
Atlassian’s CPR program untangled complex service dependencies, boosting platform reliability and recoverability. By simplifying architecture and fostering a culture of dependency awareness, CPR strengthened Atlassian’s cloud resilience.
1. Introduction
Over four years, an Atlassian project called CPR (Continuous PaaS Recovery) improved platform reliability and recoverability by removing dependency tangles in its services architecture. It delivered six new platform services, created innovative tools, and shaped engineering culture to focus on dependency analysis and recoverability. The project identified and eliminated hundreds of critical platform risks, simplifying architecture and boosting Atlassian’s reliability and emergency recovery capabilities.
2. Platform Overview – Micros
Atlassian runs a large service-based platform with thousands of different services, most deployed by our custom orchestration system, Micros. It is a high-level abstraction on AWS Cloud that enforces best practices and lets developers focus on building products and features instead of managing infrastructure.
Read more about Micros here:
- Why Atlassian uses an internal PaaS to regulate AWS access – Work Life by Atlassian – Still mostly accurate from 2019
- From firefighting to future-proofing: Atlassian’s journey with a multi-account strategy – Work Life by Atlassian
- Atlassian Cloud architecture and operational practices | Atlassian
The Micros platform has achieved widespread adoption and operates at scale across Atlassian. Key indicators of its reach and impact include:
- 2000+ services
- 5000+ deployments daily
- 40k+ DynamoDB tables, 80k+ RDS tables, 3 million lambda functions
- 30+ supported resource types
- 12+ supported regions
While this scale brings significant advantages, it also amplified the complexity of the platform and introduced unforeseen interactions between its underlying components at scale that could risk reliability.
3. Why dependencies matter: Risks to reliability and recovery.
First lets define what a circular dependency is:



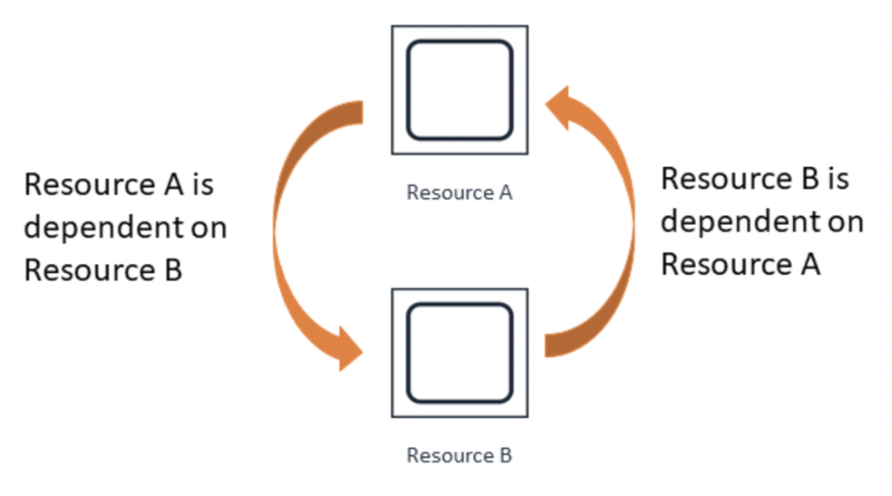
A concrete historical example for the above diagram related to Atlassian:
In 2021, Artifactory (A), Atlassian’s private docker registry, was deployed via Micros (B) A->B, and the Micros platform (B) depended on Artifactory (A) at deployment and runtime B->A. This created a dependency loop.
What could cause both services to be down simultaneously?
- They might share a critical third-party dependency that experiences an outage, such as an auth provider or cloud service.
- Overlapping incidents in both services.
How are tangles introduced?
Large PaaS architectures evolve constantly, naturally introducing new tangles.
Tangles arise in situations often driven by legitimate business needs, including:
- Feature development – Adding new features often requires services to communicate, creating a mesh of dependencies.
- Evolution – New frameworks, tools, and languages change underlying dependencies, including build-time dependencies.
- Centralisation – Dispersed capabilities may consolidate into central services. For example, service owners who provisioned their own databases now consume a central team’s offering, replacing a third-party cloud dependency with an internal one shared by many services.
- Standardisation – Services may use various solutions for tasks like logging. Standardisation efforts narrow this to a single provider.
- Service proliferation – Unchecked growth in services increases risk.
- Monolith decomposition – Decomposing a monolith can cause dependency tangles if services lack clear boundaries. Common causes include tight coupling, shared databases, complex event choreography, versioning issues, network problems, and unclear ownership.
4. A catalyst for change
In 2022, as more customers migrated and upgraded from DC to cloud, Atlassian increased investment in risk reduction programs including soft deletion, blast radius reduction, and improved disaster recovery. It also prioritized resolving circular dependency risks recently identified in the core Micros platform. Fixing this became a key goal.
The CPR program was born with clear objectives: break circular dependencies, rearchitect the platform for recoverability, and increase customer trust.
5. Analysis: Our approach to breaking tangles
Data-driven analysis: Surveying service owners, mapping dependencies.
To fix the circular dependency problem, we first surveyed hundreds of service owners about the dependencies of the thousands of services they manage.
We collected the following information:
- Deploy time dependencies – required to build and deploy software
- Runtime dependencies – required while the service operates
We further categorised these as:
- Hard dependency – essential for operation, e.g., AWS, networking, authentication
- Soft dependency – operates with limited capabilities, e.g., logging, metrics, alerting
This survey created a database of dependencies, enabling us to map subsets. The diagram below shows a platform subset with red lines indicating problematic tangles and blue lines marking non-problematic dependencies.


Guiding principles
We established guiding principles for the program.
- Prioritise hard dependencies – We focus on reducing hard dependency tangles, which block recoverability. Soft dependency tangles may complicate or slow recovery; removing them is a bonus, but many will remain. Converting hard dependencies into soft ones is also desirable.


- Worst case scenario – After analyzing the data, it became clear that untangling each tangle was difficult due to their number and complexity. The cleanest approach was to imagine the worst-case scenario: recovering the entire platform. If we can recover from that, all subproblems are resolved.
- Minimise using “break glass” solutions (emergency-only fixes) – One approach considered was to have ‘break glass solutions’ or special runbooks for disasters. Instead, we integrated our architectural changes into normal operations to ensure they work when needed, as they are used daily.
- Pragmatic, not perfect – The goal is risk reduction, not perfection. New tangles will arise while fixing existing ones, which will take years. This means we will:
- Prioritise tangles posing above-average risk. Some will become special projects.
- Accept some tangles pragmatically if their risk is low.
- Realistic – We are retrofitting new rules to an existing platform serving many enterprise customers. We may want ideal solutions if starting from scratch, but we are not. Our approach must upgrade the platform without assuming a full rebuild.
- Note: if starting from scratch an idealised solution may be for all services to have no network access by default and can only call services that they declare as dependencies and dependencies can only be on layers below it.
- Educate – We estimated the problem would worsen organically and that resolving existing tangles would take time. Educating engineers about tangle risks now and fostering a culture to minimise new tangles was critical.
- Build if needed – While rearchitecting existing solutions may work, we expect building new tools will often be better. CPR will provide tools to build the lowest layers of Cloud Infrastructure when existing solutions don’t fit.
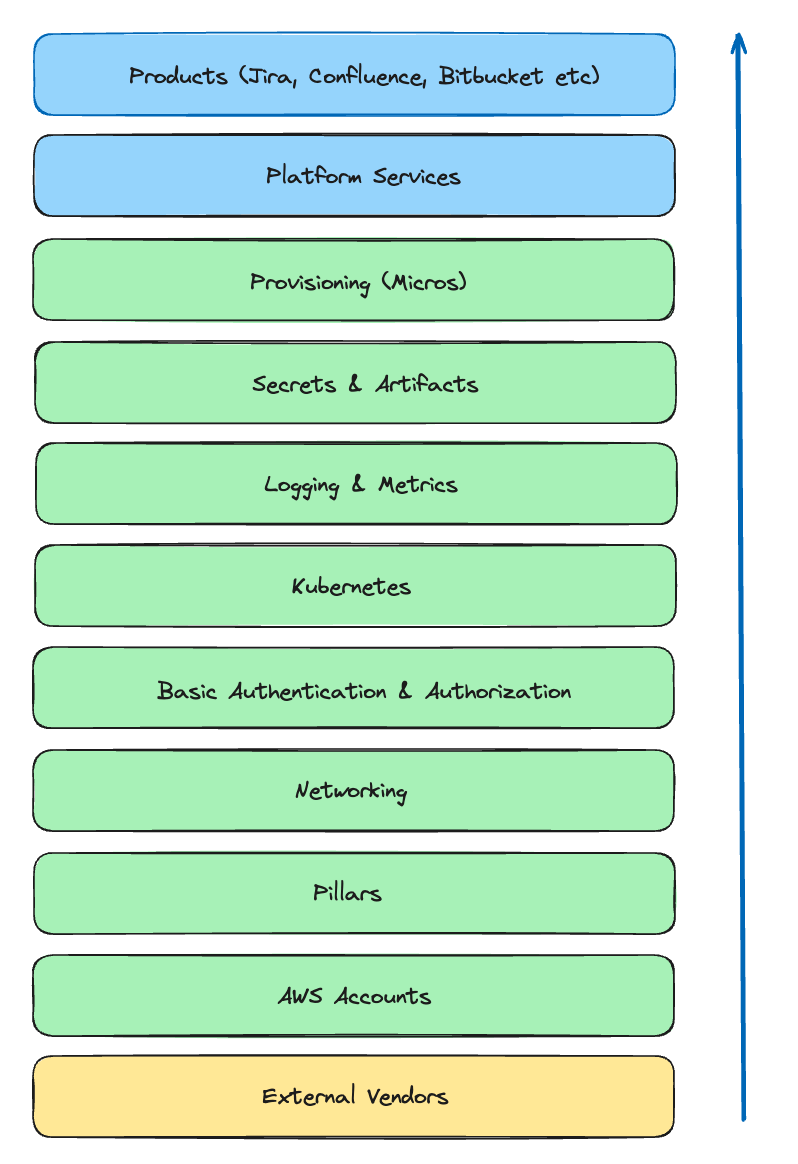
The “Layer Cake” model: Visualising and restructuring the platform into layers
To rearchitect the platform, we decided to divide the cloud infrastructure into layers, with the lowest layers having the fewest dependencies and upper layers having many dependencies.
Establish principles for building layers:
- A component in layer (N) can only have hard dependencies on lower layers (N → N-1 = Good).
- No hard dependencies on the same layer (N → N = Bad).
- No hard dependencies on higher layers (N → N+1 = Bad)


The Atlassian platform can now be viewed as layers, starting with external dependencies like AWS at the bottom, followed by AWS accounts, networking, authentication systems, orchestration systems (Micros, Kubernetes), and products like Jira, Confluence, and Bitbucket at the top.
This turns the complex tangle of dependencies above into a layer cake:

Tabletop exercises: Simulating disaster recovery to identify weaknesses.
A tabletop exercise is a discussion-based activity where team members review a hypothetical scenario to determine an appropriate response.
In March 2023, the CPR team and 40 representatives from 26 PaaS teams participated in an 8-hour tabletop exercise simulating recovery from a complete platform outage.
Start point:


Red circle = not recovered and tangled
The 8-hour session simulated 6.5 days of recovery efforts, improving our shared understanding and helping identify unique risks to prioritise as special projects.
Recovered by end of the day:

Red circle = not recovered yet and still tangled
Risk categorisation: focusing on the most impactful dependency risks.
Several dependency types emerged from analysis.
We scoped pragmatic plans to eliminate the most impactful without needing perfection.
- Deployments risk
- Problem: Atlassian’s main orchestration system “Micros” was a collection of interdependent services deploying itself.
- Solution: Develop a low-level provisioning tool to deploy critical services independently, breaking dependency loops.
- Source code risk
- Problem: Many platform teams host critical code on Bitbucket, stored on a higher platform layer, e.g., Networking Terraform code.
- Solution: Build a low-level Git mirroring solution so code is available in recovery.
- Artefacts risk
- Problem: Compiled binaries, libraries, containers, and images are stored centrally on a higher level platform service, despite being needed by lower level services.
- Solution: Create a low-level mirroring system for artefacts.
- Builds risk
- Problem: In a recovery scenario, you may need to make code changes, such as new networking addresses, permissions, or AWS accounts. If you have access to source code and artifacts, how can you reliably build new copies of services? We want to avoid having service owners reinvent their build pipeline on their laptops during emergencies.
- Solution: Develop a low-level build system or eliminate dependencies from existing build systems.
- Logging
- Problem: Logging is needed to speed debugging in recovery for low-level services before production logging is available.
- Solution: Implement a low-level AWS-based Kinesis stream as a drop-in replacement for services, used only in emergencies.
- Configuration
- Problem: Atlassian’s Feature Flagging system has dependencies on a middle platform layer.
- Solution: Build a dynamic configuration system native to AWS for platform teams.
- Dependency monitoring
- Problem: How do we monitor, interact with, model, and update dependency data?
- Solution: Build a web tool to manage a dependency graph and generate reports displaying dependency information.
6. Source Control Pillar (SCP): Ensuring code availability in emergencies.
During fire drills, the networking team first faced issues re-provisioning the Atlassian Network, SharedVPC, or DNS (Layer 4 of the stack) because they used Infrastructure as Code ( Terraform), stored in Stash (Layer 17) or Bitbucket (Layer 36). This was one example where lacking source code access hindered platform teams.

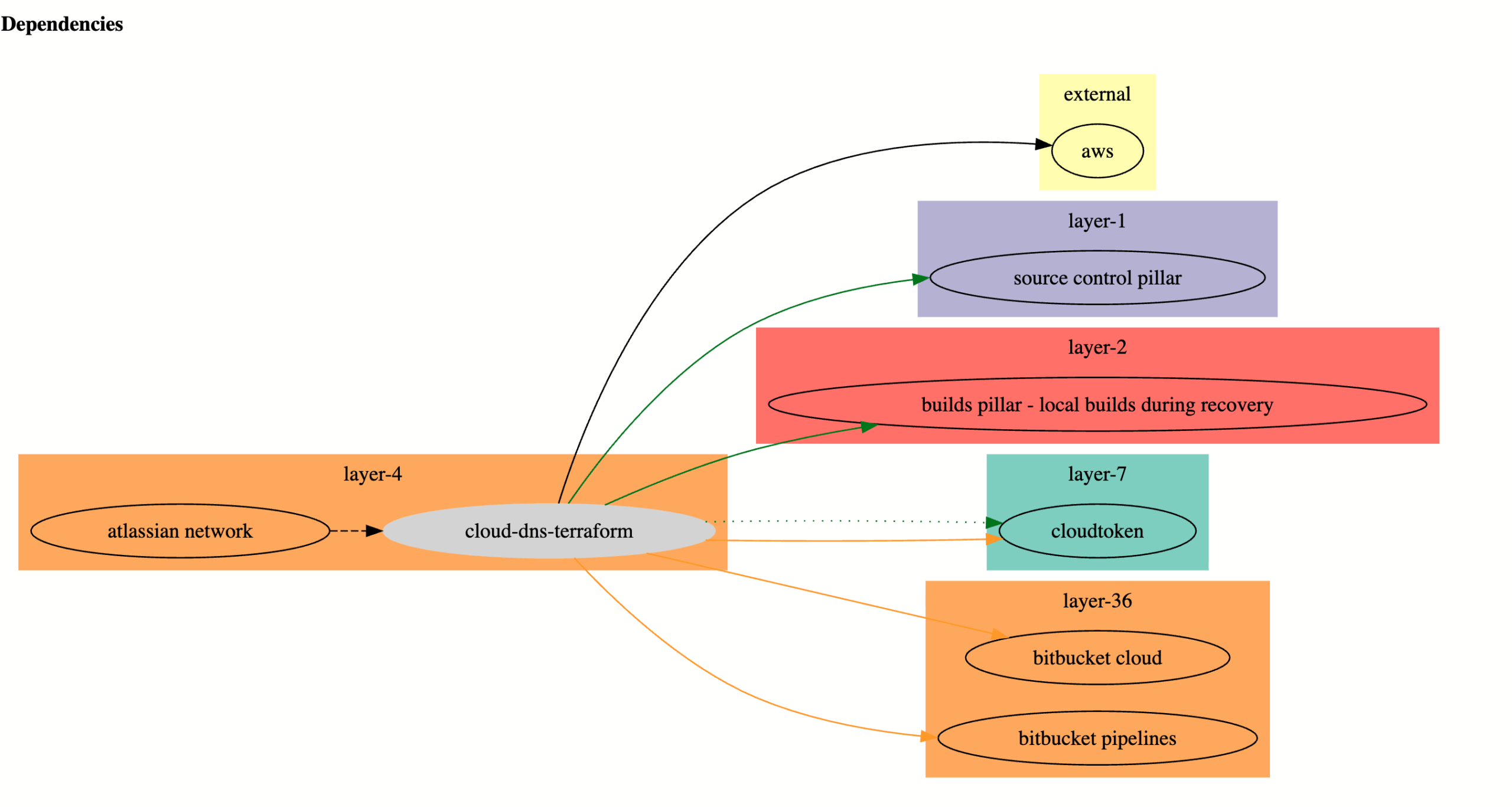
Hence a low layer mirroring system was built to replicate certain critical repositories to AWS Code commit. This automatic mirroring system was called the Source Control Pillar (SCP) and was built using AWS native technologies. Using raw AWS services avoids dependencies and operates at the lowest layer, complying with CPR guiding principles.

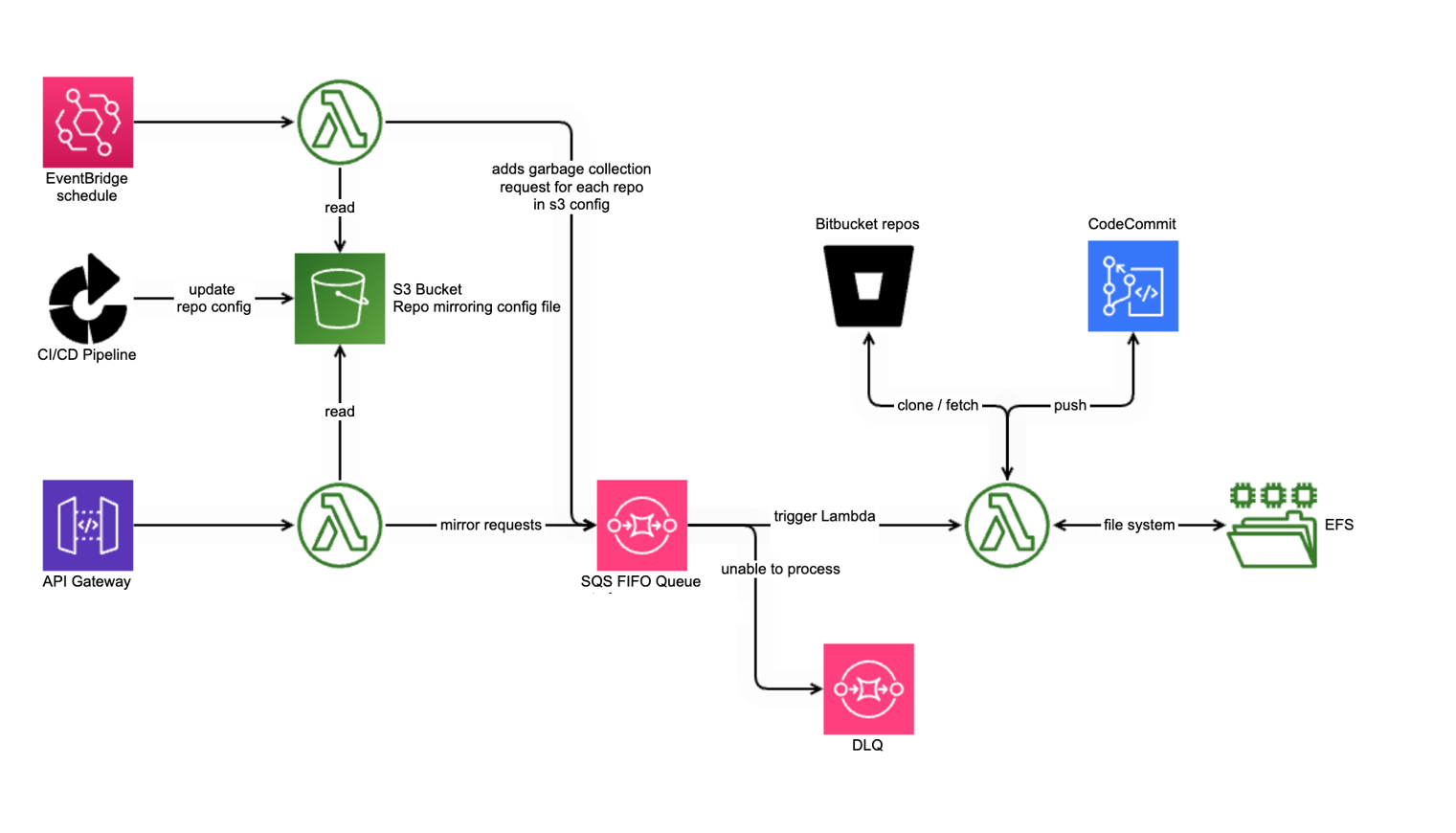
We enforced a guiding principle: use the low-level mirroring solution during normal operations. This ensured working code was available in emergencies because we used it daily.
The deployment process for services changed to:
- PR approved and merged in Bitbucket
- SCP triggered by web-hook and mirrors code to AWS Code Commit.
- Bamboo/Bitbucket pipelines build using code pulled from Code Commit.
Today, dozens of platform repositories use the Source Control Pillar.
7. Special project – Artifactory migration
We planned to address circular dependency concerns methodically, but some urgent risks required a immediate attention in the form of a special project:
The first was the Micros ↔︎ Artifactory tangle.
Artifactory is the system that stores and distributes artifacts for all of Atlassian. Its functionality includes:
- Stores and retrieves Docker images
- Stores and retrieves various packages, both internally built and externally cached, for building artifacts from source code
- Provides authentication and authorisation to control who can store or retrieve artifacts
- Handles all operations at large scale
Artifactory was deployed via Micros, and the Micros platform depended on Artifactory during deployment and runtime. As a result, if both Artifactory and Micros were down recovery was impossible.
We resolved this dependency by migrating Artifactory from Micros to Kubernetes. Now, if both fail, Kubernetes can recover Artifactory, which can then recover Micros.
We completed this migration over six months.
Atlassian’s Artifactory service can support upwards of:
- ~2.5 million requests per minute (~40,000 per second)
- 5 Gbps of network traffic
- 250-400 TB of objects downloaded daily
- 990 TB and 348 million objects being stored
Docker Mirroring: Artifacts Reliability Improvements
To improve Docker distribution reliability and remove Artifactory as a single point of failure, we developed a low-level AWS native distribution mirroring system (similar to Source Control Pillar) based on AWS ECR. Services pull from the mirror during normal operations.
8. Atlassian Platform Deployer (APD): Building a low-dependency provisioning system.
To untangle Micros and other low layer services a new low level provisioning system needed to be created. This is similar to and inspired by the existing Micros Orchestration system but with minimal dependencies, less features and a restricted customer base. At a high level this results in 4 provisioning systems used by Atlassian for different purposes.
- AWS Native – Provisioning via IaC such as Terraform or Ansible. Used by critical low-level platform systems such as Networking.
- APD – Provisioning via a service descriptor YAML file that abstracts AWS with a limited feature set. Used to run critical platform software services.
- Kubernetes – Provisioning via a Helm chart YAML file. Used for services requiring large compute fleets or additional isolation.
- Micros – Provisioning via a service descriptor YAML file that abstracts AWS and other resource types. Evolved over 10 years to handle most Atlassian provisioning, including Jira and Confluence. A managed service enforcing security, compliance, best practices, and boosting developer productivity.
APD-server is an API based webservice. It reads a service descriptor YAML file (like Micros) and provisions all AWS resources (EC2, RDS, Dynamo, SQS, S3, etc.) and alarms within APD itself without calling external services. This changed from Micros, which delegated resource provisioning to external services using a delegation protocol. While this allowed greater scaling and specialisation, it added dependencies and complexity.
APD was designed without a database, using AWS as the source of truth for simplicity and reliability. This worked because APD serves only a few platform services, so scalability was not a challenge.

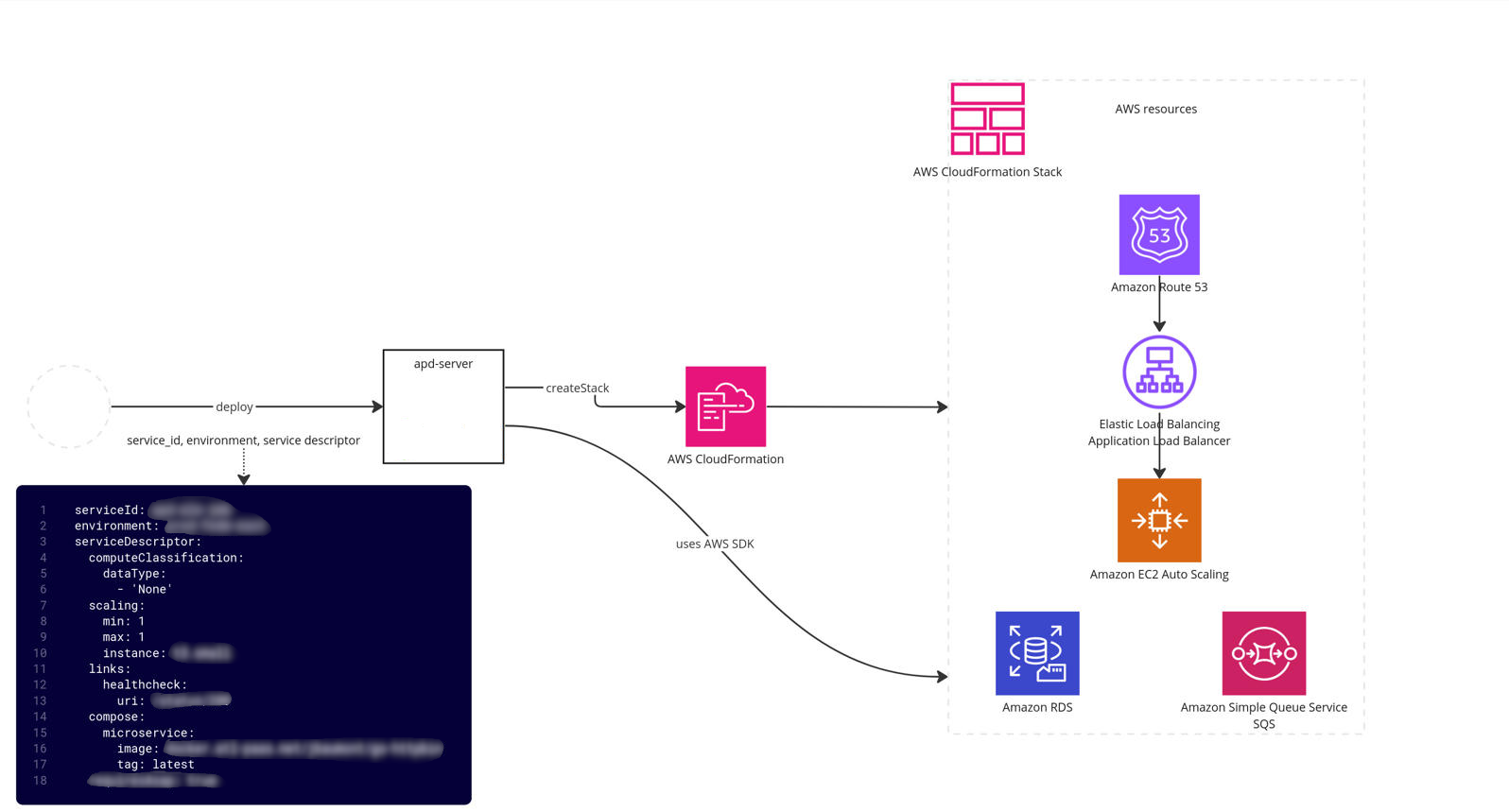
APD makes extensive use of CloudFormation as its deployment orchestration engine. It relies on CloudFormation custom resources to extend functionality— rather than defining everything within a single stack, it fans out into multiple layers of custom resource handlers, which may in turn create additional stacks. We use custom resource stacks even for standard AWS resources (e.g. S3, SQS) to add additional logic and standards when provisioning them.

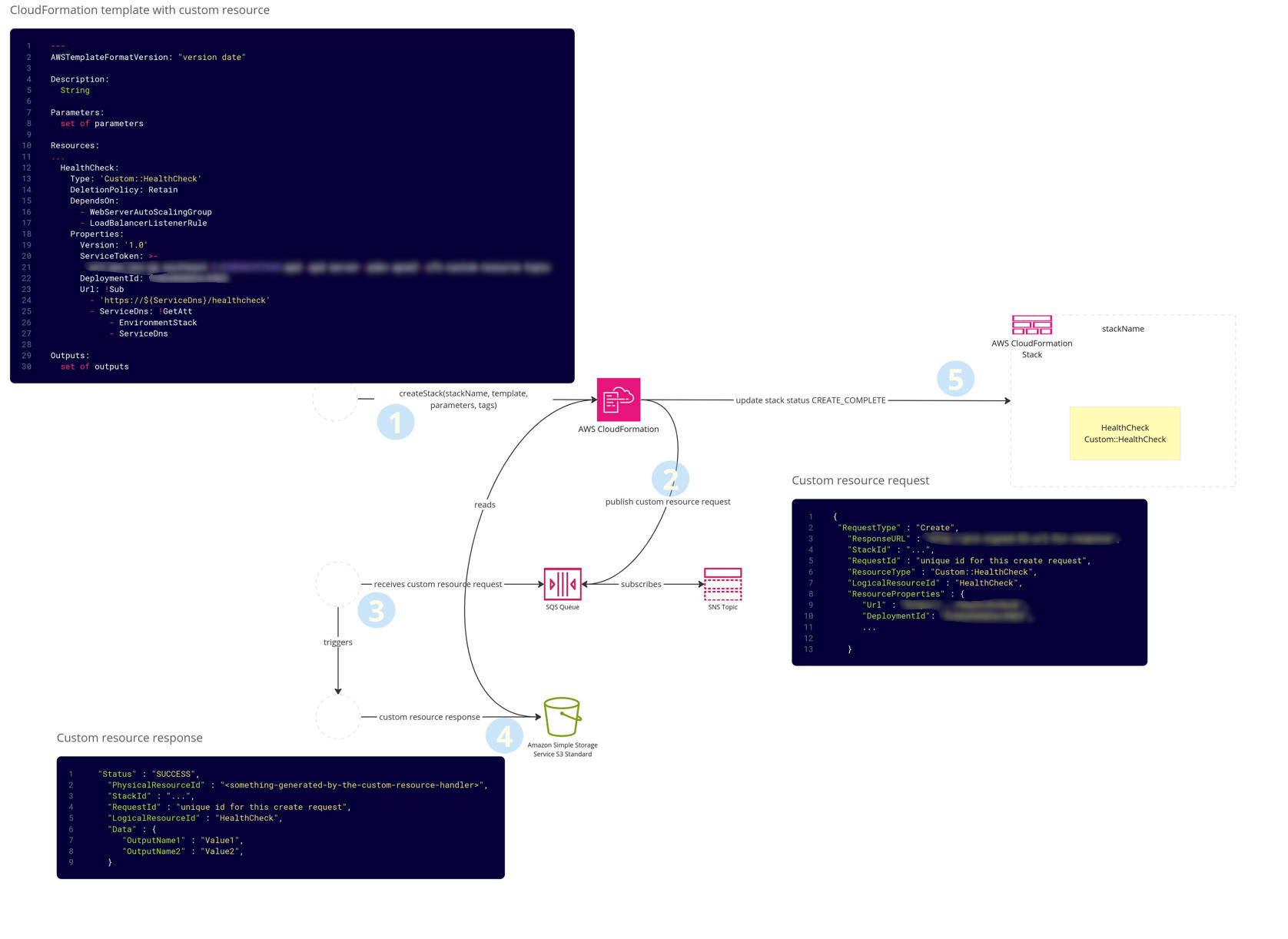
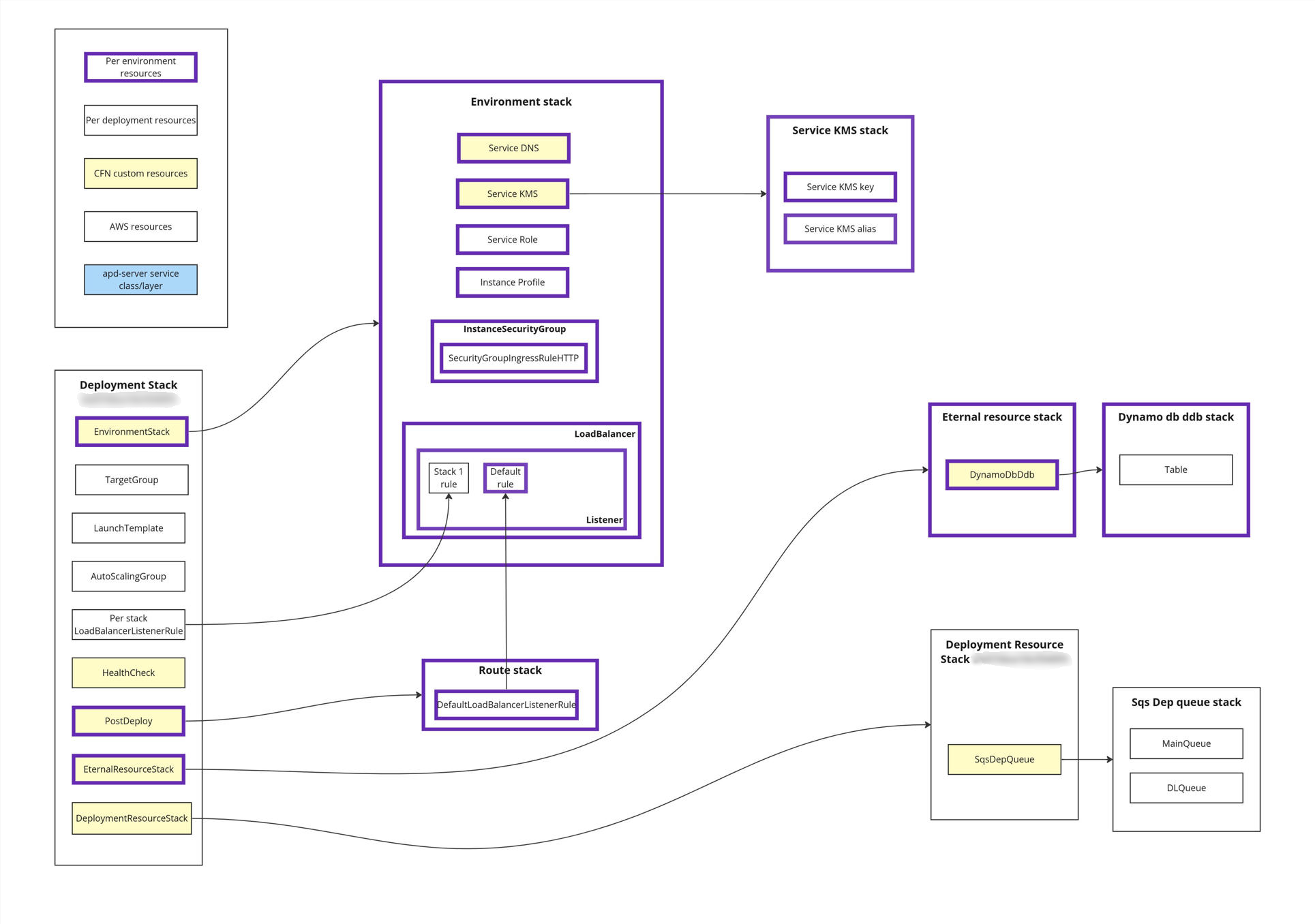
A single service ‘deployment’ consists of multiple CloudFormation stacks with different purposes.
- Deployment stack – per deployment compute resources (EC2). A new deployment stack is created for each deployment.
- Environment stack – generic persistent resources, e.g., security groups, ALBs.
- Route stack – contains ALB listener rules and identifies which deployment stack is active.
- Deployment Resource Stack – contains per deployment resources (non-persistent).
- Eternal Resource stack – contains persistent resources e.g. databases.
When you upgrade your custom software from v1.0 to v1.1 and trigger a new deployment, the following occurs.
- A new Deployment stack is created running v1.1 of your software.
- A new Deployment Resource Stack is created if needed.
- Environment Stack updates to reference the new deployment stack.
- Route Stack updates to redirect traffic from the old deployment stack (v1.0) to the new one (v1.1), using HTTP health checks.
- After a period, a cleanup job removes the old Deployment and Deployment Resource stacks.

To deploy APD itself raw Infrastructure as Code (IaC) is used.
9. Atlassian Government Cloud
As part of Atlassian Government Cloud (AGC) a new environment needed to be built. APD facilitated this and enabled a circular dependency free orchestration control plane in this new environment.
This also served as another validation that the platform could be recovered, since a new platform management plane needed to be created from scratch which would highlight where improvements had been made and where more work was needed.
CPR took a leading role in the AGC buildout, using previously gathered dependency data to define the service provisioning order for platform teams. As APD was the first major consumer of lower-layer systems like networking and auth, and then provisioned Micros and other platform services above them, CPR became a central hub of the build.
The end result leveraged the repeatable APD/CPR process and system and created the initial Atlassian Government Cloud environment.
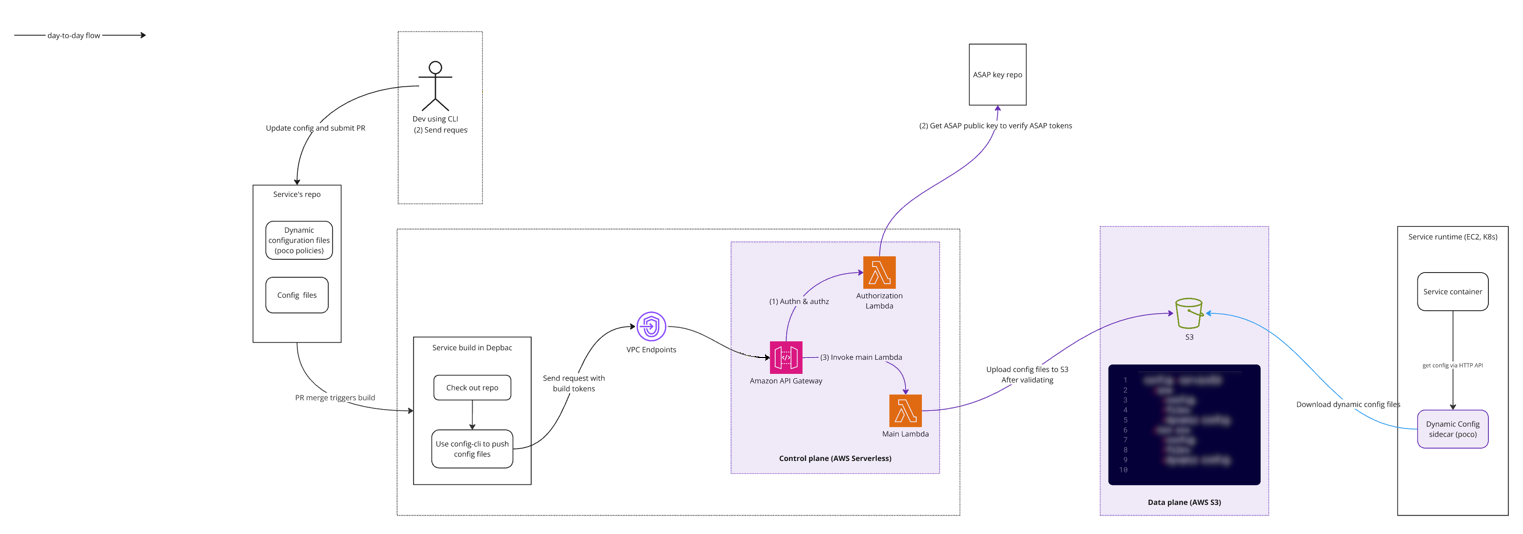
10. Config Pillar
Although Atlassian’s feature flagging / dynamic configuration solution was 3rd party provided it was combined with additional internal tooling that created a hard dependency on a number of components deployed on the Micros platform. In the event of a recovery scenario, these capabilities would not be available until after Micros itself was recovered. The loss of this dynamic configuration capability has the potential to further delay the recovery process, extending downtime for the Atlassian platform.
To address this, the CPR team built a low-dependency, AWS-native dynamic configuration system now adopted by many platform services. We used Open Policy Agent (OPA) as the decision agent powering configuration rules implementing policy as code. Config Pillar currently manages over 700 flags.

11. Monitoring dependency data
CPR created a web front end called the PaaS Dependency Visualisation System (PDVS) to display all platform dependency data. It shows how each Atlassian PaaS component connects to others and recommends component changes to remove tangles using tangle heat maps. It also supports model updates, versioning, and simulating changes for architectural adjustments. PDVS helps us decide if adding a dependency is acceptable.

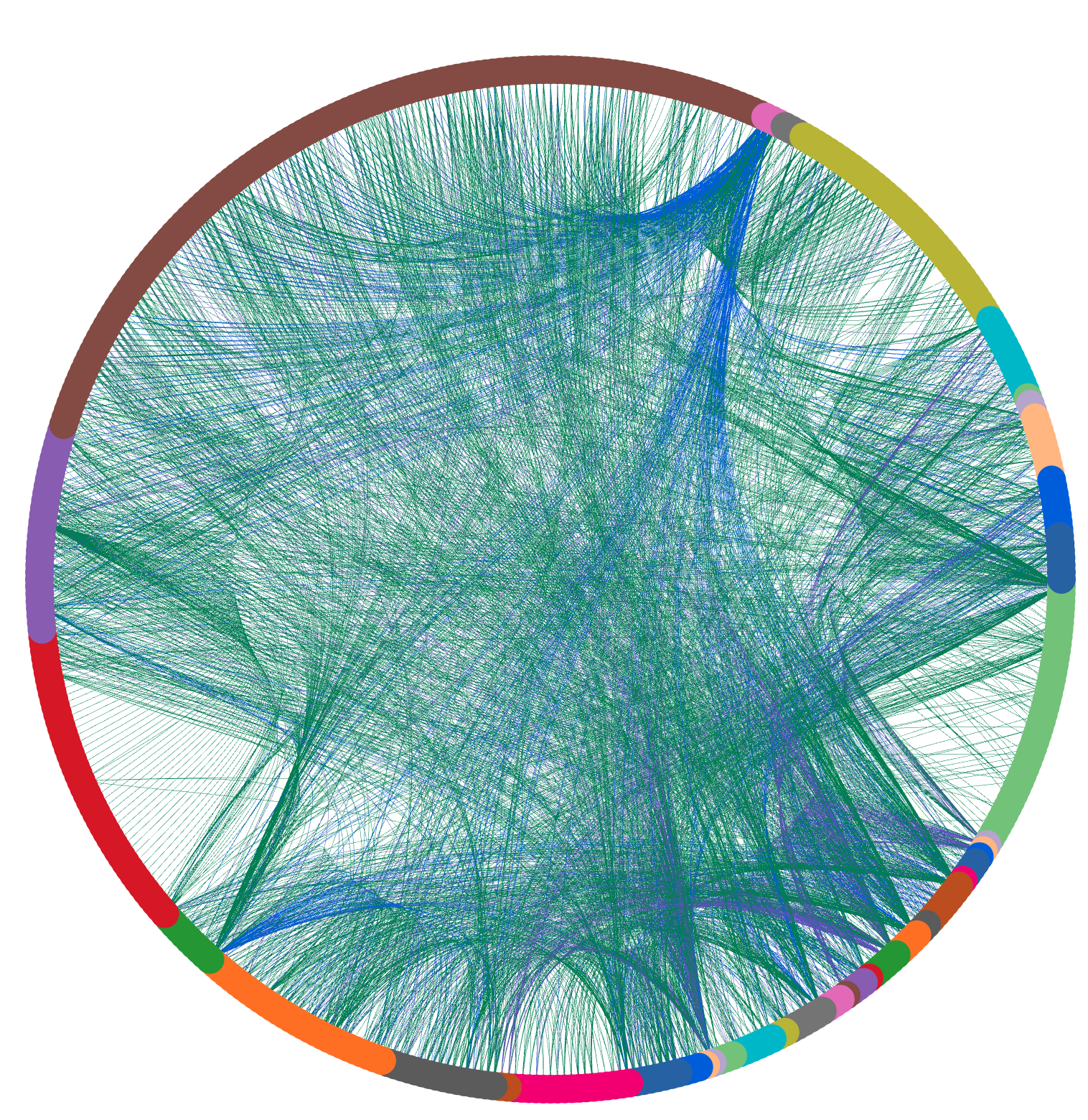

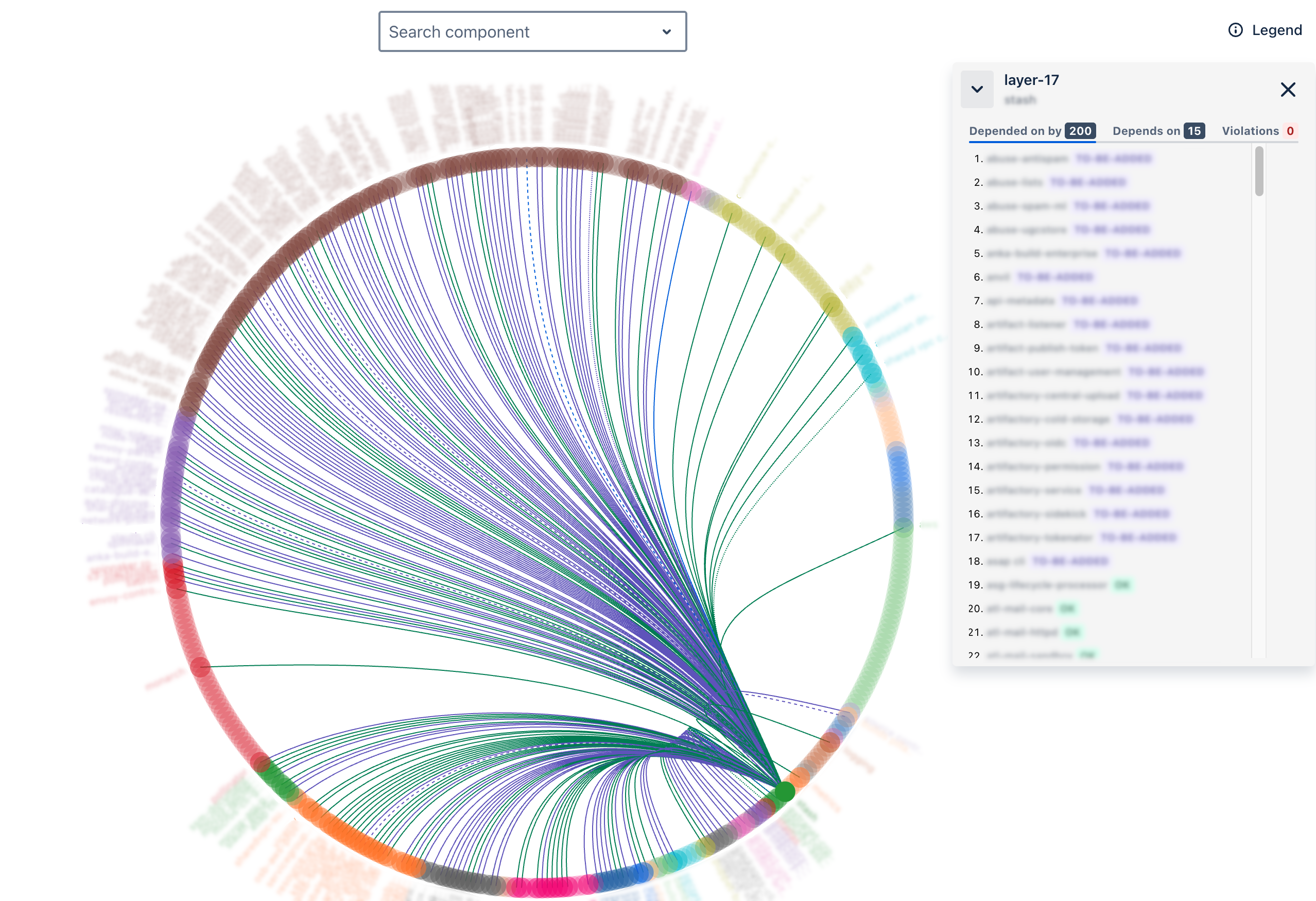




PDVS started with the survey dependency model and now incorporates VPC flow log dependency data (network traffic flows) to update the backend data model dynamically.


Additionally having a full view of the platform enables:
- Finding reliability mismatches e.g. Tier 0/1 services (critical & highly reliable) that have hard dependencies on Tier 3 services (less critical, lower reliability requirements).
- Improving resilience: Services that claim regional resilience but depend on services operating in a single region.
- Help to define cell boundaries: Understanding boundaries in a cell-based architecture is challenging. We can create a precise service tree for Jira and Confluence.
- Define SLAs: Establish the maximum reliability of a service based on the reliability of their dependencies.
12. Logging Pillar
The logging pillar is a key part of Atlassian’s log retention strategy during disasters. When the Observability logging pipeline is down, low-level platform services redirect logs to the logging pillar. This lets service teams access logs via CloudWatch in the AWS console, speeding platform recovery. Without it, low-level services facing issues would lack logs for debugging until observability services recover.
The logging pillar is mostly dormant, receiving a trickle of logs from synthetic tests to confirm functionality. It activates during disasters and uses a Kinesis stream with the same interface as the regular observability pipeline for easy replacement. We view the logging pillar like a fire extinguisher, mostly inactive and on standby, hoping never to use it.


13. Commercial migration: Moving critical services with minimal downtime.
After building and testing APD in FedRAMP we needed to migrate services running in the existing commercial boundary with existing customers. This included a many critical (Tier 0/Tier1) services with high uptime requirements and large blast radius.
This involves migrating HTTP traffic between AWS accounts and network subnets. We developed a Traffic Migration Proxy (TMP)—a simple Envoy-based HTTP proxy in the form of a sidecar for this scenario. The TMP sidecar was configured and deployed to the services deployed in Micros, enabling the routing of traffic from Micros to APD.
Persistent stores (Dynamo, S3, RDS) must also be synchronised between old and new accounts.

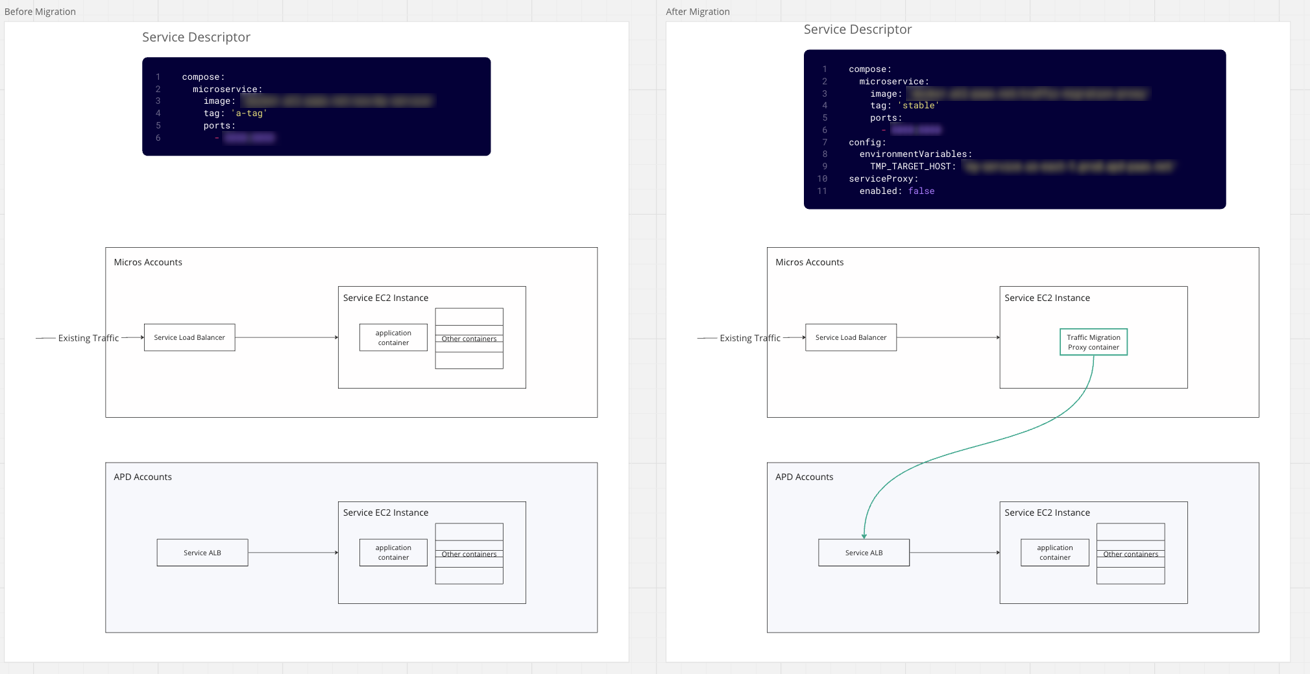
These migrations spanned multiple regions and environments and occurred in stages over several weekends. Service owners found these migrations straightforward because APD contracts were compatible with Micros, lowering migration costs and easing onboarding.
Micros migration to APD
Micros Server was one of the last services to migrate to APD, presenting challenges due to its broad impact, legacy architecture, and complex codebase.
To protect the platform during the migration, we divided the process into multiple phases over several months, carefully staging the rollout to minimise orchestration impact. This migration concluded successfully in July 2025.
14. Results & Impact
The CPR program was a multi-year cross-team effort that eliminated hundreds of circular dependencies, simplified the PaaS architecture, and enhanced platform reliability and recovery.
Systems built by the CPR program now underpin Atlassian’s cloud platform.
The CPR program reflects Atlassian’s ongoing commitment to reliability and proactive risk management.