
Scaling, rearchitecting, and decomposing Confluence Cloud
This blog covers the journey of Confluence Cloud – the team workspace for collaboration and knowledge sharing used by thousands of companies – and how we aim to take it to the next level, with scale, performance, and resilience as the key motivators.
Moving Confluence to a stateless multi-tenant architecture
In 2015, Atlassian started a project to move Confluence from a single-tenant architecture to a stateless multi-tenant architecture based on AWS services, codenamed Project Vertigo. You can read more about that project and the challenges we encountered in this blog post.
Vertigo was successful, and took advantage of AWS infrastructure to enable better scale, reliability, and performance, as well as frequent and seamless deployments. This was a significant step towards a multi-tenant stateless architecture and gave us the ability to onboard new customers faster. Over time, we began to see certain bottlenecks at scale.
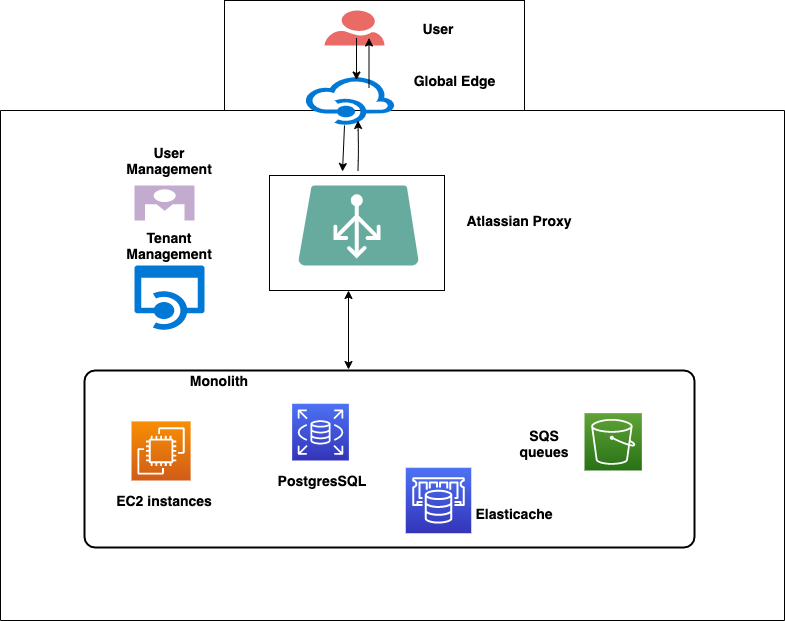
The following diagram shows a high-level overview of the Vertigo architecture.
The above figure gives a simplistic view of a region. Every region has multiple tenant shards in it. Each shard is a logical grouping of nodes and resources for a set of tenants and contains the following resource types:
- Amazon RDS for PostgreSQL databases
- Amazon Simple Queue Service (SQS) queues
- Amazon EC2 instances for compute nodes, which can serve as web-server nodes, which can process HTTP requests
- Amazon EC2 instances for worker nodes, which can process the messages from the queues and be scaled out accordingly
- Amazon Elasticache for Memcached
Tenants are deployed in a shard, which gives them the best performance based on their traffic patterns. Amazon RDS for PostgreSQL database instances are provisioned per shard, and every tenant has a dedicated SQL database on the RDS instance. To avoid noisy neighbor issues, we enforced limits on the number of database connections each tenant can get. We also have limits on the number of connections per Java Virtual Machine (JVM) for a tenant. For addressing the search use cases, we rely on external platform services known as Search and Smarts, which take care of addressing the scale, performance, and relevance issues.
Scalability challenges requiring architecture changes
Even though Vertigo enabled our web server and worker nodes to scale out with traffic, the database could not, and we began seeing bottlenecks at scale. Database connections became critical in the multi-tenant architecture and, since the architecture was still based on a java-based web application similar to our server products, we saw requests taking longer to release DB connections. When the DB connections were exhausted, our customers would see an increase in errors, especially during peak traffic. Async workers were also adding load to the database, further exacerbating this problem, and we had to throttle them during peak times to ensure web-server nodes would have sufficient database connections to serve user requests. Hence we needed to revisit this architecture.
In short, we needed to reduce the load on the existing monolithic database. The following issues are what we set out to solve:
- Scale: With the database connections becoming the bottleneck, we wanted to opt for an architecture where we could scale horizontally and optimize for performance. We chose to decompose the most expensive tables into different services that are each responsible for their own data, thus reducing the calls made to the monolith DB. We analyzed and identified queries to the RDS, looked at our metrics and logs, and found the CPU and runtime for the queries taken in the RDS. This helped us find the ideal candidates to decompose out of the monolith and move to separate services. We explored the options of having read replicas with Amazon Aurora in the monolith, versus using Amazon DynamoDB to achieve horizontal scaling. For our use cases for decomposition, we found Amazon DynamoDB was a better fit for the latencies we were looking for. It’s a key-value and document database that delivers single-digit millisecond performance at scale.
- Reliability by reducing the blast radius: We needed to ensure our customers were getting optimal performance in a multi-tenant architecture. A bad request taking up resources and affecting other tenants’ performance and reliability was not acceptable.
- Team autonomy for clear ownership and developer velocity: We need to ensure clear boundaries so that developers can be more productive and more confident rolling out their changes. With the autonomy of every team owning their service, we would be able to deliver features more frequently to our customers.
We developed a series of principles to help govern how new services would be built:
- Multi-region deployments: We currently deploy all new services to six regions: US East (N. Virginia), US West (Oregon), EU (Ireland, Frankfurt), Asia Pacific (Singapore and Sydney). All new services we build must be deployed in multi regions and not be bound to a single region. Tenants are located in one of these six regions and make calls to the new services in that region to avoid cross-region calls.
- Low Latency: For new services, we aim to be as low latency as possible. This can be achieved by following patterns of latency-based routing, caching optimizations, and global replication of data wherever possible.
- Security: All new services are designed with encryption at rest from the ground up. Additionally, we restrict which specific services can call the endpoints of the new service by maintaining a whitelist of authorized issuers who can call a particular service. That way we ensure our endpoints are protected by proper authentication.
- High availability: Ensure there are multiple Availability Zones (AZ) per region. We periodically test for AZ fail-overs and make sure our services can handle it well. For non-User Generated Content (UGC), we can replicate globally across six regions and can fail over requests to other regions whenever there is an issue.
- Constant focus on metrics: Our team is focused on automation, anomaly detection, and alerts for latency and reliability issues, and optimizing for the best user experience. We do progressive rollouts across regions and watch for error rates via anomaly detection, and do automatic rollbacks if we see any issues with the deployed changes.
- Operational Excellence: Apart from deploying these services in multiple regions, we added operational tools to make on-call engineers’ lives easier. We realize that when there are incidents or an on-call individual is paged, we need to have clear and tested run-books and operational tools that can be leveraged. We also focus on regular war games to make sure people are trained for incidents.
Solving the problems with a new architecture: introducing Burning Man
Before we get into the details of Burning Man – the code name for the new architecture we created – let’s take a quick digression and talk about an architectural wonder of the west, the Hoover Dam.
Hoover Dam
This is the Hoover Dam, an engineering and architectural wonder of the 20th century. The Hoover Dam was built to control the Colorado River and provide water and hydroelectric power for the southwestern United States.

Technical challenges and fun facts
The Hoover Dam is as tall as a 60-story building. Its base is as thick as two football fields are long. When completed in 1936, it was the world’s largest hydroelectric power station.
Before this architectural wonder’s actual construction could begin, the Colorado River had to be diverted around the dam construction site. It was a daunting, difficult project. Building such a mammoth structure presented unprecedented challenges to the engineers.
The diversion of the Colorado River through canyon walls ranks as one of history’s greatest feats of engineering – and the diversion tunnels were just a preliminary requirement for the bigger task at hand!
What does the Hoover Dam have to do with Burning Man?
As mentioned above, we decided to invest in a Confluence Cloud architecture that was designed for the cloud first, for scale, and with principles of low latency, high performance, scalability, and resiliency in mind. To achieve this goal, we started off with a small team. Just like the Hoover Dam needed some groundwork and diversion tunnels, we needed to do some preliminary work to route our traffic. We started by building two new backend services – designed for the scale of Confluence Cloud, resilience, and performance – from the ground up.

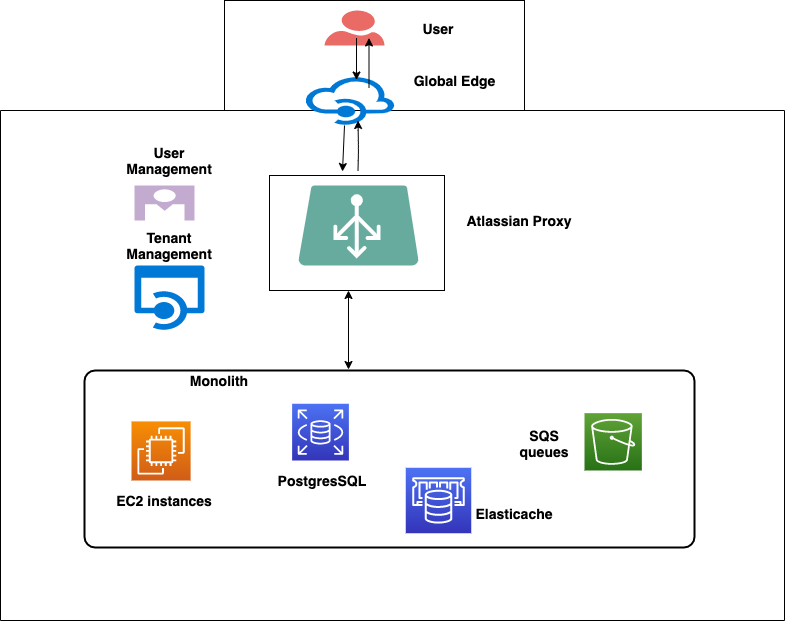
In the figure above, all new Confluence Cloud services are prefixed by “cc” (cc-proxy and cc-ledger) and were the first few new services started by the team. Let’s dive into more on these services. We show the monolith just as before, with Amazon EC2 instances, Amazon RDS for PostgreSQL databases, and Amazon Simple Queue Service (SQS) queues. New decomposed services are using Amazon EC2 instances, Amazon DynamoDB, and Kafka for certain low-latency use cases.
cc-proxy
This is a low latency, high throughput, critical service that lies between the Atlassian Proxy (AP) and Confluence, serving around 30K requests per second under 25ms with a 99.99% success rate. It uses NginX and Lua. All requests from the AP are routed to the cc-proxy service. The cc-proxy then consults the cc-ledger, which will tell it to route to Old stack or New stack. Old stack is the monolith. New Stack is the decomposed services that are rearchitected for performance and scale. The response from cc-ledger will have the region and the URL to route the request to. In simple terms, for if a Tenant is named T1 and, say, a Content of the tenant has an ID “C1,” if this query is sent to cc-ledger, then cc-ledger will let cc-proxy know how the request should be routed. The response from Ledger will have old or new stack along with other metadata needed for routing.
cc-proxy takes this response and forwards the request to the right stack. With this granular level of routing, we can gradually switch traffic for certain tenants and specific content to the new stack. This ensures that we can control our rollouts, and if there are any issues, we can always update the entries to fall back to the monolith.
Low latencies are achieved by having the service deployed in each region and having DNS aliases and latency-based routing with Amazon Route53.
cc-ledger
This is a low-latency, high throughput, critical service built from the ground up using principles of asynchronous reactive streams with non-blocking back pressure. The goal of this service is to provide information regarding the stack to route the request with low-latency lookup. To achieve this, we used Spring Webflux, multi-region, Amazon DynamoDB Global Tables. We also use Amazon DynamoDB accelerator (DAX), which is a managed, highly available in-memory cache that delivers high performance at the scale of millions of requests per second. DAX provides a write-through layer for DynamoDB and seamlessly integrates the caching logic in the application – this was one of the core reasons we chose DAX.
The cc-ledger stores mapping of tenantId:contentId → {old_stack or new_stack} along with other metadata required for routing. If a page can be rendered by the new stack, cc-ledger sends a response to the cc-proxy, which will then take care of routing the request accordingly to the new stack or default to the old monolith.
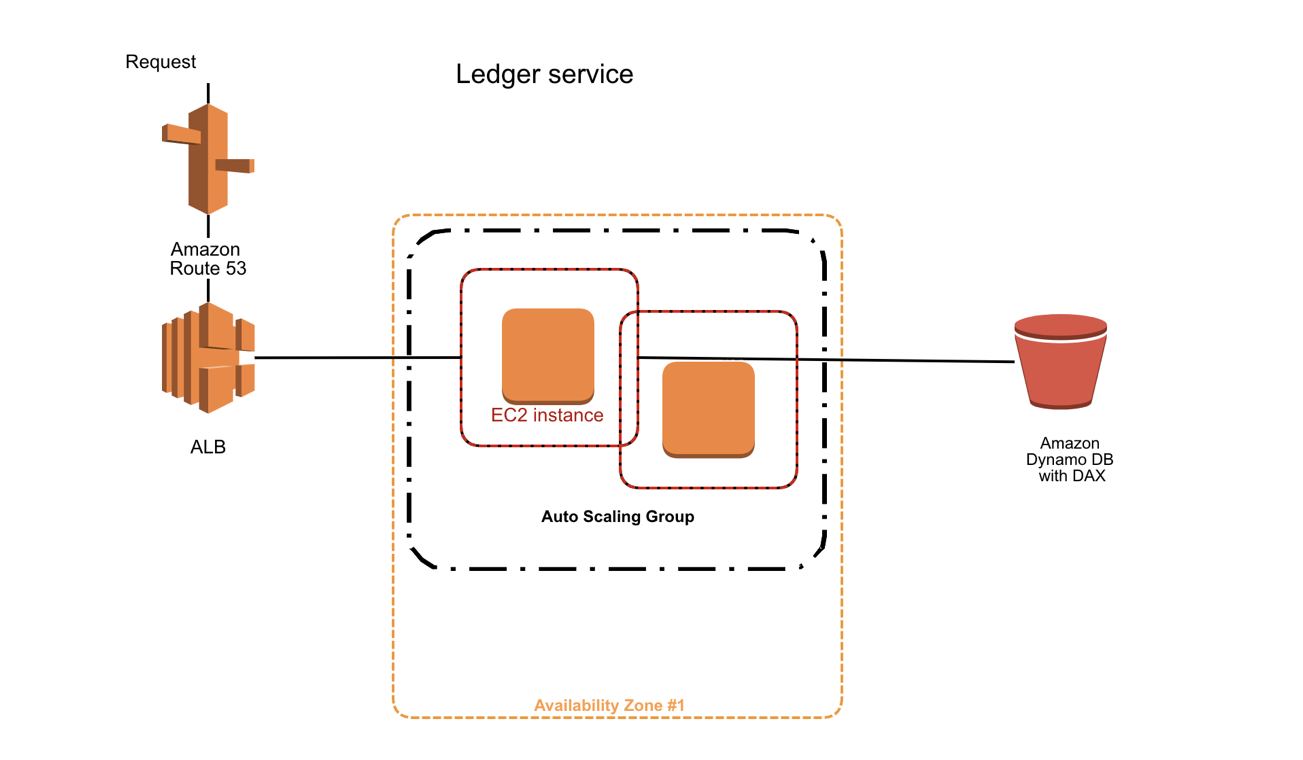
The above figure shows our deployment for the cc-ledger Service. We use the Amazon Route 53 and Amazon Application Load Balancer (ALB) for request routing. We have multiple Amazon Elastic Compute Cloud (Amazon EC2) instances as part of the Auto Scaling Group in an Availability Zone in a Region and Amazon DynamoDB with DAX.
As we decompose additional microservices, we are using this routing logic to ensure traffic moves away from the monolith and to the new services.
Routing content through these services
It was imperative that the transition between the old and new stack would be seamless for our customers. As we built these services, we started routing low-traffic pages such as Page History and Onboarding from new tenants to the new stack. Any other content would be routed to the old stack.
How was traffic routed?
At first, we cautiously routed the traffic for Page History and Onboarding pages through these services with proper plans and very slow rollout to selected tenants in the us-west region. We watched metrics for latencies and error rates. Once we were confident that the services were handling the load well, we expedited the rollouts to all tenants in the five regions. This is the same policy we follow now for any of our decomposition projects – we start slowly with cautious rollouts. We also tested for region fail-overs and made sure our services would work even if an AWS region went down.
What’s next for decomposition?
We are now building on top of this architecture and focusing on rendering comments on each page so that they can be routed to the new decomposed service and not get the data from the monolith. Once we move the comments to new micro-services and away from the monolith, we will start rendering the actual page content from the new services. Stay tuned for future blogs on how we successfully moved out other types of content to the new micro-services while handling the traffic at scale.
In conclusion, just as diversion tunnels were instrumental in the success of the construction of the Hoover Dam, we focused heavily on building the right infrastructure for request routing, on which future decomposition projects can be built reliably.
Acknowledgements
We would like to acknowledge the team behind these efforts: Mikhael Tanutama, Parag Bhogte, Igor Katkov, Neha Bhayana, Gene Drabkin, Yaniv Erel, Ran Ding, Ilia Fainstroy, Robin Wu, Saravana Ravindran, Jeevjyot Singh, Matthew Trinh, Pramod Khincha, Ali Dasdan
This is the first step in the journey for decomposing Confluence Cloud. There are lots of opportunities to tackle tough problems related to scale, resilience, and performance; making an impact; and paving the way for the future of Confluence Cloud. If you are passionate about these areas, feel free to contact us for opportunities here.