

巨大なリポジトリを Git でうまく扱う方法

Nicola Paolucci
開発者アドボケート
Git は、コード・ベースの発展過程を記録し、開発者間の協同作業を効率化する強力なツールです。しかし、記録対象のリポジトリがとてつもなく巨大なものになったときは何が起こるのでしょうか?
この記事では、それに対処するためのいくつかのテクニックを紹介します。
大規模リポジトリの 2 つのカテゴリ
考えてみると、リポジトリが巨大化する主な理由は大きく 2 つあります。
- 非常に長い期間にわたって履歴が積み上げられた (プロジェクトが非常に長い期間継続的に拡大を続けたために開発成果が積み重なった) 場合
- 追跡してコードと組み合わせる必要がある巨大なバイナリ アセットが含まれている場合
... または両方が該当します。
2 つ目のタイプの問題は、既に廃止された古いバイナリ アーティファクトがまだリポジトリに保存されているため、さらに悪化することがありますが、そのためには比較的簡単な (面倒かもしれませんが) 修正があります。以下を参照してください。
各シナリオのテクニックと回避策は、補完的なものになることもあるものの、それぞれは異なるものですので、1 つずつ取り上げていきましょう。
非常に長い履歴を持つリポジトリをクローンする
リポジトリを「大規模」と認定するためのしきい値はかなり高いですが、それでもクローンするのは面倒です。そして、長い歴史を常に避けることはできません。一部のリポジトリは、法的または規制上の理由からそのまま保管する必要があります。
単純な解決法は shallow clone です
高速クローンを作成し、開発者とシステムの時間とディスク容量を節約する第一の解決策は、最近のリビジョンのみをコピーすることです。Git の shallow clone オプションを使用すると、リポジトリの履歴の最新の n 個のコミットのみをプル ダウンできます。
その方法は、単に --depth オプションをつけるだけです。例:
git clone --depth [depth] [remote-url]
プロジェクトが 10 年以上にわたる歴史を持ち、その間にリポジトリが積み上げられてきたような場合 (たとえば、Jira の場合、私たちは 11 年もの歴史を有するコード ベースを Git に移行しました)、この方法でリポジトリでのかなりの時間を節約できます。
Jira のフル クローンは 677MB で、作業ディレクトリはさらに 320 MB で、47,000 件以上のコミットで構成されています。リポジトリの shallow clone の所要時間は 29.5 秒ですが、すべての履歴を含むフル クローンでは 4 分 24 秒かかります。プロジェクトが時間の経過とともに飲み込んだバイナリ アセットの数に比例して恩恵が大きくなります。
関連資料
Git リポジトリ全体を移動する方法
ソリューションを見る
Bitbucket Cloud での Git の使用方法についてのチュートリアルです。
ヒント: Git リポジトリに接続されたビルド システムも、shallow clone の恩恵を受けることができます。
かつての shallow clone は、一部の機能がほとんどサポートされておらず、Git の世界の問題児とでも言えるものでした。しかし、最近のバージョン (1.9 以降) において状況は大きく改善されており、現在では shallow clone からでもリポジトリへの pull や push を正しく行うことができます。
部分的な解決策は、git filter branch です。
間違ってコミットした多くのバイナリ データや今後使用することのない古いデータを含む巨大リポジトリの場合は、git filter-branch が非常に有用なソリューションです。このコマンドを使用すると、プロジェクトの履歴全体を調べて、あらかじめ設定したパターンに従ってファイルの抽出、変更、除外などの処理を行うことができます。
リポジトリが重い場所を特定したら、これは非常に強力なツールになります。サイズの大きなオブジェクトを調べるためのヘルパー・スクリプトが提供されているため、簡単に利用できます。
構文は次のようになります。
git filter-branch --tree-filter 'rm -rf [/path/to/spurious/asset/folder]'ただし、git filter-branch にはちょっとした問題点があります。_filter-branch_ を実行すると、実質的にはプロジェクトのすべての履歴が書き換えられたことになり、すべてのコミット ID が変化します。このため、すべての開発者が実行後のリポジトリを再度クローンする必要が生じます。
したがって、git filter-branch を使用してクリーンアップを行う予定がある場合、それをチーム内に周知し、その操作の実行中はリポジトリを短時間フリーズし、終了後は全員に対してリポジトリを再度クローンするように通知する必要があります。
ヒント: Git リポジトリを分解する方法については、この記事で git filter-branch の詳細をご覧ください。
git shallow-clone の代替: 1 つのブランチのみをクローンする
git 1.7.10 から、次のようにクローンの対象を単一ブランチに制限できるようになりました。
git clone [remote url] --branch [branch_name] --single-branch [folder]この特定の解決策は、長期間実行されていて差異が多いブランチの場合や、ブランチの数が多く、そのうちの少数のブランチのみを実行する必要がある場合に便利です。差異がほとんどない少数のブランチしかない場合は、これを使用しても大きな違いは見られません。
巨大なバイナリ アセットを持つリポジトリの処理
2 つ目のタイプの巨大なリポジトリは、巨大なバイナリ アセットを持つリポジトリです。これは多数のさまざまなソフトウェア (およびソフトウェア以外の) チームが目にするものです。ゲーム チームは巨大な 3D モデルを扱い、Web 開発チームは未加工の画像アセットを追跡する必要があり、CAD チームはバイナリ成果物のステータスを操作し、追跡する必要があるかもしれません。
Git のバイナリ アセット処理能力は特に問題があるわけでも、特に優れているわけでもありません。既定では Git はバイナリ アセットについて一連のバージョンのすべてを圧縮して格納しますが、これはバージョン数が多い場合は明らかに得策ではありません。
この状況を改善するには、いくつかの基本的な手法があります。たとえば、ガベージ コレクション (‘git gc’) を実行する、または .gitattributes でバイナリ タイプを指定して delta コミットを適用するなどです。
しかし、プロジェクトのバイナリ アセットの性質を考えることが重要です。そうすることで効果的なアプローチを決定できるようになります。たとえば、考慮すべき点をいくつかご紹介します。
- ある種のメタデータ ヘッダーに限らず、大きな変更のあるバイナリ ファイルについては多くの場合 delta 圧縮は有効ではありません。したがって、余計な delta 圧縮動作がリパック時に発生することを防止するために「delta off」とすることを推奨します。
- 上記のシナリオでは、それらのファイルに対して zlib 圧縮もあまり有効ではないため、「core.compression 0」または「core.loosecompression 0」を指定して圧縮を無効にすることができます。ただし、これは圧縮が有効なすべての非バイナリ ファイルに悪影響を与える可能性のあるグローバル設定であるため、これはバイナリ アセットを別のリポジトリに分離した場合に有用と言えます。
- 「git gc」は「重複した」ルーズ・オブジェクトを 1 個のパック・ファイルに変換しますが、何らかの方法でファイルを圧縮しなければ、ここでも結果として生成されるパック・ファイルの圧縮効果は小さいと思われることに留意してください。
- 「core.bigFileThreshold」の微調整。512 MB より大きなファイルは delta 圧縮されないため (.gitattributes における設定がない場合)、この方法を試す価値はあるでしょう。
巨大フォルダー ツリーのソリューション: git sparse-checkout
Git の sparse checkout オプション (Git 1.7.0 以降において提供) は、バイナリ アセットの問題に対処するためのちょっとした助けになります。このテクニックでは生成するフォルダーを明示的に指定できるため、作業ディレクトリはクリーンに保たれます。残念ながらローカル リポジトリ全体のサイズは変わりませんが、フォルダー ツリーのサイズが巨大なものになっている場合は有用なテクニックです。
関係するコマンドは何でしょうか? 次のようになります。
- リポジトリ全体を一度クローンする:「git clone」
- 機能を有効にする:「git config core.sparsecheckout true」
- アセット フォルダーを除外して、明確に必要なフォルダーのみを指定する
- echo src/ › .git/info/sparse-checkout
- 指定に従ってツリーを読み込む:
- git read-tree -m -u HEAD
上記操作を行った後は通常の git コマンドを使用できますが、作業ディレクトリには上で指定したフォルダーのみが含まれます。
巨大ファイルの更新タイミングを制御するソリューション: サブモジュール
[最新情報]... または、すべてスキップして Git LFS を使用できます
大きなファイルを定期的に扱う場合、アトラシアンが 2015 年に GitHub と共同開発した大容量ファイル サポート (LFS) を活用するのが最善の解決策かもしれません。(はい、そのとおりです。Git プロジェクトへのオープンソースによる寄与のために GitHub とチームを組んでいます。)
Git LFS は、ファイル自体をリポジトリに格納するのではなく、大きなファイルへのポインターをリポジトリ内に格納する拡張機能です。実際のファイルはリモート サーバーに保存されます。ご想像のとおり、これによりリポジトリのクローン作成にかかる時間が大幅に短縮されます。
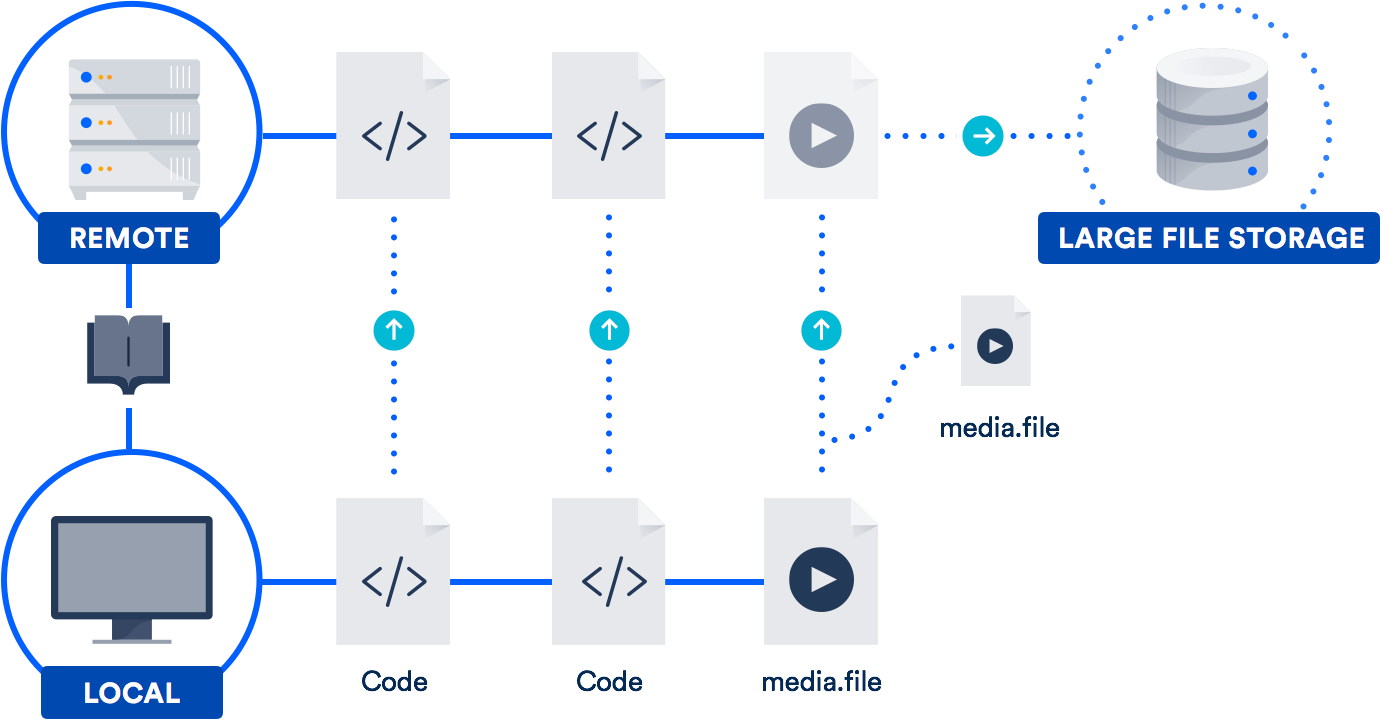
Bitbucket は GitHub と同様に Git LFS をサポートしています。ですから、あなたは既に Git LFS を利用できる可能性があります。これは、デザイナー、ビデオグラファー、ミュージシャン、CAD ユーザーなどのチームに特に役立ちます。
結論
リポジトリの履歴や取り扱うデータが大きいからというだけで、Git のすばらしい機能を諦める必要はありません。どちらの問題に対しても有用なソリューションがあります。
サブモジュール、プロジェクトの依存関係、Git LFS の詳細については、上記でリンクされている他の記事を参照してください。また、コマンドとワークフローについて復習するには、Git マイクロサイトに各種チュートリアルが揃っています。コーディングを試してみましょう。
この記事を共有する
次のトピック
おすすめコンテンツ
次のリソースをブックマークして、DevOps チームのタイプに関する詳細や、アトラシアンの DevOps についての継続的な更新をご覧ください。

Bitbucket ブログ

DevOps ラーニング パス
