Tipps für Scripting-Tasks mit Bitbucket Pipelines

Sten Pittet
Gastautor
Mit Bitbucket Pipelines kannst du schnell einen Continuous-Integration- oder Continuous-Delivery-Workflow für deine Repositorys einführen. Ein wesentlicher Teil dieses Prozesses besteht darin, manuelle Prozesse in Skripte umzuwandeln, die von einem Rechner automatisch ausgeführt werden können, ohne dass menschliches Eingreifen erforderlich ist. Manchmal kann es jedoch kompliziert sein, Aufgaben zu automatisieren, da du möglicherweise Probleme mit der Authentifizierung, der Installation von Abhängigkeiten oder beim Melden von Problemen hast. Dieser Leitfaden unterstützt dich mit einigen Tipps zum Schreiben deiner Skripte!
Uhrzeit
30 Minuten
Zielpublikum
Du bist neu bei Continuous Deployment und/oder Bitbucket Pipelines
Schritt 1: Protokolliere keine vertraulichen Informationen!
Bevor du weiter in die Welt der Automatisierung eintauchst, solltest du deine Protokolle überprüfen und sicherstellen, dass du keine vertraulichen Daten wie API-Schlüssel, Anmeldedaten oder sonstige Informationen ausgibst, die dein System gefährden könnten. Sobald du Bitbucket Pipelines zum Ausführen deiner Skripte verwendest, werden die Protokolle gespeichert und können von jedem gelesen werden, der Zugriff auf dein Repository hat.
Schritt 2: Verwende SSH-Schlüssel, um eine Verbindung zu Remote-Servern herzustellen
Bei der Automatisierung ist die Authentifizierung meistens einer der hinderlichsten Teile. SSH-Schlüssel haben den doppelten Vorteil, dass durch sie eine Verbindung zu Remote-Servern sehr leicht zu verwalten ist und dass sie sehr sicher sind. Mit Bitbucket Pipelines kannst du ganz einfach ein neues Schlüsselpaar generieren, das bei jedem Pipeline-Lauf genutzt werden kann, um sich mit Remote-Servern zu verbinden.
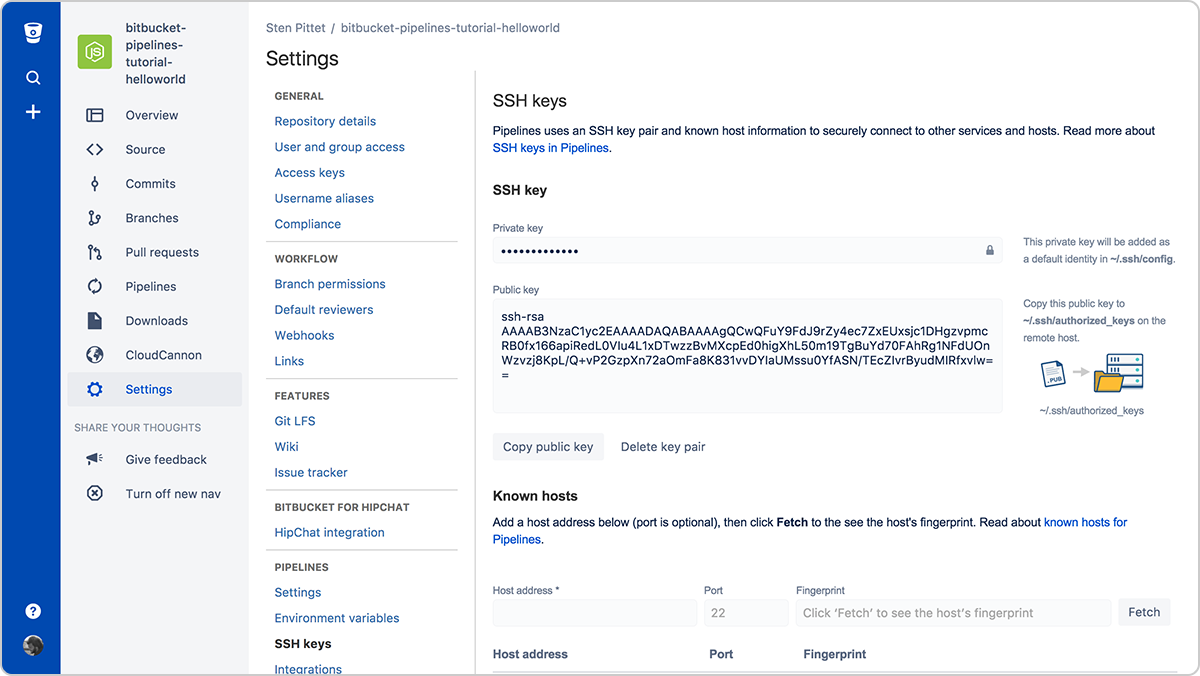
Du musst einfach den öffentlichen Schlüssel in deinem Remote-Server kopieren, um von deiner laufenden Pipeline aus eine Verbindung zu ihm herstellen zu können. Wenn beispielsweise die SSH-Schlüssel auf dem Server eingerichtet sind (du kannst eine URL oder eine IP-Adresse verwenden), dann würde das folgende Skript Dateien unter dem Verzeichnis /var/www auflisten, ohne dass du ein Passwort angeben musst.
bitbucket-pipelines.yml
image: node:4.6.0
pipelines:
default:
- step:
script:
- ssh <user>@<server> ls -l /var/wwwVergiss nicht, im Abschnitt "Known hosts" (Bekannte Hosts) alle Server zu registrieren, mit denen du eine Verbindung herstellen musst. Tust du das nicht, wird deine Pipeline stecken bleiben und auf die Genehmigung warten, wenn du versuchst, eine Verbindung zum Remote-Server herzustellen.
Schritt 3: Verwende gesicherte Umgebungsvariablen für API-Schlüssel und Anmeldedaten
Wenn du eine Remote-API als Teil deines Skripts verwenden musst, kann es gut sein, dass du die geschützten Ressourcen deines API-Anbieters mit einem API-Schlüssel verwenden darfst. Du kannst mithilfe von gesicherten Umgebungsvariablen Anmeldedaten sicher zu Bitbucket Pipelines hinzufügen. Nach dem Speichern kannst du sie in deinen Skripten aufrufen. In der Protokollausgabe bleiben sie maskiert.
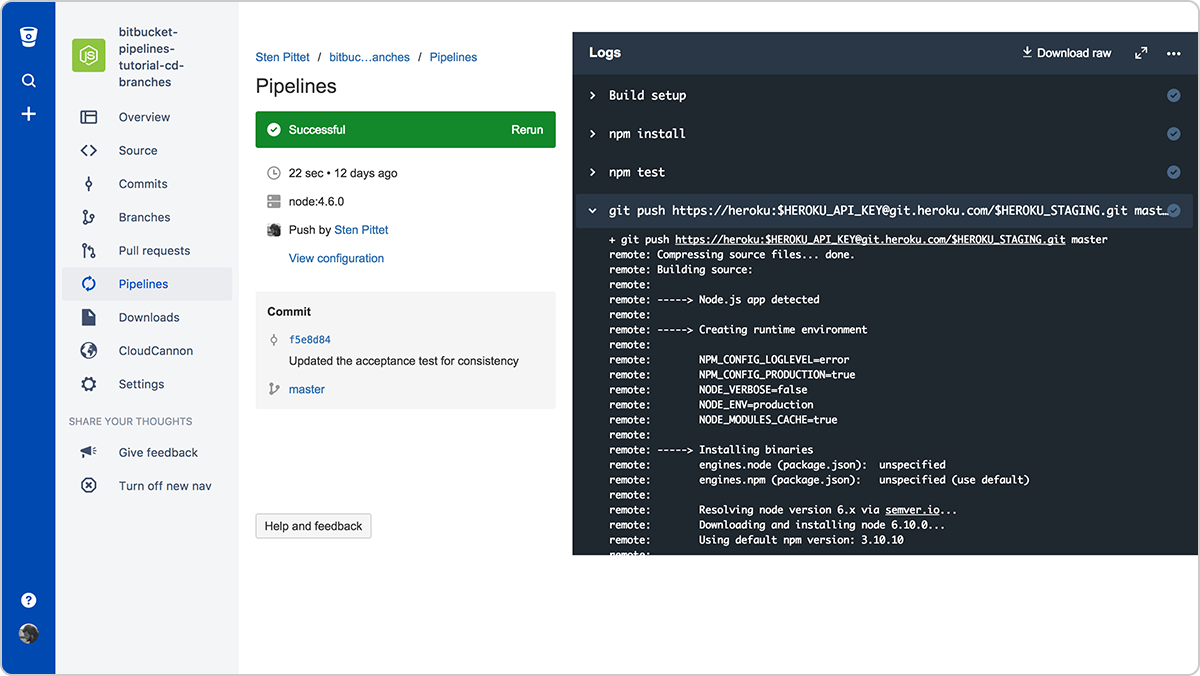
Schritt 4: Führe Befehle im nicht-interaktiven Modus aus
Wenn du Abhängigkeiten als Teil deines Skripts installieren musst, stelle sicher, dass es den Benutzer nicht zur Validierung oder Eingabe auffordert. Schau in der Dokumentation der von dir verwendeten Befehle nach, ob es ein Flag gibt, mit dem du sie nicht-interaktiv ausführen kannst.
Das Flag "-y" im folgenden Befehl wird beispielsweise PostgreSQL auf einem Debian-Server installieren.
apt-get install -y postgresqlUnd mit dem Flag "-q" kannst du Google-Cloud-SDK-Befehle nicht-interaktiv ausführen.
gcloud -q app deploy app.yamlSchritt 5: Erstelle deine eigenen sofort einsatzbereiten Docker-Images
Es kann zeitintensiv sein, die für die Ausführung deiner Pipeline nötigen Abhängigkeiten zu installieren. Du kannst sehr viel Laufzeit sparen, indem du mit den Basis-Tools und Paketen, die zum Erstellen und Testen deiner Anwendung erforderlich sind, dein eigenes Docker-Image erstellst.
Beispielsweise installieren wir in der folgenden Pipelines-Konfiguration am Anfang AWS CLI, um es später für das Deployment der Anwendung in AWS Elastic Beanstalk zu nutzen.
bitbucket-pipelines.yml
image: node:7.5.0
pipelines:
default:
- step:
script: # Modify the commands below to build your repository.
- apt-get update && apt-get install -y python-dev
- curl -O https://bootstrap.pypa.io/get-pip.py
- python get-pip.py
- pip install awsebcli --upgrade
- npm install
- npm test
- eb init helloworld-beanstalk-bbp -r eu-west-1 -p node
- eb deploy hw-eb-tutorialDas Problem hier ist, dass sich die AWS CLI nicht mit jedem Commit ändert. Das heißt, wir verschwenden etwas Zeit damit, eine Abhängigkeit zu installieren, die standardmäßig gebündelt sein könnte.
Das folgende Dockerfile könnte verwendet werden, um ein benutzerdefiniertes Docker-Image zu erstellen, das für Deployments in Elastic Beanstalk bereit ist.
Dockerfile
FROM node:7.5.0
RUN apt-get update \ && apt-get install -y python-dev \ && cd /tmp \ && curl -O https://bootstrap.pypa.io/get-pip.py \ && python get-pip.py \ && pip install awsebcli --upgrade \ && apt-get clean \ && rm -rf /var/lib/apt/lists/* /tmp/* /var/tmp/*Wenn ich es unter die Referenz spittet/my-custom-image pushe, dann kann ich meine Konfiguration von Bitbucket Pipelines so vereinfachen, dass sie nur die Befehle enthält, die zum Erstellen, Testen und Bereitstellen meiner Anwendung erforderlich sind.
bitbucket-pipelines.yml
image: spittet/my-custom-image
pipelines:
default:
- step:
script: # Modify the commands below to build your repository.
- npm install
- npm test
- eb init helloworld-beanstalk-bbp -r eu-west-1 -p node
- eb deploy hw-eb-tutorialEin Wort zum Schluss: Skripts sind auch Code
Mit diesen Tipps kannst du manuelle Aufgaben in automatisierte Prozesse umwandeln, die wiederholt und zuverlässig von einem Dienst wie Bitbucket Pipelines ausgeführt werden können. Früher oder später werden sie zu Wächtern deiner Releases und zu leistungsstarken Tools, die das Deployment deiner gesamten Produktionsumgebungen über mehrere Server und Plattformen hinweg auslösen können.
Darum solltest du deine Automatisierungsskripte wie Code behandeln und sie den gleichen Prüfungen und Qualitätsprozessen unterziehen, wie du es bei deinem Code tust. Glücklicherweise kannst du das ganz einfach mit Bitbucket durchführen, da deine Pipeline-Konfiguration mit deinem Code eingecheckt wird. So kannst du Pull-Requests im richtigen Kontext erstellen.
Und zu guter Letzt: Vergiss nicht, deine Skripts in einer Testumgebung auszuführen, bevor du sie in der Produktion anwendest – diese Extraminuten können dich davor bewahren, versehentlich Produktionsdaten zu löschen.

Diesen Artikel teilen
Nächstes Thema
Lesenswert
Füge diese Ressourcen deinen Lesezeichen hinzu, um mehr über DevOps-Teams und fortlaufende Updates zu DevOps bei Atlassian zu erfahren.

DevOps-Community

DevOps-Lernpfad