
Discover how Atlassian transforms unstructured text into actionable enterprise knowledge through advanced entity linking.
Transforming unstructured text into structured knowledge is the backbone of effective enterprise AI. By accurately associating textual mentions with specific records in our Knowledge Graph, we can significantly enhance the relevance of tools like Rovo Chat and Search.
This capability relies on Entity Linking—an NLP task that identifies mentions in text and connects them to their corresponding unique entries. At Atlassian, our Entity Linking service provides verified annotations that serve three critical functions:
- RAG & Chat: Resolving entities in chat utterances (e.g., “Summarize the Alpha project”) to improve LLM prompting and context retrieval.
- Search Relevance: Detecting entities in queries to trigger effective query rewriting and precise filter selection.
- Knowledge Indexing: Pre-processing documents offline to link mentions, enriching the index for future retrieval.
However, not all entities are created equal. Different entity types present unique linguistic and data challenges. In this post, we explain how we tackle this problem at Atlassian, using Team Names as a case study.
Problem Formulation
The primary objective of the Entity Linking system is to solve the mention-disambiguation problem. Its goal is to translate raw, ambiguous input strings into precise, unique entity IDs (canonical identifiers) for domain-specific objects such as People, Teams, and Projects.

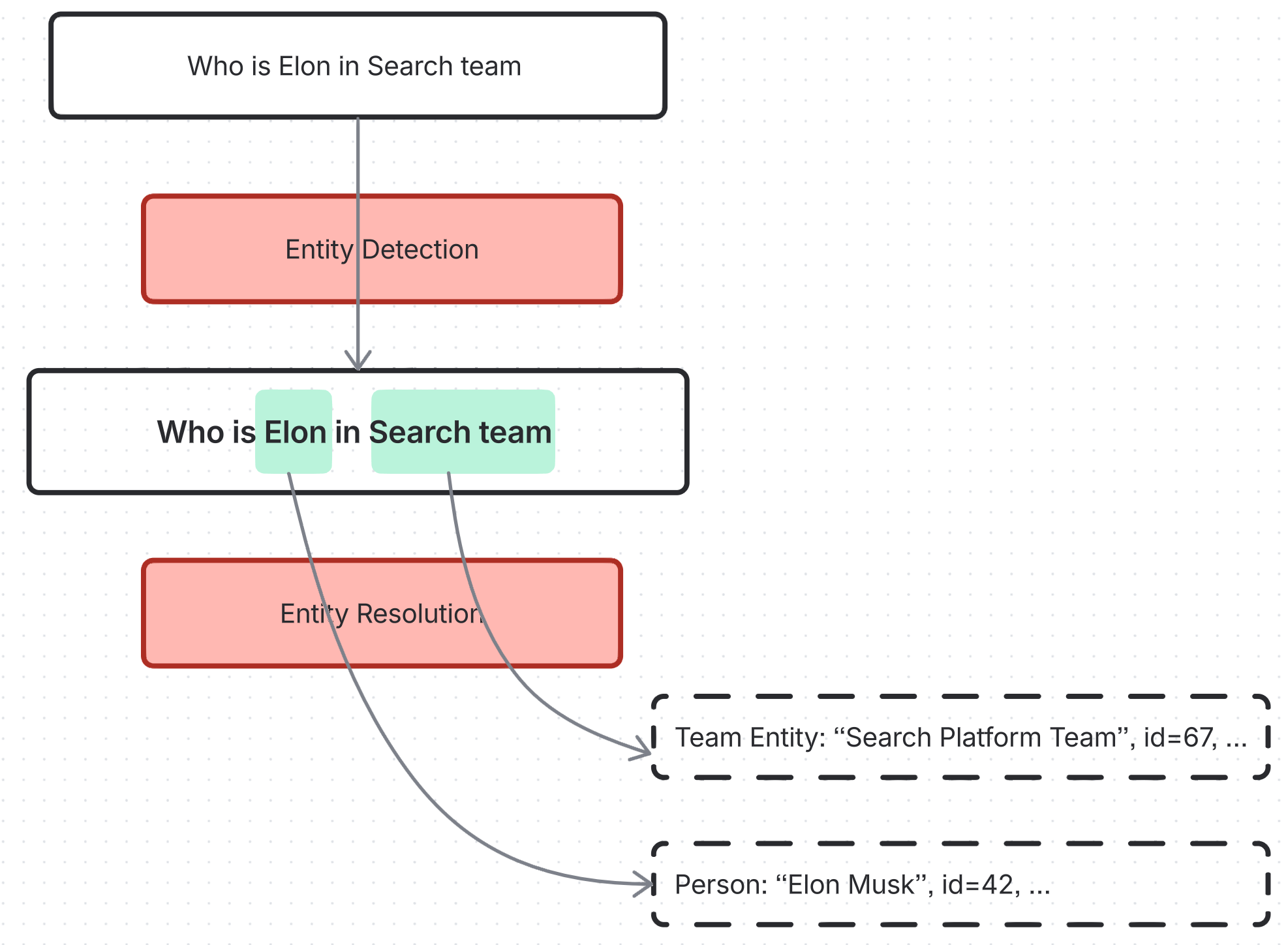
While linking a “Person” (e.g., “John Smith”) is a well-documented challenge in the industry, linking “Team Names”presents a distinct set of hurdles involving high operational noise, inconsistent naming conventions, and privacy constraints.
Throughout this post, we will focus on the Team Name entity to illustrate these technical challenges and the architecture we built to solve them.
Technical Challenges
Extracting and linking team names presents a unique set of difficulties compared to detecting personal names which often follow predictable patterns. Below are the details on the challenges we faced:
1. High variance and low distinctiveness
Team names lack a standard format, unlike personal names. It could be a long technical name, with details, like “Confluence Cloud Migration – Quality“, or an acronym such as “CCM Quality“.
- Informal usage: Users rarely query full canonical team names, preferring partial matches, acronyms, or colloquialisms.
- Non-standard characters: Team names often include emojis, punctuation (brackets, hyphens), or stylized text that standard tokenizers struggle to process.
- Common word ambiguity: Teams named “Knowledge” or “Platform” are indistinguishable from common nouns without context. Generic words in short queries challenge NER models to classify with high confidence.
2. Noise and Volatility
In an enterprise environment, the dataset of “Teams” is often polluted with test artifacts.
- Test Data & Bot Activity: A significant portion of teams are created by automated bots or by users testing features. These entries are noise—they are not actual operational teams and are irrelevant to search or chat users.
- High Churn Rate: Unlike established departments, project teams are ephemeral. They are created, renamed, and deleted daily. This volatility requires the model to handle near real-time updates to remain relevant.
3. Contextual Dependence & Sparse Metadata
Team names often lack inherent semantic meaning, requiring the model to look elsewhere for signals.
- Reliance on External Context: Disambiguation often relies entirely on the surrounding query. For example, distinguishing between “John in Sales” and “John in Engineering” requires the model to understand that “Sales” functions as a team entity in this specific context.
- Implicit Information: Teams often lack explicit descriptions. To understand what a team does, the model must infer meaning from the artifacts the team interacts with, such as Jira tickets, documentation pages, or repository names.
4. Diverse Naming Conventions
Because our solution serves all tenants across Atlassian products, we must account for vastly different corporate cultures. There is no single “standard” for how teams are named.
- Thematic Naming: Some companies adopt strict naming conventions. For instance, Netflix is known for using movie references for internal tools.
- Implication: We need to either train the model for each individual team, or make sure our model is cross-domain ready.
5. Privacy and Compliance
Team names are content provided by users in our products and may be confidential. To respect customer privacy, our solution is designed to maintain tenant isolation while delivering accurate results.
These challenges are not unique to Team names; they also apply to other dynamic entities such as Project Names, Ticket Tags, and Topics. In the following section, we detail the architecture we built to address these constraints.
Atlassian’s Solution
The goal of entity linking system in Atlassian, is to achieve both high-precision and low latency for enterprise data.
Ambiguity is the primary adversary of accurate entity linking. To cut through the noise and drive high precision, we focus on two critical pillars:
- Rich Context in the Query A query rarely exists in a vacuum. We built our pipelines to harvest the “implicit intent” hidden in the context. By analyzing the accompanying text—whether it’s the body of a ticket, a slack thread, or code comments—we provide the model with enough distinct features to disambiguate terms that look identical on the surface but are semantically distant.
- Personalization as a disambiguator One size rarely fits all in search. We found the strongest disambiguation signal comes from who is asking. We integrated signals that weigh results by their relation to the user, including interactions between users within our products. This transforms a generic search engine into a tailored assistant; it recognizes that a query from a Data Scientist requires different entities than the same query from a Product Manager, pruning irrelevant results before they reach the ranking layer.
To balance latency with precision, we implemented a cascade architecture that decouples retrieval from reasoning. As shown in Fig 1, The system architecture is consisted of three main stages:

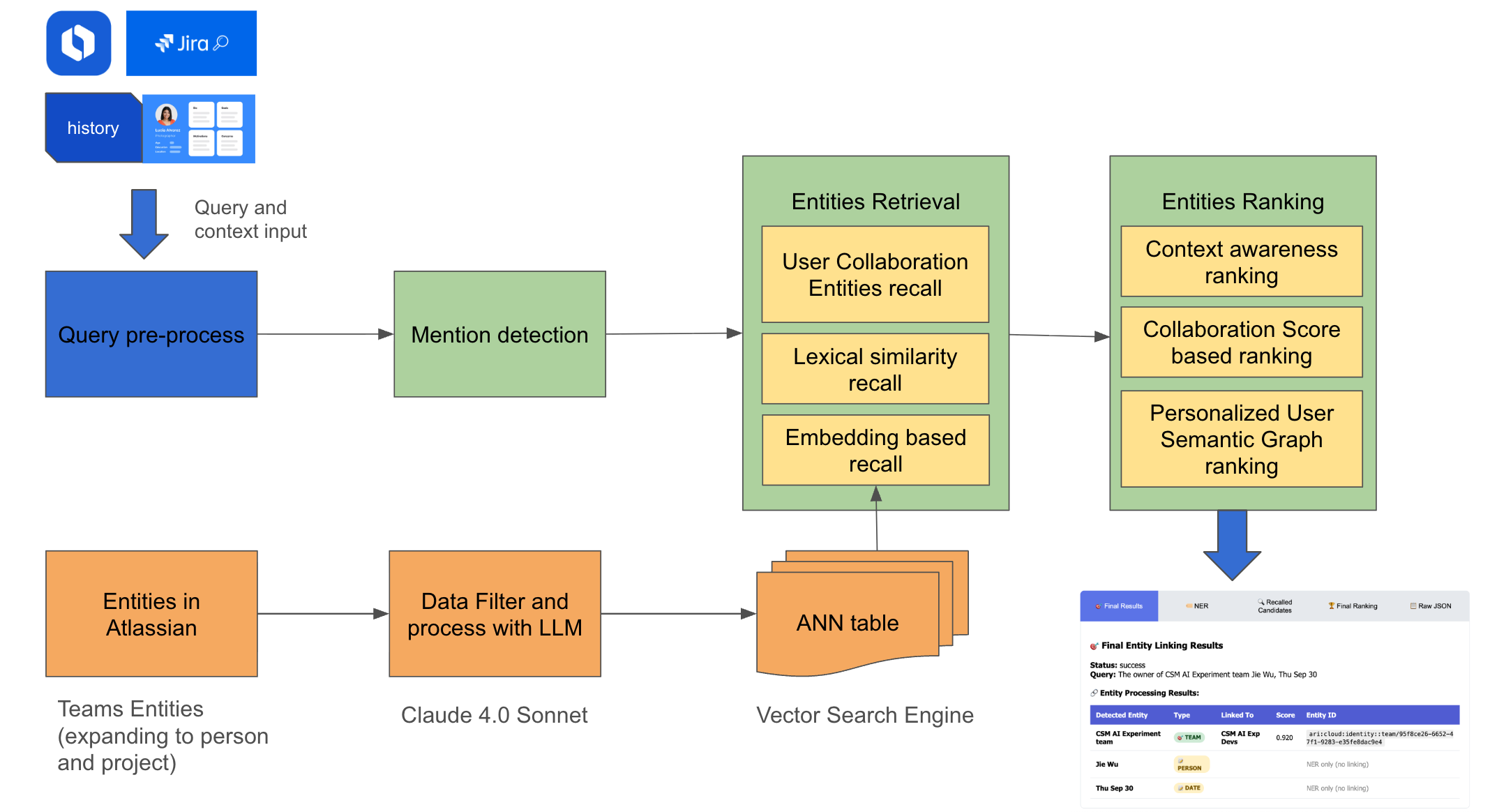
- Detection Stage (Mention detection): We utilize a fine-tuned transformer-based sequence tagging model to detect entity spans. Unlike traditional string matching, this model uses the surrounding context to resolve immediate polysemy (e.g., distinguishing “Python” the language from “Python” the internal script) before the linking process even begins.
- Recall Stage (Candidate Generation): Once a mention is isolated, the goal shifts to coverage. We query our underlying data repository to retrieve a broad set of plausible candidates. This stage maps the surface form (the raw text) to potential canonical entries—linking the noisy input “Apollo” to the unique identifiers of every project, team, or document containing that name. Due to high noise data in team name or project name, we are expanding to a 3-different recall path to maximize the coverage.
- User relation and collaboration–based recall path – We use a user’s collaboration and organizational relationships to recall entities that they frequently interact with. This includes teams they belong to or own, projects their close collaborators work on, and entities connected through shared issues, pages, or repositories. This addresses the challenge of noisy or ambiguous names, where interactions between entities and users provide stronger signals than semantic meanings from names.
- Lexical and keyword–based recall path – We use traditional information‑retrieval techniques (Jaccard and fuzzy matching) over team and project names, aliases, and short descriptions. This path surfaces candidates that share tokens with the mention, including partial matches, common abbreviations, and minor typos (e.g.,
"Apollo"↔"Apollo Platform"or"Apolo"). - Embedding‑based semantic recall path – While building the index, we use a transformer model to encode all entities using their names and descriptions, into embeddings. During inference, we do that same to the mention string, together with its local context into a dense embedding. An approximate nearest‑neighbor search is used to retrieve candidates that are semantically similar even when there is little or no lexical overlap (e.g.,
"Mobile Knowledge Hub"↔"Knowledge Platform – Mobile").
- Ranking Stage (Coarse and Fine-Grained Disambiguation)To balance latency with precision, we further decompose the ranking layer into two stages:
- Coarse Ranking (Cross-Encoder with XLM-RoBERTa).
Given the broad candidate set from recall, we first apply a lightweight cross-encoder based on XLM-RoBERTa. This model performs cross-attention between the mention (plus surrounding query context) and a condensed view of each candidate (name and short description) to quickly estimate semantic compatibility. The goal of this stage is a first-pass quick pruning: we down-select to a smaller pool of high-potential candidates (typically k < 50) while keeping latency low. - Fine Ranking (LLM-powered Relevance Scoring).
On this narrowed candidate set, we employ a more expressive LLM-based ranker that ingests the full query context (e.g., ticket body, Slack thread) together with richer candidate metadata. In this stage, the model reasons over three categories of features:- context-aware rankings – measures how well each candidate fits the full query context and surrounding content.
- collaboration‑score–based ranking – prioritizes entities that the user and their close collaborators actively work with.
- Coarse Ranking (Cross-Encoder with XLM-RoBERTa).
This architecture effectively solves entity linking problem, providing one solid piece of building block for Atlassian’s AI products. Our next step roadmap focuses on moving beyond static identifiers by implementing one-hop relation resolution to translate context-dependent queries like “my team”. Furthermore, we are expanding our index to include implicit and virtual teams by mining collaboration signals from shared communication traces on Atlassian products.