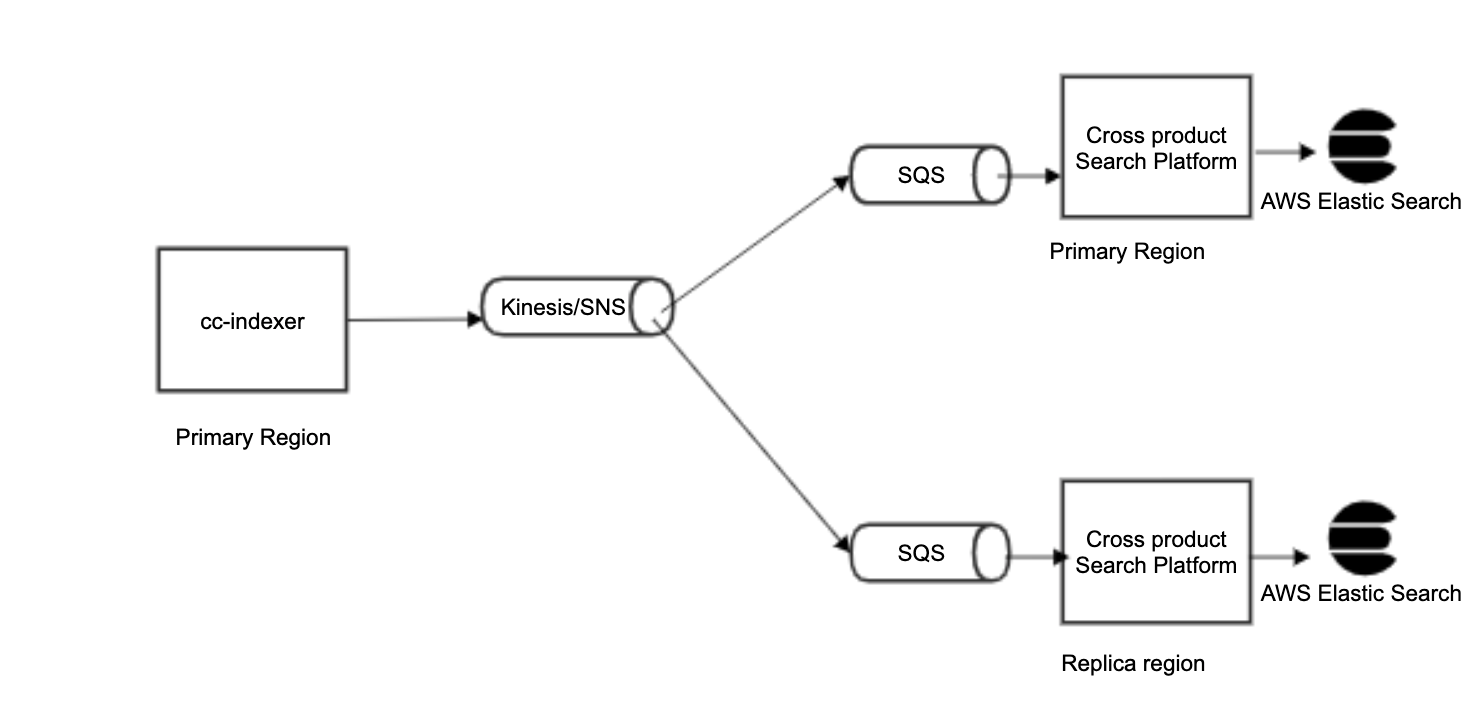
Impact
We were able to achieve zero downtime failover support since if one region is down, the traffic automatically gets routed to the alternate region.
Users who were traveling would experience low latency search responses even though they are connected to a region all the way across the world.
Efficient sharding
What was the problem?

How did we solve it?
Now, we use routing strategies based on the size of the tenant to route them to either one or many shards on the same index.
This allows for much less fragmentation with smaller tenants clustered together more efficiently.
Larger tenants will be split between many shards, meaning they don’t need their own custom index but we are still avoiding hot sharding and optimizing performance as best as possible.
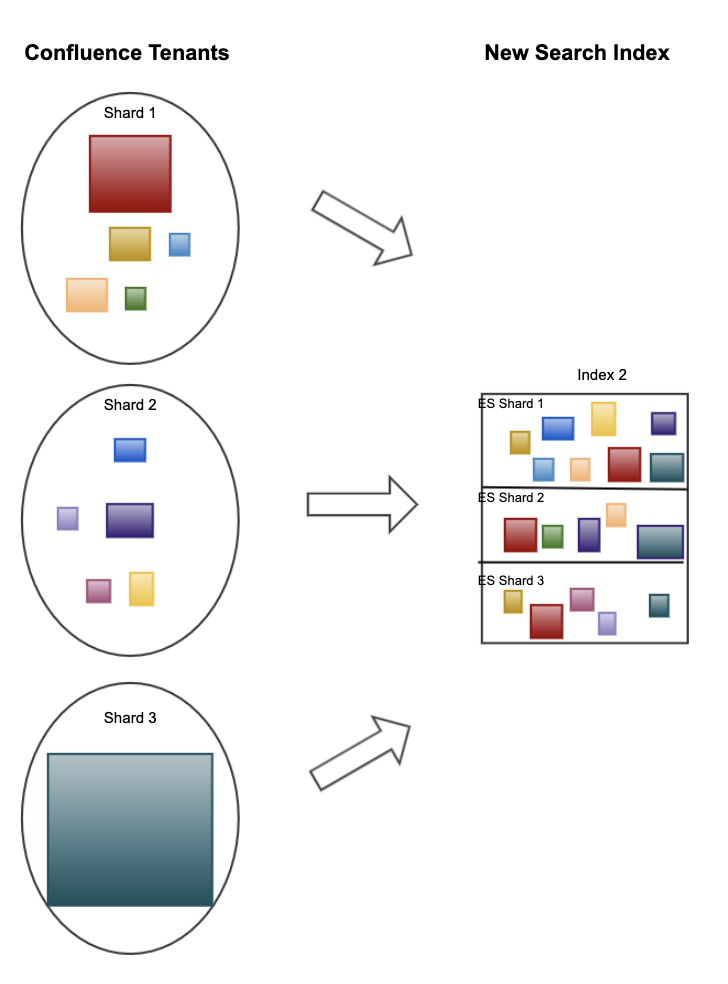
What was the impact?
By re-architecting our data partitioning, the resulting system is
- Highly scalable and ready for our larger tier customers
- Can handle the noisy neighbors problem better due to distribution
- Lower cost since we no longer needed custom configuration for larger tenants and the smaller tenants were clustered more efficiently
- Less complex since we don’t have special casing for larger tenants, making operations more straightforward
Optimal permission checks
What was the problem?
Confluence permissions can get very complex which makes them difficult to scale. This is by no means a problem unique to Confluence. As products grow, so too do features around access permissions and the size of hierarchies and permissions applied.
Let’s start with a general understanding of how permissions work in Confluence.
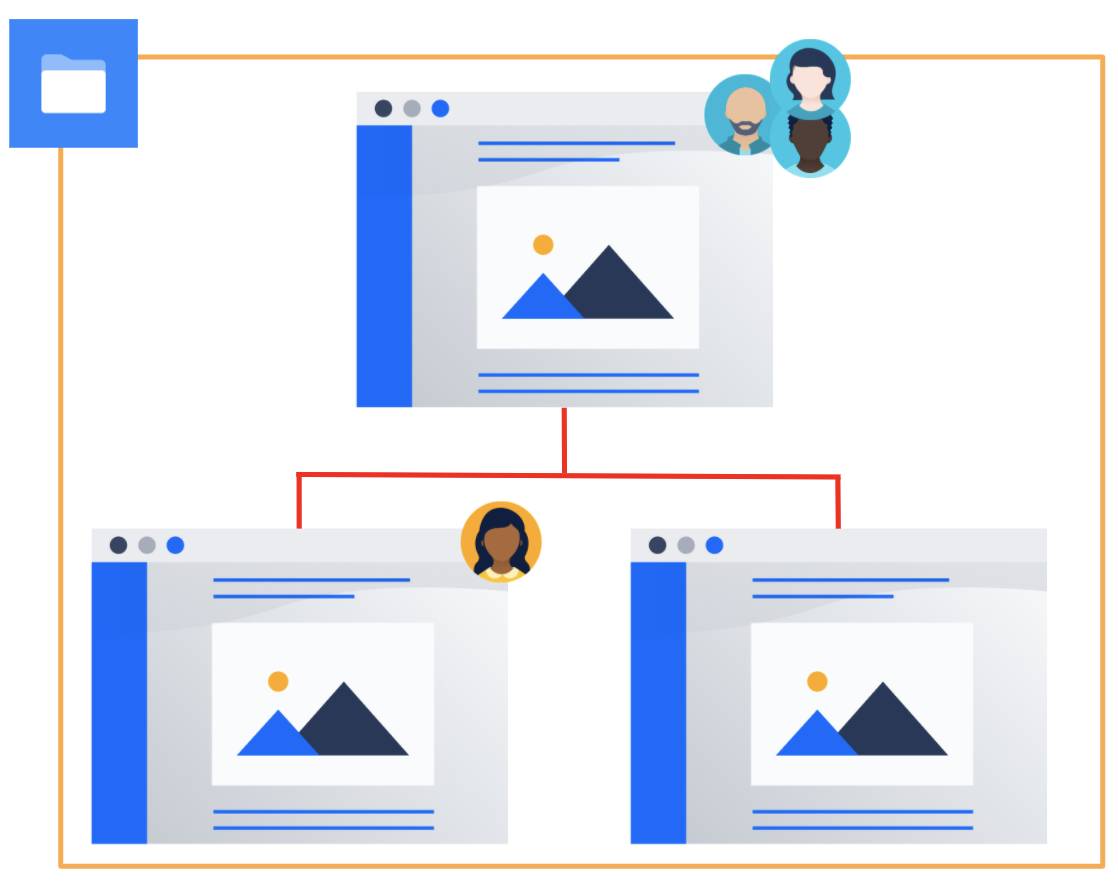
Content Permissions are hierarchical and each page will only grant permissions to users who have access to all its parent pages as well as to the space containing them.
This access can be granted through groups or directly to a user.
Previously, Confluence evaluated permissions using an Elastic Search Java plugin that ran a linear scan to evaluate these permissions.
Confluence would do a walkthrough and check the requesting user and their groups against permissions on every document that matches the query, checking all the permissions in hierarchy.

The cost of this process was linear since every document would need to be visited.
The permissions fields were brought into memory for every check, and each field could be up to 32k bytes since it was a single string field in the index.
This led to multiple incidents where the field size got prohibitively large. This not only caused performance issues but led to unexpected behavior across multiple systems.
How did we solve it?

Now the new search index converts the AND of ORs model to an OR of ANDs. This can lead to an explosion of terms. But by using set theory to remove redundant terms, subsuming sets, and impossible combinations we can simplify this.
This expression can be stored in an Elastic Search keyword array directly on the content document. Each bracketed expression will be indexed as a separate item in the keyword array. Since each item is indexed separately, there is no longer the risk of the permissions field being too large to index.
Queries against this array are supported internally by Elastic Search with logarithmic access time.
What was the impact?
This solution helped us with:
- Being much faster – went from linear time complexity to logarithmic time complexity. Take a look at the response times as a function of results before, and you can see the overall performance improvements from exponential to linear.


- Having a low memory footprint – not bringing every document into memory.
- Ability to Scale – can now store all permissions on the document without hitting field size limits.
Scaleable Relevance
What was the problem?
Experimentation and iteration are the foundation to improving anything – this is especially true in making search more relevant. It’s difficult to predict exactly what people are searching for without a way to test and validate ideas.
The search teams have been trying to make relevance improvements over the past couple of years with great difficulty.
- Difficult to change queries – There was no easy existing way to boost or change the query from outside of monolithic code bases.
- Queries became too complex – Boosting on top of existing queries was hacky and difficult to reason about and improve on.
- Post ranking experimentation was difficult – Had to overfetch for post ranking, and still had poor recall.
How did we solve it?
We solved it by providing in-built support for experimentation in one place with direct access to the query and index.
The search platform is integrated with centralized relevance stores that provide features and signals to be fed into ML models and query boosting. The store uses analytics and data processing jobs to generate features that can be customized for each user. This integration is reusable for many types of features and will work for cross-product and site experiences. Unlike before, this integration is placed very close to the query formulation, allowing for simple query boosting and the ability to reasonably combine features.
Another capability we have added is the experimentation framework. All queries coming through the content searcher have the potential to go through a shadow or an A/B test experiment. The direct access to the query means we have more control over its formulation and can do all kinds of boosting and custom queries during experimentation. The framework allows for quick iteration and testing of new ideas through a measurable process.
We now have APIs and data flows that let the data science team run their own queries directly against the index and evaluate the results. This again allows for quick iteration and testing, with no customer impact during the initial iterations. Having this in place has given our data scientists more autonomy in building and validating their queries.
What was the impact?
This has set us up for future success, with some experiments already resulting in improvements. It gives us opportunities to pull multiple levers when it comes to search relevance improvements for our customers
One major success from this pipeline is the addition of space affinity and querying principal boosting parameters to the query. Space affinity boosts results within spaces that a user interacts with most, whereas principal boosting helps bump up the ranks of pages that users have contributed to or interacted with. This experiment resulted in a significant boost to MRR for result sets of 10 of 3.3% at 95% CI [2.5, 4.0] over baseline of 0.132. The deeper meaning to MRR is that it goes beyond the question of just “Did the user find what they were looking for?”, and answers two more questions: “How good were the set of search results?” and “How many query attempts did the user take to find what they were looking for?” So improvements here are a big win for customers getting where they need to!
Learnings
Co-location for ease of collaboration
Confluence and the Search platform teams were co-located during this huge migration. This helped us significantly, as communication was easier and quicker in the same time zone. This made our conversations, planning, debugging issues across services, etc., faster. Regular sync-ups during crunch time made it easier to share info and swarm on critical issues. In the new remote world, we had a dedicated Slack channel with all engineers from each team to discuss any concerns and plan of execution. This was very effective for our collaboration.
Co-contribution model for faster turnaround
Having members of the Confluence team lean in and make changes on the platform in a co-contribution model led to faster turnaround on releasing Confluence-specific features like JSM knowledge base and Content Properties search. It also meant increased knowledge sharing between teams – through active pair programming and technical discussions.
Learning from past integrations
The Search platform team had recently launched GDPR compliant Cross Product User Search for powering mentions and user pickers in Confluence, Jira/Jira Service Desk, and Bitbucket. Many of the learnings from this project were immediately incorporated into the new Search Index:
- Common libraries were reused from the user search indexer, allowing us to quickly get event processing and indexing in Elastic Search working.
- Expertise developed in building the User Search service enabled us to move quickly, particularly in designing with Elastic Search, and work around already familiar nuances and shortcomings of this service.
On the Confluence side, we were able to use our learnings from integrating with User Search to follow the same integration and rollout strategies – for example, we use shadow mode for safer rollout, comparators, and resiliency to ensure we didn’t lose events, and even added circuit breaker to protect our downstreams. We also had effective monitoring so we could easily track the progress of our integration.
Use shadow and incremental rollout strategies
We managed our rollout slowly and incrementally using feature flags. This allowed us to validate functionality as we were developing with minimal customer impact. Our lesson is that we should have done even more of this across our features to ensure parity and allow for even more soaking time to catch all the edge case issues.
Run blitz test with all stakeholders
A blitz is where a number of cross-functional team members sit together and use a staging or test prod tenant in order to validate the various functionalities impacted by new changes. We did run blitz test but only with two teams.
Our lesson is that we should have run blitz tests with representatives from all the stakeholder teams as well, to ensure all scenarios, especially edge cases, were fully tested.
What’s new?
- Better relevance-based ranking with things like recency
- Highly scalable services which can handle heavy traffic
- Data residency compliance for the search index
- We also transitioned to cursor-based pagination for search results
- Some newly supported filters in advanced search, for example:
- search by ancestor
- searching only by the title
Summary
Overall, in migrating our search service we focused on building for reliability, latency, scale, and iterable improvements. This allowed us to achieve the following.
- We had a major performance improvement, particularly in the upper-right search box and the advanced search experience. Before the latencies were ~1800ms@p95 E2E, now our latencies sit around 900ms@p95. We have also done load tests and verified we support scale for our 10k tier customers and beyond.

- We were able to achieve Zero Downtime failover by maintaining multiple active indices allowing us to seamlessly failover to an alternate index for search traffic if a region is down.
- We have leveraged the search platform for relevance improvements as mentioned above by rolling out successful boosting features like space affinity and principal boosting as well as signals like recency. We have many new initiatives in the pipe to continue improving this experience, including better recall and popularity signals.
- We built a reusable search platform that can be used by multiple Atlassian products which can rely on Search expertise and build a common pipeline for all types of content.
- We reduced our overall cost from being a self-hosted Atlassian Managed Elastic Search cluster to AWS-managed Service costs with optimal sharding.
What’s next for Search at Atlassian?
The search platform team and product teams will be working together over the next year to leverage our infrastructure and improve search in Confluence and other products on the platform. We plan on doing this through rapid experimentation and the addition of new signals as well as ensuring compliance and reliability at scale for our largest customers. At the same time, we will simplify the process for reusing this platform in more products and experiences so that search improves across the board.