
Redefining Automated Research with Adaptive Intelligence
When we introduced Rovo Deep Research in June, we focused on a simple promise: give every team an AI researcher that can connect the dots across Atlassian and SaaS apps, and deliver cited, executive‑ready reports in minutes. Since then, teams have been using Deep Research for increasingly complex, high‑stakes questions.
Deep Research proved that an AI teammate could turn scattered knowledge into grounded, executive‑ready reports. But as usage grew, new opportunities to make it better quickly became apparent.
What’s New?
As we evaluated Deep Research on real‑world tasks, a clear pattern emerged: many reports were technically accurate but too shallow, missing nuance and alternative angles. We also saw that the single‑turn, “fire‑and‑forget” workflow left little room for users to steer the process if the initial research plan wasn’t quite right. Deep Research v2 addresses these gaps by rearchitecting the workflow to resemble how humans actually research—iteratively searching, synthesizing, and revising as new evidence emerges—and by making the experience more steerable through multi-turn interactions.
Research questions were sometimes too vague for a single‑shot answer
Teams often came in with open-ended prompts, such as “Help me understand our AI strategy risks” or “What are the biggest gaps in our incident process?” Before doing any serious research, a human analyst would ask follow‑up questions: Which product? Which timeframe? Which audience? Deep Research v2 makes that explicit. It starts by clarifying the brief—asking targeted questions to pin down scope, constraints, and success criteria—so the research reflects what the user actually cares about, not just what they typed first.
The v1 workflow was too rigid once the plan was wrong
In v1, research was effectively “fire and forget”: Rovo built a plan, ran with it, and only showed you the result at the end. If the initial plan missed the mark, there was no good way to intervene mid‑flight. In v2, the research plan becomes a shared artifact. Rovo proposes a structured plan and explicitly asks the user to accept it or propose changes—editing sections, priorities, or angles—before any heavy research runs. That keeps users in the loop and lets them correct course early instead of starting over.
Reports needed more depth and stronger insight
Our evaluations showed that while reports were often accurate, they weren’t always comprehensive or insightful enough for big decisions. Deep Research v2 is designed to dig deeper: spending more time where it matters, comparing perspectives, and identifying patterns, risks, and recommendations—not just summarizing sources. The goal is to produce reports that not only answer the question but also help teams think more effectively about what to do next.
Enterprise knowledge alone wasn’t always enough
In many cases, teams needed more than what lived inside their Atlassian products and connected SaaS tools. Strategy work, market scans, and technology evaluations often depend on public benchmarks, vendor documentation, research papers, or news. Deep Research v2 introduces the ability to draw from the public web (alongside internal knowledge) when appropriate, so users can ground their reports in both what their organization knows and what the broader world is saying. This makes Deep Research more useful for end‑to‑end questions where the best answer lives at the intersection of internal context and external signal.
New Architectures
Deep Research v2 marks a transformative leap in automated research systems, moving beyond the rigid, one-size-fits-all pipelines of earlier generations. At its core, v2 introduces adaptive intelligence, orchestrated by a central agent powered by large language model (LLM) reasoning. This orchestrator analyzes each incoming query in the context of the full conversation and intelligently routes it—simple questions receive instant answers, while complex research requests trigger multi-step, iterative investigations.

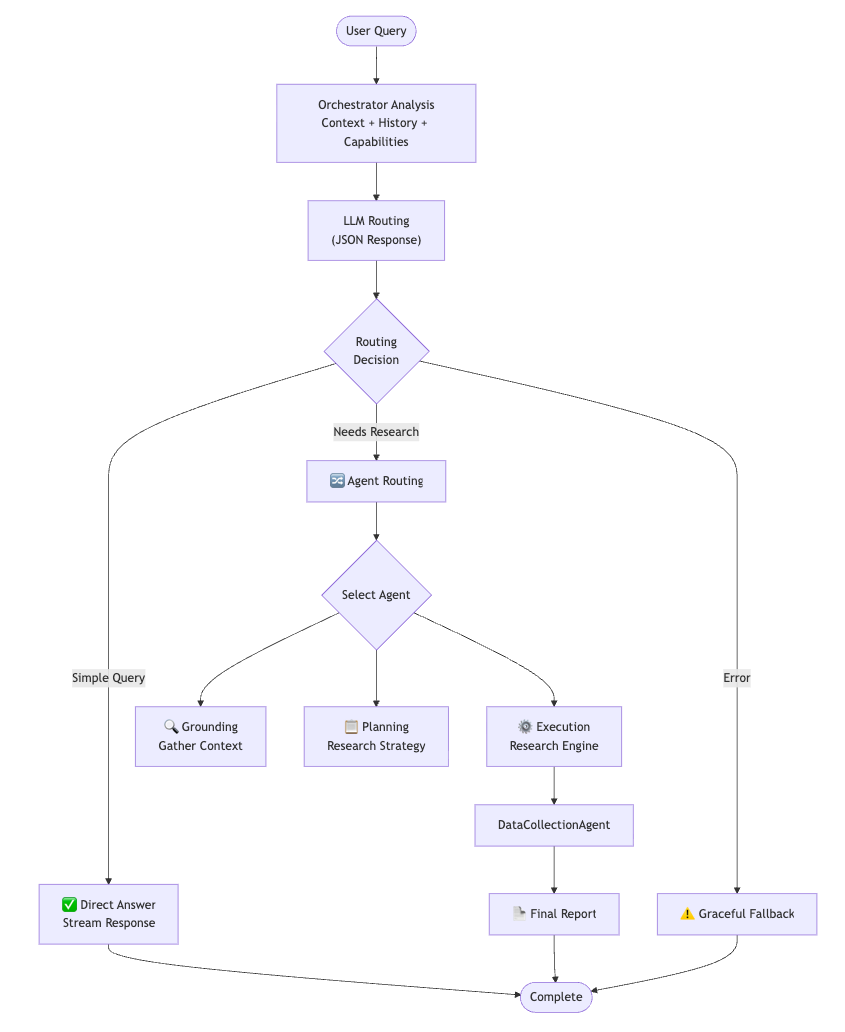
Adaptive Orchestration: From Query to Report
The heart of the system is the orchestrator agent. Unlike traditional systems that force every query through the same sequence of stages, the orchestrator dynamically constructs a prompt that includes user context, conversation history, and the capabilities of specialized agents. It then produces a structured, machine-readable response that determines whether to answer directly or delegate to a specialized agent.
This context-aware routing ensures that each research request is handled with the right level of depth and nuance. For straightforward queries, users get immediate responses. For more complex needs, the orchestrator delegates to a suite of specialized agents—Grounding, Planning, and Execution—each responsible for a distinct phase of the research process.
Specialized Agents and Iterative Research
- Grounding Agent: Collects contextual information by investigating the user’s environment before formulating clarification questions.
- Planning Agent: Translates research objectives into structured, step-by-step plans.
- Execution Agent: Conducts the actual research, leveraging parallel query execution and iterative refinement.
The Execution Agent is where Deep Research V2’s most innovative features come to life:
- Self-Evolution Engine: Drives an iterative research loop, evolving queries based on discoveries and intelligently determining when research is complete.
- Dynamic Outline Optimization: Continuously refines the report structure as new evidence emerges, ensuring findings are organized coherently.
- Memory Bank Writing: Constructs a memory bank of sources for each section and claim, enabling traceable reports where every claim links back to its source.
- Test-Time Diffusion: Treats the initial draft as “noise” and systematically denoises it through targeted, prioritized research, ensuring gaps are filled and claims are verified.
Parallelism, Traceability, and Robustness
Deep Research v2 executes research queries in parallel, dramatically accelerating the process while maintaining meticulous source attribution. The Memory Bank system ensures every claim in the final report is traceable to its original evidence, supporting transparency and auditability.
Configuration and Observability
Every aspect of Deep Research v2 is configurable—teams can tune models, execution parameters, and feature flags without code changes. This flexibility supports A/B testing, gradual rollouts, and context-specific optimizations. Comprehensive observability is built in, with structured logging, latency metrics, and token usage monitoring, enabling continuous improvement and cost management.
Async Execution
Deep Research jobs can be long‑running and intensive, so in v2, we moved them off the main web request path into an async execution system. When you start Deep Research, the web server hands the work to a pool of background workers via a lightweight queue, then simply streams back updates as the workers make progress. This lets the research engine do all of its planning, research, and synthesis in the background, while the chat experience still feels live and responsive.
Deep Research is also more resource‑intensive than a typical Rovo Chat query, so isolating it on separate worker nodes is important for scalability and reliability. By running these jobs in parallel on a dedicated worker fleet, we can prevent Deep Research from monopolizing CPU and memory on the web servers, which protects other Rovo Chat usage from slowdowns and instabilities. It also lets us scale and tune the worker pool independently, so we can handle spikes in Deep Research demand without impacting the rest of the system.
On top of that, we added reconnectable streaming so long research sessions survive real‑world conditions. If your network drops, your browser crashes, or you switch devices, you can simply reconnect to the same Deep Research run and keep streaming from where you left off. This reduces the impact of transient network errors and makes Deep Research feel like a durable, cross‑device workflow.
Evaluation Strategy, Metrics & Results
I. Reference-Based Evaluation Strategy
Report – RACE Framework (details)
To evaluate how well our deep research product performs in realistic scenarios, we primarily rely on the RACE framework, a recent and rigorous benchmarking methodology for long-form research. RACE evaluates each report along four dimensions: Comprehensiveness, Insight, Instruction Following, and Readability.
- Comprehensiveness captures whether the report covers all key areas, provides a complete picture of the topic, and avoids omitting major points.
- Insight assesses whether the report goes beyond surface-level facts to explain causes, impacts, and trends, and whether it provides useful, non-obvious perspectives.
- Instruction Following measures how faithfully the report follows the research brief and how directly it answers the user’s questions.
- Readability reflects how clearly the report is structured, how logically it flows, and how easy it is for stakeholders to digest.
A key strength of RACE is that it does not apply a single fixed rubric. Instead, it dynamically generates task-specific weights and detailed criteria based on the query, tailoring the evaluation to what “good” looks like for that particular task.
Example: Query-Specific Weighting and Criteria
Consider the following query:
“Write a paper to discuss the influence of AI interaction on interpersonal relations, considering AI’s potential to fundamentally change how and why individuals relate to each other.”
For this task, RACE allocates the following weights:


Below is an example of the generated rubric for the Insight (40%) dimension:


Benchmarks
We benchmark our product on both public and internal datasets to ensure strong performance in open, competitive environments as well as realistic enterprise workflows.
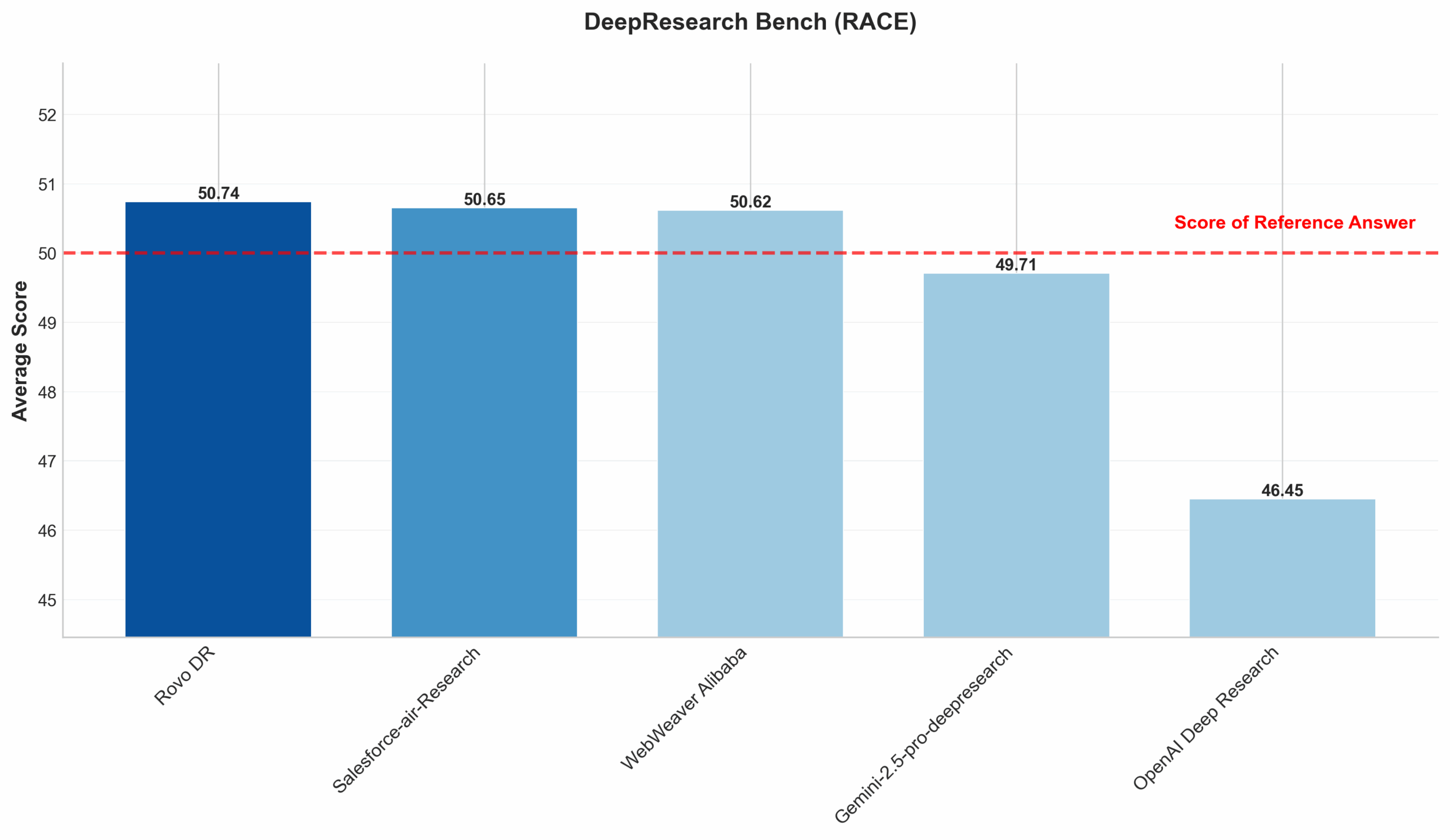
Public Benchmark – DeepResearch Bench
We use DeepResearch Bench, a public benchmark designed specifically for evaluating deep research systems in an open setting. It consists of 100 PhD-level research tasks authored by domain experts and is intended to support fair comparison between deep research products.
On this benchmark, our current score is 50.74, which places us at #4 on the leaderboard.
Leaderboard URL: https://huggingface.co/spaces/muset-ai/DeepResearch-Bench-Leaderboard

Internal Benchmark – Enterprise Reports
To capture how deep research is actually used inside enterprises, we maintain an internal benchmark derived from high-quality reports in our internal Confluence space. We apply reverse prompt engineering to transform these reports into realistic research questions that reflect core enterprise use cases, including:
- Market and competitive analysis (e.g., “What recent market and talent trends should Atlassian be aware of in Q4 FY25, and how might these trends impact our recruiting and business strategy?”)
- Quarterly and executive summaries (e.g., “Provide a comprehensive summary and analysis of Atlassian’s Q1 FY26 State of Atlassian, including founder perspectives, company-level OKRs, major customer wins, progress and challenges in key transformation areas, and updates across product collections. Highlight significant business, product, and organizational developments, and discuss how Atlassian is positioning itself for the future, especially regarding AI and cloud leadership.”)
- Other executive-ready reports that mirror real stakeholder deliverables.
We then evaluate model-generated reports on this dataset using the RACE framework. Our current RACE score is 62.72. Since scores above 50 indicate performance better than the human-written reference, this implies that our generated reports are already substantially higher quality than the original human reports on this benchmark.
By combining a state-of-the-art public benchmark with an enterprise-focused internal dataset, our evaluation strategy captures both industry-standard performance and how customers actually use deep research in day-to-day work.
Summary of Reference-Based Benchmarks


II. Reference-Free Evaluation Strategy
Side-by-Side Evaluation
In addition to reference-based benchmarks, we also run reference-free, side-by-side evaluations against competitor deep research products. For each research task, we:
- Generate a report using our product.
- Generate a competing report (e.g., ChatGPT Deep Research).
- Compare the two outputs using an LLM-judge–based win / tie / lose framework.
This setup simulates realistic decision-making: it estimates how often users or judges would prefer our reports over alternatives when viewing the outputs side by side.
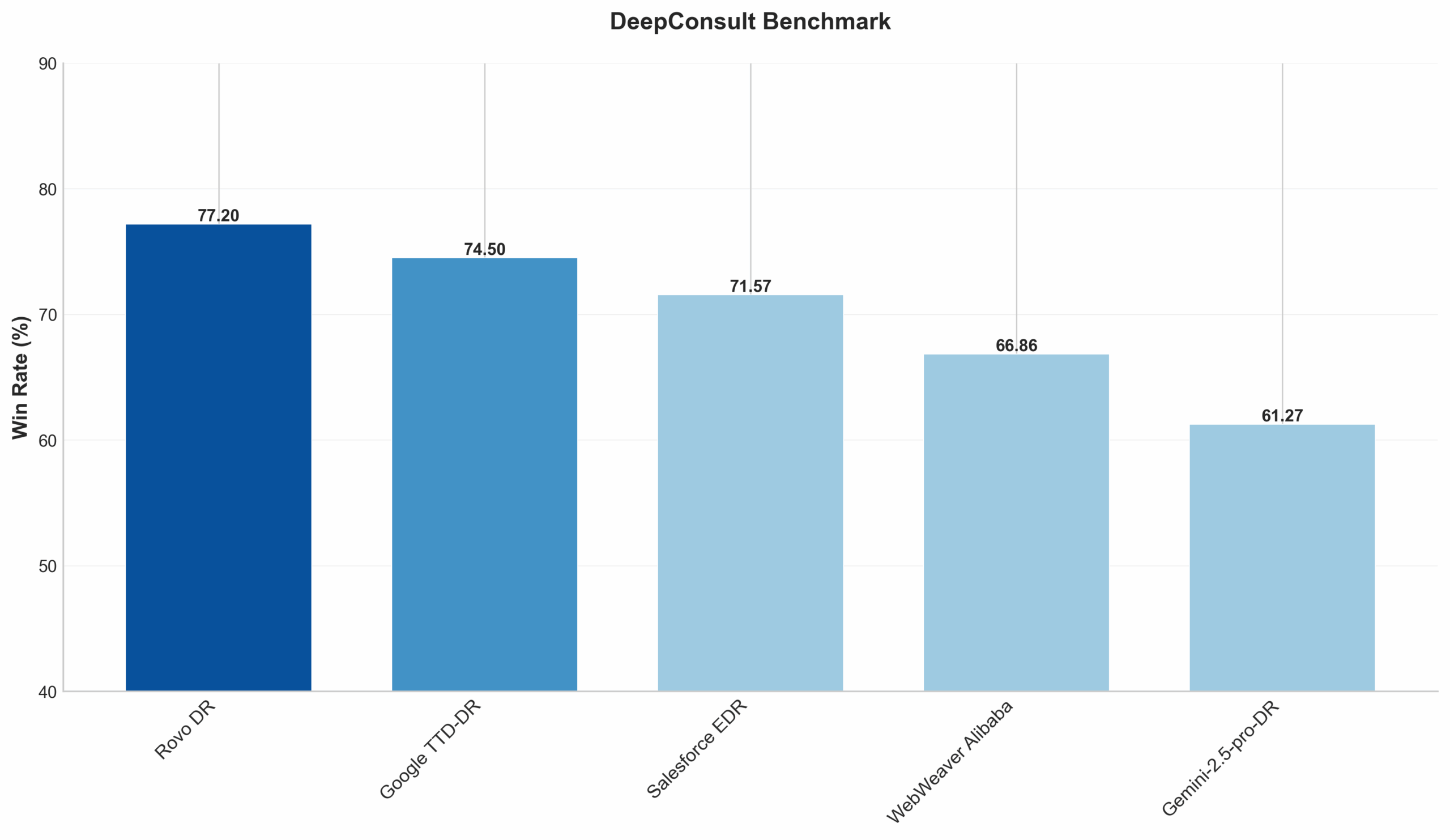
DeepConsult Evaluation
We leverage DeepConsult, which contains a broad set of consulting-style tasks such as market analysis, investment opportunities, industry evaluations, financial modeling and assessment, technology trend analysis, and strategic business planning.
Using this dataset, we compare our deep research product against ChatGPT Deep Research in a side-by-side setting, with LLM judges selecting the preferred output.
Quality Comparison Summary


In other words, in side-by-side evaluations on DeepConsult, our reports achieve a 77% win rate against ChatGPT Deep Research, indicating that LLM judges prefer our outputs most of the time.
What’s next for Deep Research
Deep Research v2 is our new baseline, not the finish line. Our roadmap is shaped directly by how people use Deep Research today and feedback from our users.
- More expert‑level, actionable recommendations – Users don’t just want information—they want help deciding what to do. We’re focusing on deeper synthesis and gap‑finding, so reports highlight trade‑offs, propose concrete options, and surface next steps rather than stopping at a well‑organized report.
- Stronger factual accuracy signals and guardrails – We’re investing in a dedicated factual accuracy metric and improved citation-quality metrics, so we can systematically track whether key claims are actually supported by their sources. This work helps us catch hallucinations earlier, identify regressions, and refine the research workflow to favor grounded, well-cited answers over confident but unsupported ones.
- Clearer, more readable reports – We’re making Deep Research outputs easier to skim, share, and act on. That includes integrating with Atlassian Document Format (ADF) to add richer visual structure and components, bringing in data analysis so insights can be shown as charts and plots (not just text or tables), and steadily improving the writing itself so reports are more information‑dense and easy to digest.
References:
How Rovo Deep Research works – Work Life by Atlassian How Rovo Deep Research works
Introducing Rovo Deep Research, grounded on your data – Work Life by Atlassian