

Incident management for high-velocity teams
The importance of an incident postmortem process
Incidents happen.
They just do. As our systems grow in scale and complexity, failures are inevitable.
Incidents are also a learning opportunity.
A chance to uncover vulnerabilities in your system. An opportunity to mitigate repeat incidents and decrease time to resolution. A time to bring your teams together and plan for how they can be even better next time.
The best way to work through what happened during an incident and capture any lessons learned is by conducting an incident postmortem, also known as a post-incident review.
An incident postmortem brings people together to discuss the details of an incident: why it happened, its impact, what actions were taken to mitigate it and resolve it, and what should be done to prevent it from happening again.
Thanks to tools like version control, feature flags, and continuous delivery, a lot of incidents can be quickly “undone.” Many incidents are caused by some bug in a change pushed to production, and rolling back that change can get the app up and running again. This is really beneficial for everyone, it gets the service quickly working again. But it often doesn’t help you understand what failed and why. This is where postmortems come in.
An incident postmortem is a framework for learning from incidents and turning problems into progress. It also builds trust with customers, colleagues, and end users (basically the folks affected by the incident) and lets them know your team is working to minimize future incidents and impact.
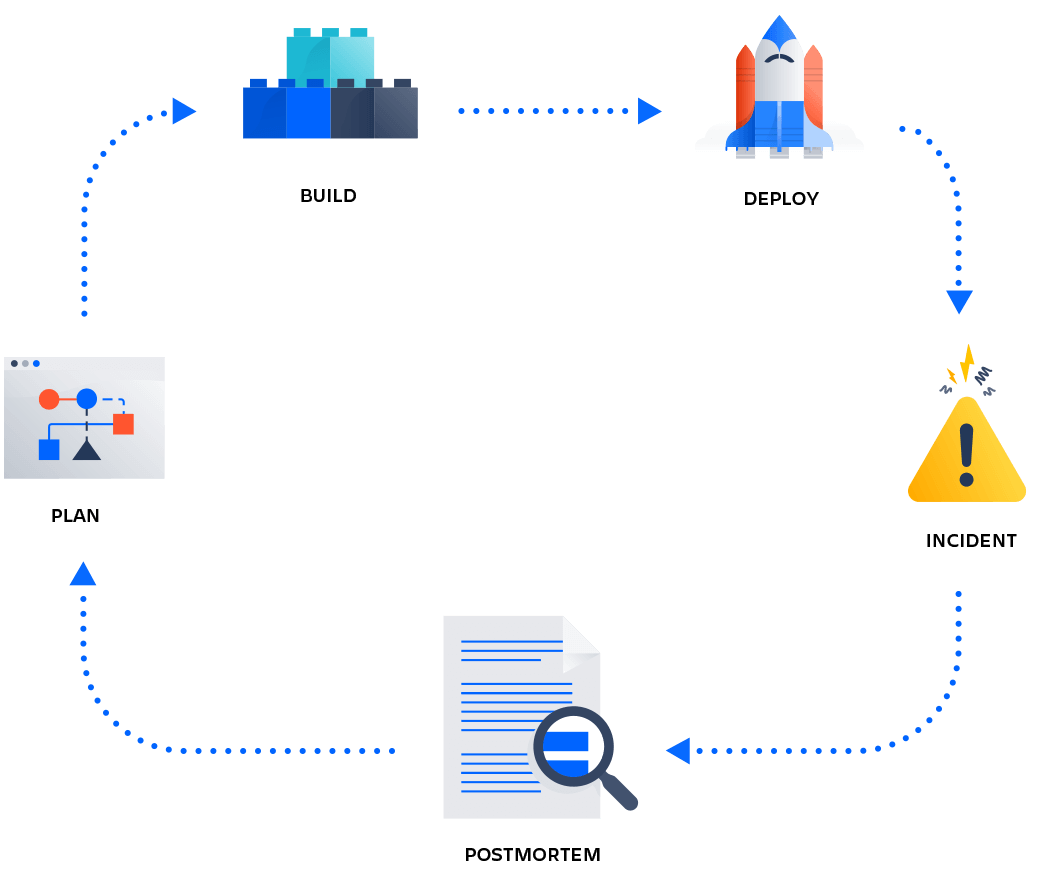
A postmortem is an important step in the lifecycle of an always-on service. The findings from your postmortem should feed right back into your planning process. This ensures that the critical remediation work identified in the postmortem finds a place in upcoming work and is balanced against other upcoming work and priorities.
Setting up an on-call schedule with Opsgenie
In this tutorial, you’ll learn how to set up an on-call schedule, apply override rules, configure on-call notifications, and more, all within Opsgenie.
Read this tutorialIncident postmortem template
Clear documentation is key to an effective incident postmortem. Use this postmortem template to capture all of the important details about an incident.
Read this article