
Introduction:
Jira Cloud is undergoing a substantial rearchitecture, moving its foundation to a cloud‑native, multi‑tenant platform built for massive scale, speed, and reliability. In this post, we’ll take you behind the scenes on why we’re making these changes, the architectural principles guiding us, and describe the services we are building to deliver consistently fast reads, highly reliable operations, and better developer velocity. Whether you’re an enterprise customer, a platform builder, or just curious about the journey, trade-offs, and what’s next, you’re in exactly the right place.
Setting the stage:
Jira Cloud began life with the Studio (later known as Unicorn) architecture, which essentially wrapped the same codebase used for Jira Server with additional cloud-specific layers. The core application logic, data models, and plugin system remained identical to the server version. That decision gave us crucial speed to market, considering a complete rewrite of Jira would have been prohibitively costly and risky. Although logical, this approach retained server-era assumptions unsuitable for a cloud application, the most important one being its single-tenant database.
It also brought to the cloud Jira’s early design choices. Back in 2005, Atlassian adopted the OfBiz Entity Engine, a minimalist ORM and schema-definition framework forked from Apache OFBiz, as the core persistence layer. This technology decision resulted in a heavily relational, normalised schema tightly coupled to a single RDBMS. This suited the era of on-premises, single-tenant server deployments, where much of the customer dataset could be held in long-lived in-memory caches, making repeated queries over the same data relatively cheap. However, this model increasingly misaligns with Jira’s requirements. Jira is a read-heavy application with a 10:1 read-to-write ratio, and in a multi-tenant architecture, caching most customer data in long-lived caches is neither feasible nor cost-effective.
Changing the architecture wasn’t only about new technology choices; it required substantial code rewrites to reshape access patterns. Historically, Jira was built as a plugin system. Jira core provided the backbone, and plugins hooked into that spine to modify or augment behavior. While this made Jira extremely flexible and extensible, serving a request required Jira to call many components and services outside the platform, making it hard to guarantee performance and reliability SLOs.
Over the years, we invested heavily to improve Jira’s performance and scale, but the ROI of these tactical improvements diminished. To take Jira to the next level of scale and performance, it was clear we had to undertake substantial re-architecture and evolve Jira to a cloud-native platform.
Additionally, the original server architecture tightly coupled the database and business logic, making it difficult to build cloud features requiring data replication beyond the Jira monolith. By transitioning to a cloud-native architecture, where data is replicated across multiple specialised services and reliable Change Data Capture (CDC) is the standard, we could unlock the ability to power more sophisticated features like the Data Lake and Rovo Search.
In summary, to support larger Jira Cloud customers with ambitious performance and reliability targets, and enable new cloud features, we addressed 4 main challenges:
- Transform Jira from a single-tenant database into a horizontally scalable multi-tenant platform that elastically adjusts to traffic growth on demand.
- Transition from a write-optimised monolith to a read-optimised platform. Allowing us to choose the appropriate trade-offs to improve the experience of key features.
- Redefine access patterns to achieve performance at scale by shifting from a pull model, where multiple services are called to serve the request, to a push model, where data proactively enters the platform, and the platform is the only one responsible for serving the request.
- Decouple data and business logic, enabling scalable and reliable data replication.
The platform we’re building:
In Jira, users interact with work items (formerly called issues) either by their ID or key, or via searches using JQL. User permissions determine what they can see and do, while project and field configurations define how issues behave and appear.
To optimize Jira for scalability and performance, we must optimize each core domain. Our strategy is to extract them into dedicated, purpose-built services that deliver an order of magnitude improvement in performance, scale, and reliability:
- Issue Domain: Managed by JIS (Jira Issue Service), which handles the lifecycle, storage, and retrieval of Jira issues in the cloud.
- Issue Search: Powered by JSIS (Jira Scalable Issue Search), enabling fast, scalable search capabilities across projects and customer instances.
- Permissions: Governed by JAS (Jira Authorization Service), which applies all necessary permissions to control data access.
- Configuration: For field and project configuration, we took a different approach, which will be covered in a separate blog post.
These services constitute the core components of the Jira Platform, enabling multiple Jira products to build on them and achieve high performance and reliability at scale.

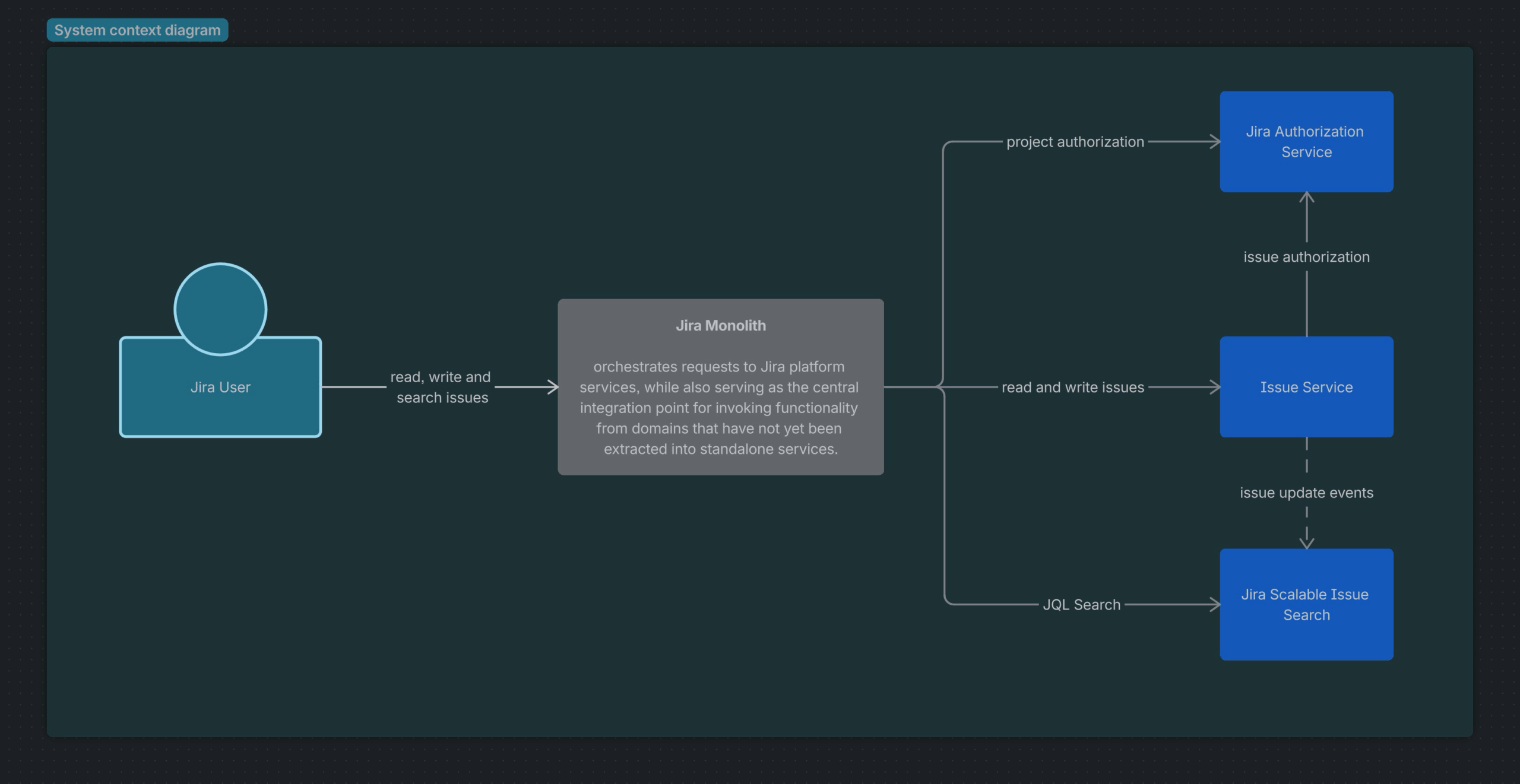
Jira Platform services adopt a consistent set of engineering practices to deliver scalable performance and high reliability at enterprise scale. For instance, we apply service sharding by dividing customers into multiple deployments. Instead of one large service handling all tenants or data, we run many copies, each responsible for a subset of customers. This design distributes the load horizontally, enabling elastic scaling by adding shards as needed, and reduces the blast radius by limiting infra-level incidents to a shard-level impact.
To minimize latency, we employ multi‑level caching, combining hot in‑memory caches with external cache layers, to achieve sub‑millisecond cache retrieval for the critical path.
Cross‑service communication is hardened with resilience patterns, including bounded retries, circuit breakers to prevent cascading failures, timeouts, and idempotent operations to safely recover from transient faults.
Together, these patterns reduce tail latency, improve success rates under load, and accelerate recovery during partial outages.
The drivers for change
Performance: Our largest customers have set a high bar for what they expect from Jira Cloud. To truly meet enterprise needs, we need order-of-magnitude improvements for Jira core experiences, ensuring that performance is consistently excellent, even at the largest scales.
Reliability: it is equally paramount. To offer ambitious, world-class experiences to our customers, we set ourselves the goal of achieving internal SLOs of at least 99.99%. This level of reliability requires every backend component to be even more robust and resilient, capable of handling surges in traffic and complex workloads without faltering.
Cost: To remain competitive, our platform must be cost-effective. Adopting a cloud-native, multi-tenant model provides the elasticity and efficiency modern enterprises need.
Developer productivity: We needed to fix internal issues with developer productivity and platform growth. Jira’s plugin-based past gave flexibility but led to inconsistent features needing custom fixes. Modernizing our architecture and practices aimed to speed up development, simplify operations, and prepare Jira for future innovation.
Architecture deep-dive:
Issue Domain:
JIS is the service responsible for storing and retrieving all Jira issue data in the cloud. The vision is for this service to act as the single source of truth for issue data, including fields like assignee, reporter, summary, description, custom fields, and comments. JIS is designed to provide fast, reliable, and scalable access to issue data for all Jira experiences.
Main responsibilities:
- Store and retrieve all issue data, meeting strict requirements for reliability, performance, scalability, and compliance.
- Issue data hydration on read. Get issue APIs require additional information, beyond issue data, to serve the request. This process is called hydration, and it resolves references to related entities (such as users or projects) using cached data or service calls.
- Provide a reliable stream of issue updates and bootstrapping capabilities for downstream services (e.g., search indexing, analytics).
JIS is architected to support massive scale (up to 1 billion issues per tenant and 100 billion–1 trillion issues across Jira Cloud), with a strong focus on performance (under 15ms SLO for read requests), reliability (offering 99.999% API uptime), and cost efficiency.
Issue Service Design:


Issue Service uses caches for issue and entity data, as well as a document store for issue data. JIS deploys two auto scaling groups (ASG), the webserver groups to handle read and write requests, and the worker groups for async tasks.
Reads:
JIS retrieves issue data through a single lookup operation in the cache or document store for cache misses. This design optimizes for read performance, compared to the previous approach of joining multiple normalised tables in the Jira monolith.
Issues have a monotonically increasing version, and the read API supports a “minVersion” parameter. When this parameter is present, JIS first checks whether the cached issue has at least the version specified in the request; if not, it queries the store. When querying the document store, it uses an eventually consistent read or a strong consistent read if a retry is required. This design enables JIS to deliver a high-performance and cost-effective solution, while also guaranteeing read-after-write consistency for clients that need to immediately see their own updates.
Hydration:
JIS hydrates issues by augmenting issue data according to the field type. For example, fields like Project store only the project ID in the issue document. However, read requests often need a hydrated version of the field with additional attributes of the Project entity. Therefore, JIS resolves the project ID to the project entity by fetching the entity’s value from the cache at read time; this is what we call hydration.
Hydration uses the Command Pattern to resolve all fields through parallel bulk requests to the cache or to dependent services in case of cache misses, calling each service once per bulk request.
This pattern replaces the legacy integration approach, where the platform used to call external services to fetch entity values. JIS now enforces an integration pattern where products need to push data to the JIS cache, and the JIS cache is invoked from the pre-defined hydration logic. Therefore, JIS has full control of the request flow.
Writes:
JIS writes uses a simple, scalable storage design. At a high level, the document is defined by:
- Data attribute: which stores all the issue data in protobuf format, which is compressed to reduce cost.
- Version attribute: to enable version control.
To mitigate limitations such as DynamoDB item size limits, JIS splits the issue document into the Issue Root Node and Sibling Nodes if the limit is exceeded.
Updates to the issue data are done by creating new Sibling Nodes if needed. These are written in batches to the document store first, and then the Issue Root Node is conditionally updated with the new data model, which includes references to the new Sibling Nodes.

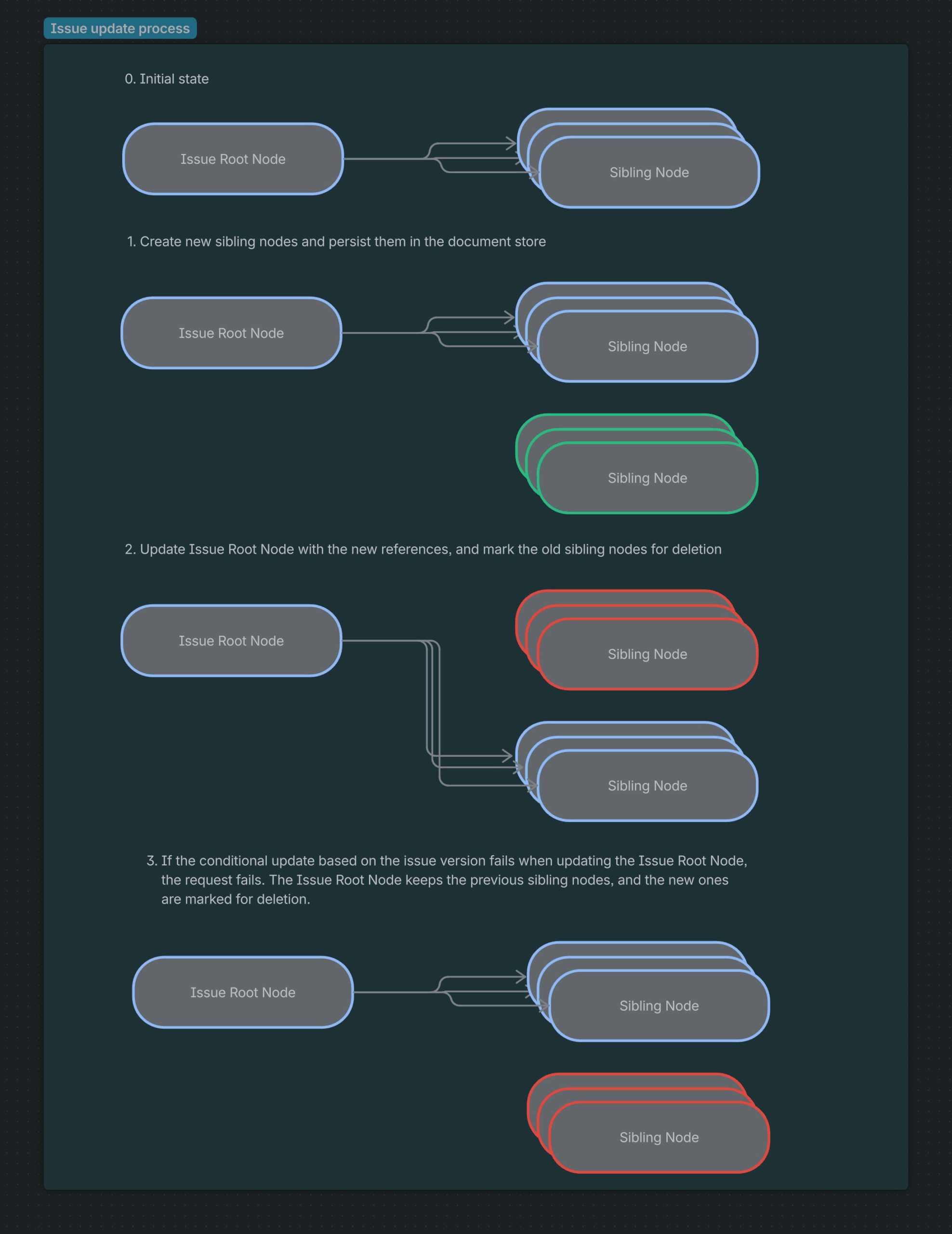
The conditional update is performed on the version field, ensuring that the version field is what was expected by the write update. If the conditional update fails, then an ERR_VERSION_TOO_NEW or ERR_VERSION_TOO_OLD is returned to the client, and the client can determine whether it should retry the update or not.
For example, upon receiving an error, the caller can reload the latest issue state and attempt to reapply the update, ensuring that no concurrent modifications are lost or overwritten. This design supports business logic around Jira features like workflows and permissions, where allowed mutations depend on the Issue’s current state. Consequently, mutation A and mutation B may both be allowed individually, but not simultaneously.
This design achieves consistency across nodes of the same issue, without implementing transactions, enabling higher throughput and write performance.
Issue Update Events & Post-processing:
After writing to the store, JIS refreshes the issue cache to maintain up-to-date information and sends an issue update event to downstream services. The cache refresh uses a version check to prevent race conditions from overwriting the cache with older data.
These two processes are first attempted in the webserver nodes as a best effort. If successful, they record the operation in a cached record.
To provide at least one delivery guarantee, JIS integrates with the storage streams, such as DynamoDB streams. JIS worker nodes process these streams by checking the cached record linked to the event to verify if the webserver node has already processed it. They refresh the cache and send the update event only on a cache miss.
This design minimizes the eventual consistency window and ensures at least one delivery.
High-throughout operations
JIS must support processing data across the entire customer data set. This capability is needed to support requirements such as data residency to be able to migrate data across regions, or to reconcile the data between JIS and other services like the Data Lake or Search index, by a downstream bootstrap.
JIS implements an index on the customer ID (internally called tenant ID), for example, using DynamoDB GSI. This index allows JIS to query the entire tenant data by dividing the index into multiple chunks and processing them in parallel.
Moreover, JIS can process thousands of these tenant-level operations concurrently thanks to its scalable design.
These operations incorporate multiple levels of concurrency and horizontal scalability, enabling it to handle the synchronization of massive datasets, including issue data from millions of tenants, when a full production bootstrap is required.
At the core of this scalability is the PTL (Per Tenant Loop) service, which orchestrates the workload by issuing one request per tenant and managing concurrency settings to ensure each tenant’s data is processed independently. This approach enables JIS to scale horizontally across multiple worker nodes, each handling requests for different tenants in parallel. Within each node, thread pool executors process each tenant’s data using numerous threads simultaneously. By combining tenant-level orchestration, elastic node scaling, and intra-node parallelism, JIS efficiently distributes the load, ensuring rapid and reliable data replication at large scale.
Issue Search Domain: JQL for scale and reliability
JQL (Jira Query Language) is a powerful and flexible query language used in Jira to search and filter on issues with fine-grained control. Its capabilities include:
- Advanced search using fields (e.g., status, assignee, project, date ranges, text search, custom fields).
- Logical operators (AND, OR, NOT) and grouping for complex queries.
- Sorting search results using the ORDER BY clause in ascending (ASC) or descending (DESC) order
- Matching, to determine if specific Jira issues match a given JQL query
- Extensible with functions and custom plugins.
JSIS (Jira Scalable Issue Search) is the new engine for JQL, optimized for scale and built on OpenSearch. It supports key search experiences, including Boards, Backlogs, Queues, Filters, Dashboards, and ecosystem apps via REST APIs and Automation.
Issue Search Design


JSIS is composed of multiple services:
- JQL Service: It is the front-facing service in the JSIS domain that orchestrates the calls to search and match issues using JQL.
- Jinx: The search index.
- JQL Resolver: This service is responsible for translating JQL into the Intermediate Language (JIL).
- JQL Matcher: This service is designed to match a set of Jira issue IDs to a JQL.
- Ingestion Service: This service is responsible for encapsulating the ingestion complexities and creating ready-to-consume events for Jinx.
Search index: Jinx
Jinx search index architecture centers on a denormalized document model, where each issue in Jira is represented as a standalone document within OpenSearch. Each issue document contains not only the core issue fields (such as summary, description, status, and custom fields) but also denormalized properties required for efficient sorting and filtering.
To support permission evaluations, each issue document references its parent project document, which encapsulates project-level metadata and permission information. This design allows the search engine to quickly evaluate both issue-specific and project-level constraints during query execution, ensuring that results are both accurate and permission-aware.
Moreover, permissions can be defined based on specific issue fields, such as reporter, assignee, or user and group custom fields. We call these Dynamic Permissions because they depend on the issue’s current state. At query time, Jinx retrieves the relevant dynamic permission grants from JAS and combines them with the querying user’s group memberships to build permission-aware search queries. This ensures users see only issues they are authorized to access, with permissions evaluated dynamically according to each issue’s current state and fields.
Additionally, the Jinx index is sharded by tenant and project to optimize scale and performance. Issues from each project are stored in the same shard, enabling efficient project-specific searches without scanning the whole index. This approach works well for large Jira instances with thousands of projects, allowing fast, high-throughput searches by spreading load across shards.
JQL Resolver:
When a JQL request is processed, the first step is translating the user’s JQL query, which is written in a human-friendly format using field and entity names, into JIL (Jira Intermediate Language). JIL is a lower-level, machine-oriented representation that uses entity IDs instead of names, making it suitable for efficient execution against the underlying OpenSearch index.
While some clauses require straightforward mapping, such as converting a project or issue type name to its corresponding ID, others demand more sophisticated resolution logic. For example, the resolver handles dynamic JQL functions like currentUser() or membersOf(), which depend on the context of the user, as well as product-specific clauses like those involving SLAs (e.g., breached(), remaining(), withinCalendarHours()).
To perform the resolution at high speed, this service is built on top of multiple highly optimized caches, which are designed to handle the diverse and complex requirements of JQL resolution. These caches store mappings and metadata, enabling the resolver to swiftly convert names to IDs without repeatedly querying backend services or databases, reducing latency and increasing throughput.
JQL Matcher:
JQL Matcher is a specialized component in JSIS designed to determine whether a specific issues match a given JQL query, which is particularly important in scenarios like automation. For example, after an issue is updated, an automation rule may need to check if the updated issue now satisfies certain JQL criteria to decide whether the rule should trigger. In these cases, it’s not about searching across all issues, but about evaluating a single, known issue against a JQL condition.
To accomplish this, the JQL Matcher component first hydrates the issue by fetching its most current data from JIS. Once the latest issue state is retrieved, the component performs the JQL evaluation directly on this data.
Ingestion Service:
OpenSearch, the backbone of JSIS’s search capabilities, excels at scaling query operations and delivering fast, flexible search experiences. However, it is less suited to handling extremely high volumes of write operations, especially in a system like Jira that is fundamentally read-heavy but must still process large numbers of updates efficiently.
To address these challenges and improve system reliability, JSIS has implemented a sophisticated ingestion pipeline component that sits directly in front of Jinx. This component acts as a gatekeeper, filtering out updates that are not relevant to the index by keeping a slim version of entities called diet_entities, thereby reducing unnecessary write load. It also intelligently buffers and collapses multiple updates into single operations when possible, further minimizing the number of write requests sent to the index. For entity updates where the event payload does not include a diff, the pipeline tracks recent changes and computes the difference itself, ensuring that only actual changes are propagated to the index.
Drop-in Replacement:
Moving from a monolith architecture to a distributed system introduces eventual consistency, a fundamental trade-off explained by the CAP theorem. While we cannot eliminate this, our goal is to minimise its impact. In distributed systems like JSIS, there is an inherent lag between when issues are updated and when they become fully searchable in OpenSearch. This delay stems from the asynchronous nature of the ingestion pipeline and OpenSearch’s refresh cycles, which are optimised for throughput rather than immediate consistency.
To bridge this gap, we implemented DIR (Drop-in Replacement). This component maintains a cache of recently updated issues and, when a search request arrives, the same query is applied simultaneously to the main index and the DIR cache. The index provides the bulk of matching results from fully indexed data, while the DIR applies JQL Matching to the recently created and updated issues, which might not yet be indexed. By merging these result sets, JSIS delivers a more consistent and up-to-date search experience, improving specific user experiences that are more sensitive to the impact of eventual consistency.
Authorization domain:
The Jira permission domain is the comprehensive framework responsible for access control and user actions within Jira. It governs who can view, create, edit, transition, or delete issues and projects, ensuring that only authorized users can perform specific operations. This domain encompasses authorization validations, organizational policies, and product-specific access controls.
JAS centralises and encapsulates all the required permission and authorisation checks behind a single API.
Key components
- Permission Configuration:
Permissions are configured by site or project administrators to define how entities, such as projects and issues, can be accessed or modified. These configurations reference groups, project roles, or individual users, allowing administrators to tailor access according to organisational requirements. - User Collections:
Jira enables administrators to organize users into collections that can be easily referenced in permission settings. These collections include groups, project roles, and Jira Service Management (JSM) customer organizations, providing scalable and maintainable ways to manage access for teams of any size. - Object Attributes:
Permissions can also be determined by attributes associated with specific objects. Examples include issue-level security schemes, field values such as assignee or reporter, user/group custom fields, and role or group-based security for comments and worklogs. These attributes enable fine-grained control, ensuring that access can be precisely tailored to meet diverse business needs and scenarios.
Service design

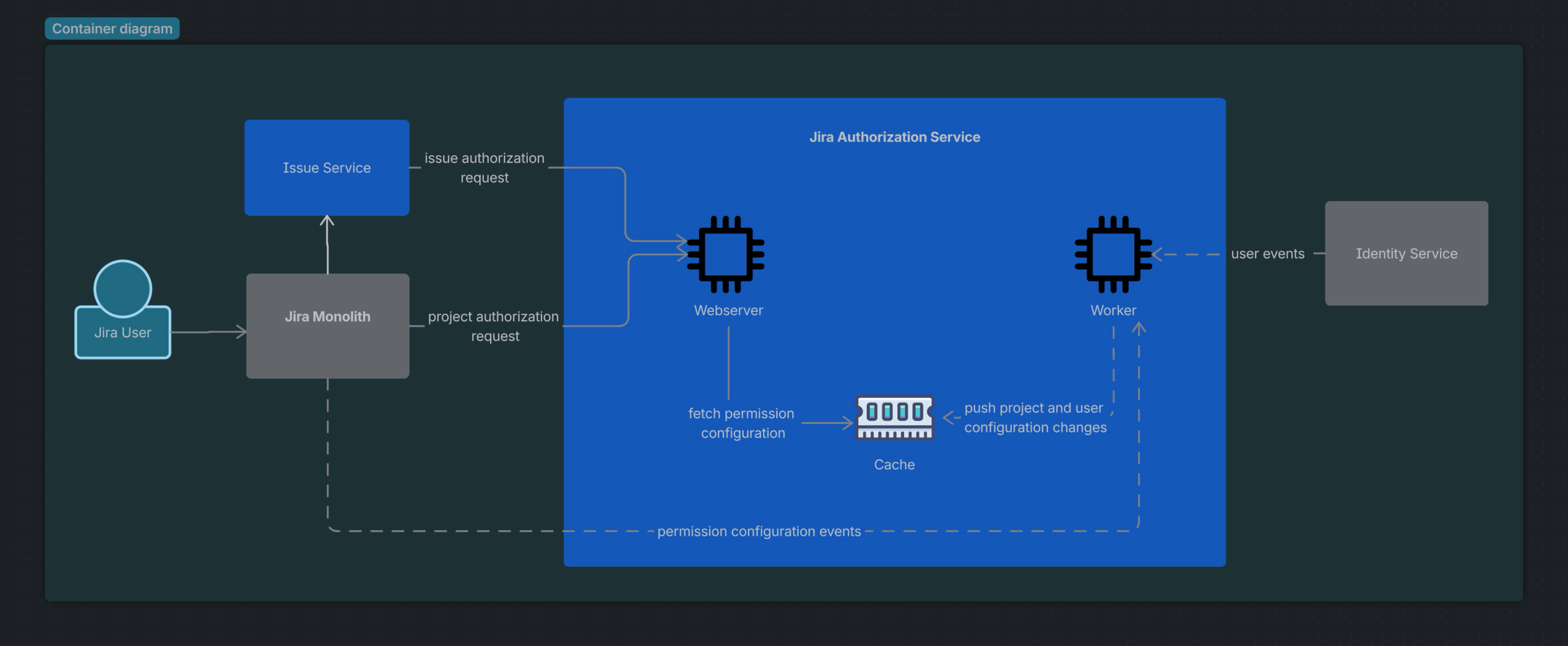
Reads:
JAS is engineered for exceptional speed, targeting permission evaluations within 10 milliseconds. To achieve these ambitious service-level objectives, it employs advanced multi-level caching strategies and is optimized for extremely high cache hit rates.
When a read request is received, the service first performs a rapid pass to determine all the data required for the permission check. It then executes bulk data fetching in parallel, minimizing the number of calls to the cache or any external services. This approach ensures that permission checks are not only fast but also scalable, even under heavy load.
A key aspect of Jira’s permission model is that certain permissions depend on specific issue fields. For example, permissions like “the user can edit the issue if they are the assignee” require access to the issue’s assignee field to make an accurate decision. This creates a dependency between the JIS and the JAS during permission evaluation. To avoid unnecessary round-trip calls, when JIS invokes JAS for a permission check, it proactively includes all relevant issue fields needed for the evaluation. This design ensures that permission checks are both efficient and contextually accurate, supporting complex access control scenarios without sacrificing performance.
Consistency guarantees:
Within the consistency model expected for permissions in Jira, we typically think of two primary use-cases:
- The configuration of permissions (i.e., modification Permission schemes) or associating users with Groups or Project Roles.
- The modification of issue data such that it affects Issue-level permissions
In case (1), we can tolerate a small eventual consistency window. When a user is added to a group, permission changes may take a few seconds to propagate. We minimise this consistency window by invalidating caches based on the event stream and refreshing them in the background according to activity.
In the case of (2), we expect that there exists a total ordering of operations, such that permissions are immediately applied to an Issue, and subsequent modifications to that Issue can never be seen by users who should not see them.
To achieve a stronger consistency model with total ordering for Issue data modification, we use the issue data provided by JIS. JIS acts as the Policy Enforcement Point (PEP) and supplies relevant Issue data to the Jira Authorization Service (the Policy Decision Point, PDP) during the API request. This approach ensures permission evaluation applies to the exact issue data served in the request, preventing race conditions or out-of-order events that could expose unauthorized data.
Cache refreshes:
When updating values in the cache, JAS carefully handles race conditions to prevent outdated data from being written back into the cache, especially as integrations with event streams introduce the risk of processing out-of-order events. JAS leverages the updated_time field provided by the data source, in the case of the permission scheme, to determine the correct ordering of events.
When a cache update is needed, JAS leverages Memcached’s Compare-And-Swap (CAS) capabilities: before writing a new value, it checks the updated_time of the incoming data against what’s already cached. Only if the new data is more recent will the cache be updated, effectively guarding against stale writes even in the presence of concurrent updates or delayed event processing.
To maintain high-performing APIs, JAS extensively leverages JVM-level caching, providing extremely fast lookups. An LRU (Least Recently Used) strategy is employed, where a time-based linked list tracks cache hits and evicts the least recently accessed items when the cache reaches its maximum capacity. This approach ensures that frequently accessed data remains in cache, supporting the typical Jira usage pattern of high activity over the same projects during business hours. Additionally, a TTL is applied to remove cache entries after periods of inactivity, which, combined with the LRU policy, helps manage JVM memory efficiently. This allows the system to accommodate future tenants with larger memory requirements while keeping overall resource utilization optimized.
Data model:
JAS cache model is organised on a per-project basis, enabling Jira to scale permissions and access control efficiently at the project level. This design allows each project to be managed and scaled independently, supporting the needs of large enterprise customers with complex organizational structures.
At the core of the JAS data model, permissions configuration is cached implicitly, name-spaced to the tenant via activationId and to the cache via a unique cache name.
This configuration includes key associations such as the mapping between Project IDs and their corresponding Permission Scheme IDs, as well as the association between Project IDs and Issue Security Scheme IDs where applicable.
Additionally, permission schemes and issue security schemes themselves reference other entities, such as project roles and user groups, which are managed and stored separately. This modular approach ensures that permissions can be evaluated quickly and accurately, while also supporting per-project scalability and flexibility across diverse Jira environments.
Wrapping up
If you have read this far, you may wonder about the impact of this work. This effort significantly improved performance, reliability, and cost.
Key highlights
- Substantial speedups: API responses improved significantly, especially for complex search paths and at high percentiles where customers feel the pain. For example, Issue Navigator initial load p99 dropped from ~4s to ~300ms (10x improvement), and some large customers saw endpoint p99 decrease from ~14.4s to ~486ms (up to 30x improvement).
- Significantly more reliable: Changing the access patterns helped us reduce the number of dependencies, enabling us to consolidate reliability efforts into a few services that maintain extremely high reliability targets between 99.99 and 99.999% SLO targets.
- Millions in savings: Shifting traffic to a more efficient architecture and reducing the monolith’s load allowed us to serve more customers on the same infrastructure, saving millions in operational costs.
- Better throughput: The new services scale horizontally to handle billions of daily requests, supporting platform growth while maintaining high SLO standards.