



Introduction
A year ago, we began addressing flaky tests to enhance the Continuous Integration (CI) experience within our monorepo. A manually managed file-based system was in use; however, it presented several challenges, including a complex workflow, no customisations, no actionability, a single point of failure, and difficulties in scaling. As we progressed in enhancing our CI ecosystem, it became essential to establish a system that is effective, scalable, and configurable. This system must be easily adoptable and designed to minimise friction in developers’ workflows. In response to this, we developed a platformised, tech stack agnostic tool, designed to detect, manage, and mitigate flaky tests across all of our codebases effectively: Flakinator Flakinator.
Before we delve into our solution, it is crucial to grasp the problem’s intricacies and underlying significance.
What are Flaky Tests?
Flaky tests are the bane of any software development team. They fail sporadically without any changes to the underlying code, leading to mistrust in test results, wasted debugging efforts, and disruptions to CI/CD pipelines.

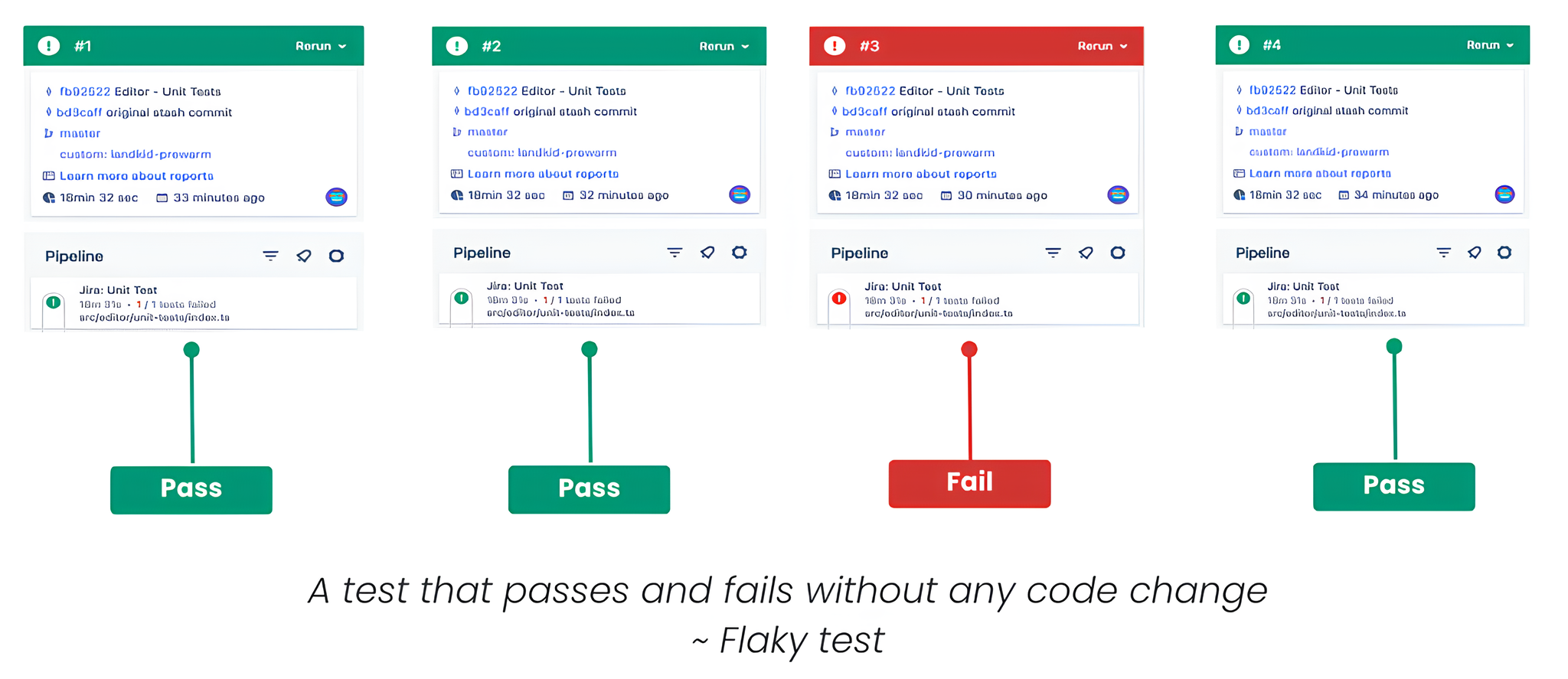
Hidden Cost of Flaky Tests?
Non-deterministic behaviour that leads to random failures creates inefficiencies, forcing developers to repeatedly run builds. This not only consumes valuable engineering hours spent troubleshooting tests that should ideally yield consistent results, but it also diminishes developer satisfaction.






Why is it a Big Deal?
Flaky tests are a well-documented problem in the software development lifecycle (SDLC), and several studies and industry insights highlight the severity of their impact.
- In Atlassian,
- Test flakiness has been a significant contributor to build reliability issues in the past, responsible for as much as 21% of master build failures in the Jira Frontend repository.
- Approximately 15% of Jira backend repo failures are attributed to flaky tests, necessitating reruns that ultimately waste over 150,000 hours of developer time each year.
- A study by Microsoft Research on flaky tests in their CI systems found that 13% of their test failures were flaky, highlighting that even mature CI pipelines are not immune.
- A Google study of its internal testing systems found that 16% of test failures were determined to be flaky rather than actual bugs.


Key Quotes from Research
- “Flaky tests are one of the most time-consuming and frustrating issues in software development. They undermine the trust in automated tests and lead to significant inefficiencies in CI/CD pipelines.” – Google Research
- “Flaky tests are not just a result of poor test writing; they’re often a symptom of deeper architectural or environmental issues.” – Microsoft Research
Introducing Flakinator
Flakinator serves as an essential offering for our Atlassian products, enabling teams to focus on delivering features and improvements rather than being bogged down by the unpredictability of flaky tests.
Relentless pursuit of flaky tests and their ultimate elimination
Flakinator Capabilities
Efficient Identification
Utilize advanced algorithms and machine learning technologies to efficiently identify flaky tests
Quarantine Mechanisms
Provides an ecosystem to isolate flaky tests from CI pipelines, while still tracking them for review and resolution
Trend Analysis and Reporting
Dashboards which offer insights into trends and patterns over time
Root Cause Analysis
Diagnostics that flag flaky tests and provide in-depth analysis and actionable insights
Custom Settings
Enable teams to set thresholds and priorities based on their own product requirements for identifying flaky tests.
Scalable and Performant
Ensures that it can adapt to evolving needs of products, making it a long-term investment in quality and efficiency
User-Friendly Experience
Intuitive dashboards and easy setup, designed to be accessible to teams of all sizes
Collaboration and Communication
Seamlessly integrates with other tools like Jira and Slack, enabling prompt notifications and fostering a collaborative environment for tracking and resolving flaky tests.
Smooth Integrations
Easily fit into existing CI/CD ecosystem, ensuring transition doesn’t disrupt current workflows.
Design Overview
Flakinator sits in our CI infrastructure, expecting the test run data to be ingested through CI. The ingested records undergo transformation, with raw test data being stored for future use. Various detection mechanisms are implemented for different products to identify flaky tests within the system. Multiple consumers utilise this information, tailoring it to meet their specific needs and visualisations.


How the Ecosystem Works
A test is flaky when it produces inconsistent results across runs with the same code, passing sometimes and failing other times without code changes. Flakinator uses several algorithms to detect flaky tests. After detecting a flaky test, the code ownership system identifies its owners, creates Jira tickets with deadlines to resolve them, and sends Slack notifications if configured.
We collect signals for quarantined tests by running them in branch builds, scheduled jobs, or quarantine pipelines to gather results with the latest code changes. Test health is calculated from collected results. If a test remains healthy for a configured period, we remove it from quarantine and reintroduce it into the system. Monitoring and dashboards track quarantined and unquarantined test volumes. Once teams have resolved the underlying issues, the flaky test tickets are resolved and tests are and reintegrated into the system.
How It All Comes Together
Flakinator is built on a scalable, distributed architecture to handle the large volume of test data across multiple Atlassian products. Here’s an overview of the key components:


- Ingestion Pipeline to record Test Runs:
- A robust data ingestion pipeline collects test run data in real-time from CI systems, normalises it, and stores it in a centralised storage.
- Implemented scripts or hooks in the CI/CD to automatically capture metadata from each test run. This data includes test duration, execution environment, results, retry attempts, error messages and other metadata.
- Flakiness Detection Engine:
- Flakinator supports multiple detection mechanisms, all constructed upon a similar architectural framework.
- We use the Java and Kotlin ecosystems alongside numerous AWS components to effectively calculate, store, and serve test quality scores at scale.
- Various configurations are employed for different products to ensure customisation, and all of these configurations are driven by user preferences.
- Notification and Insights:
- The code ownership and notification module has been implemented to ensure that the relevant team members are promptly informed about the status of tests. This enhancement significantly improves communication and accountability within the team.Once a flaky test is detected, a Jira ticket is created for the owning team with pre-decided due dates to provide resolution. Additionally, the Flakinator Bot sends out Slack notifications to keep everyone informed.A user-friendly interface designed with React empowers developers to manage flaky tests effectively. Users can easily explore these tests, take actions such as silencing them, search by test type, and access linked builds along with historical run data for each test.
- Our system handles more than 350 million test executions per day, with high availability and fault tolerance.
- Our storage module is equipped with over 3TB of data for efficient operation and analysis.
Detection Algorithms
RETRY detection mechanism –
Rerun the failing test in the same build and use that data as a detection method to find flakes. The Flakinator CLI, integrated into the pipelines, checks whether failing test cases are already designated as flaky. If a test is not included in the flaky list, an implicit retry mechanism is employed to collect flaky signals, with the circuit breaking at the first occurrence of a flip signal. The number of retries is configurable and varies depending on the test type. When flip signals are received, newly identified flaky tests are logged in the database to enhance the efficiency of future builds. This approach has enabled us to achieve an impressive 81% detection rate for certain products.


For a test case history like below, the yellow ones are flakes. This information is the signal that we use for quarantining a test.


Bayesian Inference for Flakiness Detection
Bayesian theorem is a theorem in Statistics which provides a formula to calculate the Probability of an event A happening given that event B has already occurred. In other words, it’s used to update the probability of a hypothesis based on new evidence


Conditional probability is the likelihood of an outcome occurring based on a previous outcome in similar circumstances. Bayes’ theorem relies on using prior probability distributions in order to generate posterior probabilities.
Bayesian inference
In Bayesian statistical inference, prior probability is the probability of an event occurring before new data is collected. Posterior probability is the revised probability of an event occurring after considering the new information.
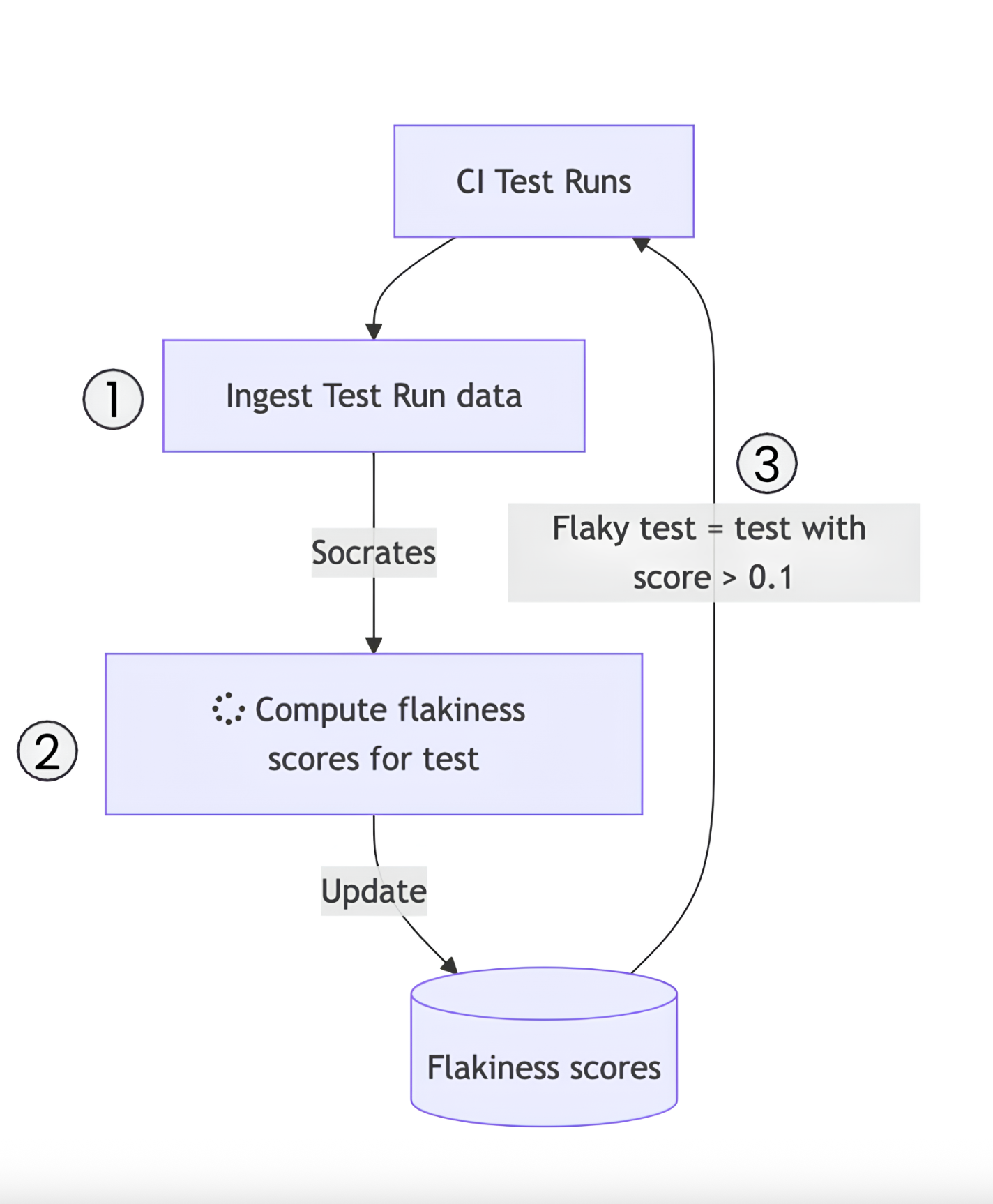
For the use case of creating a flakiness score for a test case, we use the prior probability distribution of a test case’s historic runs and create the posterior probability from it. The analysis/ inference component consists of 3 modules
- Historical Analysis: Utilise a moving window approach to analyse historical test run data, applying Bayesian inference to calculate the probability of a test being flaky.
- Signal Processors: To derive a comprehensive flakiness score, consider multiple signal distributions (e.g., duration variability, environment consistency, result patterns, retry frequency).
- Scoring: Assign a flakiness score between 0 and 1, where higher scores indicate greater flakiness.



An example of a low-quality test case where the test shows indeterministic results in CI across multiple commits


Results and Impact
Since deploying Flakinator, we’ve seen significant improvements in CI build stabilisation across our engineering products. This tool is currently utilised by over 12 products within Atlassian.
Flakinator has significantly impacted various Atlassian repositories by proactively detecting flaky tests and quarantining them to prevent build failures. This approach saves build minutes and reduces costs, resulting in substantial savings. It has an alerting and notification mechanism that notifies the team when it detects a flaky test and creates a actions for the team to own and fix the test to restore it to the system. As of the last quarter, Flakinator successfully recovered more than 22,000 builds and identified 7,000 unique flaky tests leading to considerable cost savings.
This tool enhances build reliability, conserves development hours, and reduces CI resource consumption by minimising the need for test reruns, ultimately accelerating time to market.


Metrics give teams visibility into their quality and performance tracking key indicators, for example, tracking the flaky test rate at a team level highlights which teams are contributing the most to pipeline instability, motivating them to prioritise fixing flaky tests. Data-driven insights also help teams and leadership forecast the effort and time required for specific tasks, such as reducing test flakiness in the packages owned by them.






Lessons Learned
Building a flaky test management system wasn’t without its challenges. Here are some of the key lessons we learned:
- Data Quality Matters: Inconsistent or missing test metadata can lead to inaccurate flakiness detection, so it’s critical to invest in reliable data collection.
- Iterate on Algorithms: No single algorithm works universally. Combining heuristics, statistical methods, and machine learning provided the most accurate results.
- Prioritise Developer Experience: A tool is only effective if developers use it. We focused heavily on building an intuitive UI and smooth integrations with existing workflows.
Future Plans
We are continuously improving our flaky test management tool. We plan to use machine learning algorithms to improve its ability to predict outcomes, identify patterns, and forecast issues. Our goal is for the tool to automatically fix flaky tests by addressing common problems such as timeouts, mocking failures, and environmental dependencies.
Flaky tests are an inevitable challenge in large-scale software development, but they don’t have to derail your CI/CD pipelines. By building a robust flaky test management system, we’ve improved build reliability, streamlined developer workflows, and saved resources across Atlassian.
We hope this blog inspires you to tackle test flakiness in your own organisation. Thanks!