Artykuły
Samouczki
Interaktywne przewodniki
Monitorowanie DevOps
Zwiększanie świadomości na każdym etapie pipeline'u dostarczania

Krishna Sai
Kierownik ds. inżynierii, dział rozwiązań IT
Od DevOps oczekuje się przyspieszenia programowania, regularnego testowania i częstszego wydawania przy jednoczesnej poprawie jakości i obniżeniu kosztów. Aby ułatwić osiągniecie tych celów, narzędzia do monitorowania DevOps zapewniają automatyzację oraz rozszerzone pomiary i widoczność w całym cyklu życia tworzenia oprogramowania — od planowania, przez programowanie, integrację i testowanie, aż po wdrażanie i obsługę.
Nowoczesny cykl życia tworzenia oprogramowania jest szybszy niż kiedykolwiek, a wiele etapów tworzenia i testowania oprogramowania przebiega jednocześnie. Właśnie to stało się zalążkiem DevOps — przejścia od odizolowanych zespołów, które prowadzą osobno prace programistyczne, testowe i operacyjne, do zunifikowanego zespołu, który zajmuje się wszystkimi tymi zadaniami i stosuje podejście odpowiedzialności za produkt („you build it, you run it”, YBIYRI).
Przy tak częstych obecnie zmianach kodu zespoły programistyczne potrzebują monitorowania DevOps, które zapewnia kompleksowy widok środowiska produkcyjnego w czasie rzeczywistym.
Czym jest monitorowanie DevOps?
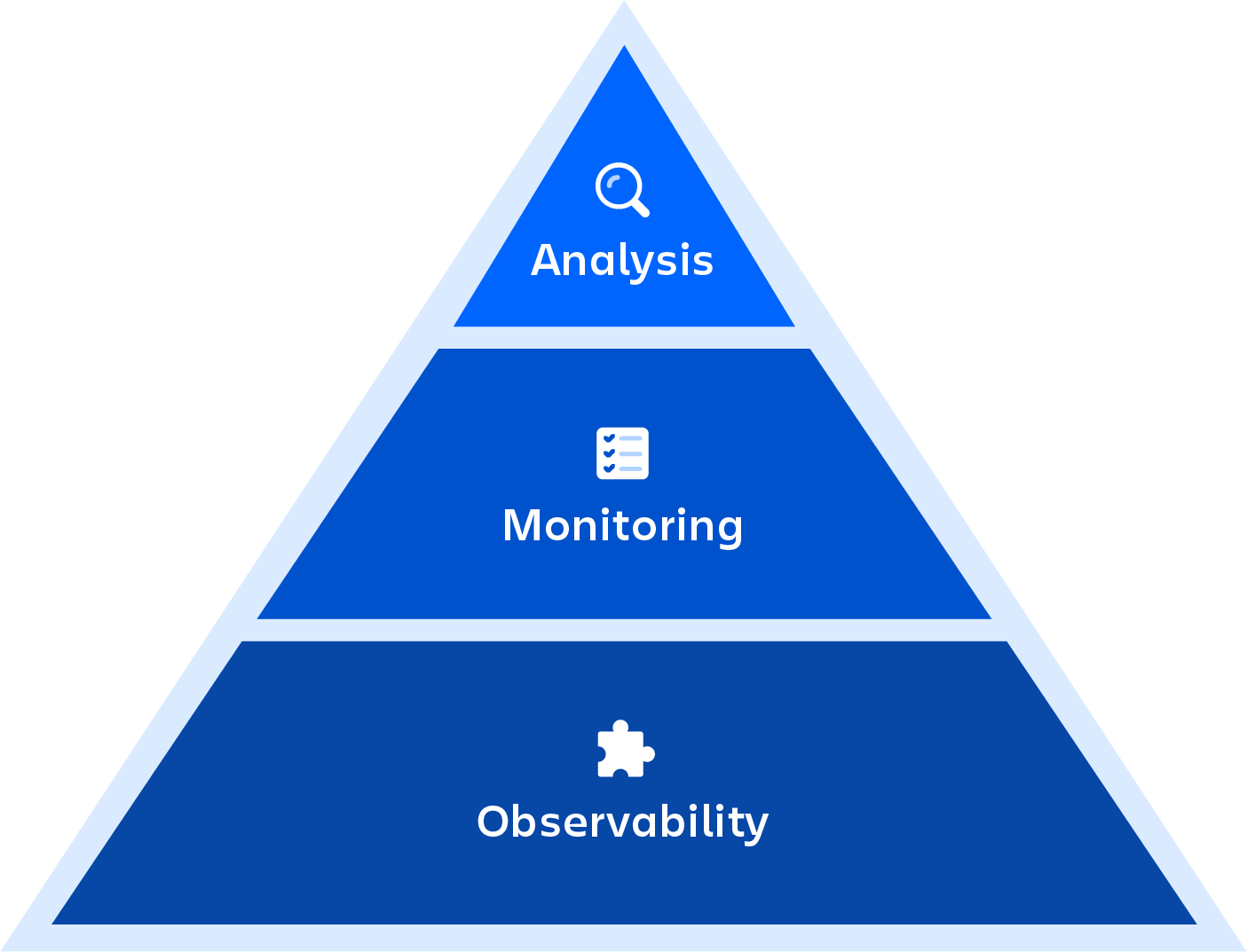
Monitorowanie DevOps polega na nadzorowaniu całego procesu tworzenia oprogramowania — od planowania, przez programowanie, integrację i testowanie, aż po wdrażanie i operacje. Obejmuje ono pełny widok stanu aplikacji, usług i infrastruktury w środowisku produkcyjnym i w czasie rzeczywistym. Funkcje, takie jak przesyłanie strumieniowe w czasie rzeczywistym, powtórki historyczne i wizualizacje, są krytycznymi elementami monitorowania aplikacji i usług.
zobacz rozwiązanie
Uproszczone zarządzanie incydentami i reagowanie
powiązane materiały
Dowiedz się więcej o narzędziach DevOps
Monitorowanie DevOps pozwala zespołom szybko i automatycznie reagować na wszelkie pogorszenia jakości obsługi klienta. Co jeszcze ważniejsze, pozwala zespołom przejść do wcześniejszych etapów prac programistycznych i zminimalizować wadliwe zmiany produkcyjne. Przykładem są lepsze narzędzia do wykrywania błędów i reagowania na nie, zarówno ręcznie podczas dyżurów domowych, jak i automatycznie, gdy jest to możliwe.
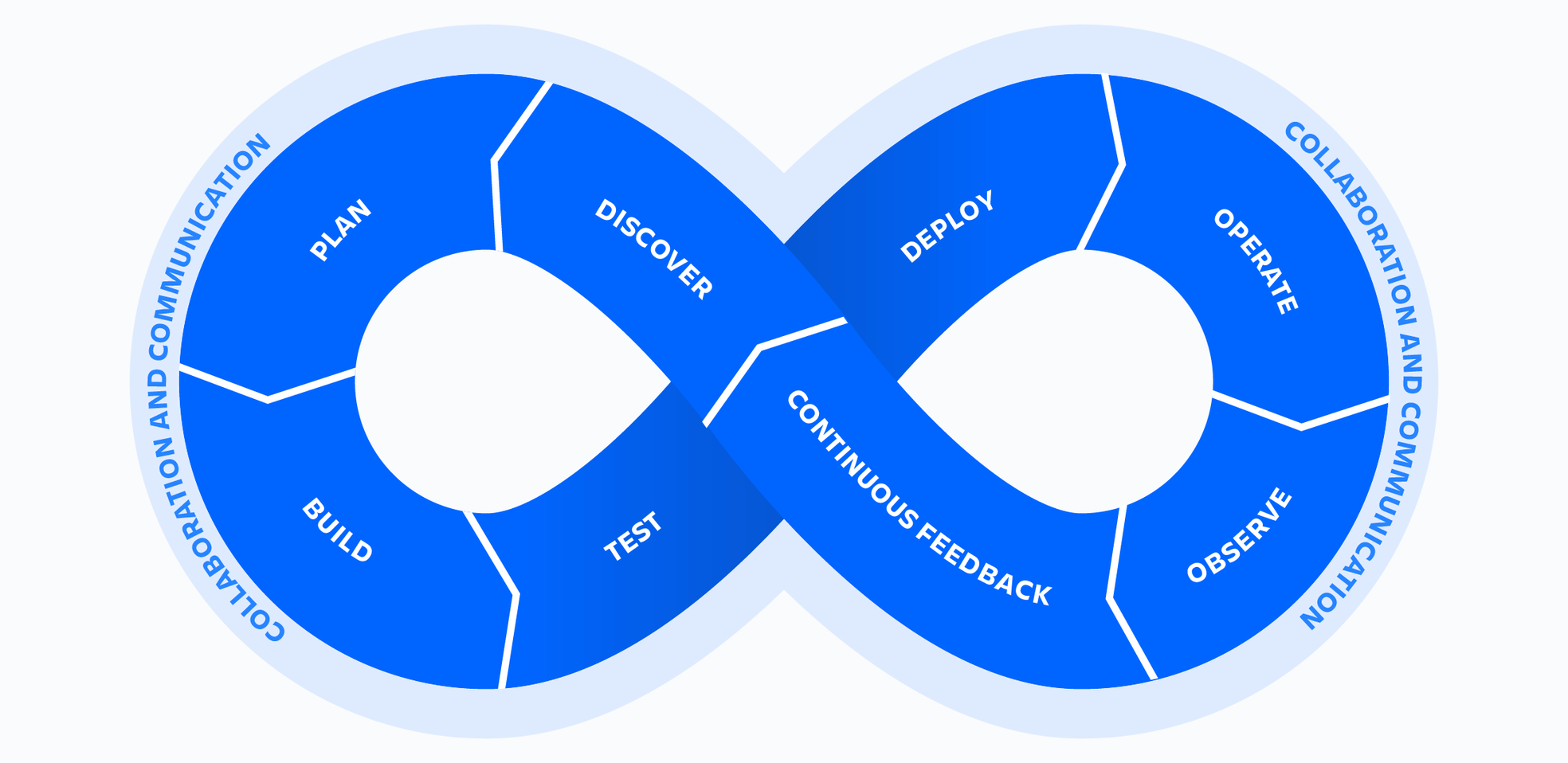
Monitorowanie DevOps a wgląd
Jeśli potraktujemy lewą stronę pętli nieskończoności jako stronę produktu a prawą jako stronę operacji, menedżer produktu, który przekazuje nową funkcję do produkcji, z pewnością będzie chciał zobaczyć, jak projekt dzieli się na zadania i historyjki użytkowników. Programista po lewej stronie projektu musi zobaczyć, jak przenieść tę funkcję do produkcji, wraz ze zgłoszeniami projektu, historyjkami użytkowników i zależnościami. Jeśli programiści będą stosować się do zasady DevOps polegającej na odpowiedzialności za produkt („you build it, you run it”), będą również zainteresowani usuwaniem przyczyn incydentów.
Jeśli chodzi o stronę operacyjną cyklu życia, inżynier ds. niezawodności lokalizacji musi rozumieć usługi, które można mierzyć i monitorować, aby w przypadku wystąpienia problemu można go było naprawić. Jeśli nie masz łańcucha narzędzi DevOps, który łączy wszystkie te procesy ze sobą, efektem jest nieuporządkowane, nieskorelowane i chaotyczne środowisko. Jeśli masz dobrze zintegrowany łańcuch narzędzi, możesz uzyskać lepszy ogląd bieżącej sytuacji.
Znaczenie monitorowania DevOps
Podejście DevOps rozszerza ciągłe monitorowanie na środowiska przejściowe, testowania, a nawet programistyczne. Wynika to z wielu powodów.
Częste zmiany kodu wymagają widoczności
Częste zmiany kodu wynikające z ciągłej integracji i ciągłego wdrażania zwiększyły tempo zmian i sprawiły, że środowiska produkcyjne stają się coraz bardziej złożone. Mikrousługi i mikrofrontendy wchodzą do nowoczesnych środowisk opartych na chmurze. W produkcji istnieją setki, a czasem tysiące różnych obciążeń, z których każde ma różne wymagania operacyjne dotyczące skali, opóźnień, nadmiarowości i zabezpieczeń.
Wszystko to powoduje wzrost zapotrzebowania na większą widoczność. Zespoły muszą nie tylko wykrywać przypadki spadku jakości obsługi klienta i reagować na nie, ale także robić to szybko.
Zautomatyzowana współpraca
DevOps zakłada poprawę jakości współpracy między pracownikami działów programistycznych, operacyjnych i biznesowych wchodzących w skład zespołów. Współpracę może jednak zakłócić brak integracji różnych narzędzi, co skutkuje problemami związanymi z koordynacją pracy różnych zespołów. Był to też jeden z głównych wniosków z ankiety Atlassian dotyczącej DevOps.
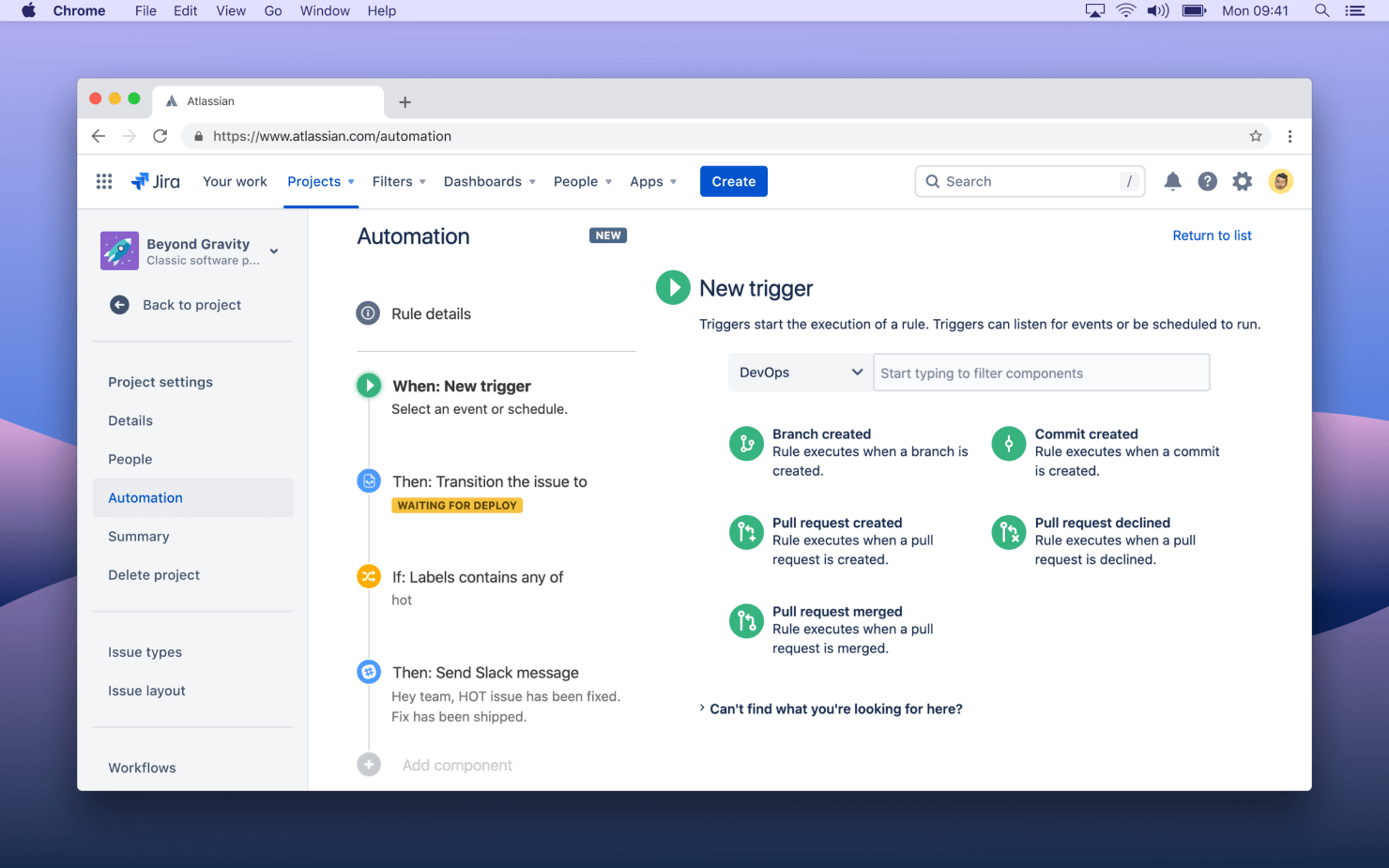
Współpracę można zautomatyzować za pomocą takich praktyk, jak uzyskanie pełnego widoku pipeline'u prac programistycznych wewnątrz edytora. Warto również ustawić reguły automatyzacji, które nasłuchują commitów lub pull requestów, a następnie aktualizują stan powiązanych zgłoszeń Jira i wysyłają wiadomości do kanału Slack zespołu. Można także skorzystać z funkcji analiz, która zapewnia raporty ze skanowania, testowania i analityczne.
Eksperymentowanie
Potrzeba optymalizacji produktów w celu zaspokojenia potrzeb klientów, wynikająca z personalizacji i optymalizacji lejków konwersji, prowadzi do ciągłych eksperymentów. W środowiskach produkcyjnych można przeprowadzać setki eksperymentów i wprowadzać setki flag funkcji, co sprawia, że systemy monitorowania mają problemy z przekazywaniem informacji o przyczynie obniżenia jakości obsługi.
Rosnące wymagania dotyczące zawsze dostępnych usług i aplikacji, a także rygorystyczne zobowiązania wynikające z umów SLA, mogą zwiększać podatność aplikacji na ataki. Zespoły programistyczne muszą zadbać o to, aby określić docelowe poziomy świadczenia usług (SLO) i wskaźniki poziomów świadczenia usług (SLI), które mają być monitorowane i wobec których podejmowane są działania.
Zarządzanie zmianami
Ponieważ większość przerw w produkcji jest spowodowana zmianami, zarządzanie zmianami ma zasadnicze znaczenie, zwłaszcza w przypadku aplikacji o znaczeniu krytycznym, np. w branży finansowej czy medycznej. Trzeba określić ryzyko związane ze zmianami, a przepływy zatwierdzeń muszą być zautomatyzowane w oparciu o ryzyko wynikające ze zmiany.
Poradzenie sobie z tymi zawiłościami wymaga kompleksowego zrozumienia i strategii monitorowania. Oznacza to zdefiniowanie i wykorzystanie praktyk monitorowania oraz posiadanie zestawu rozbudowanych, elastycznych i zaawansowanych narzędzi do monitorowania, które mają kluczowe znaczenie dla procesów programistycznych.
Monitorowanie systemów zależnych
Systemy rozproszone stają się coraz bardziej powszechne i często składają się z wielu mniejszych usług międzyfirmowych. Zespoły muszą teraz nie tylko monitorować tworzone przez siebie systemy, ale także analizować wydajność i dostępność systemów zależnych oraz zarządzać nimi. Amazon Web Services (AWS) oferuje ponad 175 produktów i usług, w tym narzędzia obliczeniowe, pamięci masowej, sieciowe, baz danych, analityczne, mobilne, służące do wdrażania i zarządzania, a także rozwiązania programistyczne. Jeśli tworzysz aplikację na platformie AWS, musisz wybrać usługę odpowiednią do potrzeb swojej aplikacji. Potrzebne będzie Ci także oprzyrządowanie i strategie śledzenia błędów w sposób rozproszony i służące do obsługi awarii systemów zależnych.
Kluczowe możliwości monitorowania DevOps
Zgodnie z tradycją DevOps opracowanie i wdrożenie strategii monitorowania wymaga również zwrócenia uwagi na podstawowe praktyki i zestaw narzędzi.
Testowanie shift-left
Testowanie shift-left (przesunięcie testowania w lewo), które jest przeprowadzane na wcześniejszym etapie cyklu życia, pomaga zwiększyć jakość, skrócić cykle testów oraz zmniejszyć liczbę błędów. W przypadku zespołów DevOps ważne jest rozszerzenie praktyk testowania shift-left o monitorowanie stanu środowisk przedprodukcyjnych. Umożliwia to wczesne i częste wdrażanie monitorowania w celu utrzymania ciągłości w produkcji oraz zachowania jakości alertów monitorowania. Testowanie i monitorowanie powinny ze sobą sprawnie współdziałać, a wczesne monitorowanie pomaga ocenić zachowanie aplikacji w ramach kluczowych ścieżek i transakcji użytkowników. Pomaga również zidentyfikować odchylenia wydajności i dostępności przed wdrożeniem produkcyjnym.
Alerty i zarządzanie incydentami
W świecie opartym na chmurze incydenty są tak samo powszechne jak błędy w kodzie. Do incydentów należą awarie sprzętu i sieci, niepoprawna konfiguracja, wyczerpanie zasobów, niespójności danych i błędy oprogramowania. Zespoły DevOps powinny uwzględniać incydenty i dysponować wysokiej jakości narzędziami do monitorowania, aby na nie reagować.
Niektóre z najlepszych praktyk, które mogą w tym pomóc, to:
- Zbudowanie kultury współpracy, w ramach której monitorowanie jest wykorzystywane podczas prac programistycznych wraz z funkcjami/funkcjonalnościami i zautomatyzowanymi testami
- Podczas programowania: tworzenie odpowiednich, wysokiej jakości alertów w kodzie, które minimalizują średni czas do wykrycia (MTTD) i średni czas do wyizolowania (MTTI)
- Utworzenie narzędzi monitorowania w celu upewnienia się, że usługi zależne działają poprawnie
- Przeznaczenie czasu na utworzenie wymaganych pulpitów i przeszkolenie członków zespołu w zakresie korzystania z nich
- Zaplanowanie „gier wojennych” dla usługi w celu upewnienia się, że narzędzia monitorowania działają poprawnie, i wyłapania brakujących
- Podczas sprintów: planowanie zamykania działań z poprzednich przeglądów incydentów, w szczególności działań związanych z tworzeniem brakujących narzędzi monitorowania i automatyzacją
- Utworzenie detektorów bezpieczeństwa (uaktualnienia/łatki/rolowanie poświadczeń)
- Kultywowanie podejścia typu „mierz i monitoruj wszystko” dzięki automatyzacji określającej odpowiedź na wykryte alerty
Narzędzia do monitorowania DevOps
Uzupełnieniem zestawu skutecznych praktyk monitorowania są zaawansowane narzędzia, które są zgodne z kulturą DevOps/YBIYRI. Wymaga to zwrócenia uwagi na identyfikację i wdrożenie narzędzi do monitorowania, oprócz dobrze znanych narzędzi programistycznych w postaci repozytoriów kodu, środowisk IDE, debugerów, systemów śledzenia usterek oraz narzędzi do ciągłej integracji i wdrażania.
Pojedynczy skonsolidowany widok zapewnia kompleksowy wgląd w różne aplikacje, usługi i zależności infrastruktury, nie tylko w środowisku produkcyjnym, ale także przejściowym. Daje to możliwość aprowizacji, pozyskiwania, tagowania, wyświetlania i analizowania kondycji złożonych środowisk rozproszonych. Przykładowo wewnętrzne narzędzie PaaS Atlassian Micros zawiera narzędzie o nazwie Microscope, które dostarcza pełne informacje o usługach w zwięzłej formie i w sposób umożliwiający odnajdowanie.
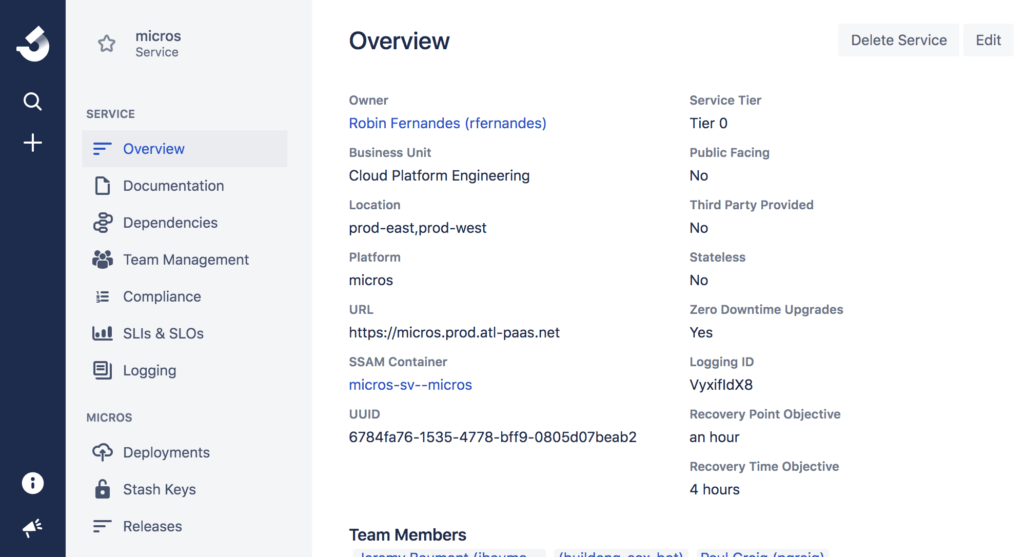
Monitorowanie wydajności aplikacji jest niezbędne w celu zapewnienia, że wskaźniki wydajności specyficzne dla aplikacji, takie jak czas ładowania się stron, opóźnienia usług podrzędnych lub przejścia, są monitorowane razem ze wskaźnikami systemu bazowego, takimi jak wykorzystanie procesora i pamięci. Narzędzia, takie jak SignalFX i NewRelic, doskonale nadają się do obserwacji danych wskaźników w czasie rzeczywistym.
Implementacja różnych rodzajów narzędzi monitorowania, w tym monitorów błędów, transakcji, syntetycznych, heartbeats, alarmów, infrastruktury, pojemności i bezpieczeństwa w procesie programowania. Należy zadbać, aby każdy członek zespołu był przeszkolony w tych obszarach. Te narzędzia monitorowania są często specyficzne dla aplikacji i muszą być implementowane w oparciu o wymagania poszczególnych aplikacji. Przykładowo nasz zespół programistyczny Opsgenie implementuje syntetyczne narzędzia monitorowania, które tworzą alert lub incydent i sprawdzają, czy przepływ alertów jest wykonywany zgodnie z oczekiwaniami (tzn. czy integracje, przekierowywanie i zasady działają poprawnie). Wdrażamy również syntetyczne narzędzia monitorowania zależności infrastrukturalnych, które okresowo sprawdzają funkcjonalność różnych usług AWS.
System zarządzania alertami i incydentami, który umożliwia bezproblemową integrację z narzędziami Twojego zespołu (zarządzanie dziennikami, raportowanie awarii itp.), dzięki czemu naturalnie wpasowuje się w rytm prac programistycznych i operacyjnych zespołu. Narzędzie powinno wysyłać ważne alerty do preferowanych kanałów powiadomień z możliwie najniższymi opóźnieniami. Powinno dawać także możliwość grupowania alertów w celu ich filtrowania, zwłaszcza gdy kilka alertów zostanie wygenerowanych w przypadku pojedynczego błędu lub awarii. W Atlassian nie tylko oferujemy Opsgenie jako produkt, który zapewnia te możliwości naszym klientom, ale również używamy go wewnętrznie, bo jesteśmy pewni, że mamy wydajny, elastyczny i niezawodny system zarządzania alarmami i incydentami zintegrowany z naszymi praktykami programistycznymi.
Podsumowując…
W przypadku wdrażania DevOps ważne jest, aby oprócz testowania objąć podejściem „shift-left” także monitorowanie oraz stosować praktyki i narzędzia pozwalające na szybkie przekazywanie zmian do środowiska produkcyjnego z zachowaniem wysokiej jakości.
Aby uzyskać więcej informacji, zapoznaj się z dodatkowymi zasobami Atlassian dotyczącymi DevOps, zarządzania incydentami i zarządzania zmianami.

Udostępnij ten artykuł
Następny temat
Zalecane lektury
Dodaj te zasoby do zakładek, aby dowiedzieć się więcej na temat rodzajów zespołów DevOps lub otrzymywać aktualności na temat metodyki DevOps w Atlassian.

Społeczność DevOps

Ścieżka szkoleniowa DevOps