
Let’s say your engineering team has gone agile. They work in sprints, collaborate, and are building a lot of great features. But there’s just one catch: you still have to wait for the release train to leave the station, and customers aren’t getting value fast enough.
At Atlassian, we’ve discovered some best practices for building products, DevOps style. Let’s start with feedback; because no matter the product, your success is solely based on your users.
This is an article from our newest ebook, DevOps 101, where we give readers an inside look at how Atlassian does DevOps. Access the entire ebook here, or read on for a sneak peek of the great content we have for you.
Let’s say your engineering team has gone agile. They work in sprints, collaborate, and are building a lot of great features. But there’s just one catch: you still have to wait for the release train to leave the station, and customers aren’t getting value fast enough.
At Atlassian, we’ve discovered some best practices for building products, DevOps style. Let’s start with feedback; because no matter the product, your success is solely based on your users.
How to gather feedback — and use it to shape and build features
We’ve learned over the years that the easiest way to improve our product, Hipchat, is to listen to the people that use it. So we rely on the feedback from the thousands of companies that use Hipchat, and naturally, the team at Atlassian, too.
You can collect feedback from just about every source imaginable:
- Ask for in-product feedback.
- Collect user feedback from a Help Desk like Jira Service Desk.
- Monitor social media channels like Twitter and Facebook.
- Use Apdex scores to monitor whether our users are satisfied with your application’s response times.
- Gather monitoring data from third party solutions like Datadog and New Relic.
We have all these services connected to Hipchat so that we can get feedback right in our group chat rooms and discuss as a team. We call this mode of working ChatOps, a collaboration model that connects people, tools, process, and automation into a transparent workflow. Hipchat becomes our home base where all information comes in, discussion is had, and action comes out.
For example, we get a ton of tweets sent to us about our product. We route them, along with all our other social media mentions, bug reports, etc. into dedicated Hipchat rooms, where the whole team can discuss each notification and help shape our backlog.


In either case, we make sure to always stay listening to our customer feedback, wherever they are, and take action when possible.
Plan together in sprints
So, how exactly do we plan what we’re going to build? Our small development teams regroup and meet for an hour every week. We use the hour to:
- Demo everything that was built in the previous week, to keep the team informed and connected.
- Review the objectives and sprint goals we established the previous week, and agree on whether we achieved them.
- Define our objectives for our next sprints. At Atlassian, a sprint objective isn’t the same thing as a ticket. A sprint objective is a unit of work that you have to be able to demo to the team, or ship to production at the end of the sprint.
After the meeting, we break out. With our new objectives in hand, our developers can go through all the issues in our backlog and pick out the ones that will help us achieve the sprint objectives we took on during the meeting.

The end result is complete buy-in from the team. Everyone is fully involved in defining our goals, how we are going to achieve them, and how we are dividing the work.
Plus, these weekly sprint and meeting combinations provide a very natural, collaborative way for us to measure our velocity, and stay focused on our priorities. If a single objective is taking up too much time, or doesn’t look like it will deliver the value we originally hoped for, we can agree as a team to de-prioritize it or cancel it altogether.
Spike early and often
You’re probably familiar with the term “spike” in agile development. A spike is a short effort to gather information, validate our ideas, identify early obstacles, and guesstimate the size of our initiatives. Instead of building a shippable product, we focus on end-to-end prototyping, to arm us with the knowledge we need to get the job done right.
At the end of each spike, we have a better idea of the size and technical obstacles we will encounter for each initiative, and we categorize them: Extra Small, Small, Medium, Large, Extra Large, or Godzilla.
We regularly rotate between normal sprints and spikes, and hold regular “innovation weeks” that result in really amazing prototypes and insights around project scope and approach. Most teams at Atlassian hold innovation weeks, too, and they love to write about them.

Keep even the biggest changes small
Instead of shipping big things infrequently, ship small changes very often. It makes it very easy to roll back a particular change if we need to, or even better: fix and roll-forward, and it helps us iterate very fast.
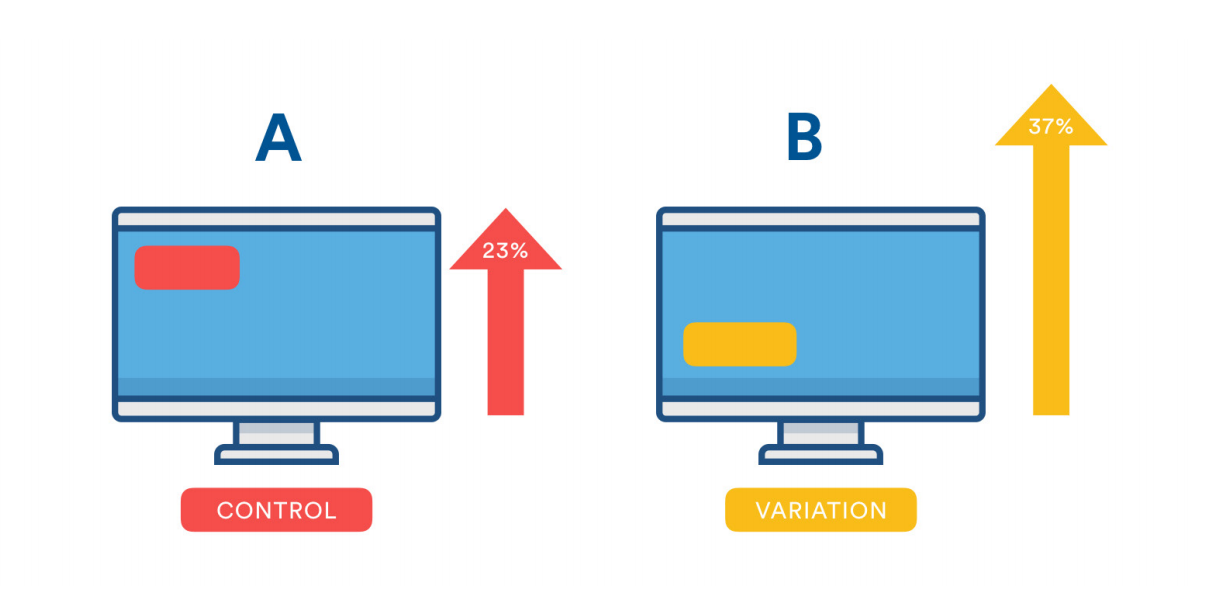
For really big changes — like highly anticipated new features, for example — we still take a “start small” approach, setting “step by step” goals and running frequent A/B tests and experiments to see what our users like best.
To test, we divide our users into cohorts. For example, cohort A might see one version of a Hipchat feature, and cohort B might see a slightly different version. We look at the usage data to see which version of the feature is performing best against the goals we defined during planning — and we keep iterating and testing until we get to the best version of that feature.
A tool we use during these testing phases is Launch Darkly, which lets us release new features to small segments of users, gather feedback, and then gradually increase the audience size until we’ve fully deployed. We often start with just 5% of users running the new feature — and then slowly increase by 10 or 15 percent increments after each feedback and revision cycle.

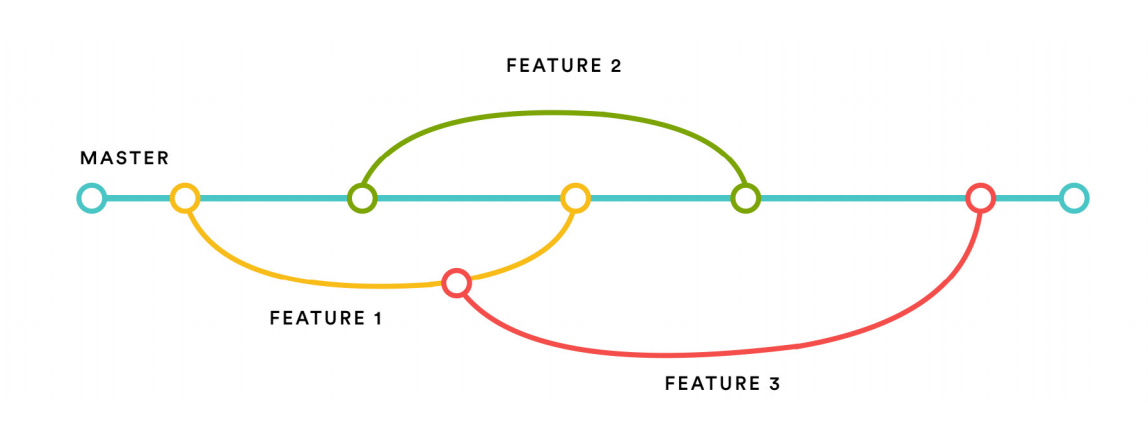
Git + Bitbucket + Bamboo = Automated awesome
We’re heavy users of Git and Bitbucket, using feature branches to make continuous integration far more effective. Any feature, however small, translates into a feature branch, which is automatically tested via our Bamboo builds.
After we test a feature branch, we create a pull request to merge it back to the master branch — and we select a minimum of two reviewers from our team to review and verify the code. Once you get a green build, and 2 approvals, you’re good to go.
Since our master branch is what gets shipped to production, we require that the master be “green” — with no known bugs, issues, or errors — at all times. If a build goes “red,” that means all hands on deck, and the entire team has to drop everything to fix the build.

Encourage accountability
A big difference between our team and many other DevOps teams is our ownership model. We’re big on “you build it, you ship it, you run it” — meaning the team that is responsible for writing a feature also becomes the team responsible for deploying it, and providing ongoing maintenance once it’s live.
But isn’t that going to introduce a lot of issues in production? In fact it’s quite the contrary: it encourages every developer to build the very best version of something, and gives each of us a vested interest in its ongoing success.
What this leads to is 100+ developers able to ship to production at any point in time. This is made possible with the right process, and especially the right tools. We use Chef and Puppet for automation, and developed a number of Hipchat integrations to help us coordinate this process.
Finally, accountability for us also means keeping our users informed of what’s going on. Occasionally, bad stuff happens, and glitches have the potential to impact all of our users. We love Statuspage.io for keeping everyone up to date on the status of all of our services.
For even more DevOps tips and tricks from Atlassian, check out our ebook hosted on our IT Unplugged DevOps resource center. In the book you’ll hear how we use DevOps principles in everything from building infrastructure with continuous delivery, to handling incidents, and more.
If you found this post useful, we’d appreciate if you’d share it on your social network of choice so others can learn about DevOps best practices, too!