Artykuły
Samouczki
Interaktywne przewodniki
Naucz się ciągłego dostarczania z Bitbucket Pipelines

Sten Pittet
Autor współpracujący
W tym przewodniku zobaczymy, jak można wykorzystać Bitbucket Pipelines do wdrożenia przepływu pracy opartego na ciągłym dostarczaniu. Czytaj dalej!
Godzina
30 minut
Publiczność
Osoby, które dopiero zaczynają stosować ciągłe wdrażanie, i/lub początkujący użytkownicy Bitbucket Pipelines
Wydanie nowej funkcji to zawsze ekscytujący moment, ponieważ dajesz swoim klientom nowe możliwości. Jednak bywa ono również ryzykownym przedsięwzięciem wymagającym mnóstwa przygotowań, przez co zespół nie chce robić tego zbyt często. A im dłużej czekasz, tym trudniejsze staje się wdrożenie w środowisku produkcyjnym. Zmiany zaczynają się piętrzyć, trudno ustalić ich zakres, a w razie wystąpienia problemów w środowisku produkcyjnym wskazanie ich głównej przyczyny nie jest łatwe.
Prostym sposobem na wyeliminowanie tych obaw i obniżenie kosztu wdrażania oprogramowania jest zautomatyzowanie tego procesu oraz częstsze wydawanie mniejszych zmian. Przede wszystkim zaoszczędzisz w ten sposób wiele godzin, które normalnie poświęcasz na przygotowanie wydania. Jednocześnie zmniejszysz ryzyko związane z wdrożeniem oprogramowania dzięki znacznemu ograniczeniu zakresu poszczególnych wydań, co ułatwi monitorowanie środowisk i rozwiązywanie problemów.
Taka automatyzacja wdrażania jest z łatwością dostępna w Bitbucket Cloud już dziś. Dla każdego repozytorium można skonfigurować pipeline, który pozwoli automatycznie kompilować, testować i wdrażać kod w Twoich środowiskach przy każdym wypchnięciu. W tym przewodniku pokażemy, jak możesz wykorzystać Bitbucket Pipelines do wdrożenia przepływu pracy opartego na ciągłym dostarczaniu.
Ciągłe dostarczanie a ciągłe wdrażanie
Praktyka ciągłego dostarczania polega na zapewnianiu ciągłej gotowości kodu do wydania, nawet jeśli nie każda zmiana jest wdrażana w środowisku produkcyjnym. Zaleca się możliwie jak najczęstsze aktualizowanie środowiska produkcyjnego, aby zakres zmian był niewielki, jednak ostatecznie to Ty kontrolujesz rytm swoich wydań.
W przypadku ciągłego wdrażania nowe zmiany wypychane do repozytorium są automatycznie wdrażane w środowisku produkcyjnym, jeśli pomyślnie przejdą testy. Większy nacisk (a więc i większą presję) kładzie się wówczas na kulturę testowania. Jest to jednak doskonały sposób na przyspieszenie wymiany informacji zwrotnych z klientami.
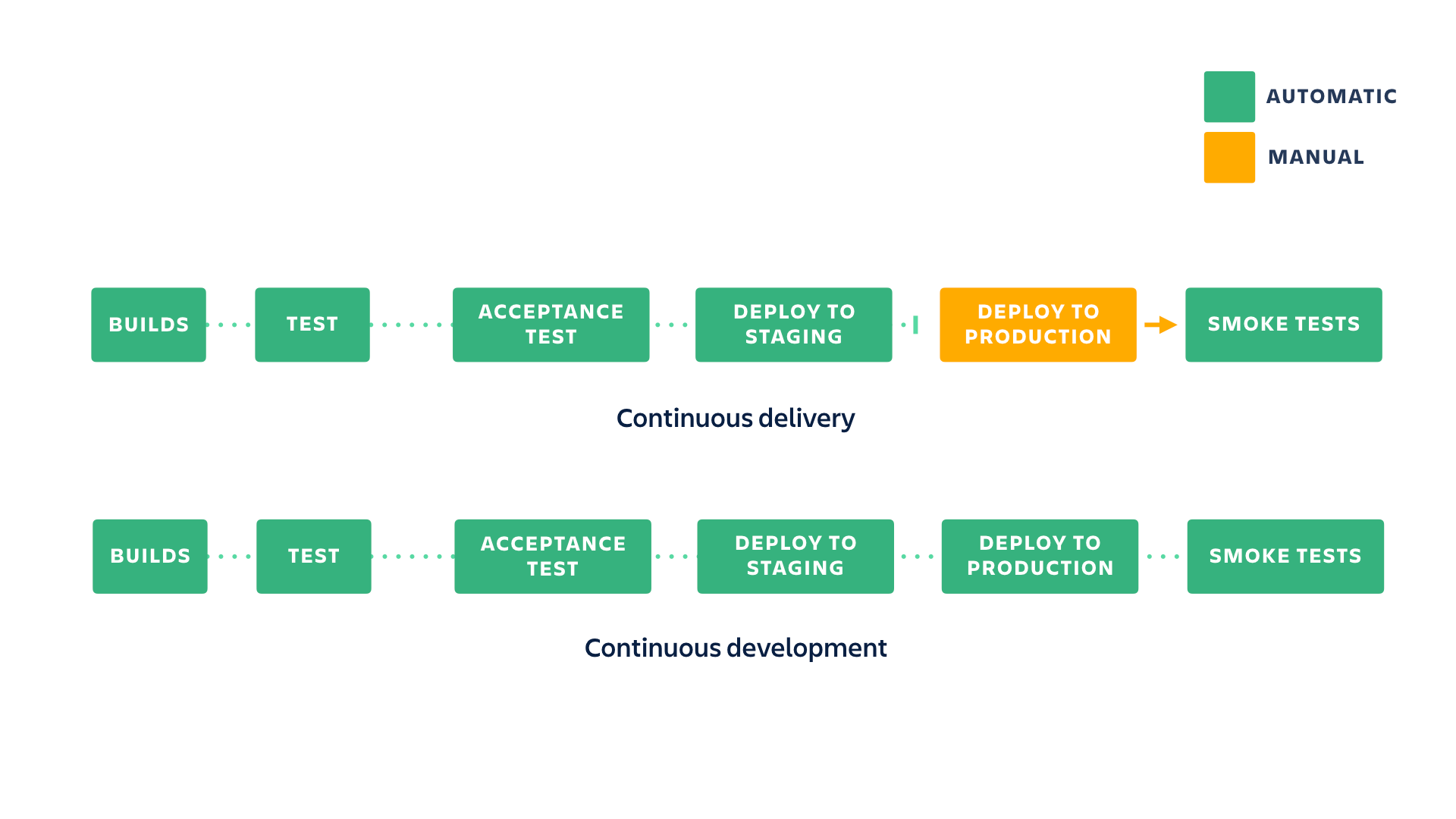
Wdrożenie pipeline'u ciągłego dostarczania
W tym przykładzie rozbudujemy prostą aplikację w środowisku Node.js, którą skompilowaliśmy w samouczku dotyczącym ciągłej integracji, dodając pipeline ciągłego dostarczania, który będzie automatycznie wdrażał aplikację w środowisku przejściowym po pomyślnym zaliczeniu testu kompilacji. Zapoznamy się z dwiema różnymi strategiami wdrażania w środowisku produkcyjnym: jedną z wykorzystaniem gałęzi i pull requestów, a drugą z wykorzystaniem niestandardowych pipeline'ów i ręcznych wyzwalaczy.
W obu przypadkach wykorzystamy prostą aplikację w środowisku Node.js, która wyświetla komunikat „Hello World” w Twojej przeglądarce. Wdrożymy tę aplikację w środowiskach przejściowym i produkcyjnym hostowanych na Heroku przy użyciu obu metod.
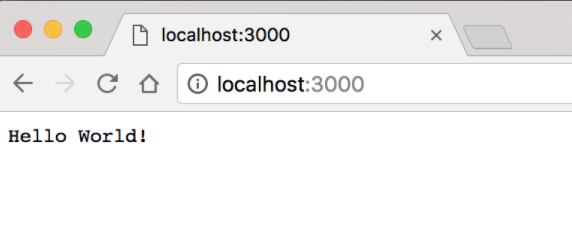
Nasza bardzo prosta aplikacja Hello World
Przygotowanie wdrożenia do Heroku
Najpierw zarejestruj się w Heroku.
Następnie zainstaluj interfejs CLI Heroku.
Zaktualizuj plik package.json, aby wyglądał mniej więcej tak:
{
"name": "cdtutorial",
"version": "1.0.0",
"description": "",
"main": "server.js",
"scripts": {
"start": "node server.js",
"test": "mocha --exit"
},
"repository": {
"type": "git",
"url": "git+ssh://git@bitbucket.org/pmmquickstartguides01/cdtutorial.git"
},
"author": "",
"license": "ISC",
"bugs": {
"url": "https://bitbucket.org/pmmquickstartguides01/cdtutorial/issues"
},
"homepage": "https://bitbucket.org/pmmquickstartguides01/cdtutorial#readme",
"dependencies": {
"express": "^4.17.3"
},
"devDependencies": {
"mocha": "^9.2.2",
"supertest": "^6.2.2"
}
}Zaktualizuj plik server.js, aby wyglądał mniej więcej tak:
var express = require("express");
var app = express();
app.get("/", function (req, res) {
res.send("Hello World!");
});
app.listen(process.env.PORT || 3000, function () {
console.log("Example app listening on port 3000!");
});
module.exports = app;Zwróć uwagę na zmianę w wierszu app.listen(). Teraz zawiera on zapis process.env.PORT ustawiony przez Heroku.
Dodaj plik Procfile do katalogu głównego przykładowego repozytorium, wykonując następujące polecenie:
touch ProcfileNastępnie dodaj następujący tekst do pliku Procfile:
web: npm startZaloguj się do Heroku, kliknij ikonę użytkownika w prawym górnym rogu, kliknij opcję Konfiguracja konta i przewiń w dół, aby odszukać pozycję Klucz API.
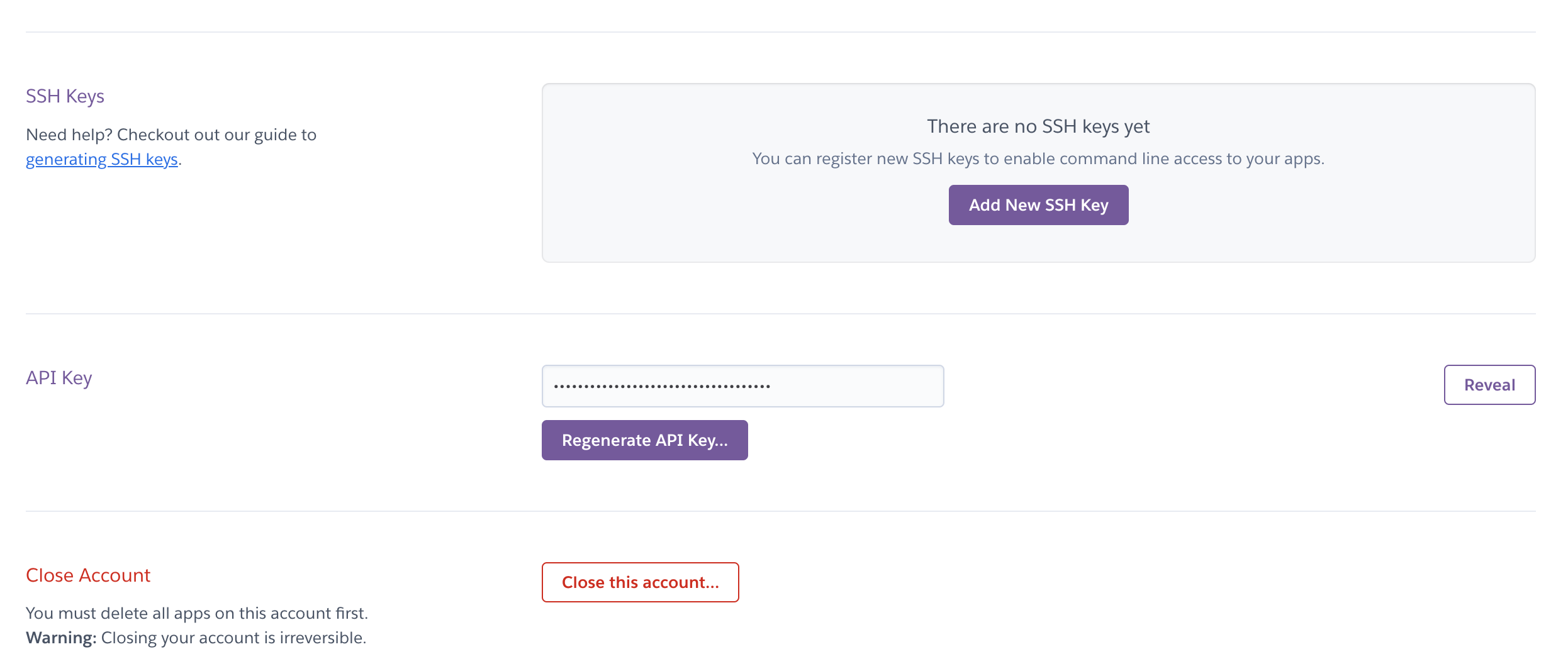
Następnie dodaj zmienną środowiskową do Bitbucket Pipelines, abyśmy mogli dokonać wdrożenia w Heroku:
- HEROKU_API_KEY: klucz API znajdziesz na swoim koncie Heroku
Wybierz kolejno pozycje Pipeline'y > Zmienne środowiskowe w ustawieniach repozytorium, aby dodać tę zmienną.
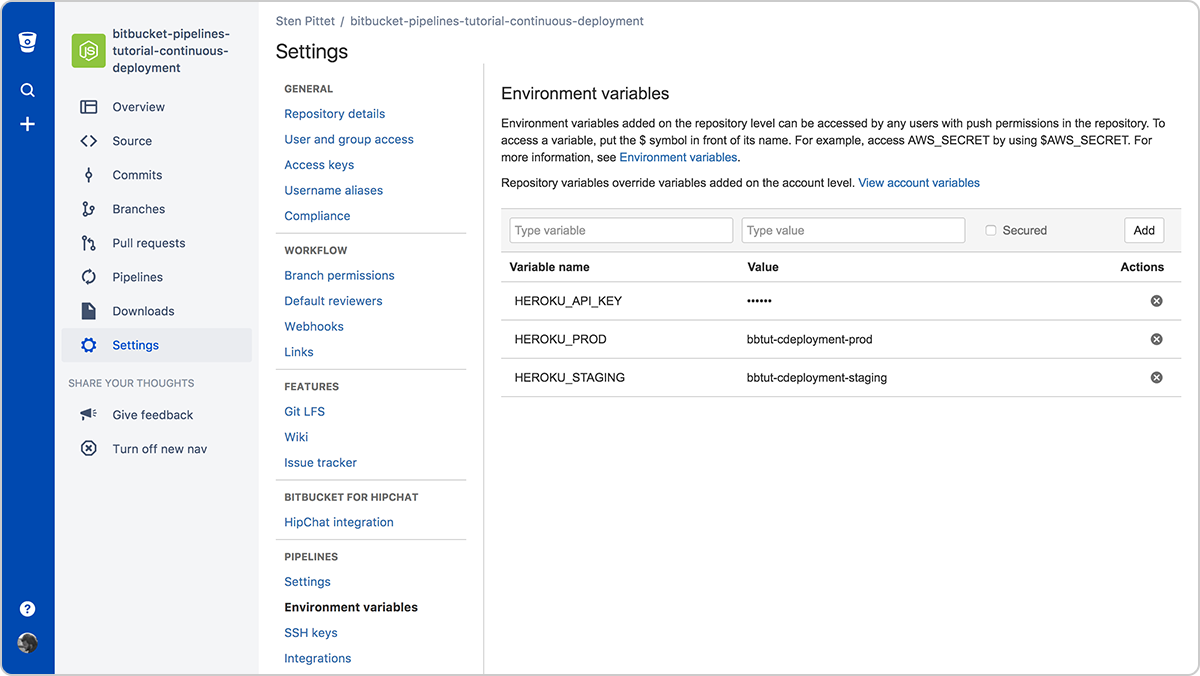
Konfigurowanie zmiennych środowiskowych w celu wdrożenia w Heroku
Choć w tym przewodniku korzystamy z Heroku, z pewnością przykład ten można dostosować także do innych usług hostingowych. Skorzystaj z tego przewodnika, jeśli używasz Heroku.
Ciągłe dostarczanie z gałęziami pełniącymi funkcję bramy do środowiska produkcyjnego
Ta konfiguracja jest przeznaczona dla zespołów posiadających specjalne gałęzie wydań, które można zmapować do wdrożenia. Umożliwia również przeglądanie zmian w pull requeście przed wdrożeniem ich do środowiska produkcyjnego.
W tej konfiguracji użyjemy 2 różnych gałęzi do wyzwalania wdrożeń:
- main: każde wypchnięcie do gałęzi main spowoduje wdrożenie kodu w środowisku przejściowym po uprzednim przeprowadzeniu testów.
- production: kod scalony z gałęzią production będzie automatycznie wydawany do środowiska produkcyjnego.
Utwórz gałąź production w usłudze Bitbucket Cloud, klikając przycisk Gałęzie.

Następnie kliknij przycisk Utwórz gałąź.
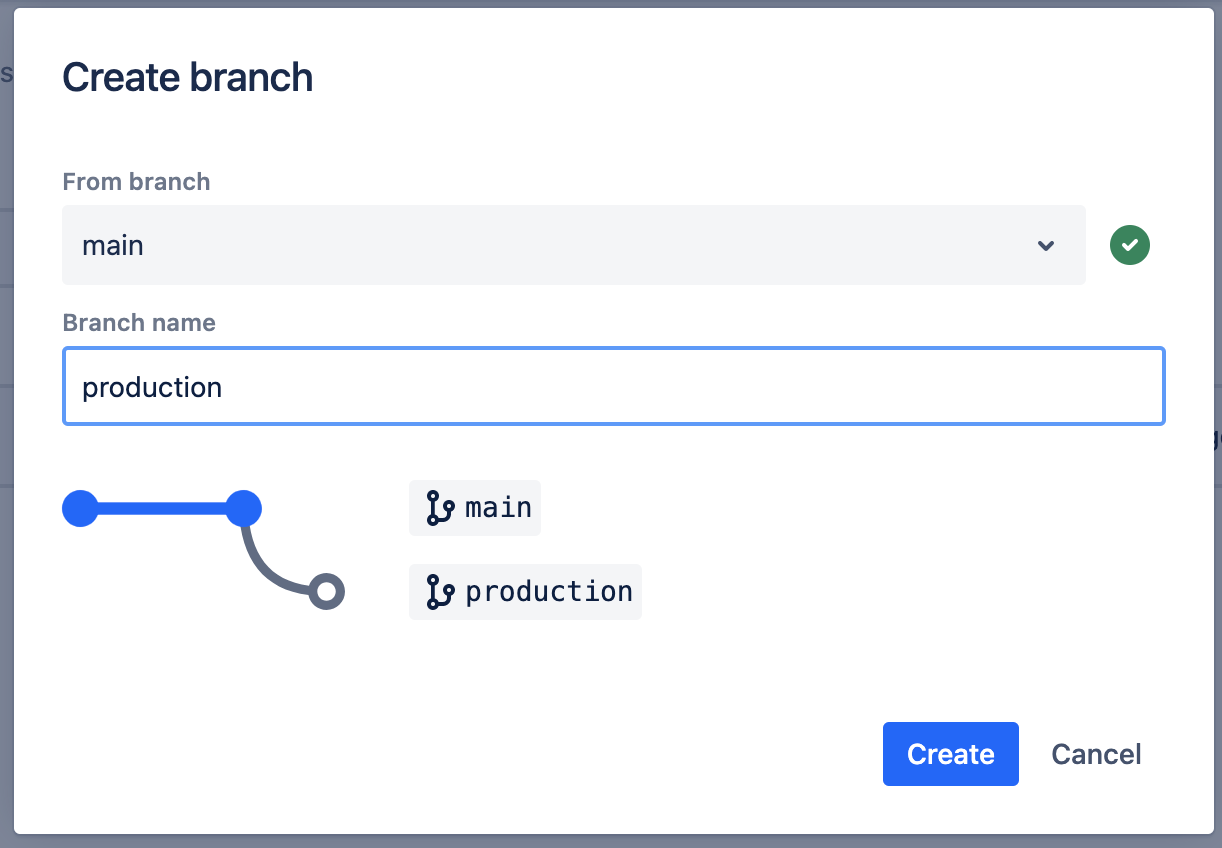
Wpisz production i kliknij przycisk Utwórz.
Z katalogu głównego przykładowego repozytorium wykonaj następujące polecenie:
heroku create --remote staging
git push staging main
heroku create --remote production
git push production mainAby sprawdzić, czy polecenie zadziałało poprawnie, przejdź do Heroku w przeglądarce i sprawdź, czy na liście znajdują się dwie aplikacje.
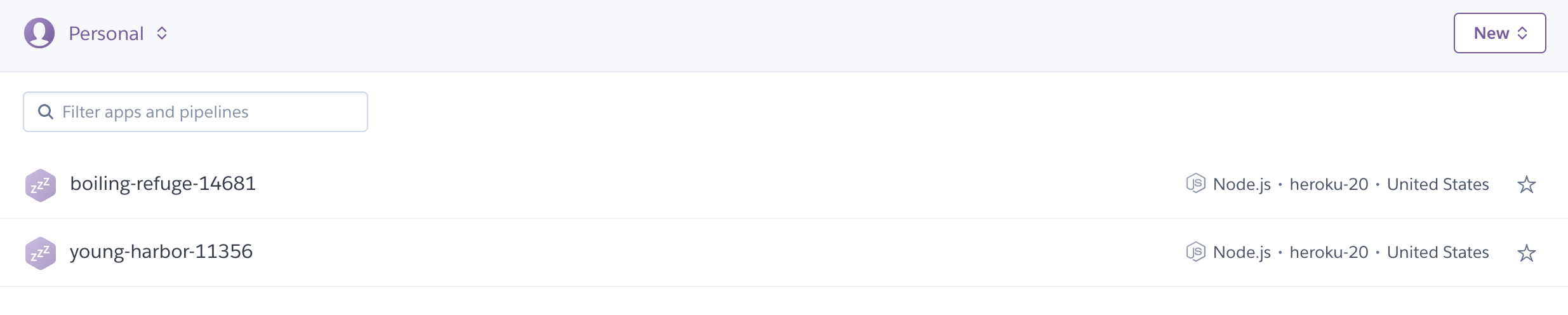
Wykonaj również następujące polecenie:
git remote -vvW wynikach powinny się znajdować trzy repozytoria zdalne. Jedno dla Bitbucket i dwa dla Heroku. Jedno z nich będzie repozytorium zdalnym środowiska przejściowego, a drugie — środowiska produkcyjnego.
wmarusiak@C02F207NML7L cdTutorial % git remote -vv
origin git@bitbucket.org:pmmquickstartguides01/cdtutorial.git (fetch)
origin git@bitbucket.org:pmmquickstartguides01/cdtutorial.git (push)
production https://git.heroku.com/young-harbor-11356.git (fetch)
production https://git.heroku.com/young-harbor-11356.git (push)
staging https://git.heroku.com/boiling-refuge-14681.git (fetch)
staging https://git.heroku.com/boiling-refuge-14681.git (push)Następnie skonfiguruj wdrożenie do środowiska przejściowego. Wykorzystamy w tym celu pipeline'y właściwe dla gałęzi, tworząc pipeline wykonywany przy każdym wypchnięciu kodu do gałęzi main. Wprowadź tę zmianę w swoim terminalu i wypchnij ją do początkowej gałęzi main.
bitbucket-pipelines.yml
image: node:16
clone:
depth: full
pipelines:
branches:
main:
- step:
name: deploy_to_staging
script:
- npm install
- npm test
- git push https://heroku:$HEROKU_API_KEY@git.heroku.com/boiling-refuge-1468.git mainPamiętaj o zastąpieniu adresu URL wypchnięć w systemie Git dla gałęzi main adresem URL środowiska przejściowego z polecenia git remote -vv powyżej.
W ten sposób utworzyliśmy pipeline, który będzie wdrażał każde wypchnięcie kodu z gałęzi main do Heroku po uprzednim skompilowaniu i przetestowaniu naszej aplikacji. Sekcja klonowania na początku konfiguracji zapewnia, że wykonujemy pełny klon (inaczej Heroku może odrzucić polecenie git push). Wystarczy wypchnąć tę konfigurację do Bitbucket, aby zaobserwować pierwsze zautomatyzowane wdrożenie w środowisku przejściowym.
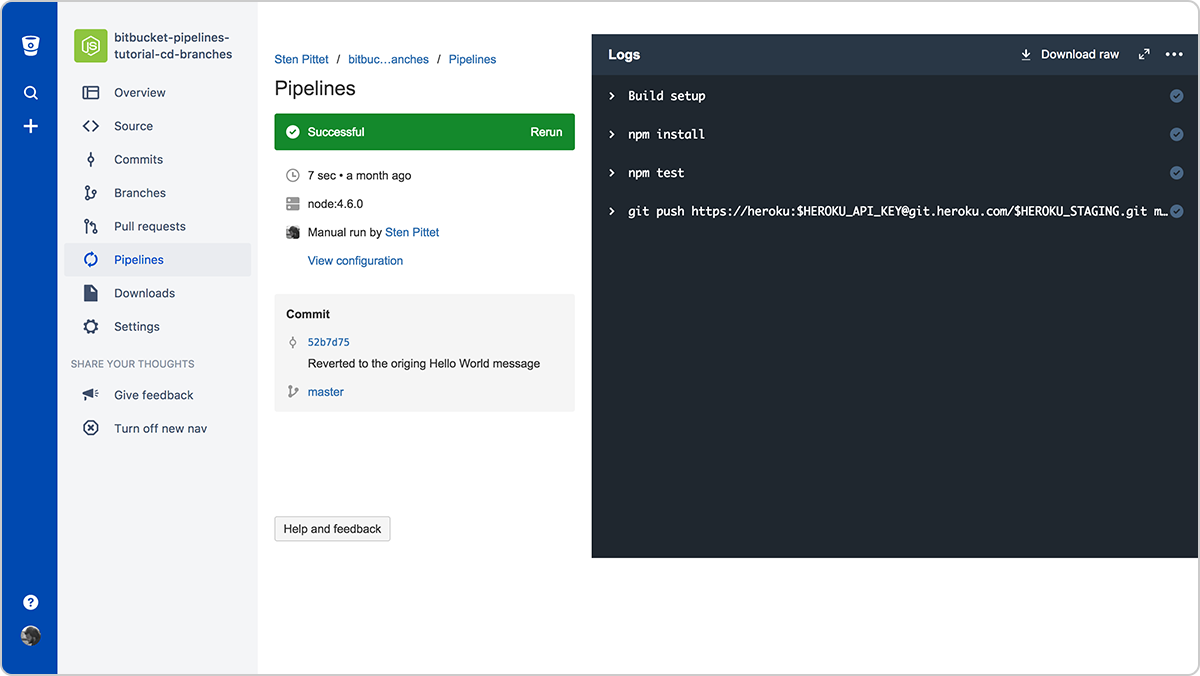
Skuteczny pipeline do wdrażania naszej aplikacji w środowisku stagingowym
Jak można się domyślić, wystarczy dodać kolejny pipeline do gałęzi production, aby zautomatyzować wydawanie do środowiska produkcyjnego po scaleniu zmian z gałęzią production. Wprowadź tę zmianę w swoim terminalu i wypchnij ją do początkowej gałęzi main.
bitbucket-pipelines.yml
image: node:16
clone:
depth: full
pipelines:
branches:
main:
- step:
name: deploy_to_staging
script:
- npm install
- npm test
- git push https://heroku:$HEROKU_API_KEY@git.heroku.com/thawing-river-12585.git main
production:
- step:
name: deploy_to_production
script:
- npm install
- npm test
- git push https://heroku:$HEROKU_API_KEY@git.heroku.com/fierce-basin-45507.git production:mainZastąp adres URL przy poleceniu git push dla gałęzi main adresem URL środowiska przejściowego z wiersza git remote -vv, a adres URL przy poleceniu git push dla środowiska produkcyjnego adresem URL production z polecenia git remote -vv.
Ponownie przeprowadzamy testy w obrębie gałęzi produkcyjnej, aby przed wydaniem aplikacji zyskać pewność, że kompilacja nie zawiera błędów.
Nasze pipeline'y są teraz skonfigurowane i możemy wprowadzić w gałęzi production ograniczenie, które pozwoli akceptować wyłącznie scalenia dokonane za pośrednictwem pull requestów. Wystarczy wybrać kolejno opcje Przepływ pracy > Uprawnienia gałęzi w ustawieniach repozytorium, aby wprowadzić ograniczenia dotyczące gałęzi production. Jest to ważny krok, ponieważ chcemy uniemożliwić ludziom wypychanie kodu prosto do środowiska produkcyjnego z ich komputerów lokalnych.
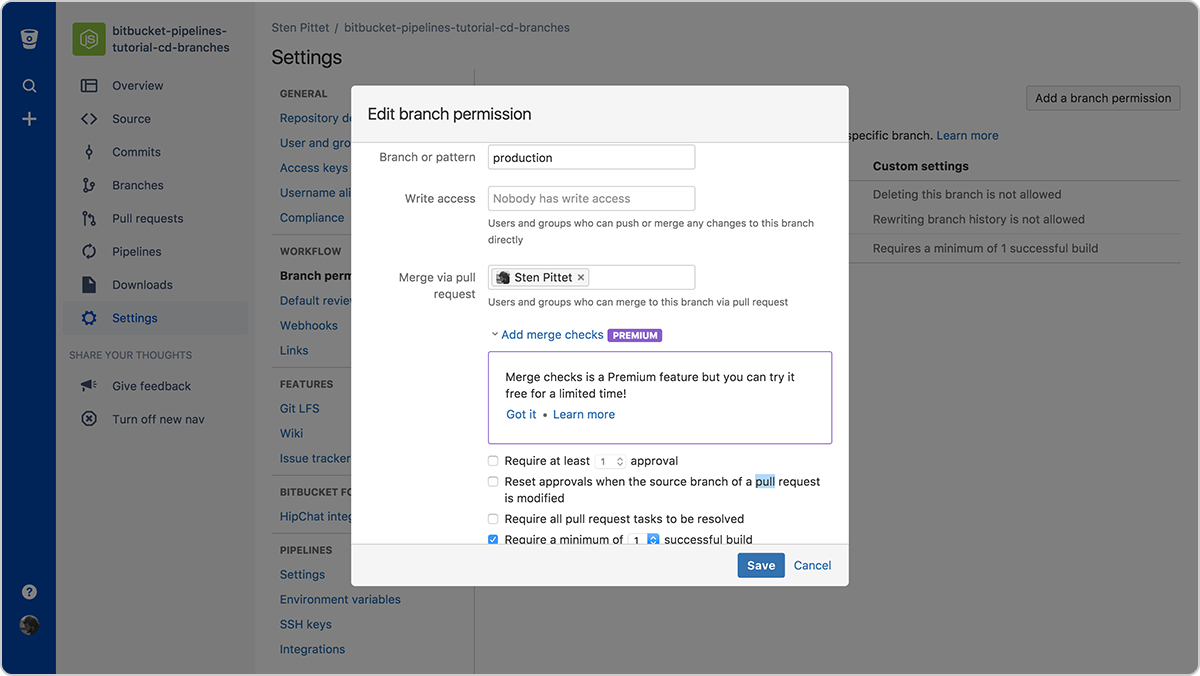
Konfigurowanie uprawnień do gałęzi production
Na powyższym zrzucie ekranu widoczne są następujące uprawnienia:
- Nikt nie ma uprawnień do zapisu.
- Tylko jeden programista ma uprawnienia do scalania z gałęzią.
Dodaliśmy również kontrolę scalania, aby przed scaleniem kodu zyskać pewność, że gałąź źródłowa ma co najmniej jedną zieloną kompilację. To pozwoli nam zaoszczędzić czas poświęcany na kompilację i uniemożliwić programistom scalenie niewłaściwego kodu z naszą gałęzią produkcyjną.
Po wykonaniu tej czynności można utworzyć pull request, aby scalić kod z gałęzi main z kodem gałęzi production, a następnie wydać nowe zmiany w środowisku produkcyjnym.
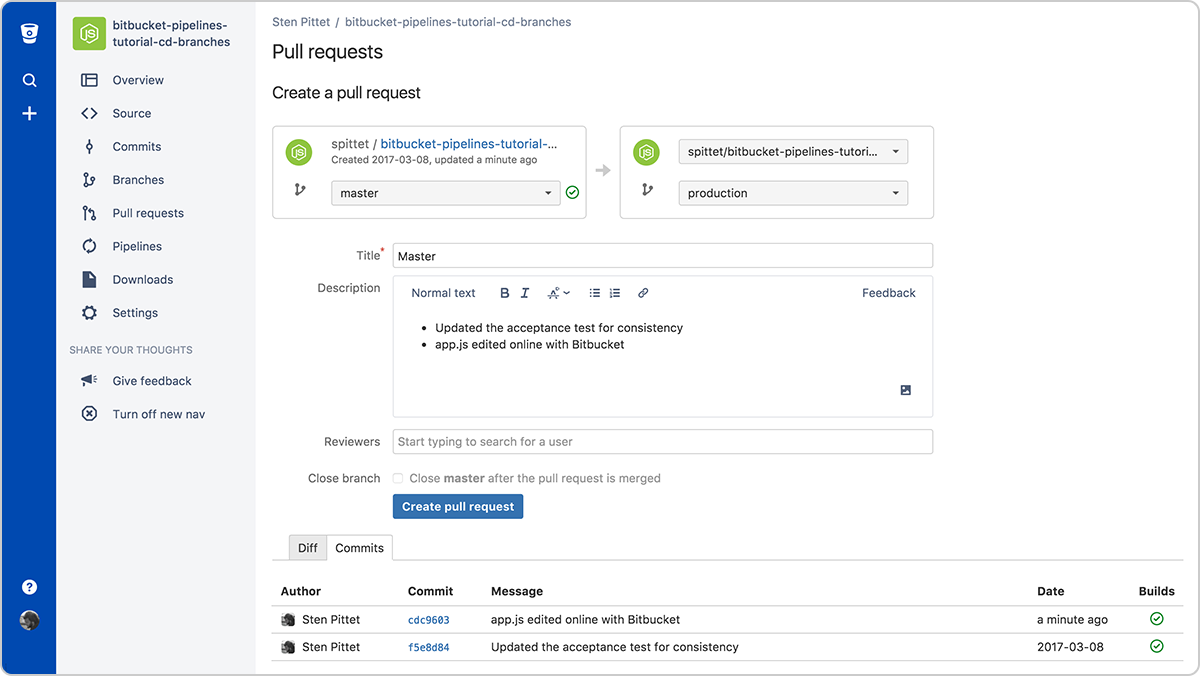
Tworzenie pull requestu w celu scalenia zmian z gałęzią production
Bezpośrednio po scaleniu pull requestu wyzwolony zostanie nowy pipeline dla gałęzi production.
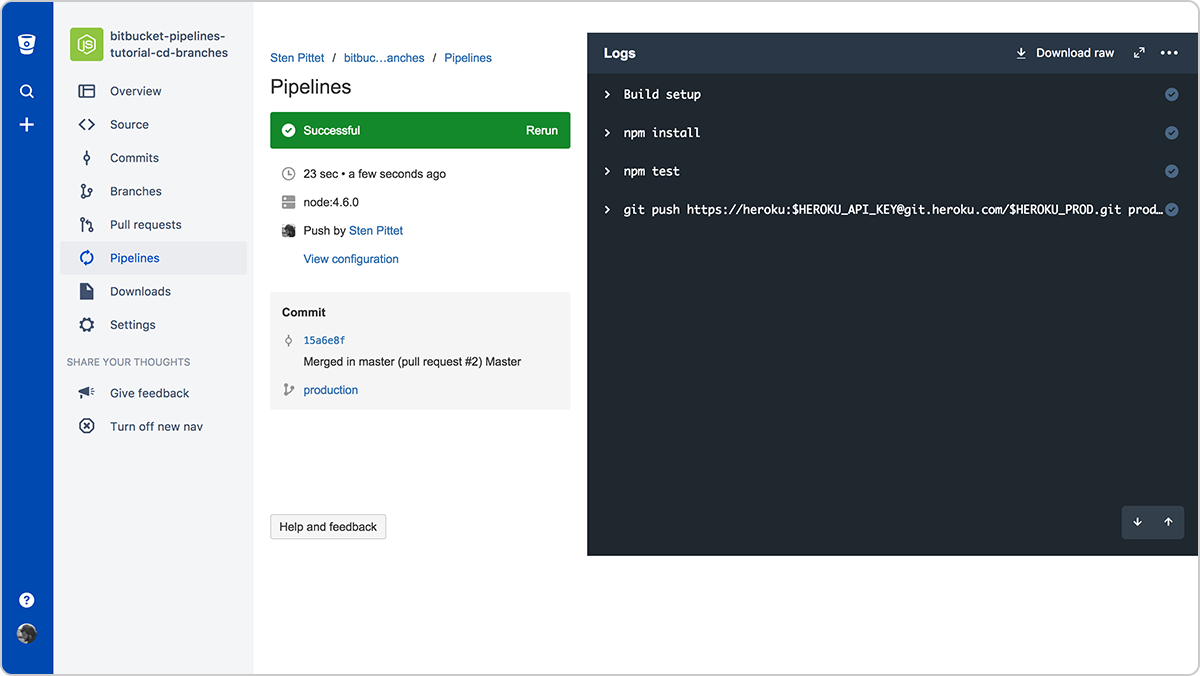
Po jego zakończeniu nowe zmiany zostaną wdrożone w środowisku produkcyjnym.
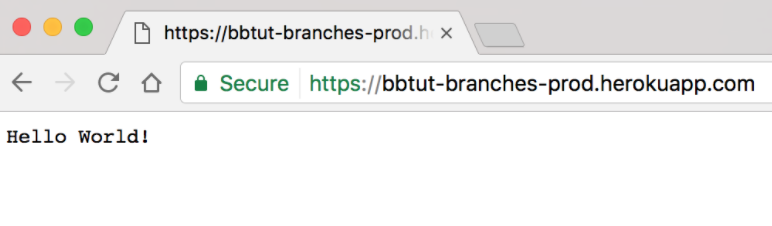
Środowisko produkcyjne jest aktualne!
W ten sposób skonfigurowaliśmy przepływ pracy oparty na ciągłym dostarczaniu przy użyciu aplikacji Bitbucket Pipelines i możemy bezpiecznie wydawać kod klientom za pomocą pull requestów.
Ostateczną wersję źródła z tego przykładu znajdziesz w repozytorium pod poniższym łączem.
Ciągłe dostarczanie z ręcznym wyzwalaniem wydania
Ta konfiguracja sprawdza się świetnie w zespołach praktykujących tworzenie oprogramowania w oparciu o gałąź główną.
W Bitbucket Pipelines można skonfigurować pipeline'y niestandardowe z możliwością ręcznego wyzwalania. Można ich używać w różnych celach: do czasochłonnych testów, których nie chcemy wykonywać przy każdym wypchnięciu, lub do wykonywania konkretnych czynności, nad którymi chcemy sprawować kontrolę. My wykorzystamy niestandardowy pipeline, aby skonfigurować przepływ pracy oparty na ciągłym dostarczaniu, w którym wypchnięcia do gałęzi main będą wdrażane automatycznie w środowisku przejściowym, a commity będą wdrażane ręcznie w środowisku produkcyjnym.
Po skonfigurowaniu środowiska przejściowego możemy po prostu dodać niestandardowy pipeline do naszej konfiguracji bitbucket-pipelines.yml, którą wykorzystamy do ręcznego wyzwalania wydania do środowiska produkcyjnego.
bitbucket-pipelines.yml
image: node:16
clone:
depth: full
pipelines:
branches:
main:
- step:
name: deploy_to_staging
script:
- npm install
- npm test
- git push https://heroku:$HEROKU_API_KEY@git.heroku.com/thawing-river-12585.git main
custom:
prod-deployment:
- step:
name: deploy_to_production
script:
- npm install
- npm test
- git push https://heroku:$HEROKU_API_KEY@git.heroku.com/fierce-basin-45507.git production:mainZastąp adres URL przy poleceniu git push dla gałęzi main adresem URL środowiska stagingowego z wiersza git remote -vv, a adres URL przy poleceniu git push dla środowiska produkcyjnego adresem URL production z polecenia git remote -vv.
Po wypchnięciu nowej konfiguracji do repozytorium Bitbucket można przejść do commita i kliknąć łącze Uruchom pipeline pod danymi commita, aby wyzwolić wdrożenie w środowisku produkcyjnym.
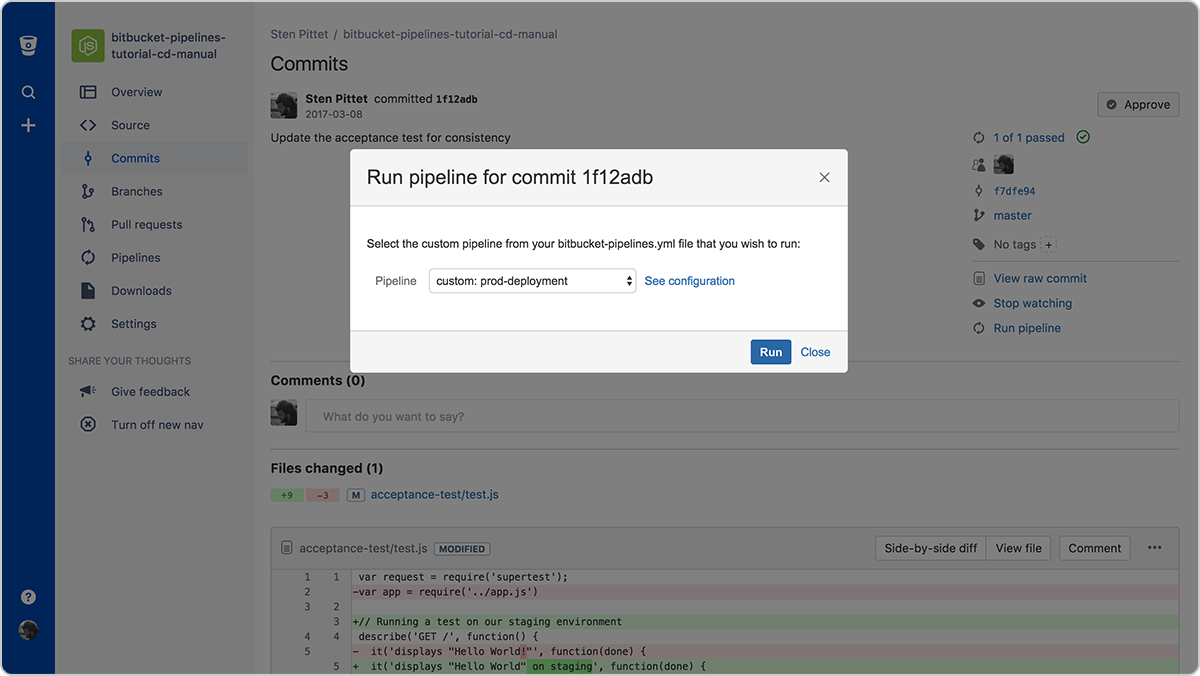
Uruchomienie pipeline'u spowoduje wyświetlenie listy dostępnych pipeline'ów niestandardowych
Wystarczy nacisnąć przycisk Uruchom, a nastąpi przekierowanie do pipeline'u wdrażania w środowisku produkcyjnym, w którym można monitorować dzienniki.
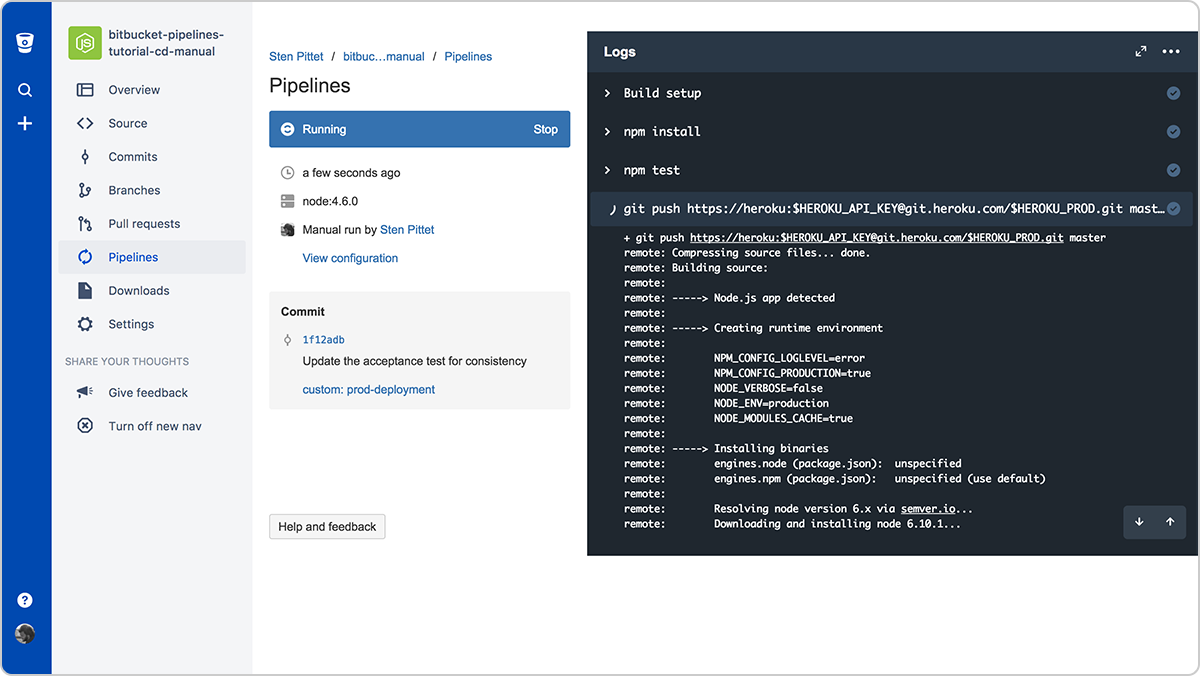
W sekcji danych commita pipeline'u widać nazwę pipeline'u niestandardowego, który zastosowano. Teraz wszystko jest gotowe do użycia nowej konfiguracji Bitbucket Pipelines do ciągłego dostarczania i możesz sprawdzić swoją aplikację Hello World w środowisku produkcyjnym, aby się upewnić, że wszystko przebiegło prawidłowo!
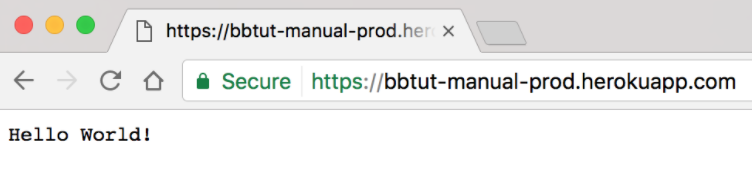
Nasza aplikacja Hello World została wdrożona w środowisku produkcyjnym przy użyciu ręcznego wyzwalacza
Ostateczną wersję źródła z tego przykładu znajdziesz w repozytorium pod poniższym łączem.

Udostępnij ten artykuł
Następny temat
Zalecane lektury
Dodaj te zasoby do zakładek, aby dowiedzieć się więcej na temat rodzajów zespołów DevOps lub otrzymywać aktualności na temat metodyki DevOps w Atlassian.

Społeczność DevOps

Ścieżka szkoleniowa DevOps