
Many Bitbucket Server customers have development teams spread across the globe. Over the years, we’ve heard from many of them, asking us if we could speed up Git operations for their remote teams. In 2015, we gave customers this capability with Bitbucket Smart Mirrors. Smart Mirrors are a read-only replica of a primary or upstream Bitbucket Server instance and can be placed close to development teams to accelerate their Git operations.
Soon after releasing Bitbucket mirrors, we began to hear from customers who were using mirrors for an unexpected use case – servicing their CI/CD workload. CI/CD pipelines are becoming a vital part of the modern enterprise and an increasingly mission-critical service.
Using mirrors for CI/CD load has several advantages.
- Scalability: Effectively unlimited hosting capacity – add more nodes to increase capacity.
- Reduced blast radius: if a larger-than-expected build storm hits the primary instance, it can affect performance for interactive users, e.g. creating or commenting on pull requests or pushing code. On the other end of the spectrum, upgrades and maintenance can affect the availability of the service for CI/CD systems. Configuring your CI/CD system to perform git operations against a separate system results in a stable, more resilient CI/CD pipeline.
- Data locality: Customers can place mirrors close to their build farms while positioning the primary Bitbucket server instance in the best position for their interactive users.
While customers loved the operational capabilities of Smart Mirrors, there were shortcomings that prevented wholesale adoption, mostly related to the single-node deployment model.
- Limited scalability: The only option to increase capacity was to scale up, and this meant that if customers wanted to distribute CI/CD load to a set of mirrors, they would need to manually point repositories, build plans, or pipelines at individual mirrors. Any change in demand or capacity requirements would mean re-sharding the workload.
- A single point of failure: Enterprises consider their CI/CD pipeline to be mission-critical, and introducing a system with a single point of failure is out of the question.
Solving these problems would make Smart Mirrors even more compelling for the CI/CD use case. Thus, the Smart Mirror Farm project was born, with the mission of creating a distributed, horizontally scalable, self-healing Git hosting solution. Going from a single node to a multi-mode deployment model meant that the primary barriers to adopting Smart Mirrors for CI/CD load in the enterprise would be overcome.
It is important to call out early that one of the properties of this system that dramatically simplified the design is that we could almost always rely on the upstream as a source of truth.
Read on for a deep-dive technical exploration of:
- The underlying Git protocol required to run Smart Mirror farms
- The processes for syncing and healing the mirror farm
- Guaranteeing consistency in a data-intensive distributed system
- The farm vet, our anti-entropy system
- How the system was tested to ensure a high level of reliability
A bit about Git
A basic understanding of how Git works when fetching changes from a server is essential to understanding the solution design.
Ref
A named pointer to a commit, such as a branch or a tag.
Fetch
Updating a repository from another source, usually but not always a Git server. A fetch can mean pulling down the entire contents of a repository, referred to as a “clone,” or an incremental update.
Pack protocol
A Git client talks to a server using the Git Pack Protocol, which at a high level involves two steps.
Ref advertisement
This is the first step in pack protocol. The server returns a list of refs pointing to commits. To see the output of a ref advertisement, run the git ls-remote command.
$ git ls-remote --refs ssh://git-server:7990/foo/bar.git
d116e985ffbb7d4ee6dc7e310cba9aa4ea215e15 refs/heads/bar
bea5baa3ebcb18675275ed6a218e9c8ec87515b1 refs/heads/foo
58cdca2f051b47438d4dccb66c231a5eeeb31593 refs/heads/master
405084e365a31123916d0d4c821b5a6671cf303c refs/tags/bazThis repository has three branches: bar, foo and master as well as a single tag baz, all of which point at different commits.
Pack negotiation
The second phase of the pack protocol is known as pack negotiation. The Git client sends the server a series of have and want lines. A have line tells the server that the client already has the commit, and a want line tells the server that it wants to fetch that commit. You can see this in practice by setting the GIT_TRACE_PACKET environment before executing a Git fetch, e.g., GIT_TRACE_PACKET=1 git fetch. Let’s go ahead and add a new branch to our repository and see how pack negotiation works.
$ GIT_TRACE_PACKET=1 git fetch
packet: fetch< 58cdca2f051b47438d4dccb66c231a5eeeb31593 HEAD�multi_ack thin-pack side-band side-band-64k ofs-delta shallow ... symref=HEAD:refs/heads/master agent=git/2.17.2
packet: fetch< d116e985ffbb7d4ee6dc7e310cba9aa4ea215e15 refs/heads/bar
packet: fetch< bea5baa3ebcb18675275ed6a218e9c8ec87515b1 refs/heads/foo
packet: fetch< 58cdca2f051b47438d4dccb66c231a5eeeb31593 refs/heads/master
packet: fetch< 1e59f05ab782697de68b42178a88ebfcb27a80ef refs/heads/new
packet: fetch< b93a1b11d6ee09d78a71dfa64c1d637576f5511a refs/remotes/origin/new
packet: fetch< 405084e365a31123916d0d4c821b5a6671cf303c refs/tags/baz
packet: fetch< 0000
packet: fetch> want 1e59f05ab782697de68b42178a88ebfcb27a80ef multi_ack_detailed side-band-64k thin-pack include-tag ofs-delta agent=git/2.7.4
packet: fetch> 0000
packet: fetch> have d116e985ffbb7d4ee6dc7e310cba9aa4ea215e15
packet: fetch> have bea5baa3ebcb18675275ed6a218e9c8ec87515b1
packet: fetch> done
packet: fetch< ACK d116e985ffbb7d4ee6dc7e310cba9aa4ea215e15 common
packet: fetch< ACK bea5baa3ebcb18675275ed6a218e9c8ec87515b1 common
packet: fetch< ACK bea5baa3ebcb18675275ed6a218e9c8ec87515b1
packet: sideband< 2Counting objects: 3, done.
remote: Counting objects: 3, done.
15:40:02.508614 pkt-line.c:80 packet: sideband< PACK ...
15:40:02.508624 pkt-line.c:80 packet: sideband< 2Total 3 (delta 0), reused 0 (delta 0)
remote: Total 3 (delta 0), reused 0 (delta 0)
15:40:02.508639 pkt-line.c:80 packet: sideband< 0000
Unpacking objects: 100% (3/3), done.
From ssh://bitbucket:7999/stash/pack-protocol
* [new branch] new -> origin/newAt line 6, the server advertises the new branch, and on line 10, the client tells the server it wants this new commit through a want line. You will also notice several have lines, which tell the server which commits the client already has. Git does a tree search using the have and want lines provided by the client to generate an efficient pack file. More information on this can be found in the documentation linked above, as well as the “multi ack” section of the Git documentation.
Consistency
The most common question we get asked is, “why not just put a load balancer in front of a number of mirrors?” The answer is that we want to present a consistent view of a repository to the world, and this simple solution does not work for the following scenarios.
HTTP
When using Git over HTTP, the ref advertisement and pack negotiation messages could land on different servers. If the node that replies to the ref advertisement message responds with a ref that is not present in one of its peers, then the client can include a ref in its want line that a node does not yet know about, resulting in a not our ref error.
CI systems
Whenever a change is pushed to a repository on an upstream, Bitbucket notifies CI/CD systems that it has received a modification. The same goes for mirrors; for a Smart Mirror farm, we don’t want to tell build systems that a mirror has the changes until every mirror in the farm can service the request for those changes.
Consistency guarantee
How is it possible to serve Git repositories from a farm of Git servers, sitting behind a “dumb” load balancer with no shared state?
One of the most common topics of discussion when talking about distributed systems is consistency. The consistency guaranteed by Smart Mirror farms is that a node in a mirror farm only advertises commits that each of its peers can serve, and is unique to the nature of Git and the pack protocol described above.
Synchronization operations
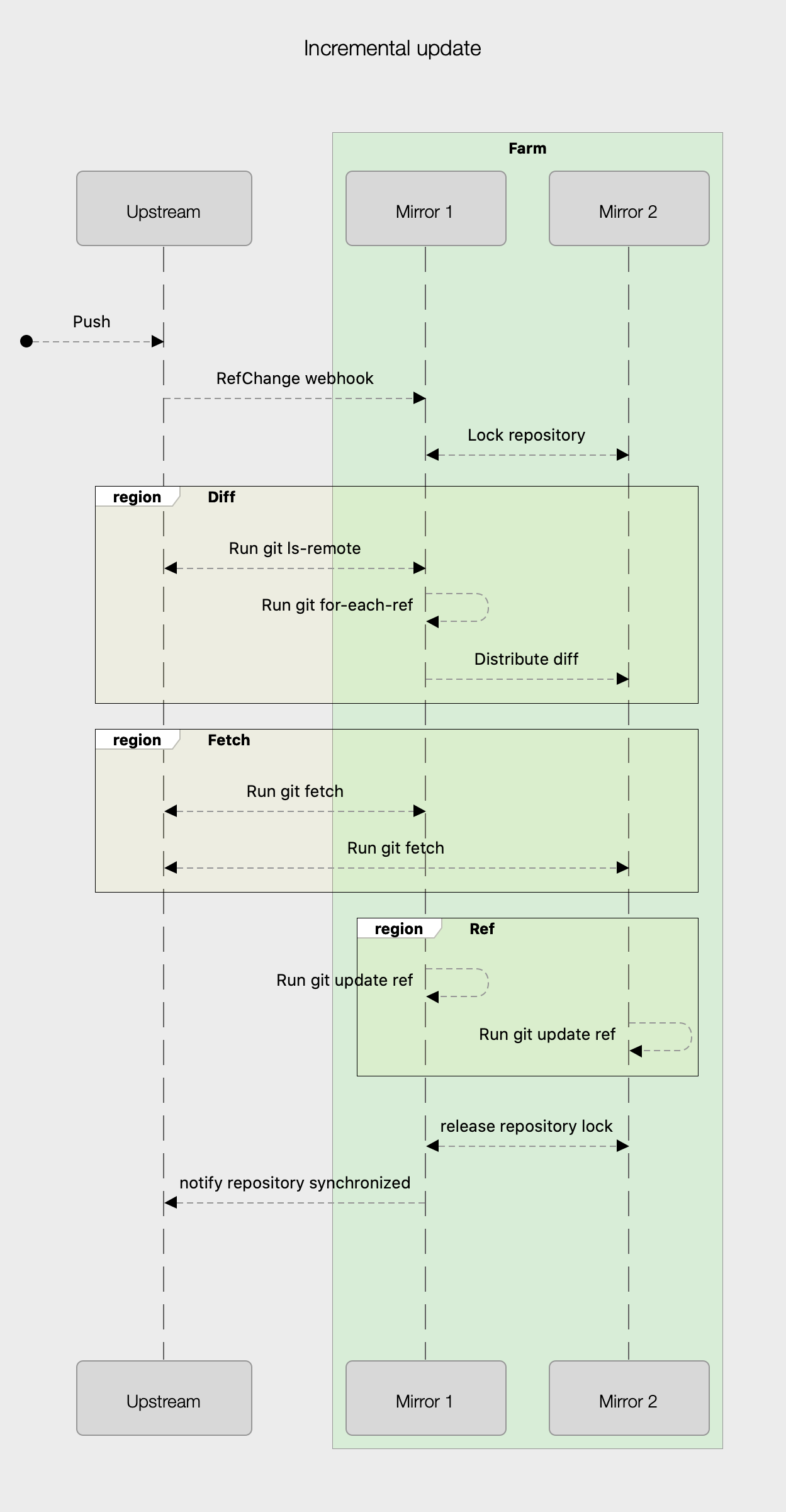
A mirror fetches changes from the upstream in response to a RefChange webhook, so how do we coordinate updates to provide the consistency guarantee described above?
We defined two types of synchronization operations.
- Incremental: Used when incrementally syncing a Git repository across a mirror farm. This is by far the most common type of operation.
- Snapshot: Used for repairing repository inconsistencies across nodes in a farm, usually triggered by the farm vet but also used when a node rejoins a farm.
Incremental
The mirror farm triggers incremental sync when it receives a RefChange webhook from the upstream system. The node that gets the webhook is now the orchestrating node for the sync operation, and the following steps take place:
- A farm-wide lock is acquired for the repository.
- The orchestrating node runs a
git ls-remoteagainst the upstream server. - At the same time, a git
for-each-refis run against the local repository. - A diff between the contents of the remote and local repository is generated. One of the cool things about this approach is that the contents of the
ls-remoteandfor-each-refare ordered lexicographically, so the diff can be generated by streaming through the output of each command. The number of refs in a Git repository can be huge, and so the ability to generate this diff by streaming means that memory pressure is not an issue for the sync process. The diff contains a set of instructions describing an add, delete, or update operation. - Once this diff has been generated we zip it up, create a content hash, and distribute it to the rest of the farm (there is also a chunking process involved, but it’s not that interesting). The content hash of this compressed file becomes the operation ID for the update. This is important because we only distribute the diff to the farm once, and the second phase of this process is triggered by using this operation ID.
- For an add or update operation, each node in the farm runs a git fetch for the objects contained in the diff. It’s important to note that no refs are updated as part of this operation.
- Once each node has reported back to the orchestrating node that it has completed its fetch operation, an update-ref process is triggered using the operation ID. Remember the consistency guarantee we provided? This is the crucial step at which the guarantee comes into play, although not all nodes run the update-ref at the same time. Any ref that is now advertised is available for fetching from any node.
- Once each node has reported back that the update-ref operation has been complete, the mirror farm can notify CI/CD systems that a change is ready and available for building.
Let us dive into a worked example.
Given a repository R with three branches and a single tag. Note the commit hash has been shortened to a single character to aid readability.
$ git ls-remote --refs ssh://upstream:7990/R.git
A refs/heads/bar
B refs/heads/foo
C refs/heads/master
D refs/tags/bazA developer pushes changes to three branches.
- Deletes
bar - Updates
foofromB→X - Adds a new branch
featurethat is at`Z`
The next thing that happens is the mirror farm will be notified that there are changes to R that must be synchronized. The node that receives the webhook is now responsible for orchestrating this synchronization. The first thing the orchestrating node will do is take out a cluster lock for R and then run a git ls-remote against the upstream, which now looks like this:
$ git ls-remote --refs ssh://upstream:7990/R.git
Z refs/heads/feature
X refs/heads/foo
C refs/heads/master
D refs/tags/bazIn parallel, the orchestrating node runs a git for-each-ref against its local copy of R
The output of these two commands is compared to generate a diff in a proprietary null separated format.
-A�refs/heads/bar
=B�X�refs/heads/foo
+Z�refs/heads/featureThe first character is the type of operation: - for delete, = for update, and + for add. This file is then compressed (chunked if necessary) and distributed to the rest of the mirrors in the farm. Each mirror will save this file to disk with a content addressable name. This is also the operation ID that will be used to trigger the update-ref in the next step.
Each mirror will then fetch any objects that it does not already have.
git fetch ssh://upstream:7990/R.git X ZAfter this command completes repository R on the mirror has objects X and Z and will include them as part of a pack file if requested. It will not advertise the presence of these objects, as no refs point to them.
Once all mirrors have reported back that they have completed the fetch command successfully, a set of Git update-ref instructions are generated and piped into the git update-ref command. The same diff file can be used to create both the fetch command and the update-ref instructions. It is worth noting that we don’t delete objects that are no longer being advertised by the upstream. Instead, we remove a reference to the object using update-ref and leave it to git garbage collection process to remove the object.
delete refs/heads/bar-baz��update refs/heads/foo�X��update refs/reads/feature�X��Once each node has notified the orchestrating node that the update-ref step has taken place, the cluster lock can be released, and downstream systems such as CI/CD can be advised that the mirror farm has finished synchronizing the changes. This process is documented in the sequence diagram below.
Snapshot
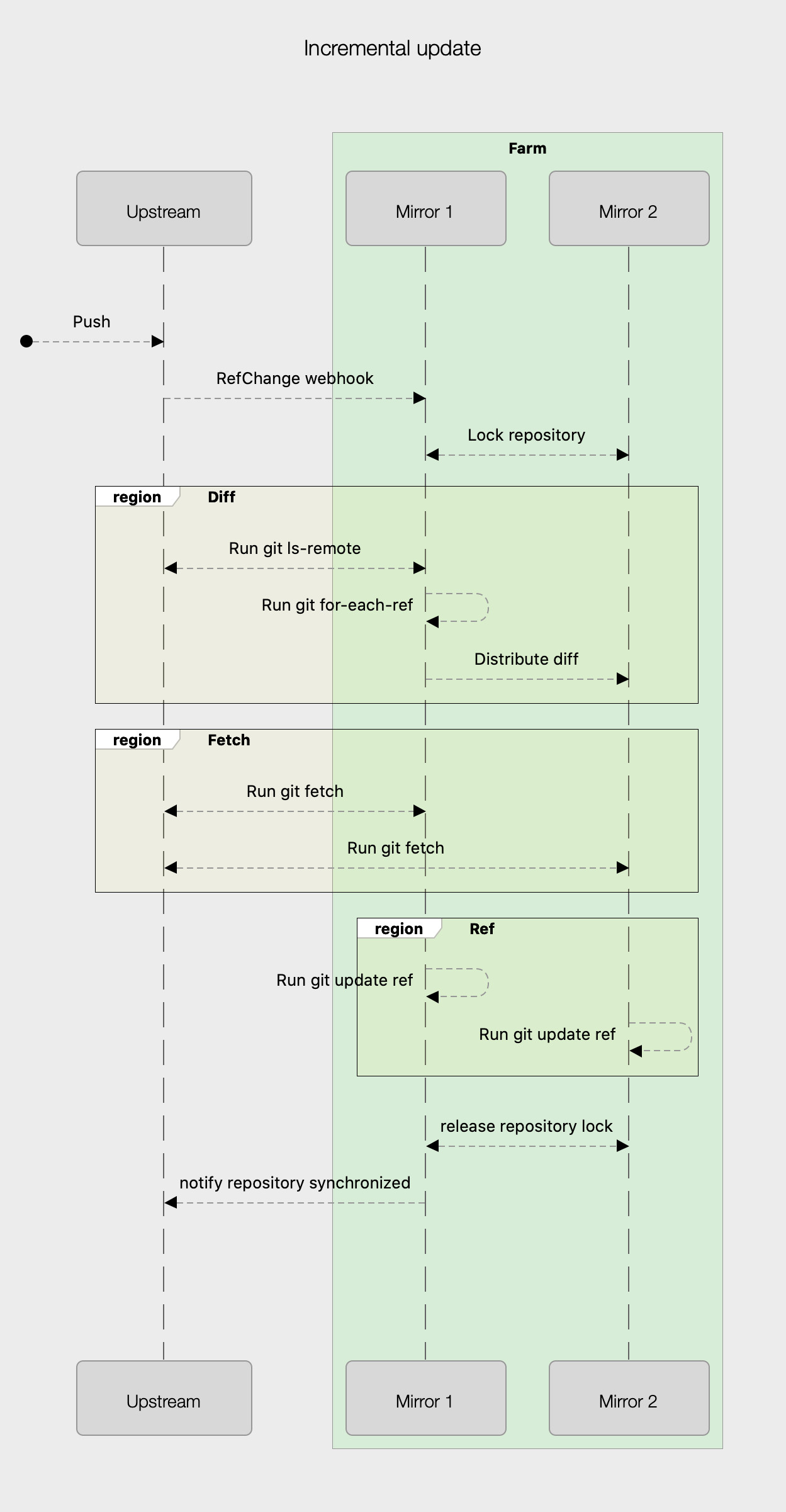
You may have noticed that the diff generation algorithm for incremental sync assumes that all the copies of a repository in a farm are identical. There are several scenarios where this does not hold, and we need a mechanism for repairing repositories that have diverged – enter the snapshot sync. The critical difference between the snapshot sync and the incremental sync is where and how the diff is generated once snapshot sync is triggered.
- A farm-wide lock is taken out for the repository.
- The orchestrating node runs a
git ls-remoteagainst the upstream server. - Rather than a diff being distributed to all the nodes in the farm, the output of the
git ls-remotecommand is distributed to the farm nodes. Again, we compress the contents of this output and digest it. This is now considered the target state or snapshot of the upstream system. - Each node then runs a
git for-each-refand feeds the output of that command along with the output of thegit ls-remoteit received from the orchestrating node into the diff calculator. The same streaming diff calculator is used for both types of operation. Once this operation is complete, each node has a “diff” detailing the steps it needs to take to become consistent with the snapshot that was distributed to the farm. - From this point on, the same process is followed as with the incremental sync operation. All objects are fetched, and then refs are updated.
Let us dive into a worked example.
We have an upstream with repository R that is currently advertising the following refs:
$ git ls-remote --refs ssh://upstream:7990/R.git
Z refs/heads/feature
X refs/heads/foo
C refs/heads/master
D refs/tags/bazMirror M1 has a view of R
$ git for-each-ref --format="%(objectname) %(refname)"
A refs/heads/bar
Z refs/heads/feature
X refs/heads/foo
C refs/heads/master
D refs/tags/bazThat is inconsistent with the upstream and mirror M2
$ git ls-remote --refs ssh://upstream:7990/R.git
B refs/heads/foo
C refs/heads/master
D refs/tags/bazFarm vet to the rescue! Once the farm vet detects that there is an inconsistency between mirrors and the upstream, it will execute snapshot sync for the inconsistent repositories. The first mirror to detect this inconsistency will become the orchestrating node. As with incremental lock, the first steps are to take out a cluster lock for the repository and run a git ls-remote against the upstream system. This now becomes the snapshot or target state for R on each mirror. This is where incremental and snapshot sync starts to diverge. Rather than generating a diff comparing its copy of R to the upstream state and distributing that to the mirror farm, the contents of the ls-remote output is distributed to each node in the mirror farm. It is now up to each node to calculate the diff of necessary instructions required to bring its state in line with that of the upstream.
The diff for M1
-A�refs/heads/barAnd for M2
=B�X�refs/heads/foo
+Z�refs/heads/featureThe rest of the process is the same as for an incremental synchronization. The difference is that each node will run a different set of instructions to bring it in line with the snapshot taken by the orchestrating node. Once again, a sequence diagram makes an excellent companion to the steps described above.
The farm vet
In any well-designed distributed system, there is a mechanism for recovering from unexpected events. In the case of smart mirrors, this can be anything from a missed webhook to on-disk repository corruption. One of the challenges with scale-out systems like smart mirror farms is that, as you add more nodes, rare events become common due to the law of averages.
Whats happens when cattle on your farm get sick? That’s right – you call in the farm vet! The farm vet is the mechanism mirror farms use for detecting and correcting errors, and its how we achieve one of the primary design goals of self-healing, low-maintenance mirror farms. The industry calls this anti-entropy, but we prefer the term farm vet.
Pre-farm mirrors also had an anti-entropy mechanism. It had some shortcomings, which we improved.
- Non-stable hashes: Before mirror farms, the hash used to determine if a repository was in sync was a randomly generated UUID that bore no relation to the content of the repository.
- These hashes were fetched from the upstream using a paging mechanism of 100 hashes at a time sequentially. The round-trip latency of this strategy meant that repair jobs could only be run at most every 15 minutes. Fifteen minutes does not sound like much, but it’s important to note that any delay in detecting and repairing an inconsistency will result in a build being delayed by up to 15 minutes – this is not an ideal developer experience!
The first and most significant improvement was the use of stable hashes to represent the repository contents, which is the (somewhat simplified) equivalent of running git for-each-ref --format=” %(objectname) %(refname)” | shasum -a 256 on a repository. Doing this gave us a stable content hash of the content of each repository. We also split the repository hash into two: a metadata hash for things like repository name and the content hash.
The next thing the team wanted to improve was the frequency of farm vet runs so that any errors could be detected and corrected earlier. Why did we invest effort in decreasing the time to identify and repair any inconsistencies? The simple answer is that end-users notice quickly if the Git repository they are fetching from is out of date, and we wanted to lower the support burden of managing smart mirror farms. In addition, if a critical hot-fix needs to go out, waiting 15 minutes or more for the CI/CD pipeline to pick up the change is simply unacceptable for mission-critical applications.
The first option we considered was maintaining a Merkle tree of repository hashes that would allow us to compress the integrity information for a massive number of repositories in a single response. Each hash in this page could then contain the hashes of hundreds or even thousands of other repositories. This approach also has some elegance in that it shared some similarities with the way the Git pack protocol (discussed above) works. One of the questions I always ask myself as an engineer is, “Can we make this simpler?” The team was challenged to simplify this process.
The team had a key insight that the majority of the time taken by the previous approach was the latency introduced by paging. Could we just send all the hashes in a single response? Yes, we could, but we were concerned about holding the digest for every repository in the system in memory while sending the response over the network and the GC pressure this would cause. We discovered that we could stream records straight out of the database to the network via a streaming API of our JSON library, and that would give us all the properties we wanted from this system component. On the mirror side, we again made use of the streaming JSON API for deserialization.
Smart mirror farms now run a more reliable anti-entropy process every three minutes, detecting and correcting errors faster than ever before.
Node joining process
One of the primary goals for smart mirror farms is the ability to elastically scale Git hosting capacity by adding and removing nodes from a mirror farm. The process for adding a new mirror to a farm needed to be smooth and efficient without disturbing the functionality of other farm nodes. The other goal of the farm joining process was to ensure that nodes that rejoined the farm did so in the most efficient way possible.
The node joining process:
- Authentication: When a node joins a farm for the first time, an authentication process takes place, where the node is given a secret for authenticating to the upstream system over REST, as well as an SSH key for authenticating to the upstream over Git.
- The set of repositories that should be mirrored is transferred over from the farm. This is the only piece of data that does not have a “source of truth” on the upstream, so special care needs to be taken to maintain the consistency of this information. If two different nodes contain conflicting information about which set of repositories should be mirrored, then we use a simple last write wins strategy for resolving this conflict.
- The metadata for the projects and repositories to be mirrored is fetched from the upstream.
- The order in which repositories are synced is essential; many of our customers make extensive use of fork-based workflows without going into too much detail about how Git works with forks under the hood. The critical point is that a fork only contains objects unique to itself within its repository, while the majority of objects point to its parent’s object directory. The reason this is important for mirrors and specifically the join process is that if we sync a series of forks before we sync the parent, redundant data will not only be copied over the network, but also stored on disk. We order repositories so that parents are synchronized before their children to make the initial sync process as efficient as possible.
- If the repository has not been synced before, i.e., this is a brand new mirror joining the farm, or the repository was added since the mirror was last part of the farm, a git fetch is run to pull down data from the upstream. This git fetch is run independently on each new mirror node, with no locking taking place. The reason for this is that we don’t want to stop the repository in the mirror farm from making progress while a new mirror node is being spun up. Repositories can be vast, and mirrors can be located far away from their upstreams. We have seen the initial sync for repositories take days!
- Once the initial sync process has finished, the new mirror node runs snapshot sync for the repository in question. After the snapshot sync has completed, the new mirror node participates in sync operations for the repository.
- When a mirror rejoins a farm, the farm vet is run to detect any repositories that have become out of date, so that only repositories that have changed since the node was last part of the farm can be synced. This means the time to rejoin a mirror farm is vastly reduced.
- Once all repositories have been synced, the mirror node advertises its availability to the load balancer and begins servicing Git hosting operations.
Panic stations
No engineering fable is complete without a story about going down the wrong path. When we first designed mirror farms, we planned on using Git namespace support to differentiate between the refs that a mirror node was aware of and the refs that could be safely advertised. We discovered later that the namespace support is not complete. Certain Git features just did not play nice with namespace support, one example being default branch support. This was a heart-stopping moment – would it be back to the drawing board for the whole mirror farm design? Luckily we realized that a simple workaround was to fetch objects without pointing any refs at them and simply update refs when the mirror was ready to advertise the availability of those objects.
CAP
Most developers have heard about CAP theorem. First, a quick refresher: CAP states that under a network partition, a distributed system can choose between Consistency or Availability. In other words, when building a distributed system, you must choose either CP or AP. What choice did smart mirror farms make?
The team spent a lot of time thinking about how we would achieve consistency in our mirror farm. This document has gone through quite some effort to explain the consistency approach we took. There are a number of guarantees the mirror farm system provides, but does this mean that mirror farms are a CP system? No! We made the decision early on in the mirror farm project that we would build an AP system, so that in the case of a split-brain caused by a partition, we would server a potentially stale repository and allow Git to detect that it was out of date rather than remove several mirror nodes from the farm, which could result in a cascading error failure mode.
Upstream stability
Another important design goal was that even the largest mirror farm installation(s) would not affect the stability of the upstream server.
Git is resource hungry, especially for CPU and memory. To protect these resources, Bitbucket Server makes use of a ticketing mechanism where each hosting operation acquires a ticket, and if there are no tickets available, the operation waits in a queue for some amount of time before timing out.
We considered making use of the existing ticket bucket for mirror operations, but this had a couple of disadvantages. If the upstream is queuing hosting operations, that would mean those mirror operations would need to wait in the same queue, potentially delaying builds by up to five minutes. A large number of mirrors operating at the same time could also lead to queuing for interactive users.
One of the key insights we had while researching this problem is that the amount of CPU/memory consumed while generating a pack file is strongly correlated to the number of commits included in want lines, as well as the recency of those commits. In other words, requesting the single most recent commit even for the very largest repositories only consumed a tiny fraction of the resources that a full clone would consume.
The solution we decided upon was to introduce a new ticket bucket, to be used exclusively by smart mirror farms. This has the advantage that hosting operations from smart mirror farms are prioritized separately to requests from other sources. We also know with a high degree of certainty that the resources consumed by these incremental fetches are small compared to a full clone or a larger fetch. We can optimize the shape of this bucket appropriately (number of tickets available and the maximum amount of time spent waiting for a ticket). The one place where hosting operations for a mirror to an upstream does not go through the mirror ticket bucket is during the initial fetch used during the mirror join process, or when a new repository is added to a mirror.
Testing at scale
Before releasing smart mirror farms to our biggest most demanding customers, we wanted to stress test mirrors under extreme conditions that they are unlikely to ever experience in the real world. The theory was that if smart mirror farms could make it out of our test labs unscathed, they would be able to handle anything our customers could throw at them. This included tests such as setting up large mirror farms with tens of nodes pausing, then resuming the mirror process on these nodes continually using SIGSTOP and SIGCONT, having new nodes join while the farm was under extreme load.
Trikit
One of the problems we encountered fairly early on while doing load testing was that the resources consumed by the Git client when cloning and fetching repositories would quickly saturate a single worker node. We developed a tool to help us get around this limitation called Trikit. The way Trikit works is that it understands the Git pack protocol and can “trick” a Git server into serving a pack file. Rather than spending resources decoding the pack file, it is sent straight to /dev/null, meaning that a single worker machine can replicate hundreds of clients, dramatically simplifying load testing. Trikit is in the process of being open-sourced.
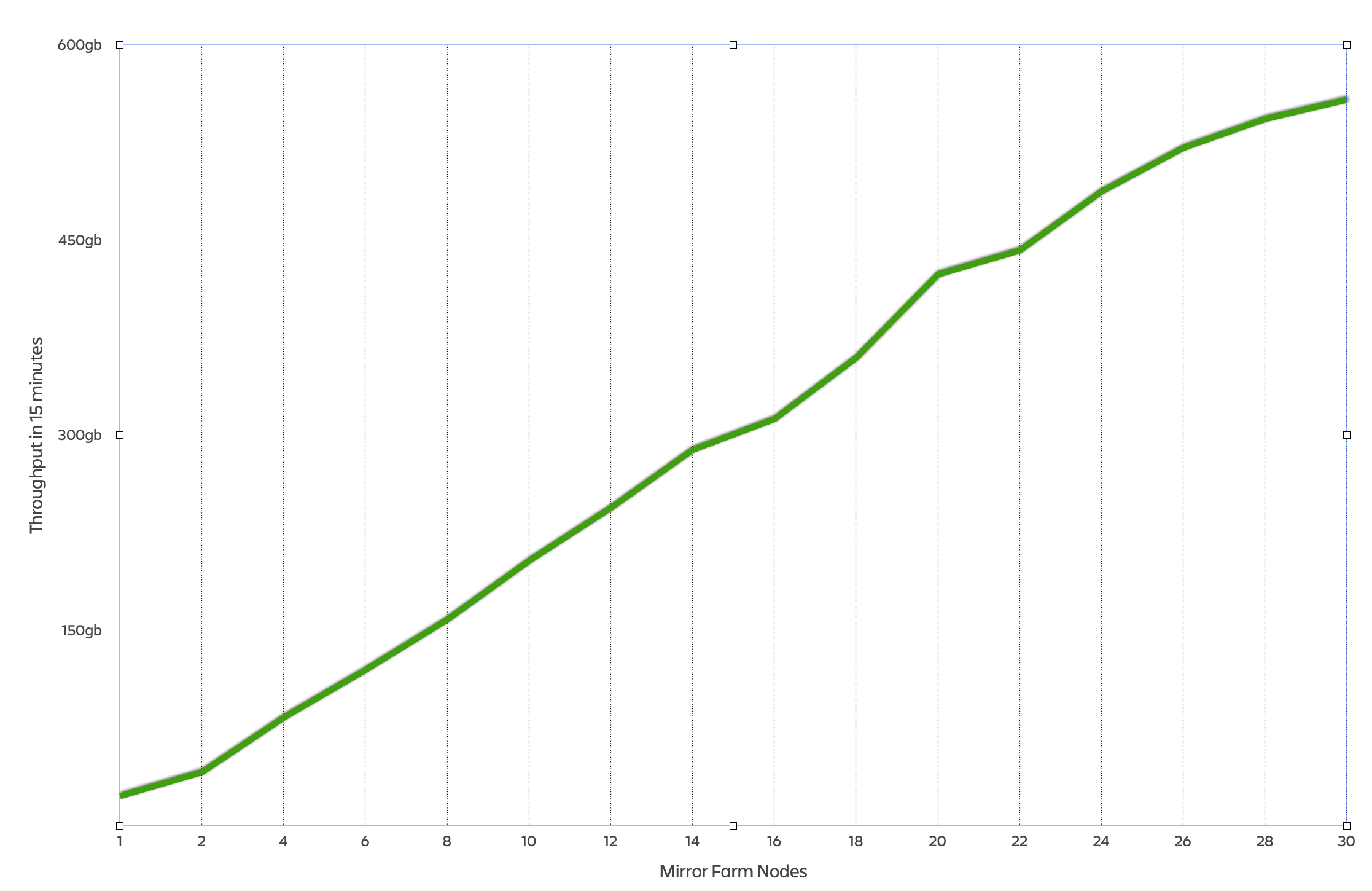
Results
The output from one of our test runs. As you can see, the mirror farm exhibits almost linear scalability up to 30 nodes. In this performance test, we started to hit the throughput limits of our load balancer at about 26 nodes.
Tradeoffs
We managed to write a fault-tolerant, self-healing distributed system that scaled out and exhibits something approaching linear scalability when doing so. What sort of tradeoffs were made to achieve this? We discussed the CAP theorem earlier, but what about the PACELC theorem? This theorem states that in a distributed system there are further tradeoffs that a designer must make beyond the Consistency vs. Availability tradeoff, and that even in the absence of a network partition, a distributed system must choose between latency and consistency. In the case of mirror farms, because we wait for each node to acknowledge a “write” before moving on to the next step of the consistency algorithm, we fall on the consistency side of this choice. What this means in practice is that, as more nodes are added to a mirror farm, the cycle time will increase. This is a tradeoff we verified with customers in the design phase. The customers we spoke to were happy to trade off a small increase in cycle time for what is effectively unlimited, elastic Git hosting capacity. We measured the increase in cycle time using latency heat maps, one of which is included below. It was taken during an experiment where we scaled from 1-10 nodes.
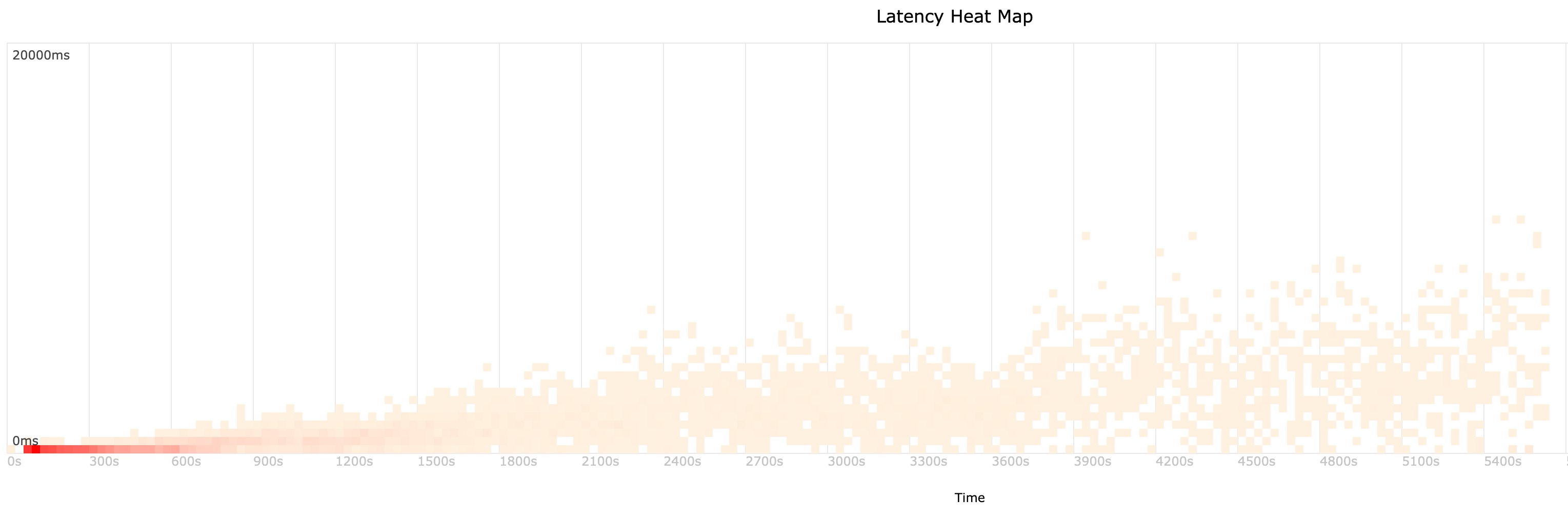
In practice, we find that for the majority of operations, the sync cycle time is in the low single digits, and that this holds true even for large mirror farms.
This is a graph taken from the monitoring of our own internal mirror farm over the past month showing a latency heat map of the 99.9 percentile end-to-end synchronization time. This chart shows that, even in the 99.9 percentile, the slowest sync operations generally stay in the 10-second range.

Conclusion
Building a distributed system is hard. Every decision and tradeoff needs to be carefully considered. The team spent a lot of time thinking about the farm vet and how we would recover from errors. Some of these processes we have not covered in this blog post include:
- How to recover from distributed locks failing – either being acquired by two nodes at once or a lock not being released correctly – which was solved by introducing a lock harvester.
- What happens when an operation fails? When do we retry and how many times to retry? What sort of backoff should we use?
- Metadata consistency, how metadata is synced, and how mirror farms self heal when metadata is out of sync.
- What happens when a repository is pushed to while the farm sync process is running for that repository? What happens if this occurs multiple times a second, how do we prevent duplicate “no-op” sync events from taking up time that could be better spent syncing real changes?
- How do we stop the farm vet from detecting the same error on multiple nodes and triggering excessive snapshot sync operations?
- The process that authenticates a new node to the farm and exchanges secrets.
The topic of distributed systems is fascinating and enjoyable work. I hope this blog post has given you insight into the steps we took to ensure that mirror farms would be scalable, reliable, and low maintenance under the most challenging conditions.

