
Migrating complex CI/CD workflows in Bitbucket Cloud
In late 2021, we fully migrated Bitbucket Cloud from a data center to AWS to improve reliability, security, and performance. One of our focus areas in this massive project was migrating complex CI/CD (Continuous Integration / Continuous Delivery) workflows to Bitbucket Pipelines. We wanted to optimize release times and eliminate inefficiencies so we could provide Atlassian customers with newer features faster.
A large part of Bitbucket Cloud is a Django Python monolith that’s operated by hundreds of engineers on a weekly basis. Scaling deployments to a monolithic architecture with shared ownership between product teams was a challenging goal.
In this post, I’ll share how Bitbucket cloud developers, managers, and site reliability engineers worked together to migrate our CI/CD workflows from Bamboo to Bitbucket Pipelines and how this project helped us scale our engineering processes.
What it was like before the migration
While our data center served us well for many years, operating one came with slower production releases and risks, especially as we scaled. These issues were mainly caused by:
- a CI/CD pipeline fragmented across multiple tools (mainly Bamboo and Bitbucket Pipelines). This back and forth between tools added complexity and required frequent manual intervention from different teams.
- only release managers having the ability to deploy to production, causing bottlenecks.
- slow tests and deployments, leading to a higher failure rate.
How we migrated our CI/CD workflows from Bamboo to Bitbucket Pipelines
Team engagement
From the beginning of the project, the core migration team ran several initiatives to make sure we were listening to all Bitbucket engineers and had a complete understanding of what had already been done, what needed to be done, and how to best tackle that work.
- Developer survey: Initially,we ran a developer survey to get feedbackon the current deployment process. We wanted to understand the technical aspects that we initially not familiar with (like legacy deployment tooling) and gauge the sentiment from our engineers about our current status quo.
- Deployment champions: After that, we created a community of engineers from each team who worked closely with us and communicated changes or decisions that were made to their teams.
- Sharing technical knowledge: We created an internal home page for our deployments, containing runbooks and tutorials for every engineer to trigger deployments or troubleshoot issues with the release pipeline.
- Frequent cross-team communication: Throughout the process, we organized informational sessions and constantly shared our plans, achievements, and vision with all teams in Bitbucket Cloud. This allowed all engineers to participate and gave us the opportunity to engage with their ideas and feedback.
Measuring CI/CD efficiency
After our developer survey, we defined the following metrics so we could identify bottlenecks and benchmark our current state before we began the migration.
| Metric | Our current state before the migration |
|---|---|
| Pipeline build time measures how long it takes to run a complete pipeline execution. It looks at the time taken by automated tasks. | Our pipeline build time was taking more than six hours (just compute time, without taking into account waiting times), caused by slow, serial processes or duplicate processes. |
| Pipeline lead time is the time it takes to go from code merged to code successfully running in production. It measures the time taken by both automated and manual tasks (code review, manual approvals, etc.). | Our lead time was several days, caused by soak time, long review periods, waiting periods between timezones, etc. Releases were only being done during United States timezone, which caused long waiting periods for engineering teams in Australia. |
| Pipeline failure rate measures how often failures occur in the production pipeline that require immediate remedy. | Our failure rate was high, causing delays in deliveries to customers and increasing engineering frustration. |
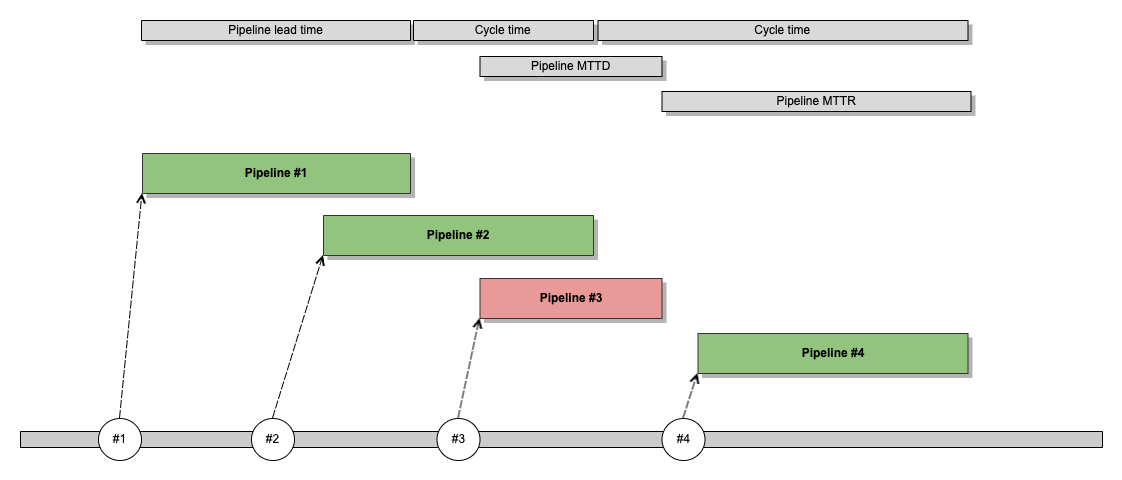
| Pipeline mean time to detect (MTTD) measures how long it takes from when a “defect” is introduced to the pipeline till it is found (the pipeline fails). | Defects were found too late in the pipeline, mainly caused by slow tests and poor unit test coverage. Most defects were found during post-deployment or integration testing. |
| Pipeline mean time to recover (MTTR) measures how long it takes from when a “defect” is found (the pipeline fails) until the pipeline is green again. | Defects took too long to resolve caused by lack of visibility and knowledge from product teams to understand and fix pipeline-related issues. This impacted deployment frequency and cycle time, delaying code being shipped to customers. |
| Deployment frequency tells you how often you are delivering value to end users, so the number of deployments per period of time. | Our deployment frequency was low (one to two times per week), caused by all the reasons listed above. At the same time, this caused code changes to accumulate, increasing the risk of incidents in releases. |
Once we identified and quantified the bottlenecks, we created a plan to improve these metrics incrementally across several milestones.
Designing an end-to-end CI/CD pipeline in Bitbucket Pipelines
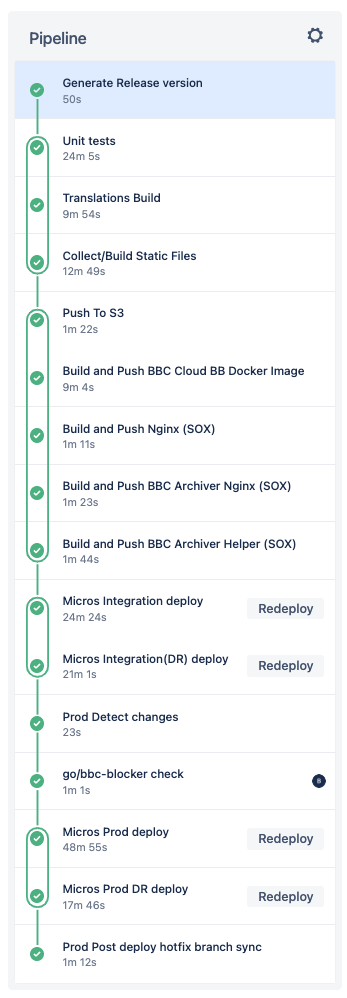
Our release pipeline was composed of multiple build plans configured across Bamboo and Bitbucket Pipelines. Only release managers operated the CI/CD pipeline, so engineers didn’t know how to track the status of the release or fix broken releases. This situation impacted overall dev speed and MTTR during incidents.
To address this, we simplified our CI/CD pipeline and build a unified end-to-end view of our releases in Bitbucket Pipelines. This lead to:
- Unified pipeline visibility: Developers could see a unified view of the pipeline so they had complete visibility and were able to track progress.
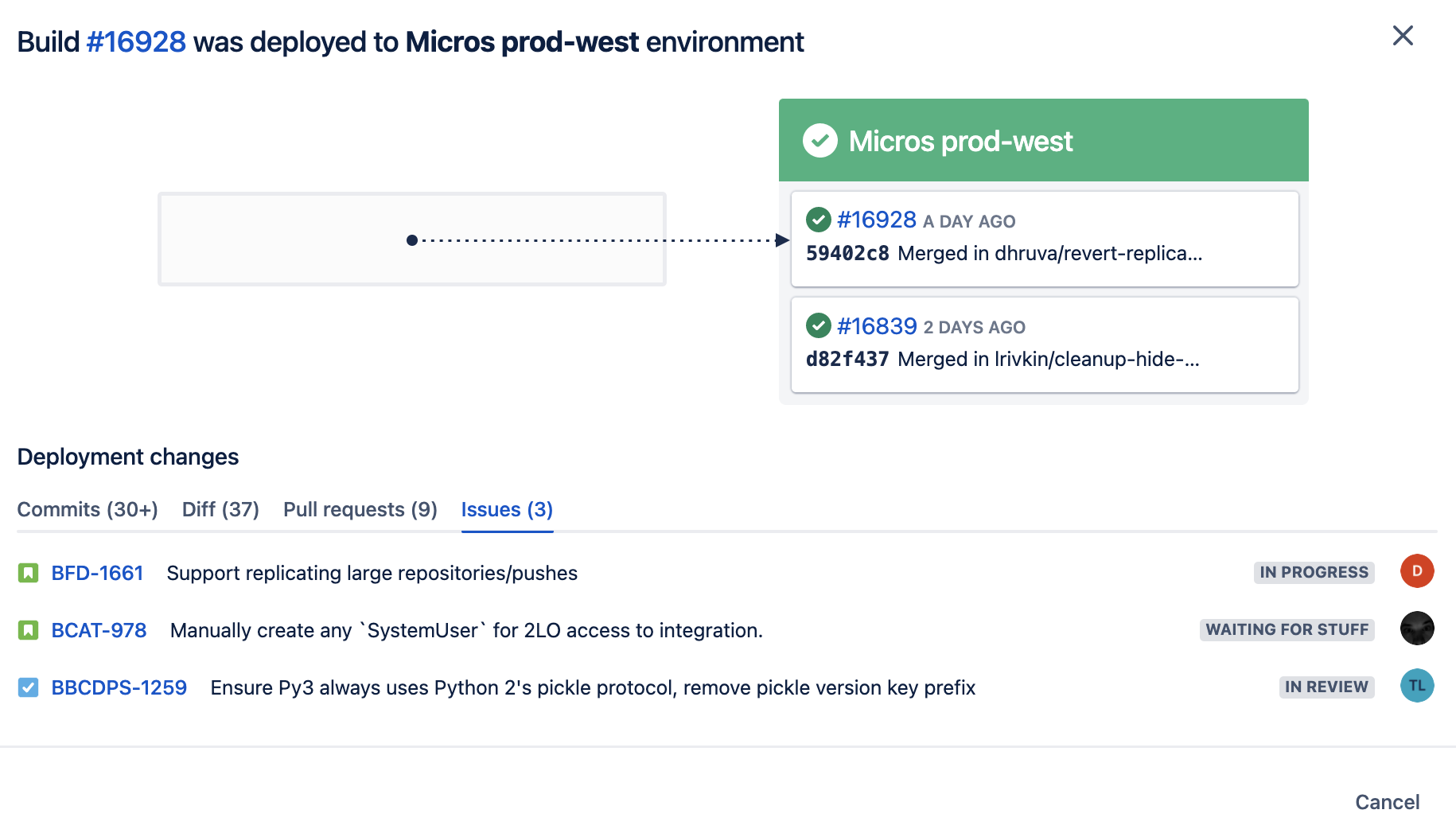
- Tracking deployments: With Bitbucket Pipelines’s deployment dashboard, engineers and managers could track the code, Jira tickets, commits, and pull requests introduced in every release. This helped track what we shipped in each release and kept the right teams informed via Jira and Bitbucket Cloud.
- Scaling tests: We were able to scale our CI/CD processes by running more tests in parallel. This is possible because Bitbucket Pipelines scales well due to our underlying reliance on Kubernetes.
- Faster failure and incident resolution: With more parallel tests, we could find defects much faster (reducing Pipeline MTTD) and with more transparent pipelines and code tracking, developers could fix defects faster (reducing Pipeline MTTR).
Iterative migration process
Migrating a monolith with hundreds of weekly active developers from Bamboo to Pipelines was not an easy process since we couldn’t stop our delivery process to re-engineer some areas. We had to do it live. The migration from Bamboo to Pipelines was done in an iterative 3-step process:
- We designed and built the unified end-to-end pipeline in Bitbucket Pipelines, being the ideal CI/CD workflow we wanted our product teams to use, i.e. the end state.
- Next, within the unified pipeline, we configured some steps to trigger existing Bamboo plans using its REST APIs. We waited for the results from the Bamboo plan before moving on to the next step. At this point, we were managing and tracking the unified pipeline in Bitbucket Pipelines but Bamboo was still being used as the underlying tool.
- Then gradually, we started migrating steps from Bamboo to Pipelines, to be executed directly in Bitbucket Pipelines to reduce computing costs and simplify the troubleshooting experience. As part of this migration, we also re-architected some plans in Bamboo and moved them to Docker containers. This made it easier to port to Bitbucket Pipelines. All of this enabled us to run the same code in both CI/CD platforms, reducing the risk of any divergence that could introduce regressions in the build process and impact the product teams.
Our strategy ensured we could get the benefits from a unified end-to-end pipeline early on, and also gather feedback from product teams to keep iterating. Also, it didn’t introduce blockers or dependencies to product teams since we could introduce changes incrementally.
Optimizing the pipeline
The old CI/CD process had six manual steps to complete the end-to-end process, as shown in the workflow below. For example, each release required creating a release branch and manually re-approving the changes made by every author. Manual steps introduce the potential for error and also add extra time to the pipeline lead time, which impacted our ability to troubleshoot issues and fix bad deployments or incidents in a timely manner.
We firmly believe that manual intervention should not be required in the release process. We audited and removed every unnecessary step until we had highly automated “push-button” releases.
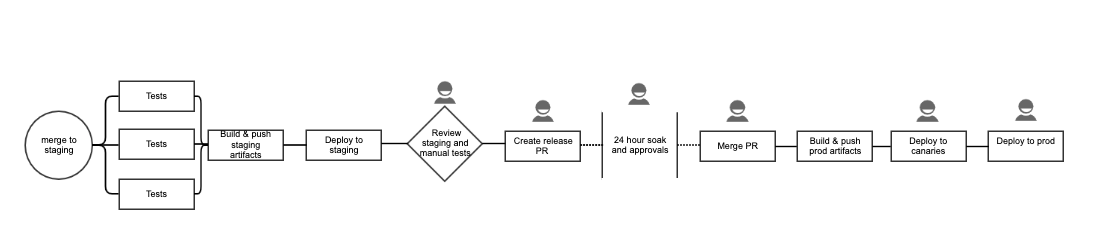
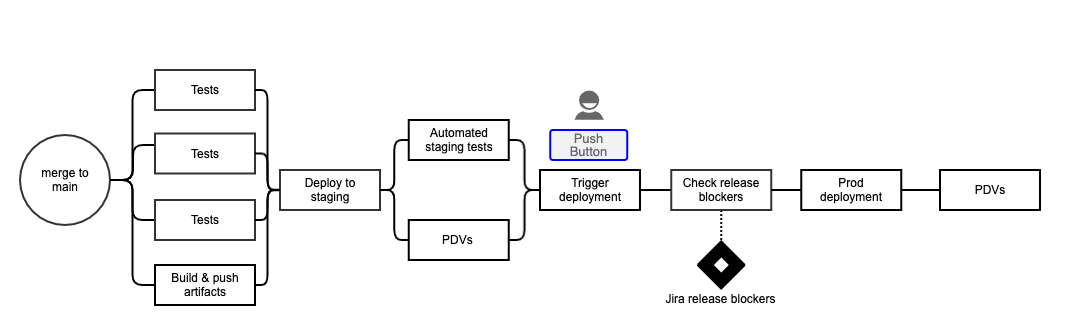
The results
We spent several months re-architecting our CI/CD by migrating to Bitbucket Pipelines. Along the way, we made many other necessary improvements such as moving to trunk-based branching model, building immutable artifacts, and using Jira to block releases.
This migration enabled all engineering teams in Bitbucket Cloud to ship code faster without compromising quality. Plus, our engineering team was more motivated and happier with the simplified and transparent process.
Here’s how our metrics improved after we completed the migration:
| Before | Now | |
|---|---|---|
| Pipeline build time: compute time from merge into main branch to run in Production. | 6+ hours | 1h 30m |
| Pipeline lead time: lead time from merge into main branch to run in Production (normal deployments). | ~ 2 days | As fast as 1h 30m |
| Deployment frequency | Up to once a day | Multiple times per day |
| CI/CD Strategy | Continuous integration | Ready for continuous deployment |
| Branch strategy | Long-lived branches per environment | Trunk-based |
| Who releases? | Release manager | Everyone (engineers and managers) |
| Where releases happen? | Only United States | Everywhere (United States and Australia) |
What’s next?
There’s always room for improvement. We are now working towards continuous deployments (making every merge deployed to production automatic) in order to eliminate the last remaining manual step in the delivery process. Moving to continuous deployments in monolith architectures is especially difficult due to the overall time required to build, test, and deploy.
If you found the work in this post interesting, consider applying to our open Bitbucket Cloud roles!