



Announcing mcp-compressor: reduce MCP tool token usage by up to 97%
MCP servers can be extremely token-hungry — a single large server can consume 10,000–17,000+ tokens of context per request just for tool descriptions. mcp-compressor is an open-source MCP proxy from Atlassian Labs that wraps any existing MCP server and reduces its tool-description overhead by 70–97%, without changing how the agent calls tools.
Drop it in front of any MCP server in your mcp.json — no changes to the server or the agent required.
Model Context Protocol (MCP) has made it dramatically easier to connect LLM agents to real tools. The trade-off is that every MCP server tends to bring along a large bundle of tool descriptions and schemas, and those tokens are expensive. In Rovo Dev, we found that if you simply expose every tool from every server directly to the model, you can spend a surprisingly large fraction of your prompt budget on tool metadata before the model has even started solving the user’s problem.
That pushed us toward a simple question: can we preserve the full power of MCP tool calling while paying much less of the upfront token tax?
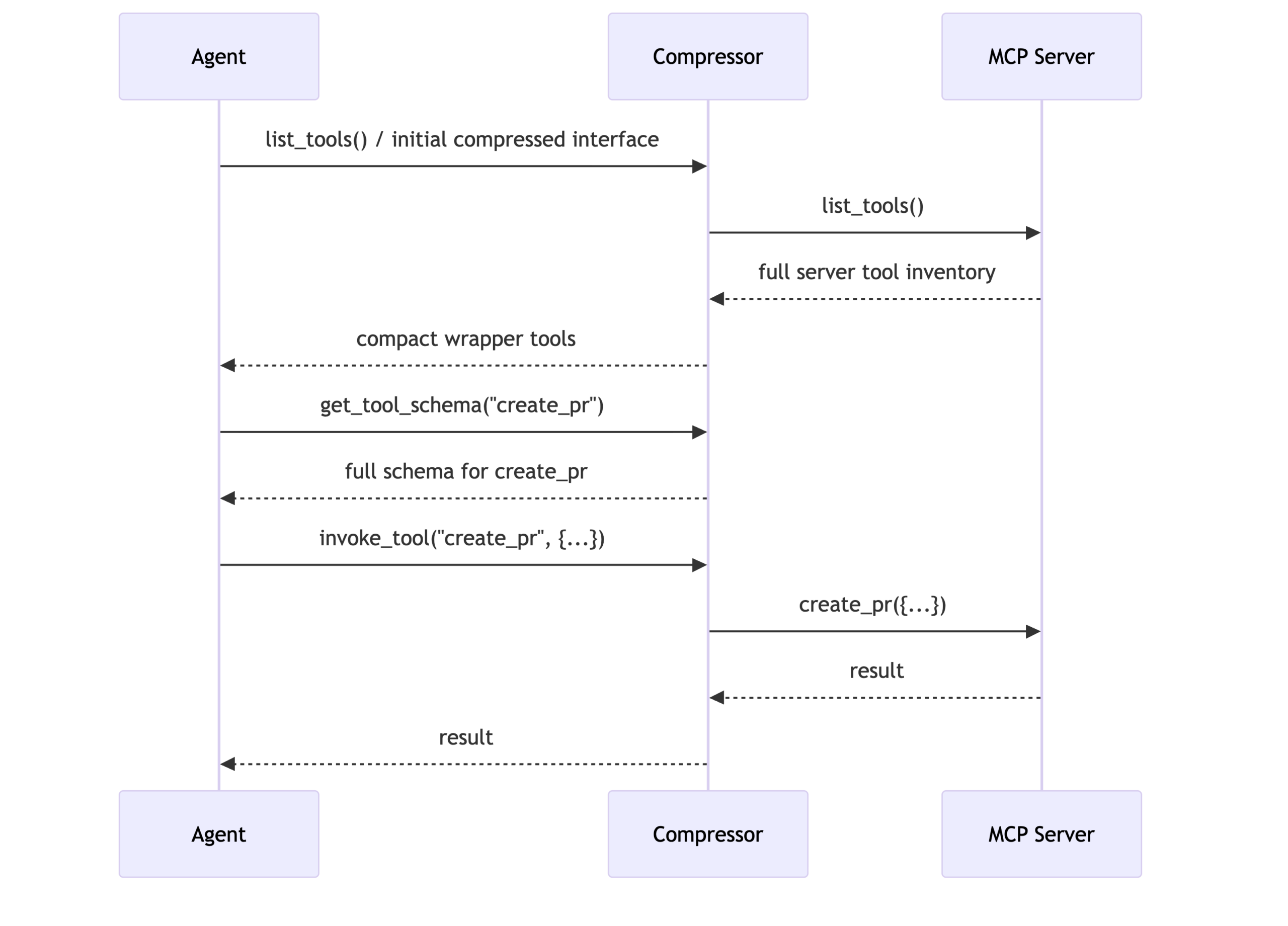
Our answer is tool compression: instead of surfacing dozens or hundreds of full tool definitions to the model, we replace an MCP server’s toolset with a tiny proxy interface that lets the agent discover details on demand.
in one sentence
Rovo Dev compresses large MCP toolsets into a small, cache-friendly wrapper interface, then expands individual tool schemas only when the model actually needs them.
Why this matters
As MCP adoption grows, the number of tools available to an agent grows with it. That is great for capability, but expensive for context. For example:
- The official Atlassian MCP server consuming roughly 10k tokens for Jira and Confluence tools alone.
- The official GitHub MCP server exposing 94 tools and consuming roughly 17.6k tokens.
If you combine several large MCP servers, it becomes easy to spend 30k+ tokens on tool descriptions in every request. At that point, tool metadata is no longer a small overhead – it becomes a meaningful product and UX constraint.
For Rovo Dev, this was especially important because we want to support both:
- rich built-in integrations, such as Jira, Confluence, Bitbucket, and Compass, and
- user-configured third-party MCP servers without requiring users to think about context blow-ups.
The core idea
The key move is to replace a server’s full tool inventory with two generic wrapper tools:
- get_tool_schema(tool_name) – fetch the full input schema and documentation for one specific tool
- invoke_tool(tool_name, tool_input) – execute the selected tool with structured inputs
For the most aggressive compression tier, we optionally add a third helper:
- list_tools() – enumerate tools and short descriptions only when the agent explicitly asks
That changes the interaction pattern from “send the model every schema up front” to “send a tiny index first, then expand just the tool that matters right now.”

Why this works well for agents
What we like about this approach is that it preserves the important part of the MCP contract: the agent can still inspect schemas and call tools with structured inputs. We are not asking the model to hallucinate arguments or to operate on an undocumented API. We are simply moving detailed tool metadata from the initial prompt into an on-demand lookup step.
That gives us several advantages:
- Much lower fixed prompt cost for large toolsets
- Better prompt-cache behavior, because the compressed interface is stable across turns
- Scalability to many servers, including user-added third-party servers
- No loss of fidelity when a tool actually needs to be called, because the agent can still fetch the exact schema first
From product need to OSS
We first developed this pattern inside Rovo Dev as a practical response to rising MCP prompt costs. More recently, we published an equivalent open-source implementation as mcp-compressor, with docs at atlassian-labs.github.io/mcp-compressor.
The OSS version makes the idea easy to apply outside Rovo Dev: it acts as an MCP proxy that wraps an existing MCP server and exposes a compressed interface in front of it. That means the same design can be reused with other agents, other MCP clients, and other servers without requiring those servers to be rewritten.
In other words, the open-source project captures the general compression pattern, while Rovo Dev integrates the same idea directly into the agent runtime and prompt design.
How the approach shows up in Rovo Dev
In Rovo Dev, tool compression is part of the product experience rather than something users have to think about directly. Large MCP-backed toolsets can be presented to the model through a compact discovery layer, while the full schema for any individual tool remains available on demand.
That means the model starts from a much smaller and cleaner context, but it still has a structured path to expand the exact tool it wants before invoking it. In practice, this lets us support broader tool ecosystems without forcing the model to carry every schema for every tool in every turn.
It also fits naturally with the way Rovo Dev frames tool access: instead of overwhelming the model with giant flat lists of tools, we can present compressed toolsets as discoverable capabilities and let the model pull in detail only when relevant.
Configurable compression levels
One detail we found useful is that compression does not have to be all-or-nothing. Different products and models want different trade-offs between upfront context and discoverability.
In practice, the approach supports four levels of description verbosity:

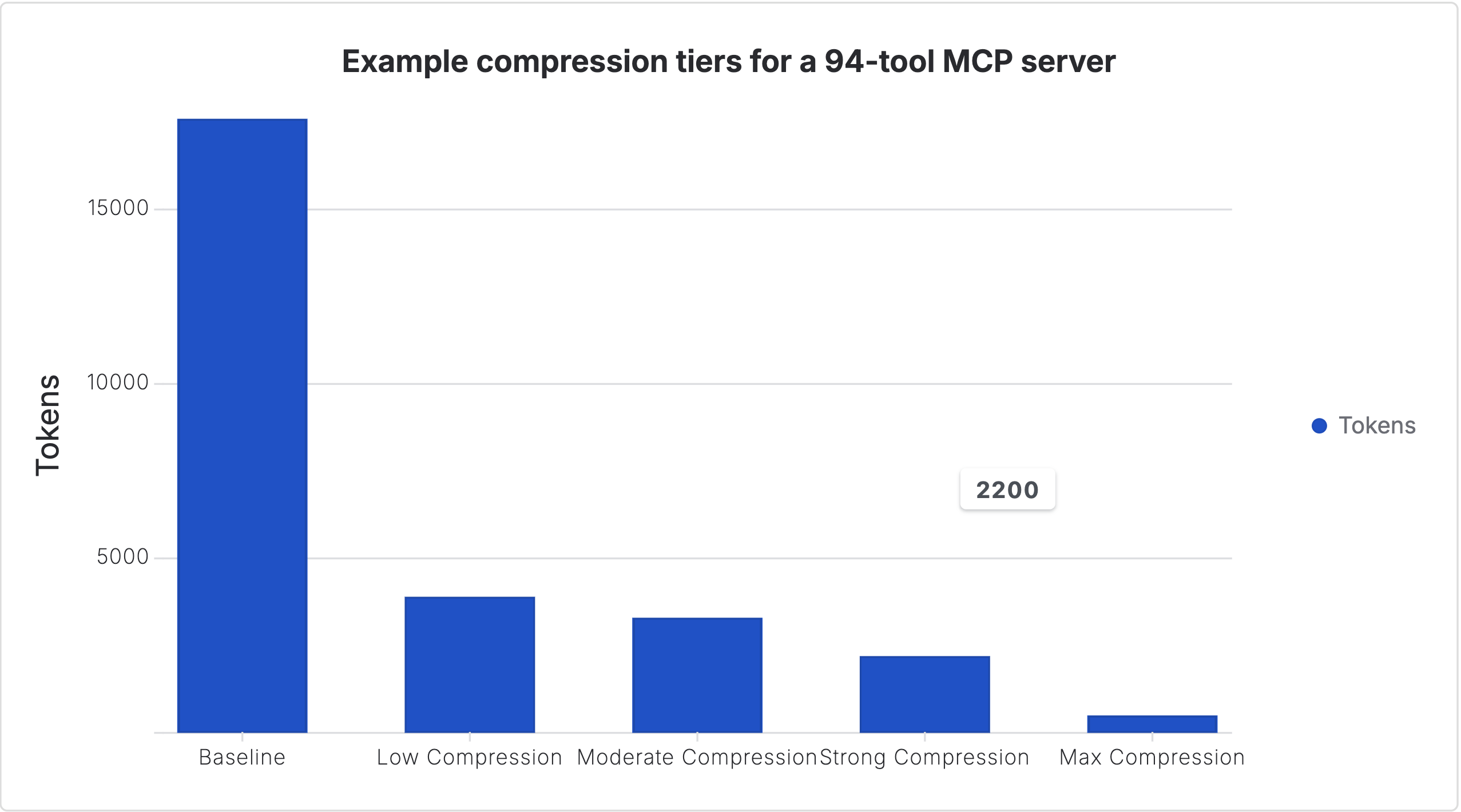
Raw data:
| Configuration | Tokens |
|---|---|
| Baseline | 17600 |
| Low Compression | 3900 |
| Moderate Compression | 3300 |
| Strong Compression | 2200 |
| Max Compression | 500 |
For a concrete example, the table chart above uses a GitHub MCP-style 94-tool scenario: 17,600 tokens with no compression, down to roughly 3,900 with low compression, 3,300 with moderate compression, 2,200 with strong compression, and as low as 500 with the most aggressive tier.
| Verbosity | What the model sees up front | Trade-off |
|---|---|---|
full | Tool names, argument names, and fuller descriptions | Least compression, highest discoverability |
brief | Tool names, arguments, and short one-line descriptions | Good balance for many large servers |
minimal | Only tool names and argument names | More aggressive compression |
none | No embedded tool list; the agent must explicitly call list_tools() | Maximum compression, slightly more indirection |
This is one of the reasons we think the approach is robust: it is not a single brittle heuristic. It is a tunable strategy that can be adapted to different server sizes, model behaviors, and cost envelopes.
What we learned
There were a few design principles that turned out to matter more than expected:
1. Compression should preserve structure, not remove it
The model still needs exact schemas before invocation. The goal is not to hide the API; the goal is to avoid paying for every schema on every turn.
2. Namespacing matters
Rovo Dev uses generated prefixes such as mcp__atlassian__* so compressed tools remain easy for the model to reason about and safe to compose across multiple servers.
3. Cache-friendliness matters almost as much as raw token count
A small, stable wrapper interface works well with prompt caching. That means compression helps not just on first-turn size, but also on repeated interactions inside a session.
4. The agent needs an explicit discovery path
Once you stop dumping every tool schema into the prompt, you need to give the model a clean and well-documented way to discover what exists. The get_tool_schema / invoke_tool pattern gives the model a simple loop it can reliably follow.
Impact on quality
One obvious concern is whether compression makes the model worse at using tools. In practice, the answer appears to be: not meaningfully, if you preserve on-demand schema access.
In our testing, tool compression had almost no impact on end-to-end quality in the evaluation setup we used, while substantially reducing prompt overhead. That matches our intuition: the model does not need every possible tool schema at all times; it needs a reliable way to fetch the right one when relevant.
Alternative approaches
Schema-preserving tool compression is not the only way to reduce tool overhead. Another important family of approaches is what Cloudflare has described as Code Mode, and what Anthropic has written about as code execution with MCP.
Those approaches take a meaningfully different path: instead of primarily compressing a toolset into a smaller discovery interface, they lean on a coding environment or execution sandbox as the main way for the model to orchestrate work. For some use cases, that can be a very strong fit — especially when the task naturally benefits from writing programs, composing many steps in code, or manipulating tools through a programmable environment.
We see schema-preserving compression and code-mode approaches as complementary options, not mutually exclusive ideologies. But they do make different trade-offs.
| Approach | Strengths | Trade-offs |
|---|---|---|
| Schema-preserving tool compression | Keeps the model in the familiar tool-calling paradigm, preserves structured schemas, and offers a simple way to tune compression level. | Still requires some tool metadata to be exposed, and extremely large ecosystems may benefit from additional layers of discovery. |
| Code mode / code execution with MCP | Very flexible for complex orchestration, multi-step automation, and tasks where writing code is itself the most natural interface. | Introduces a new dependency on successful code generation and execution, which can become its own failure mode for workflows that would otherwise map cleanly to direct tool calls. |
For our use case, one of the biggest advantages of schema-preserving compression is that it gives a simple, explicit knob for tuning compression level. You can decide how much detail to expose up front – from richer descriptions to an almost pure discovery layer – without changing the core interaction pattern.
A second practical benefit is that, for many tools, schema retrieval is not even necessary on every call. If a tool name and its parameter names are already self-explanatory, the model can often invoke it directly using the compressed interface and only fetch the full schema when there is real ambiguity. That means the indirection cost stays low in many real workflows.
By contrast, code-mode approaches introduce a different class of risk: nothing works unless valid code is produced and executed successfully. That is not a criticism – in many situations, generating code is exactly the right abstraction – but it does mean you are moving farther away from the heavily-trained tool-calling paradigm that frontier models already handle well.
So our view is not that code mode is wrong. It is that it solves a somewhat different problem. If you want a programmable execution environment, code mode may be the better fit. If you want to keep the familiar ergonomics of tool calling while dramatically reducing the prompt footprint of large MCP toolsets, schema-preserving compression is a very attractive option.
What this unlocks
For us, tool compression is not just a cost optimization. It is an enabler.
- It makes it more realistic to ship large built-in integration sets.
- It makes user-configured third-party MCP servers safer to support by default.
- It creates a path toward many-server environments where the model can discover tools incrementally instead of carrying every tool description up front.
That last point is especially important. As agent products mature, the bottleneck will not be “can we connect to tools?” but “can we connect to many tools without destroying context efficiency?” We think tool compression is one of the core building blocks for that future.
Where to look next
- OSS implementation: github.com/atlassian-labs/mcp-compressor
- OSS docs: atlassian-labs.github.io/mcp-compressor
Try it today
If you already have an MCP server in your mcp.json, the easiest way to experiment with tool compression is to wrap that server with mcp-compressor instead of connecting to it directly.
Using the hosted GitHub MCP server as an example, the general pattern is:
{
"mcpServers": {
"github": {
"command": "uvx",
"args": [
"mcp-compressor",
"https://api.githubcopilot.com/mcp/",
"--server-name",
"github"
]
}
}
}