
Somebody on the Confluence user mailing-list asked whether anyone was using Confluence and Jira for ‘agile’ development, and if so, how?
Yeah, I know the recommendation is to stick with user stories on physical cards, but for various reasons I think I might get better adoption if they’re available electronically, in an easily updatable place, where we also organize the tests that go along with them, etc.

Given that the Confluence team had significantly ramped up its agility in recent releases, I thought it was a good opportunity to chime in about how Atlassian, and the Confluence team in particular (Jira and Confluence are run quite differently), eat our own dogfood. We’ve had an interesting time finding the right balance between various approaches, and have finally ended up with a process that works well for us. You can read the original forum post if you want, or I’ve adapted it to be more blog-friendly below:
h3. Rule 1: Everything goes in Jira.
Jira is our source of truth for what has been done to Confluence, and what still needs to be done to Confluence. When we write release-notes, Jira is what we have to consult to see what changed, and when a user complains about a bug or missing feature, Jira is the only place we can really send them for more information.
Jira activity (votes, watchers, comments) is also a useful indicator of the priority of any particular development task, so we pay attention to that.
We also use Jira in preference to cards for scheduling our bug-fix releases. All candidate fixes go into the next point release, and they’re worked on in order of priority/impact/ease of fixing/etc. After a week or two, all the so-far-available fixes are packaged up into a release, and the outstanding bugs are moved back to the next version number.
(We’ve since changed this process slightly, in response to complaints from users who saw their issues being repeatedly pushed back, version after version. Now we have a bucket for all “point release candidate fixes”, and issues are only targetted for a specific release when they are concretely scheduled.)
h3. Rule 2: Planning goes in Confluence
Planned (or potentially planned) features each get their own Confluence page. We call these “user stories”, but they’re generally a lot bigger in scope than an XP user story — each page describing
an entire feature like “autosave”, “labels”, or “mail archiving”. The pages start pretty bare: a short user-story-like description of the feature, some links to Jira issues, and maybe a point-form spec
if someone’s thought about it already. Then, as we have more ideas about the feature, they get jotted down onto the Confluence page and discussed in the comments. Confluence allows us to capture the
conversations we have about features so that when we come around to developing them, we still remember the obscure ideas we had six months earlier.
We have a simple page template for features that provides just enough structure to make the story pages look similar.
I find cards are great for stuff you’re doing Right Now, but things that are to be done in the future just aren’t useful sitting in the back of someone’s pile of cards. There are 800+ open feature and improvement requests for Confluence, and that’s just too much for a stack of physical objects to handle gracefully.
Having everything in Confluence and Jira means that anyone can find the “card” and scribble their thoughts on it, no matter where they are in the world or what time of day it is, which is pretty useful.
When we’re doing iteration planning we make a nice Confluence page for the iteration with a picture of whichever river we’re using as a code-name (pictures are important, even irrelevant ones, because they make a page look more inviting), the administrative details of the iteration, and links to those stories we’re planning to tackle.
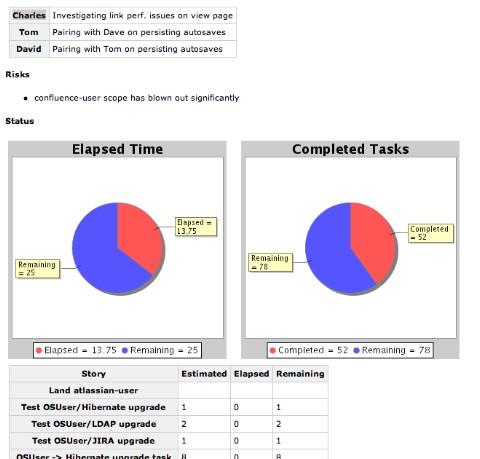
We find that Confluence is the perfect place for our “project status dashboard”, especially now we have the chart macro to play with:
Also, our nightly build script posts its results to Confluence via XML-RPC:

One of the Jira guys came up with a Confluence custom-field, which uses the Confluence remote API to give you a popup page picker from a Jira issue, to easily associate a Jira issue with a Confluence page. I’m rather ashamed to admit we haven’t got around to using this yet. Trackback has served us well enough so far.
h3. Rule 3: Stories go on Cards
Once we’ve committed to an iteration, we move stuff onto cards, estimate them, fit those we can into the iteration and stick them on the wall.
A single story page in Confluence can turn into five or ten different cards of varying estimations, which is useful because it gives us more flexibility to move stuff in and out of scope as the planning game progresses.
The advantage of cards is immediacy and physical presence, which makes them great for representing the things you’re doing right now.
h3. Rule 4: Tests go in CVS
If we had a manual test-plan, it’d probably go in Confluence. I’d consider writing the test plan for each feature as a child-page its story page, so it’s easy for developers to find when writing the feature, and adding a “test-plan” label to each of those pages so they could then be aggregated on some uber-test-plan page.
Instead we have an increasingly large suite of automated tests, and they live alongside the codebase in CVS.
We experimented with wiki-based testing frameworks, including writing one of our own, but we found that the process was too cumbersome. The frameworks didn’t give enough scope for refactoring common functions into a single place, or if they did they made it really inconvenient. So whenever you, say, renamed one of the buttons on the “Edit” page, you’d have to go through and modify two thirds of your tests, instead of just changing the “editPage()” method in your test helper class.