Статьи
Обучающие материалы
Интерактивные руководства
Мониторинг DevOps
Повышение осведомленности на каждом этапе конвейера поставки

Кришна Сай
Технический руководитель, ИТ-решения
С применением методологии DevOps можно ожидать ускорения разработки, регулярного тестирования и более частых релизов. При этом повышается качество и сокращаются расходы. Инструменты мониторинга DevOps обеспечивают автоматизацию, расширенные измерения и высокую прозрачность на протяжении всего цикла разработки: от планирования, разработки и интеграции до тестирования, развертывания и эксплуатации.
Сегодня цикл разработки программного обеспечения стал еще короче благодаря тому, что несколько этапов разработки и тестирования выполняются одновременно. Это привело к появлению DevOps и переходу от разрозненных команд разработчиков, тестировщиков и специалистов по эксплуатации к единой команде, которая выполняет все функции и действует по принципу «кто разработал, тот и поддерживает».
Поскольку частые изменения кода стали нормой, командам разработчиков необходим мониторинг DevOps, который позволяет получать полное представление о рабочей среде в режиме реального времени.
Что такое мониторинг DevOps?
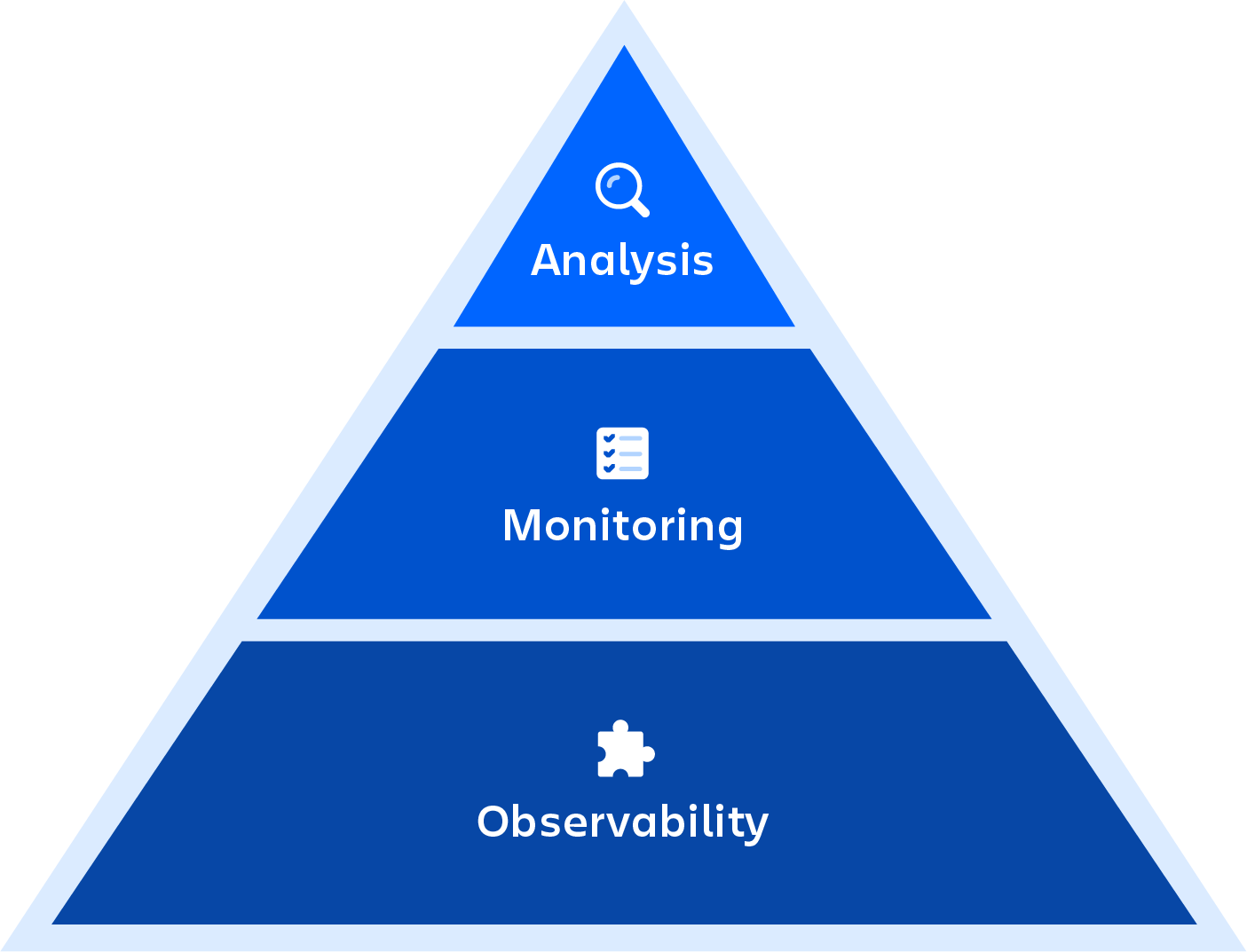
Мониторинг DevOps подразумевает контроль всего процесса разработки: от планирования, разработки и интеграции до тестирования, развертывания и эксплуатации. При этом в режиме реального времени можно осуществлять всестороннее наблюдение за состоянием приложений, служб и инфраструктуры в рабочей среде. Среди критически важных компонентов мониторинга приложений и служб — такие возможности, как потоковая передача данных в реальном времени, воспроизведение истории и визуализация.
см. решение
Оптимизация управления инцидентами и реагирования на них
Связанные материалы
Подробнее об инструментах DevOps
Мониторинг DevOps позволяет командам быстро и автоматически реагировать на любое ухудшение качества обслуживания клиентов. Что еще более важно, команды могут выполнять «сдвиг влево» к более ранним этапам разработки и сводить к минимуму неудачные изменения в рабочей среде. В качестве примера можно привести усовершенствованные средства контроля для выявления ошибок в ПО и реагирования на них как вручную (система дежурств), так и по возможности автоматически.
Мониторинг DevOps и возможности наблюдения
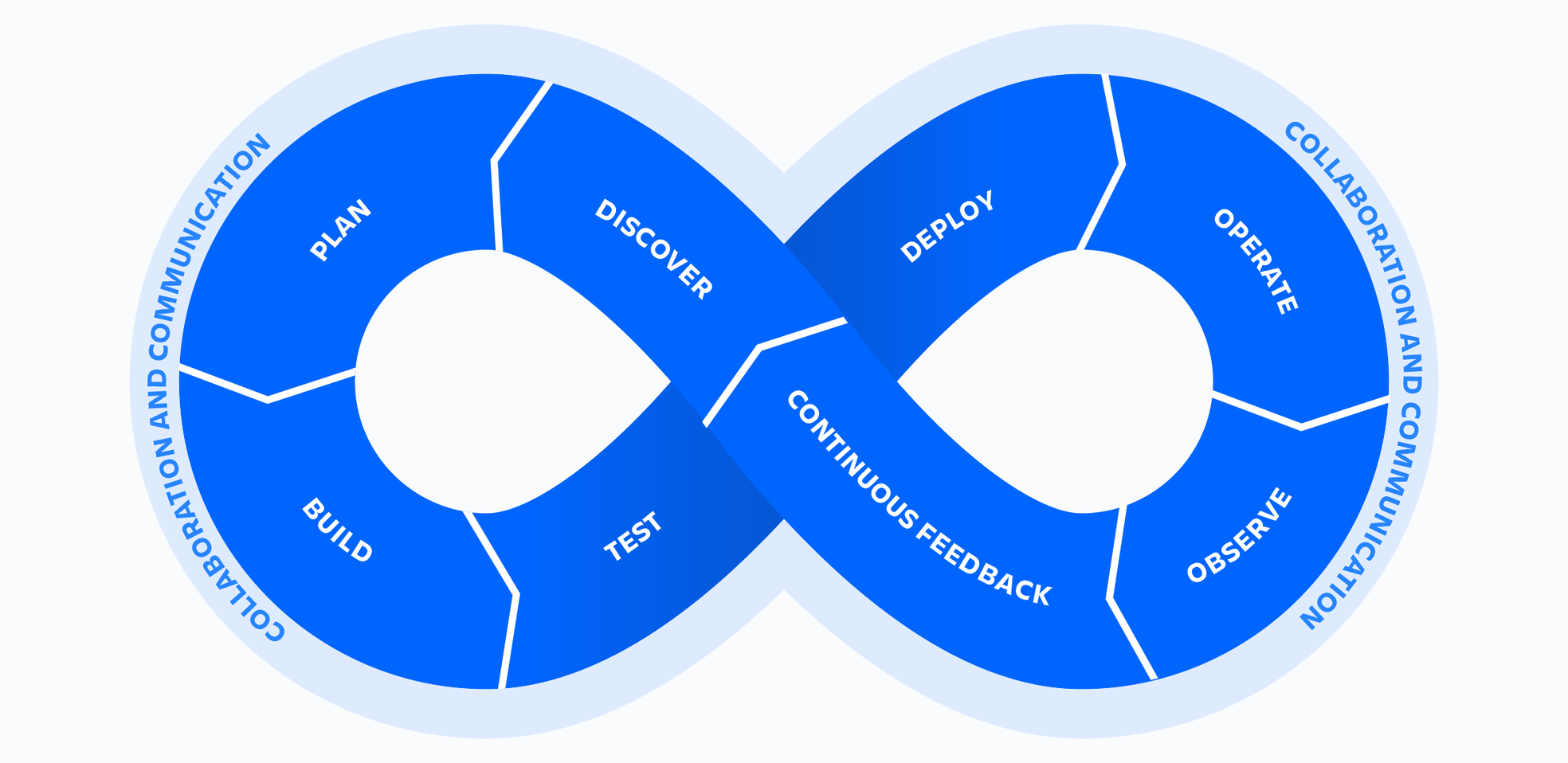
Если соотносить левую сторону бесконечного цикла с продуктом, а правую — с его эксплуатацией, менеджер по продукту, который вводит в разработку новую возможность, заинтересован в том, чтобы понимать, на какие задания и пользовательские истории можно разбить весь проект. Разработчику в левой части проекта необходимы сведения, которыми он будет руководствоваться при разработке возможности: он должен видеть заявки проекта, пользовательские истории и зависимости. Если разработчики придерживаются принципа DevOps «кто разработал, тот и поддерживает», они также заинтересованы в устранении инцидентов.
Что касается операционной части цикла разработки, инженеру по техническому обеспечению надежности сайта необходимо понимать, какие службы можно измерять и контролировать, чтобы устранять ошибки в случае их возникновения. Без пакета инструментов DevOps, объединяющего процессы, среда становится хаотичной и несогласованной. При наличии хорошо интегрированного пакета инструментов процесс разработки легко отследить.
Важность мониторинга DevOps
Подход DevOps предполагает непрерывный мониторинг в промежуточной и тестовой средах, а также в среде разработки. Тому есть множество причин.
Частые изменения кода требуют прозрачности
Частые изменения кода, вызванные непрерывной интеграцией и развертыванием, ускорили процесс изменений и усложнили рабочие среды. С переносом микрослужб и внешних микроинтерфейсов в современное облако, в рабочей среде стали выполняться сотни и даже тысячи задач, которые предъявляют разные операционные требования к масштабированию, задержке, избыточности и безопасности.
В связи с этим возникла потребность в повышенной прозрачности. Командам необходимо не только выявлять ухудшение качества обслуживания клиентов и реагировать на него, но и делать это своевременно.
Автоматизация совместной работы
Подход DevOps по умолчанию предполагает более тесное взаимодействие разработчиков с операционными и бизнес-командами. Однако неинтегрированные инструменты могут стать препятствием для взаимодействия и затруднить координацию команд — таковы главные выводы по результатам опроса о DevOps, проведенного Atlassian.
Автоматизировать совместную работу можно с помощью такой методики, как получение целостного представления о конвейере разработки в редакторе. Кроме того, можно настроить правила автоматизации, которые будут реагировать на коммиты или запросы pull, обновлять статус связанных задач Jira и отправлять сообщения в канал команды в Slack. Можно также воспользоваться преимуществами аналитики: отчетами о сканировании, тестировании и другими аналитическими отчетами.
Эксперименты
Доработка продуктов в соответствии с потребностями клиентов, обусловленная оптимизацией воронок конверсии и персонализацией, приводит к постоянным экспериментам. В рабочих средах могут проводиться сотни экспериментов и действовать сотни флажков возможностей, поэтому системы мониторинга не всегда способны выявить причину ухудшения качества.
Из-за растущих требований к непрерывно работающим службам и приложениям, а также строгих обязательств, указанных в SLA, приложения могут становиться более уязвимыми. Командам разработчиков необходимо определить отслеживаемые целевые уровни обслуживания (SLO) и индикаторы уровня обслуживания (SLI), на основе которых будет выстроена работа.
Управление изменениями
Поскольку именно изменения вызывают большинство перебоев в работе, необходимо наладить управление изменениями. Это особенно актуально для критически важных приложений, например используемых в сфере здравоохранения или финансовых услуг. Риски, связанные с изменениями, требуют оценки, а процессы подтверждения — автоматизации в зависимости от уровня риска.
Для преодоления этих трудностей необходимо комплексное понимание и стратегия мониторинга. Следует определить и принять методики мониторинга, а также внедрить расширенный набор гибких и передовых инструментов мониторинга, критически важных для процессов разработки.
Мониторинг зависимых систем
Сегодня все большее распространение получают распределенные системы, состоящие из небольших служб. Теперь командам необходимо не только следить за системами, которые разрабатывают они сами, но и заниматься мониторингом и управлением производительностью и доступностью зависимых систем. Платформа Amazon Web Services (AWS) предлагает более 175 продуктов и служб, в том числе инструменты для вычислений, хранения и сетевой работы, инструменты баз данных, аналитики, развертывания, управления и разработки, а также решения для мобильных устройств. При создании приложения с помощью AWS, вам нужно будет выбрать службу, соответствующую потребностям вашего приложения. Вам также понадобятся средства контроля и стратегии для распределенного отслеживания ошибок и устранения сбоев в зависимых системах.
Ключевые возможности мониторинга DevOps
Согласно принципам DevOps для разработки и внедрения стратегии мониторинга следует также позаботиться об основных методиках и наборе инструментов.
Тестирование со сдвигом влево
Тестирование со сдвигом влево, выполняемое на ранних этапах цикла разработки, позволяет повысить качество продукта, сократить время циклов тестирования и количество ошибок. Командам DevOps важно использовать методики тестирования со сдвигом влево для оценки работоспособности предпроизводственных сред. Тестирование со сдвигом влево предполагает, что мониторинг осуществляется часто и на ранних этапах, что помогает обеспечить непрерывность разработки и сохранить качество оповещений. Тестирование и мониторинг должны выполняться параллельно; ранний мониторинг позволяет оценить поведение приложения при осуществлении основных транзакций и сценариев взаимодействия пользователя. Этот подход также позволяет выявить проблемы производительности и доступности до начала развертывания в рабочей среде.
Управление оповещениями и инцидентами
В мире облачных решений инциденты возникают так же часто, как и баги в коде. Среди них — неполадки оборудования или сети, неверная конфигурация, нехватка ресурсов, несогласованность данных и баги в программном обеспечении. Чтобы реагировать на такие инциденты, команды DevOps должны принять методики работы с инцидентами и внедрить качественные средства мониторинга.
Вам помогут следующие рекомендации.
- Создайте культуру совместной работы, в рамках которой параллельно с автоматическим функциональным тестированием и тестированием возможностей во время разработки также проводится мониторинг.
- Во время разработки включайте в код соответствующие высококачественные оповещения, которые позволят свести к минимуму среднее время до обнаружения (MTTD) и среднее время до изолирования (MTTI).
- Создайте средства мониторинга для обеспечения надлежащей работы зависимых служб.
- Выделяйте время на создание необходимых дашбоардов и обучение участников команды работе с ними.
- Планируйте «боевые игры» для служб, чтобы проверить работу системы мониторинга и определить недостающие элементы.
- Планируйте в рамках спринтов выполнение необходимых действий по итогам предыдущих разборов инцидентов, особенно восполнение недостающих элементов мониторинга и автоматизации.
- Создавайте детекторы для обеспечения безопасности (обновления/исправления/последовательные обновления учетных данных).
- Поддерживайте принцип «измерять и отслеживать все» и автоматизируйте реагирование на оповещения.
Инструменты мониторинга DevOps
Дополнением к набору эффективных методик мониторинга могут стать передовые инструменты, которые соответствуют культуре DevOps и принципу «кто разработал, тот и поддерживает». Необходимо определить и внедрить средства мониторинга в дополнение к таким хорошо известным инструментам разработки, как репозитории кода, IDE, программы отладки, средства отслеживания дефектов, инструменты непрерывной интеграции и развертывания.
Единая витрина позволяет получить полное представление о различных приложениях, службах и инфраструктурных зависимостях не только в рабочей, но и в промежуточной среде. Это дает возможность принимать, выделять, помечать, просматривать и анализировать ресурсы в сложных распределенных средах и получать представление об их работоспособности. Например, в Micros (внутреннем PaaS-инструменте Atlassian) есть «микроскоп», который предоставляет все сведения о службах в кратком и информативном виде.
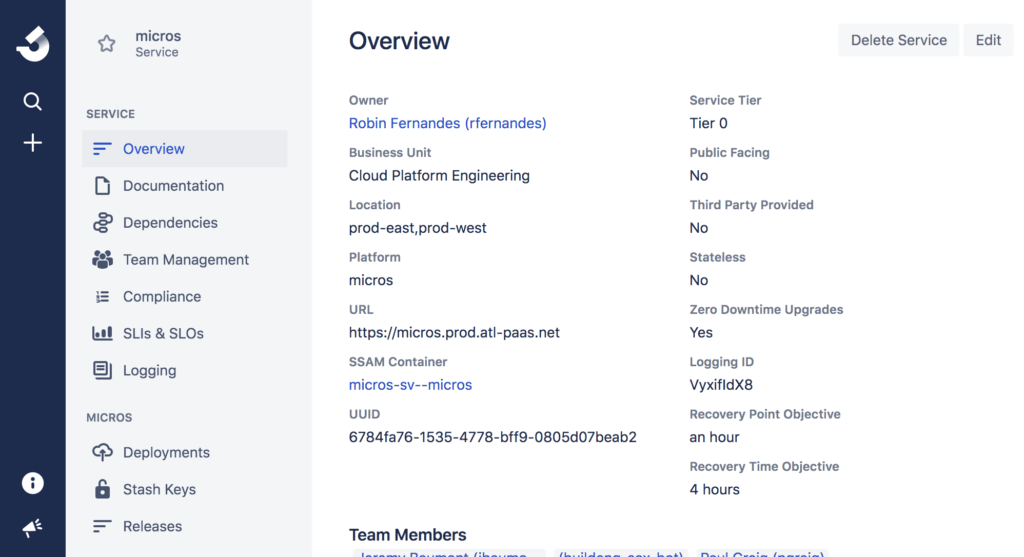
Мониторинг производительности приложений необходим для того, чтобы такие показатели производительности, как время загрузки страниц, задержка подчиненных служб или изменение состояния, отслеживались в дополнение к базовым системным показателям: использование ЦП и оперативной памяти и пр. Для наблюдения за показателями в режиме реального времени отлично подходят такие инструменты, как SignalFx и NewRelic.
Внедрение разнообразных средств мониторинга для отслеживания ошибок, обычных и искусственных транзакций, контрольных сигналов, оповещений, инфраструктуры, производительности и безопасности во время разработки. Необходимо, чтобы каждый участник команды был знаком с этими областями. Зачастую средства мониторинга ориентированы на конкретное приложение и должны отвечать конкретным требованиям. Например, наша команда разработчиков Opsgenie использует средства синтетического мониторинга, которые создают оповещения или инциденты и проверяют правильность их обработки (корректно ли работают интеграции, переадресация и политики). Мы также применяем синтетический мониторинг зависимостей инфраструктуры, чтобы периодически проверять функциональность различных служб AWS.
Система управления оповещениями и инцидентами, которую можно эффективно интегрировать с инструментами команды (например, решениями для ведения журналов или отчетности о сбоях) и которая естественным образом вписывается в процесс командной разработки и эксплуатации. Такой инструмент должен отправлять важные оповещения по нужным каналам связи с минимальной задержкой. В нем также должна быть предусмотрена возможность группировки и фильтрации большого количества оповещений, особенно когда в результате одной ошибки или сбоя генерируется несколько оповещений. Такими возможностями обладает Opsgenie — продукт, который команда Atlassian не только предлагает клиентам, но и использует сама, чтобы обеспечить надежную и гибкую систему управления оповещениями и инцидентами, идеально подходящую для наших методик разработки.
Заключение
При внедрении DevOps важно, чтобы сдвиг влево касался не только тестирования, но и мониторинга. Кроме того, важно применять методики и инструменты, способные обеспечить быстрое внесение изменений в рабочую среду при сохранении высокого качества.
Подробнее см. в дополнительных ресурсах Atlassian по DevOps, управлению инцидентами и изменениями.

Поделитесь этой статьей
Следующая тема
Рекомендуемые статьи
Добавьте эти ресурсы в закладки, чтобы изучить типы команд DevOps или получать регулярные обновления по DevOps в Atlassian.

Сообщество DevOps

Образовательные программы DevOps